
토픽 모델링(즉, 텍스트 데이터 코퍼스에서의 토픽 식별)은 라텐트 디리클레 할당(LDA) 모델이 발표된 이후 빠르게 발전해왔습니다. 그러나 이 클래식한 토픽 모델은 단어들 간의 관계를 잘 포착하지 못합니다. 왜냐하면 단어 가방이라는 통계적 개념에 기반하기 때문입니다. 최근에는 임베딩 기반의 Top2Vec와 BERTopic 모델이 사전 훈련된 언어 모델을 활용하여 토픽을 생성함으로써 이러한 단점을 극복하고 있습니다.
이 기사에서는 Maarten Grootendorst의 (2022) BERTopic을 사용하여 정치 연설 원고에서 토픽을 대표하는 용어를 식별할 것입니다. 이 모델은 다양한 코퍼스에서의 토픽 모델링 지표에서 전통적이고 현대적인 대부분의 토픽 모델을 능가하며, 기업, 학계(Chagnon, 2024) 및 공공부문에서 활용되어왔습니다. 우리는 다음을 파이썬 코드를 통해 살펴볼 것입니다:
- 데이터를 효과적으로 전처리하는 방법
- Bigram 토픽 모델을 생성하는 방법
- 시간이 지남에 따라 가장 빈번한 용어를 탐색하는 방법.
1. 예제 데이터
예제 데이터 세트로는 Efat et al. (2023) 논문의 일환으로 공개된 Empoliticon: Political Speeches-Context & Emotion 데이터 세트를 사용합니다. 해당 데이터 세트는 국제 저작권 4.0 라이센스에 따라 출시되었으며 미국, 영국, 중국 및 러시아 대통령/총리의 정치 연설 2010개의 대본을 포함하고 있습니다. 주제 모델을 더 집중시키기 위해 하위 집합에는 러시아 리더들의 556개 연설만 포함되어 있습니다:
2. 데이터 전처리
텍스트 데이터셋 작업은 복잡합니다. 단순한 정리만으로도 데이터셋에서 모든 불필요한 정보를 체계적으로 제거해야 하는 여러 단계가 필요합니다. 이 프로젝트의 모든 요구 사항을 확인해 주세요.
2.1. 못 읽는 문자(mojibake) 오류 수정
못 읽는 문자(mojibake)는 문자 인코딩 오류로 인해 나타나는 혼란스러운 텍스트를 의미하는 일본어 단어입니다. 다음은 예시입니다:

클리닝을 시작하기 전에 이 단계를 포함하는 것이 유용합니다. 인코딩 관련 오류를 수정하는 것은 간단합니다:
2.2. 특수 문자, 구두점 및 숫자 정리
이 단계는 인코딩 오류를 수정한 후에 바로 이어져야 합니다. 가장 간단한 방법은 cleantext 라이브러리를 사용하는 것입니다. 또한 소문자화를 고려하세요. 데이터 집합에서 "노동"과 "Labor"가 같은 의미인가요? 그렇다면 lowercase 매개변수를 추가하고 클리닝 함수를 적용하십시오:
2.3. 불용어 제거 전략 정의
일반적으로 불용어 목록을 제거하는 것은 필수적입니다. 프로젝트의 초점에 따라, 가치를 더하지 않는 추가적인 불용어 목록에서 데이터를 정리하는 것도 유용할 수 있습니다. BERTopic의 문서에 작성된 것처럼:
대신, 주제 모델 생성 중 임베딩을 생성한 후 문서를 전처리하는 데 CountVectorizer를 사용합니다.
3. 주제 생성
보다 깔끔한 데이터셋으로, 영어 불용어와 추가 불용어 목록을 제거하고, 주제 바이그램 모델을 생성한 후 데이터에 적용할 수 있습니다.
nr_topics parameter은 7로 설정되어 있으며, 6개의 토픽을 생성합니다. 나머지 토픽은 이상치를 유지하는 데 사용됩니다.
4. 토픽 시각화
다음 단계에서는 결과를 더 잘 표현하기 위해 히트맵으로 데이터를 시각화해보겠습니다. 결과는 다음과 같습니다:
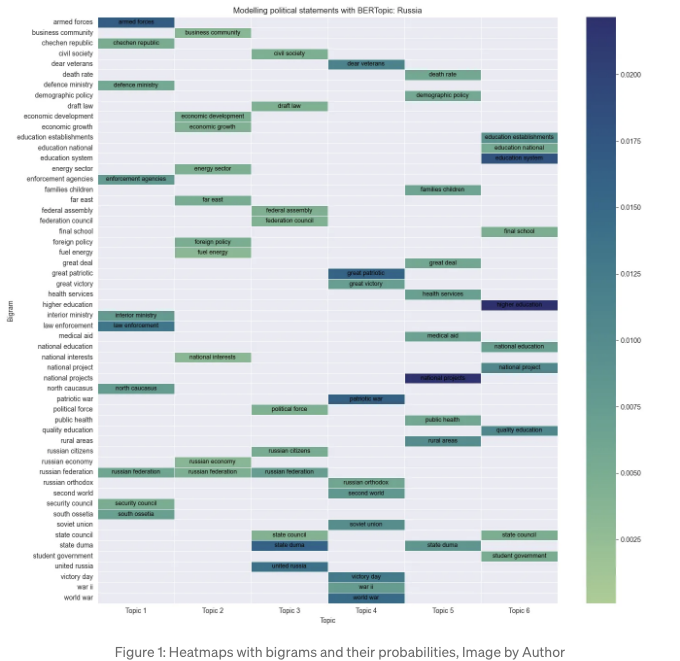
아래와 같이 하겠습니다. 토픽 모델에서 바이그램과 그 확률을 추출하여 6개 주제에 대한 데이터 프레임을 작성할 것입니다:
다음으로, 이 코드는 Figure 1에 히트맵을 생성합니다.
5. 시간별 토큰 빈도
이제, 시간에 따른 바이그램의 발전에 대한 관점을 추가할 것입니다. 러시아 지도자의 연설에서 어떤 연도에 바이그램이 가장 자주 사용되었는지 살펴볼 것입니다. Figure 2의 히트맵은 각 연도별로 5개 가장 빈도가 높은 바이그램의 빈도를 표시합니다.
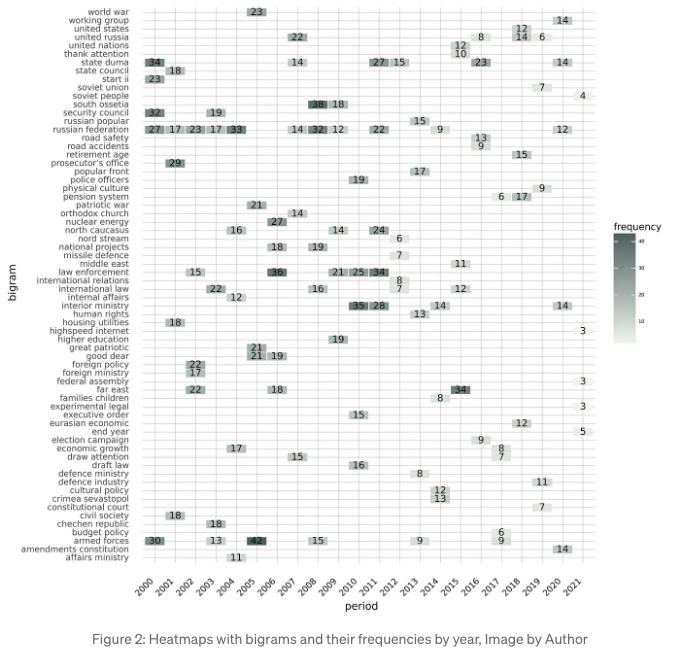
The arabica library, which is now forthcoming in the Journal of Open Source Software (Koráb & Poměnková, 2024), was developed for this purpose. Here is the code generating the heatmap in Figure 2:

Conclusions
이 기사는 BERTopic을 사용한 토픽 모델링에 대해 간단히 소개했습니다. 이 모델의 프레임워크는 다양한 확장, 세밀 조정 및 시각화 방법을 제공합니다(문서 참조). 주요 결과를 요약해보겠습니다:
- 토픽 모델은 방어 정책(토픽 1), 경제 발전(토픽 2), 제2차 세계대전(토픽 3), 내부 정책(토픽 4), 건강 및 인구통계(토픽 5), 교육(토픽 6)에 대해 6가지 명확한 토픽을 보여줍니다.
- Arabica와 BERTopic을 결합하면 외교 및 방위 정책 토픽(“군사”, “러시아 연방”, “법 집행”)이 2012년 이전에 더 자주 논의되었음을 볼 수 있습니다. 반면 교육 및 건강관련 주제가 특히 2010년 이후에는 적게 논의되었습니다.
- Arabica가 절대 빈도를 반환하기 때문에 데이터셋에는 제2차 세계대전, 외교 및 방위 정책 용어가 더 많이 포함되어 있습니다. 그러나 지역적 맥락을 알지 못하면 결과를 잘 해석하기 어렵습니다.
이전 기사에서 간단한 LDA를 사용한 토픽 모델링 접근 방식에 대해 설명한 바 있습니다. 이 튜토리얼의 완전한 코드는 내 GitHub에 있습니다.
제 작품을 즐기신다면 커피를 사주시고 글쓰기를 지원할 수 있습니다. 또한 새 기사 발행 알림을 받기 위해 이메일 목록을 구독할 수도 있습니다. 감사합니다!
참고 자료
[1] Blei, Ng, Jordan (2003). Latent Dirichlet Allocation. Journal Of Machine Learning Research 3, pp. 993–1022.
[2] Chagnon, Pandolfi, Donatelli, Ushizima (2024). Benchmarking topic models on scientific articles using BERTeley. Natural Language Processing Journal 6.
[3] Efat, Atiq, Abeed, Momin, Alam (2023). Empoliticon: NLP 및 MLBased Approach를 사용한 정치 연설에서 컨텍스트 및 감정 분류. IEEE Access, vol. 11.
[4] Grootendorst (2022). Bertopic: Neural Topic Modeling With A Class-Based TF-IDF Procedure. Computer Science.
[5] Koráb, Poměnková (2024). Arabica: A Python package for exploratory analysis of text data. In The Journal of Open Source Software. Journal of Open Source Software. https://doi.org/10.5281/zenodo.10866697.