데이터 엔지니어로서, 데이터 파이프라인을 다루고 성능을 최적화하는 데 수많은 시간을 보냈습니다. PySpark에 대해 꽤 잘 알고 있을 줄 알았지만, 몇 가지 부분에 대해 틀렸던 것을 깨달았습니다 — 특히 repartition() 함수에 관한 부분이 그렇습니다.
많은 분들처럼, 저도 repartition() 함수가 어떻게 작동하는지에 대해 많은 가정을 했습니다. 그러나 몇몇 가정이 사실은 크게 틀렸던 것으로 판명이 났습니다. 이 블로그 게시물에서는 PySpark에서 분할에 대한 일반적인 오해 몇 가지를 해소해보겠습니다. repartition() 함수에 집중하고, 실제로 데이터가 파티션으로 어떻게 분산되는지 살펴보겠습니다.
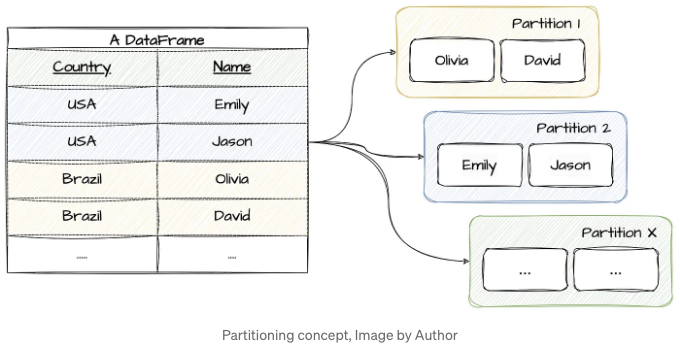
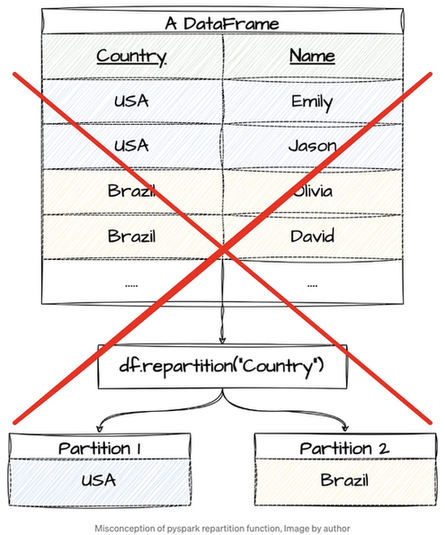
그러나 스크롤 다운하기 전에 — df.repartition(columnName)이 columnName의 값을 기반으로 데이터를 분배한다고 알고 계셨나요? 아래 이미지와 같은 방식으로 말이죠? 이것은 흔히 퍼지는 미신입니다! 사실은 대부분의 사람들이 생각하는 방식으로 작동하지 않습니다. 흥미를 느껴지나요? 이어서 진실을 밝혀보고 파티션 전략을 최적화하는 방법을 배워보세요!
파이스파크에서는 두 가지 주로 사용되는 파티션 전략을 알고 있습니다. 첫 번째는 df.repartition()이고 두 번째는 df.repartitionByRange()입니다. 이 두 함수는 데이터프레임 내에서 데이터를 파티션 간에 재분배하기 위해 일정한 로직을 사용합니다. 오늘은 repartition() 함수에 중점을 둘 것입니다.
신화
일반적으로 SQL 언어에서는 데이터를 파티션 키(예: 국가)로 파티션하면 해당 데이터가 국가 별로 여러 청크로 분할될 것이라는 개념을 자주 접하게 됩니다. 예를 들어, 이것은 일반적으로 사용되는 T-SQL 코드입니다:
SELECT
Country,
COUNT(Name) OVER (PARTITION BY Country) AS CountPerCountry
FROM sample_data;
Databricks의 Delta Tables을 사용하더라도 간단한 Spark SQL 절로 테이블을 파티션할 수 있어요:
CREATE TABLE partitioned_country_table
USING DELTA
PARTITIONED BY (Country)
AS SELECT * FROM sample_data;
PySpark DataFrames를 사용할 때 파티션을 어떻게 볼지를 다시 고려하는 것이 중요해요. 확장 가능한 병렬 컴퓨팅을 위해 설계된 Spark에서는 파티션을 주로 데이터를 효율적으로 worker 노드에 분산시키는 데 사용하며 집계를 수행하는 데 사용되지는 않아요.
.repartition(columnName)을 사용하면 데이터가 columnName의 고유 값에 따라 자동으로 그룹화된다는 흔한 오해가 있습니다. 이 오해는 사람들이 "repartition"이란 용어가 데이터를 해당 열 값에 따라 별도의 그룹으로 재구성한다고 직감적으로 생각하기 때문에 발생합니다. 하지만 Spark에서는 .repartition(columnName)이 데이터를 재분배하여 병렬성을 달성하고 성능을 향상시키지만 모든 columnName 값을 가진 행이 반드시 동일한 파티션에 포함되는 것을 보장하지는 않습니다.
가짜 데이터로 이를 증명해 봅시다.
from faker import Faker
import random
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import spark_partition_id, countDistinct
spark_session = (
SparkSession.builder.master("local")
.appName("Spark Repartitioning")
.config("spark.sql.adaptive.enabled", "false")
.getOrCreate()
)
# Faker 초기화
fake = Faker()
# 샘플 데이터 생성
def generate_data(num_records):
data = []
for _ in range(num_records):
name = fake.name()
country = fake.country()
data.append((name, country))
return data
data = generate_data(1000) # 1000개 레코드 생성
data = spark_session.sparkContext.parallelize(data)
# 데이터의 스키마 정의
schema = StructType(
[
StructField("Name", StringType(), True),
StructField("Country", StringType(), True),
]
)
# 데이터와 스키마를 사용하여 DataFrame 생성
df: DataFrame = spark_session.createDataFrame(data, schema)
df = df.repartition("Country").withColumn("partitionId", spark_partition_id())
(
df.groupBy("partitionId")
.agg(countDistinct("Country").alias("DistinctCount"))
.filter("DistinctCount > 1")
.show()
)
+-----------+-------------+
|partitionId|DistinctCount|
+-----------+-------------+
| 31| 2|
| 85| 2|
| 65| 3|
| 155| 3|
| 26| 4|
| 103| 2|
| 91| 2|
| 22| 2|
| 157| 2|
| 177| 2|
| 52| 2|
| 13| 3|
| 86| 2|
| 178| 2|
| 20| 2|
| 40| 3|
| 57| 2|
| 120| 2|
| 96| 2|
| 48| 2|
+-----------+-------------+
상위 20개 행만 표시됨
보시다시피, 일부 DataFrame 파티션에는 파티션당 하나 이상의 나라가 포함되어 있어서, 처음에 기대했던 것과는 다릅니다. 그런데 왜 이런 일이 발생하는 걸까요?
이 진실은 PySpark의 배경에 숨어 있습니다. repartition() 함수는 내부적으로 HashPartitioner를 호출하여 (이 멋진 Stack Overflow 댓글에서 설명된대로) 데이터를 파티션으로 분산합니다. 이 파티셔너는 데이터를 파티션에 따라 분배하기 위해 다음과 같이 정의된 공식을 사용합니다: hash(partitionKey) % numPartitions
아래 다이어그램에 따라 데이터를 파티션에 분배합니다.
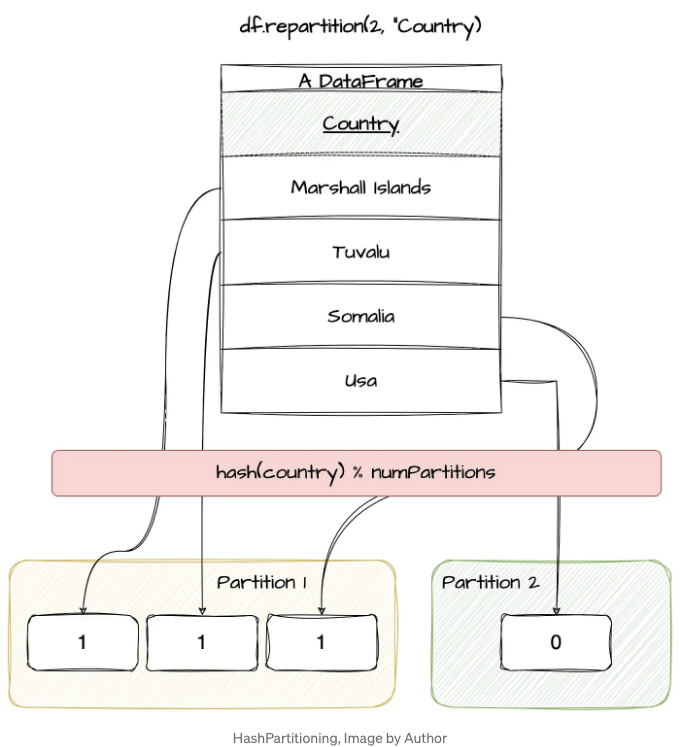
한 열을 계산하기 위해 스파크의 해시 파티셔너 동작을 모방하는데, 실제로는 해시 코드 및 파티션 수에 대한 음수가 아닌 모듈화가 발생한다는 점에 유의하십시오 (소스 코드에 따르면).
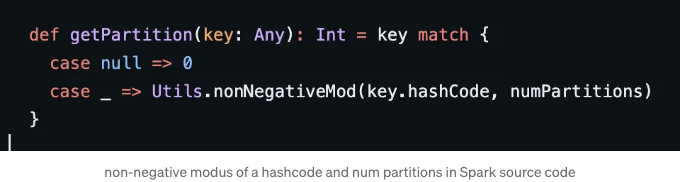
위의 다이어그램을 복제하는 PySpark 코드입니다.
from pyspark.sql.functions import hash, col, lit, spark_partition_id, udf
data = [("Marshall Islands",), ("Tuvalu",), ("Somalia",), ("USA",)]
schema = StructType([StructField("Country", StringType(), True)])
# 파티션 수
num_partitions = 2
# 해시 및 파티션 계산
df2 = df.withColumn("hash", hash(col("Country")))
df2 = df2.withColumn("num_partitions", lit(num_partitions))
df2 = df2.withColumn(
"hash(Country) % numPartitions",
(col("hash") % col("num_partitions") + col("num_partitions"))
% col("num_partitions"),
)
df2 = df2.repartition(num_partitions, col("Country"))
df2 = df2.withColumn("spark_partition_id", spark_partition_id())
df2.show()
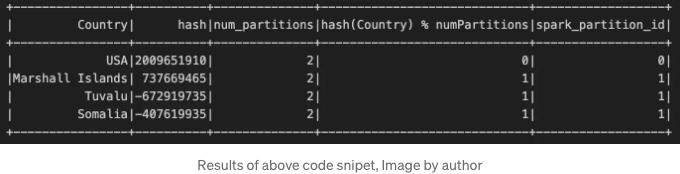
보시다시피, 레코드가 어느 파티션에 끝날지 예측할 수 있으므로 .repartition() 함수가 더 이해하기 쉬워집니다.
이게 왜 중요한가요?
저는 직접 참여한 프로젝트에서의 실제 사용 사례로 생각해보겠습니다. 저희는 Databricks와 PySpark를 사용하여 수백 테라바이트의 매우 큰 데이터 세트를 이관했습니다. 데이터가 처리된 후에는 Spark MSSQL Connector를 사용하여 Azure SQL Server에 저장되었습니다. 테이블을 파티션별로 데이터를 저장할 때 높은 동시성을 보장하기 위해 경쟁과 대기 시간을 줄이기 위해 노력했습니다. 초기 접근 방식은 쓰기 프로세스 이전에 .repartition()을 사용하는 것이었는데, 이로 인해 일부 속도 이점을 얻었습니다. 그러나 여전히 락과 경합이 발생했습니다. 최종적으로 우리는 repartitionByRange()로 전환했고, 이 방법이 더 결정론적이며 우리의 SQL Server 테이블 파티셔닝 전략과 더 잘 부합한다는 것을 알게 되었습니다.
이것은 한 가지 사용 사례에 불과하지만, 이 개념을 이해하는 것은 잠재적인 병목 현상을 식별하는 데 도움이 됩니다. repartitionByRange() 대 repartition()과 그들의 성능 영향에 대한 장단점에 대한 구체적인 기사를 쓰기로 계획하고 있습니다.
결론
PySpark에서의 Repartitioning은 파이프라인 성능에 중요한 측면입니다. PySpark 파티션 내 데이터의 분포는 병렬성 뿐만 아니라 리소스 활용에도 영향을 미칩니다. 리소스를 더 효율적으로 사용하기 위해서는 적절한 파티셔닝이 필요합니다.
repartition() 메서드가 모든 문제를 해결해 주지는 않지만, 그 동작을 이해하는 것이 중요합니다. 이 메서드는 데이터를 분할하는 데 있어 파티션 키를 기준으로 결정적으로 분할하는 것이 아니라, 작업 노드에 데이터를 골고루 분배하여 성능과 병렬화를 향상시키는 데 사용됩니다.
연락 유지하기
만약 이 글을 즐겼다면, 다른 파티션 함수에 대해 더 알고 싶다면 망설이지 말고 나를 팔로우해주세요. 그래야 최신 글들이 더 빨리 당신에게 전달될 거에요.
- 더 이상 이야기들을 원하신다면 Medium에서 제게 팔로우해주세요.
- LinkedIn에서 연락해주세요.
참고해 주셔서 감사합니다 :)
간단히 말해 🚀
In Plain English 커뮤니티의 일원이 되어 주셔서 감사합니다! 떠나시기 전에:
- 작가를 클랩하고 팔로우해주세요 ️👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | Newsletter
- 다른 플랫폼 방문하기: Stackademic | CoFeed | Venture | Cubed
- PlainEnglish.io에서 더 많은 콘텐츠 만나보세요