
머신 러닝 모델을 배포한 후 모니터링을 중요시하는 이유가 궁금했던 적이 있나요? 매주 매출 예측을 통해 소매점에서 포스트-배포 모델 모니터링 개념을 탐구하는 흥미로운 이야기를 살펴보겠습니다.
이 이야기를 따라가면 실제 월마트 매출 데이터 세트를 사용해볼 것입니다. 매출 예측 모델을 구축하고 이 머신 러닝 모델의 성능을 운영 중에 모니터링할 것입니다. Google Colab 노트북 내에서 운영 환경을 직접 모방하여 간단히 따라할 수 있을 것입니다.
우리는 실제 세계의 변화로 인해 시간이 지남에 따라 머신 러닝 모델이 악화되는 방법과 모니터링 부족이 상당한 재정 손실로 이어질 수 있는 이유를 발견할 것입니다. 그리고 ML 모델의 성능 모니터링에 nannyML을 사용하는 방법과 nannyML에 의해 발명된 확률적 모델이 필요한 이유를 알아볼 것입니다.
댄니 씨의 소매점

댄니 씨가 대형 소매점을 열면서 월마트와 유사한 상점이 열립니다. 상점이 성장함에 따라 주간 매출을 예측하고자 합니다. 따라서 댄니 씨는 데이터 과학자를 고용하여 주간 매출을 예측할 수 있는 기계 학습 모델을 구현하고자 합니다. 이를 통해 미래의 트렌드와 매출을 예측하여 재고와 수요를 미리 계획할 수 있습니다.
데이터 과학자는 댄니 씨의 주간 매출을 예측하는 인상적인 모델을 개발하여 테스트 데이터에서 97%의 정확도를 달성했습니다. 이 모델을 배포한 후, 데이터 과학자는 작별 인사를 남기고 갔습니다. :*)

Mr. Danny initially used the model in production. However, after some time, he noticed the model began to fail and gave incorrect predictions. He incurred a financial loss. Can you guess why the model performance degraded⁉️
Mr. Danny, who had limited technical knowledge, hired an ML Engineer. He identified the cause of the previous model failure as data drift. Simply put, data drift happens when real-world data changes in ways the model wasn’t trained for, leading to a decline in model performance.
The ML Engineer provided two possible reasons for the decline in model performance:
- 단변량 드리프트: 생산 중에 온도 패턴이 갑자기 변하여 쇼핑 패턴이 변경되었습니다. 예를 들어, 자외선 차단제와 탄산음료의 판매량이 증가했습니다.
- 다변량 드리프트: 고용률, 경기 침체 및 온도 변화가 모두 판매 패턴과 소비자 행동에 영향을 미쳤습니다. 이러한 요인들 사이의 복잡한 관계가 변화함에 따라 다변량 드리프트가 발생했습니다.
자세히 알아보려면 Hypothesis Testing를 사용한 데이터 드리프트 감지 방법을 방문해보세요.
ML 엔지니어는 모니터링 솔루션의 중심에 데이터 드리프트를 두는 것을 주장했습니다. Danny씨는 이 아이디어를 수용하고 모델 성능 모니터링을 시작했습니다. 그 결과, 그는 매일 모델로부터 다수의 경고를 받았습니다. 이는 그에게 상당한 정신적 스트레스를 야기했습니다.
그러나 Danny씨가 실제 '주간 매출'값 (해당 주의 실제 매장 판매액)을 받자, 대부분의 경고가 잘못되었음을 알게 되었습니다. 경고 중 90% 이상이 잘못되었고, 모델 성능 하락을 올바르게 표시한 경고는 10% 미만이었습니다. 결과적으로, 중앙 모니터링 전략으로 데이터 드리프트에 집중하는 것은 실패로 끝나게 되었습니다.
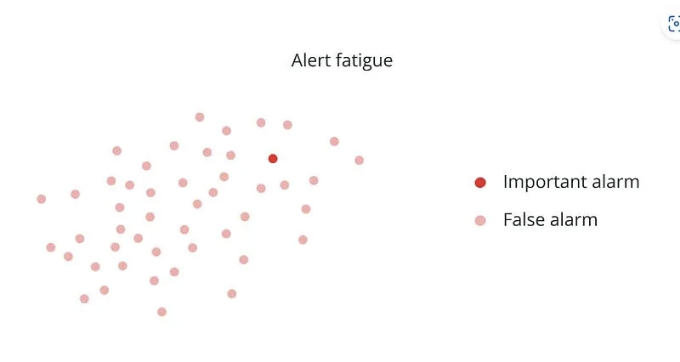
마침내 Mr. Danny는 nannyML이라는 라이브러리를 발견했습니다. 이 도구는 그의 ML 모델을 간병하는 역할을 할 수 있어서 지속적으로 성능을 모니터링하고 거짓 경보를 생성하지 않습니다. 그는 정답 데이터에 액세스하지 않고 ML 모델의 성능을 추정하고 데이터 드리프트를 감지할 수 있도록 했습니다.

다음으로, 우리는 Kaggle에서 사용할 수 있는 인기 있는 Walmart 판매 데이터 세트를 사용할 것입니다. 댄니 씨가 그의 가게를 위한 유사한 데이터를 가지고 있다고 가정해 봅시다. 우리는 NannyML을 사용하여 모델 모니터링 및 모델 성능 평가 방법을 탐색할 것입니다.

이것은 2010년 2월 5일부터 2012년 11월 1일까지의 판매를 다루는 기록 데이터입니다. 미국 전역에 위치한 여러 Walmart 매장에서 얻은 데이터가 포함되어 있습니다.
🤖nannyML의 모델 배포 후 모니터링을 위한 사용
우리가 할 일:
- 이 데이터를 사용하여 매장 수요를 예측하여 주간 매출을 예측합니다.
- 이 데이터에 nannyML 도구를 적용하여 모델 배포 후 모니터링을 결정합니다.
- 왜 댄니씨의 경우 대부분의 알람이 잘못 트리거되었는지 조사합니다.
주간 매출 데이터 소개

우리는 캐글에서 접근 가능한 널리 사용되는 월마트 판매 데이터셋을 활용할 것입니다. 이 데이터셋은 미국 전역에 위치한 여러 월마트 매장의 과거 판매 데이터를 포함하고 있습니다. 우리의 목표는 소매 수요 예측을 수행하고 주간 판매를 예측하는 것입니다.
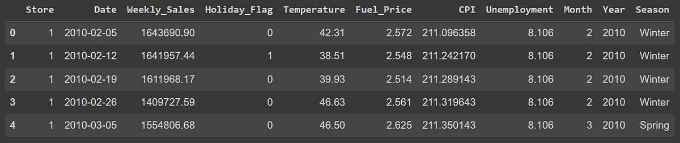
이 데이터는 2010년 2월 5일부터 2012년 11월 1일까지의 판매를 다루는 과거 데이터입니다:
기능 설명
- Store - 상점 번호
- Date - 판매 주
- 주간 판매 - 해당 상점의 매출
- 휴일 플래그 - 주가 특별한 휴일 주인지 여부 1 - 휴일 주 0 - 비휴일 주
- 온도 - 판매 일의 온도
- 연료 가격 - 지역의 연료 비용
- 소비자 물가 지수 - 현행 소비자 물가 지수
- 실업률 - 현행 실업률
- 월, 년, 계절 - 시간 관련 특성
EDA 및 전처리
일부 기본적인 탐색적 데이터 분석을 수행하고 일부 특성의 분포를 분석해보겠습니다.
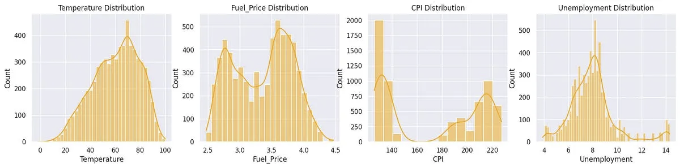
- CPI와 Fuel_Price는 이중분포를 가지고 있으며, Temperature와 Unemployment는 정규분포를 가지고 있습니다.
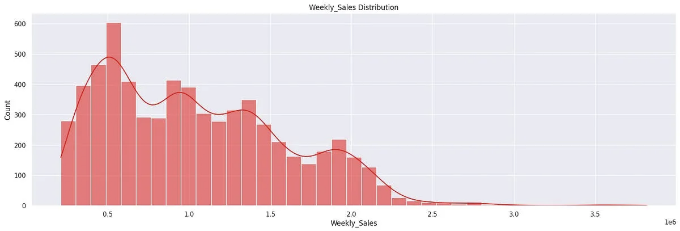
- Weekly_Sales 분포는 우측으로 치우쳐져 있으며, 이상치가 있습니다.
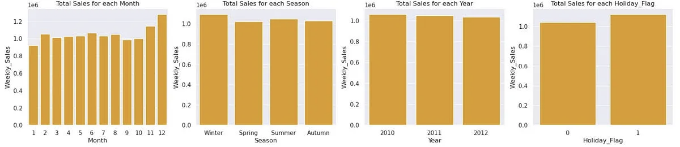
- 겨울 및 휴일에는 주간 매출이 특히 11월과 12월에 높음
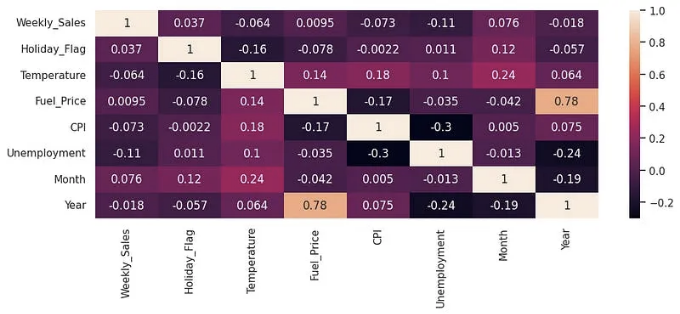
- 모든 특성의 상관 관계 히트맵은 각 입력 특성 간의 흥미로운 관계를 보여줍니다.
데이터 전처리 및 이상치 제거
#이상치 제거
num_features = ['Temperature', 'Fuel_Price', 'CPI', 'Unemployment', 'Weekly_Sales']
for feature in num_features:
q1 = df[feature].quantile(0.25)
q3 = df[feature].quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
df = df[(df[feature] >= lower) & (df[feature] <= upper)]
# 숫자형 변수 정규화
sc = StandardScaler()
df[num_features] = sc.fit_transform(df[num_features])
categoric_columns = ['Store', 'Season']
# 범주형 특성 인코딩
df[categoric_columns] = df[categoric_columns].astype('category')
encoder = BinaryEncoder(cols=categoric_columns)
df = encoder.fit_transform(df)
데이터를 nannyML에 맞게 분할 및 처리
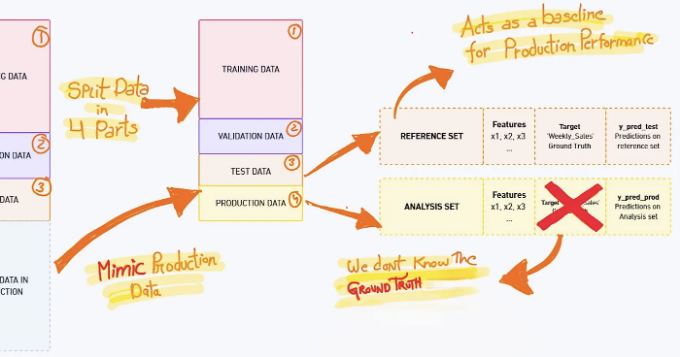
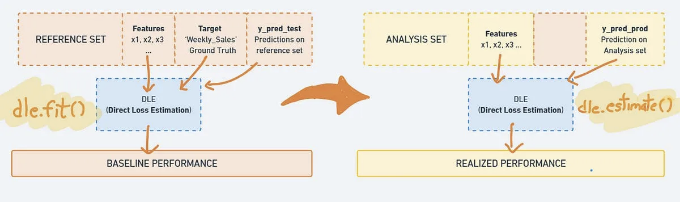
일반적으로 데이터는 학습, 검증 및 테스트 세트로 나누지만, nannyML에서는 데이터를 네 부분으로 나눕니다. 모델 모니터링 워크플로우는 제품 데이터를 모방하는 또 다른 세트를 필요로 합니다. 이는 시스템이 성능 하락을 올바르게 감지하고 올바른 알고리즘을 사용하여 어떤 문제가 발생했는지 보고하기 위함입니다.
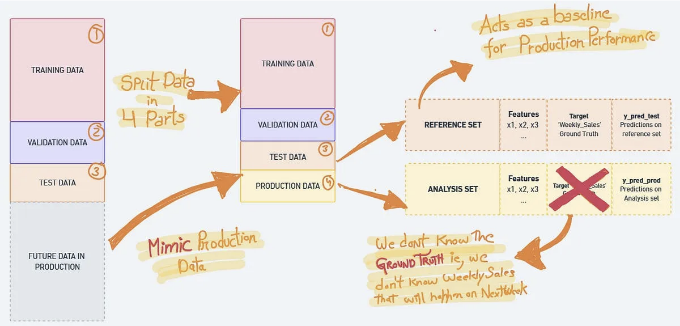
이 삽화는 데이터 분할에 관한 모든 것을 설명합니다. 깊이 이해하려면 코드를 읽어보세요.
참조 세트는 모델 모니터링 문맥에서 사용되는 테스트 세트의 다른 이름입니다. NannyML은 테스트 세트에서 모델의 성능을 기준으로 생산 성능을 측정합니다.
분석 세트는 모델에 의해 생성된 예측을 포함하는 생산 데이터이며 여기서는 실제 값(우리의 경우에는 미래 주의 소매점 매출)은 사용할 수 없습니다.
# 참고 - 여기서는 유효성 데이터를 생성하지 않습니다.
# 코드 이해를 돕기 위해 위 이미지를 참고하세요.
# 데이터 파티션 생성
df['partition'] = pd.cut(
df['Date'],
bins=[pd.to_datetime('2010-02-12'),
pd.to_datetime('2012-02-12'),
pd.to_datetime('2012-06-12'),
pd.to_datetime('2012-10-26')],
right=False,
labels=['train', 'test', 'prod']
)
# 타겟과 특성 설정
target = 'Weekly_Sales'
features = [col for col in df.columns if col not in [target, 'Date', 'partition']]
# 데이터 분할
X_train = df.loc[df['partition'] == 'train', features]
y_train = df.loc[df['partition'] == 'train', target]
X_test = df.loc[df['partition'] == 'test', features]
y_test = df.loc[df['partition'] == 'test', target]
X_prod = df.loc[df['partition'] == 'prod', features]
y_prod = df.loc[df['partition'] == 'prod', target]
따라서 최종 데이터 분포 분할은 다음과 같습니다:
- X_train 및 y_train: 2010-02-12 이후 데이터 (4725개)
- X_test 및 y_test: 2012-02-12 이후 데이터 (945개)
- X_prod 및 y_prod: 2012-06-12 이후 데이터 (675개)
기계 학습 모델 훈련하기
이제 LightGBM 회귀 모델을 훈련 데이터에 맞추어, 모델 예측과 기준 예측의 평균 절대 오차(MAE)를 계산하고 훈련 및 테스트 세트에 대한 예측을 수행할 것입니다.
#모델 훈련
model = LGBMRegressor(random_state=111)
model.fit(X_train, y_train)
# 예측 수행
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
# 기준 예측 수행
y_pred_train_baseline = np.ones_like(y_train) * y_train.mean()
y_pred_test_baseline = np.ones_like(y_test) * y_train.mean()
# 훈련, 테스트 및 기준 성능 측정
mae_train = mean_absolute_error(y_train, y_pred_train).round(4)
mae_test = mean_absolute_error(y_test, y_pred_test).round(4)
mae_train_baseline = mean_absolute_error(y_train, y_pred_train_baseline).round(4)
mae_test_baseline = mean_absolute_error(y_test, y_pred_test_baseline).round(4)
모델을 평가하기 위해, 모델의 훈련 및 테스트 MAE(Mean Absolute Error)를 주간_매출 열의 평균으로 지속적으로 예측하는 기준 모델과 비교할 것입니다.
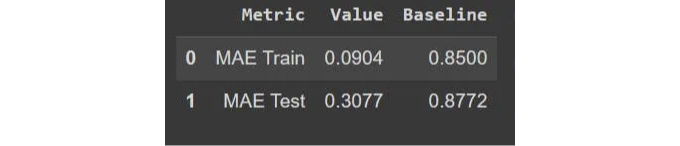
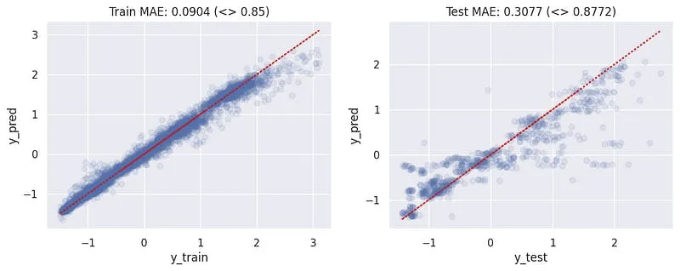
우리는 두 개의 산점도를 그렸습니다. 하나는 훈련용으로 실제와 예측값을, 또 다른 하나는 테스트 데이터에 대한 예측값을 표현한 것입니다. 두 경우 모두 평균 절대 오차가 비교적 낮은 수준으로 나타났습니다. 이는 모델이 이용 사례에 대해 충분히 잘 작동함을 의미합니다.
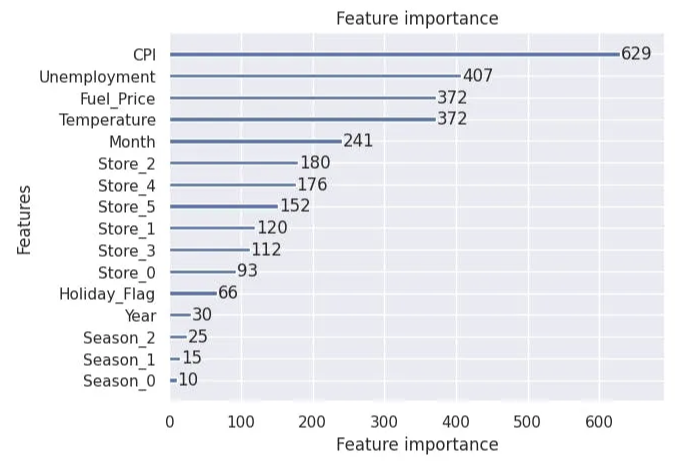
또한 우리는 특성 중요도를 계산했는데, 그 결과로 위 세 가지 중요한 특성은 소비자 물가 지수 (CPI), 실업률, 그리고 연료 가격임을 알게 되었습니다.
nannyML에서 성능 측정 예측
nannyML은 회귀 및 분류 모델의 성능을 추정하는 데 두 가지 주요 알고리즘을 제공합니다:
우리는 회귀 작업에 대한 직접 손실 추정 알고리즘(DLE)을 사용할 것입니다. DLE는 생성 모델의 성능을 그라운드 트루스 없이 측정하고 RMSE, RMSLE, MAE 등과 같은 다양한 회귀 유사 메트릭을 보고할 수 있습니다.
y_pred_prod = model.predict(X_prod) #생산 데이터에 대한 주간 매출 예측
reference_df = X_test.copy() # 참조용 테스트 세트
reference_df['y_pred'] = y_pred_test # 참조 예측
reference_df['Weekly_Sales'] = y_test # 그라운드 트루스(올바른 타겟)
reference_df = reference_df.join(df['Date']) # 날짜
analysis_df = X_prod.copy() # 특성
analysis_df['y_pred'] = y_pred_prod #생산 예측
analysis_df = analysis_df.join(df['Date']) # 날짜
DLE를 사용하기 위해서는 먼저 기준 성능을 설정하기 위한 참조값을 맞춰야 합니다.
dle = nml.DLE(
metrics=['mae'],
y_true='Weekly_Sales',
y_pred='y_pred',
feature_column_names=features,
timestamp_column_name='Date',
chunk_period='w'
)
dle.fit(reference_df) # 참조(테스트) 데이터에 fit
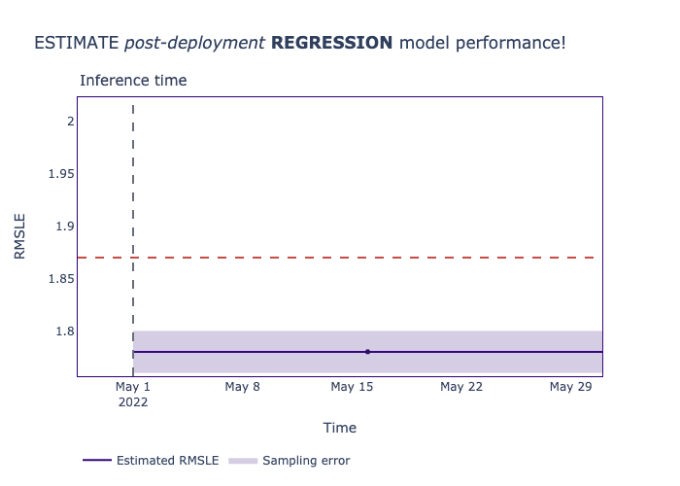
estimated_performance = dle.estimate(analysis_df) # 제품 데이터에 대한 추정값
성능 문제가 감지되지 않았으며, 추정된 성능이 임계값 내에 있음을 관찰했습니다.
미스터 댄니는 미래 주간 판매액에 대한 실제 데이터를 가지고 있지 않지만, 거짓 경고 없이 철저한 모델 성능 보고서를 받고 있습니다.
몇 일 후에 댄니씨가 Weekly_Sales(목표값이 사용 가능해지면) 실제 모델 성능을 계산할 수 있습니다. 이것을 제작 데이터의 실제 성능이라고도 합니다. 아래 셀에서는 실제 성능을 계산하고 이를 nannyML의 추정치와 비교합니다.
calculator = nml.PerformanceCalculator(
problem_type="regression",
y_true='Weekly_Sales',
y_pred="y_pred",
metrics=["mae"],
timestamp_column_name='Date',
chunk_period='w'
)
calculator.fit(reference_df)
realized_performance = calculator.calculate(analysis_df.assign(Weekly_Sales = y_prod)
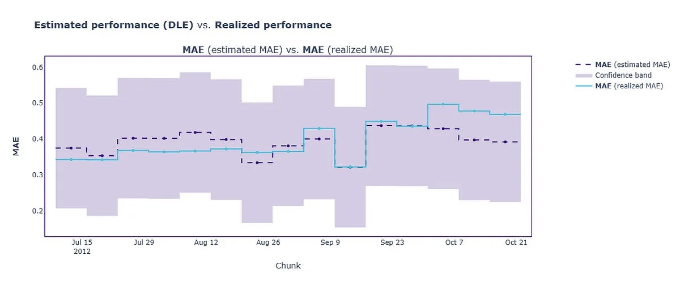
- 위 그림에서 추정 성능이 실제 성능과 밀접하게 일치하여, DLE의 추정이 정확했음을 나타냅니다.
왜 잘못된 경보가 발생하는 것일까요?
이제 이 데이터에 대한 단변량 및 다변량 drift를 검토하고, 이것이 Danny씨의 경우에 실패한 이유를 설명하겠습니다.
drdc = nml.DataReconstructionDriftCalculator(
column_names=features,
timestamp_column_name='Date',
chunk_period='d',
)
drdc.fit(reference_df)
multivariate_data_drift = drdc.calculate(analysis_df)
multivariate_data_drift.plot()
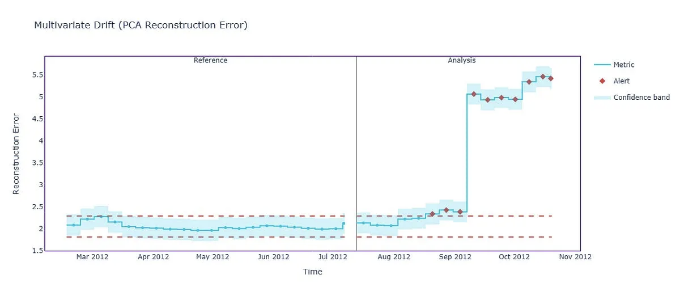
다변량 이동 방법을 통해 분석 데이터에 대한 경고를 받았습니다. 이는 모델 성능에 영향을 미치지 않았기 때문에 잘못된 경고입니다.
udc = nml.UnivariateDriftCalculator(
column_names=features,
timestamp_column_name='Date',
chunk_period='w',
)
udc.fit(reference_df)
univariate_data_drift = udc.calculate(analysis_df)
univariate_data_drift.filter(period='all', metrics='jensen_shannon', column_names=['Unemployment']).plot(kind='distribution')
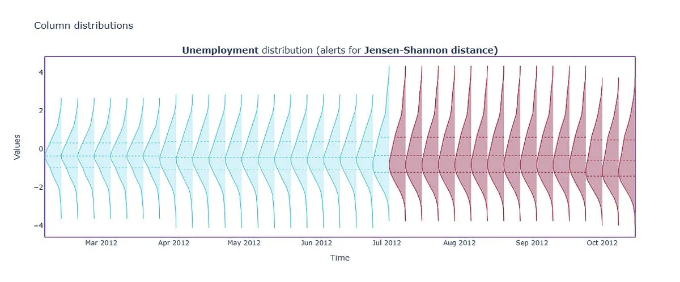
비슷하게, 일변량 드리프트 방법은 우리에게 분석 데이터에 대한 경고를 주었습니다. 그것은 잘못된 경고였습니다. 왜냐하면 모델 성능에 영향을 미치지 않았기 때문입니다. 따라서 잘못된 경보가 발생했음을 보았습니다. 데이터 드리프트 방법이 모니터링 솔루션의 중심에 놓여 있었기 때문입니다.
요약
우리는 nannyML이 소매 판매 예측을 위해 실제 월마트 데이터에 적용되는 방법을 탐색했습니다. 소비자 행동과 시장 트렌드의 변화에 대한 도전을 극복했습니다.
모델 모니터링의 중요성을 배웠지만, 효과적인 모니터링을 방해할 수있는 잘못된 경고 문제도 배웠습니다.
여기까지 오셨다면, NannyML의 문서를 살펴보시고 여러 사용 사례에서 어떻게 혜택을 받을 수 있는지 확인하는 것을 강력히 추천합니다. 더 많은 정보를 원하신다면 그들의 웹사이트도 방문해보세요.