
1. 소개
소매 가격 전략은 매출과 이익을 최적화하는 데 중요합니다. 효과적인 가격 책정은 수요, 시장 상황 및 경쟁을 고려하여 소비자 행동을 영향을 주고 매출을 극대화합니다. 예를 들어 소매업체는 가격을 전략적으로 조정하고 할인을 적용하여 매출을 촉진하고 수익을 증가시킬 수 있습니다.
본 논문은 Deep Deterministic Policy Gradient (DDPG) 알고리즘을 사용한 강화 학습 접근 방식을 통해 가격 전략을 최적화하는 것을 탐구합니다. 가격과 할인을 동적으로 조정함으로써 가격 결정을 개선할 수 있습니다. 또한 SHAP (Shapley Additive Explanations) 값은 모델의 결정에 미치는 가격, 할인 및 매출의 영향에 대한 통찰을 제공합니다. 이러한 복합 접근 방식은 실시간 분석 및 설명 가능한 인공지능 기술을 통합하여 전통적인 가격 모델을 향상시킵니다.
2. 소매 업계의 가격 정책 모델링
소매 업계의 가격 정책은 수익과 이윤을 최적화하기 위해 수학적으로 모델링될 수 있습니다. 매출 기능은 다음과 같이 작성할 수 있습니다:
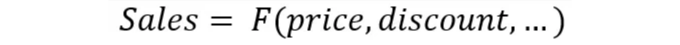
이는 매출이 주로 가격과 할인과 같은 여러 요소에 의존한다는 것을 의미합니다. 일반적으로 가격이 증가하면 매출이 감소하고 그 반대도 마찬가지입니다. 최적의 가격을 찾아 매출이나 이윤을 극대화하는 것이 목표입니다. 예를 들어, 매출 기능이 이차 함수를 따른다면:
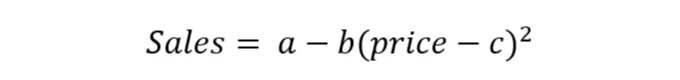
상수 a와 b가 있는 경우, 최적화 기법으로는 이차 또는 선형 프로그래밍을 사용하여 최적 가격을 찾을 수 있습니다.
하지만 전통적인 최적화 방법에는 한계가 있습니다. 실시간 적응성이 부족해 즉각적인 시장 변화에 기초한 효율적인 가격 조정이 어려울 수 있습니다. 또한 판매에 영향을 미치는 요소에 대한 사전지식이 필요한데, 동적인 시장에서는 항상 실행 가능하지 않을 수 있습니다.
실시간 데이터 및 강화 학습과 같은 고급 머신러닝 모델은 이러한 도전에 대한 해결책을 제공합니다. 이러한 모델은 가격 전략을 동적으로 조정하고 다양한 요소의 영향을 분석하여 소매 환경에서 더 효과적이고 반응력있는 가격 결정을 지원할 수 있습니다.
3. Pricing Strategies를 위한 강화 학습
강화 학습 (RL)은 환경과 상호 작용하여 누적 보상을 극대화하기 위해 최적의 조치를 학습하는 기계 학습 기술입니다. 우리의 가격 전략에서는:
- 환경: 소매 시장
- 에이전트: 가격 모델
- 목표: 가격과 할인을 동적으로 조정하여 매출과 이윤을 최적화
우리는 실시간 의사 결정에 이상적인 정책 기반 및 가치 기반 학습을 결합한 Deep Deterministic Policy Gradient (DDPG) 알고리즘을 활용합니다. DDPG의 작동 방식은 다음과 같습니다:
정책 기반 학습: 강화 학습의 정책 함수인 액터-네트워크를 사용합니다:
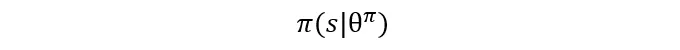
상태 s가 주어진 경우 동작 a를 선택합니다. θ^π는 정책 네트워크의 매개변수입니다.
가치 기반 학습: 비평가 네트워크(Q 함수)를 사용합니다:
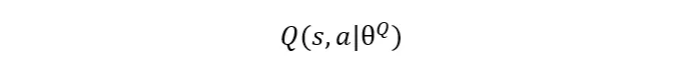
행동-가치 함수를 평가하기 위해.
학습 과정:
- Actor-Critic 아키텍처: Actor는 기대값 반환의 그래디언트를 따라 정책을 업데이트하며, Critic은 벨만 방정식을 사용하여 가치 추정을 업데이트합니다.
- Experience Replay: 과거 경험 (s,a,r,s′)을 재생 버퍼에 저장하여 상관 관계를 끊고 학습을 안정화합니다.
- Target Networks: 학습을 안정화하도록 학습된 네트워크를 천천히 추적하기 위해 목표 네트워크 세트 θ^π′ 및 θ^Q′를 유지합니다.
DDPG의 장점은 다음과 같습니다:
- 적응성: DDPG는 최신 시장 데이터를 기반으로 실시간으로 조정을 제공합니다.
- 세밀한 결정: 연속적인 액션 공간은 정확한 가격 조정을 가능하게 합니다.
- 데이터 기반 통찰력: 다양한 요소(가격, 할인 등)가 매출에 미치는 영향을 이해하는 데 도움이 되어 보다 효과적인 가격 전략을 도와줍니다.
4. 코딩 및 데이터 실험
이제 강화 학습(RL) 프레임워크 내에서 딥 디터미니스틱 정책 그라디언트(DDPG) 알고리즘을 구현하여 소매 가격 전략을 최적화해봅니다. 이 접근 방식은 매출과 이익을 극대화하기 위해 가격과 할인을 동적으로 조정합니다. 게다가, SHAP(Shapley Additive Explanations) 분석을 사용하여 모델 결정에 각 기능이 미치는 영향을 이해하여 RL 기반 가격 모델의 해석 가능성을 향상시킵니다.
강화학습 환경 설정:
- 환경 초기화: 우리는 맞춤 gym 환경인 SalesPredictionEnv를 정의합니다. 이 환경은 소매 시장을 시뮬레이션합니다. 환경은 초기 가격과 할인을 입력으로 받고 진짜 판매 기능을 사용하여 판매를 시뮬레이션합니다. 액션 공간은 가격과 할인을 연속적으로 조정할 수 있으며 관찰 공간에는 현재 가격, 할인 및 예측된 판매가 포함됩니다.
class SalesPredictionEnv(gym.Env):
def __init__(self, initial_price, initial_discount, true_sales_function):
super(SalesPredictionEnv, self).__init__()
self.initial_price = initial_price
self.initial_discount = initial_discount
self.true_sales_function = true_sales_function
self.action_space = spaces.Box(low=-0.1, high=0.1, shape=(2,), dtype=np.float32)
self.observation_space = spaces.Box(low=0, high=np.inf, shape=(3,), dtype=np.float32)
self.price = self.initial_price
self.discount = self.initial_discount
self.sales = self.true_sales_function(self.price, self.discount)
self.done = False
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.price = self.initial_price
self.discount = self.initial_discount
self.sales = self.true_sales_function(self.price, self.discount)
return np.array([self.price, self.discount, self.sales], dtype=np.float32), {}
def step(self, action):
self.price += action[0]
self.discount += action[1]
new_sales = self.true_sales_function(self.price, self.discount)
reward = -abs(self.sales - new_sales)
self.sales = new_sales
self.done = False
return np.array([self.price, self.discount, self.sales], dtype=np.float32), reward, False, False, {}
def render(self, mode='human'):
print(f'Price: {self.price}, Discount: {self.discount}, Sales: {self.sales}')
진짜 판매 함수: 그런 다음 가격, 할인 및 판매 간의 관계를 모델링하는 판매 함수를 정의합니다. 이 함수는 강화학습(RL) 구현에서 소매 환경을 시뮬레이션할 수 있습니다. RL 에이전트가 다양한 가격과 할인 수준이 판매에 어떤 영향을 미치는지 이해할 수 있도록 합니다. 이 함수는 다음과 같이 공식화됩니다:
def true_sales_function(가격, 할인):
return -0.5 * 가격 ** 2 + 가격 + 11 + 2 * 할인
실제 세계의 강화학습 구현에서는 이러한 함수들이 종종 과거 판매 데이터, 경험적 연구 또는 도메인 전문 지식을 기반으로 실제 시장 행위를 모방하는 데 사용됩니다. 이 이차 함수 형태는 중간 가격 상승이 판매를 촉진할 수 있지만, 과도한 가격이나 할인은 전반적인 판매에 부정적인 영향을 미칠 수 있다.
환경 및 모델 설정: check_env를 사용하여 환경을 초기화합니다. 그런 다음 환경에 DDPG 에이전트를 설정합니다.
env = SalesPredictionEnv(initial_price=5.0, initial_discount=1.0, true_sales_function=true_sales_function)
check_env(env)
model = DDPG('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000)
SHAP 분석:
SHAP (Shapley Additive Explanations)은 각 특징이 예측에 미치는 영향을 양적으로 설명하여 모델을 해석 가능하게 합니다. RL 설정에서 SHAP를 구현하는 과정은 다음과 같습니다:
- SHAP를 위한 데이터 수집: 환경을 재설정하고 SHAP 분석을 위해 상태와 행동을 수집합니다.
obs, _ = env.reset()
states = []
actions = []
for _ in range(10):
action, _states = model.predict(obs)
obs, rewards, terminated, truncated, _ = env.step(action)
env.render()
states.append(obs)
actions.append(action)
states = np.array(states)
SHAP 예측 래퍼: SHAP의 올바른 출력 형식을 보장하기 위해 래퍼 함수를 정의합니다.
def predict_wrapper(observations):
predictions = []
for obs in observations:
action, _states = model.predict(obs)
predictions.append(action.flatten())
return np.array(predictions)
예측 DataFrame: 예측을 저장할 DataFrame을 생성하고 추가 분석을 위해 Excel 파일에 저장합니다.
predictions = {
'ID': list(range(len(states))),
'price': states[:, 0],
'discount': states[:, 1],
'sales': states[:, 2],
'predicted_action_0': [None] * len(states),
'predicted_action_1': [None] * len(states)
}
for idx, state in enumerate(states):
action, _states = model.predict(state)
predictions['predicted_action_0'][idx] = action[0]
predictions['predicted_action_1'][idx] = action[1]
predictions_df = pd.DataFrame(predictions)
predictions_df.to_excel("reinforcement_learning_predictions.xlsx", index=False)
print(predictions_df.head(10))
SHAP Explainer 및 Visualization: 우리는 SHAP를 사용하여 모델의 의사결정에 미치는 다른 feature들의 영향을 분석하고 결과를 시각화합니다.
explainer = shap.Explainer(predict_wrapper, states)
shap_values = explainer(states)
shap_values_price = shap_values[..., 0]
shap.plots.beeswarm(shap_values_price)
shap.plots.bar(shap_values_price[0])
상위 영향력 있는 feature들: 각 state의 상위 영향력 있는 feature들을 추출하여 DataFrame에 저장하여 쉬운 분석을 할 수 있습니다.
data = {
'ID': list(range(len(states))),
'price': states[:, 0],
'discount': states[:, 1],
'sales': states[:, 2],
'top_feature1': [None] * len(states),
'top_feature2': [None] * len(states),
'importance1': [None] * len(states),
'importance2': [None] * len(states)
}
features = ['price', 'discount', 'sales']
for i in range(len(states)):
sorted_indices = np.argsort(-np.abs(shap_values.values[i][:, 0]))
data['top_feature1'][i] = features[sorted_indices[0]]
data['importance1'][i] = shap_values.values[i][sorted_indices[0], 0]
if len(sorted_indices) > 1:
data['top_feature2'][i] = features[sorted_indices[1]]
data['importance2'][i] = shap_values.values[i][sorted_indices[1], 0]
reason_df = pd.DataFrame(data)
print(reason_df.head(10))
5. 분석과 인사이트
다음의 SHAP 막대 그래프는 Price(가격), Discount(할인) 및 Sales(판매)가 특정 인스턴스에 대한 모델의 가격 결정에 미치는 영향을 보여줍니다:
- SHAP 막대 그래프는 Price(가격), Discount(할인) 및 Sales(판매)가 특정 인스턴스에 대한 모델의 가격 결정에 미치는 영향을 보여줍니다:
- Sales(판매): 가장 높은 긍정적 영향을 나타내며, 높은 판매량이 모델이 가격과 할인을 유지하거나 높이는 데 강력한 영향을 미친다는 것을 시사합니다.
- Discount(할인): 높은 할인은 결과에 부정적인 영향을 미치며, 과도한 할인을 피하기 위해 할인액을 줄이는 것을 권장하는 모델의 결론으로 이어집니다.
- Price(가격): 약간의 긍정적 영향을 나타내며, 결과를 향상시키기 위해 가격을 약간 올리는 것을 선호하는 모델이고 판매량에 큰 영향을 미치지 않는다는 것을 나타냅니다.
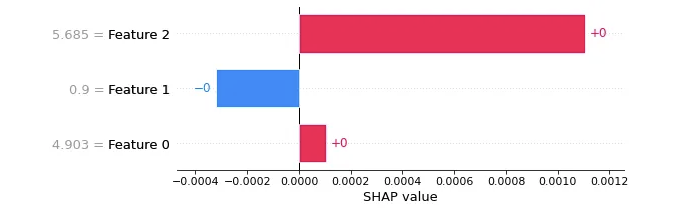
모델은 가격 책정 전략을 안내하기 위해 판매를 우선시하며, 수익을 극대화하기 위해 신중한 할인 관리와 약간의 가격 인상을 권장합니다. 막대 도표는 모델의 특정 사례에 대한 가격 결정에 영향을 미치는 Sales, Price 및 Discount가 어떻게 변하는지를 강조합니다.
다음은 SHAP beeswarm 도표로, 여러 사례에 걸쳐 Price, Discount 및 Sales가 모델의 가격 결정에 미치는 영향을 보여줍니다:
- Sales (Feature 2): 높은 값(빨강)은 모델의 출력을 증가시키고, 낮은 값(파랑)은 감소시킵니다.
- Price (Feature 0): 낮은 값(파랑)은 부정적인 영향을 미치며, 더 높은 값(빨강)은 긍정적인 영향을 미칩니다.
- Discount (Feature 1): 높은 값(빨강)은 모델의 출력을 감소시키고, 낮은 값(파랑)은 긍정적인 영향을 미칩니다.
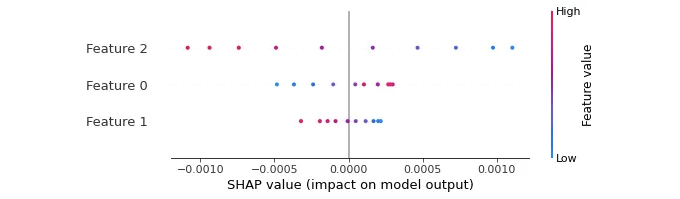
벌집 그림은 매출, 가격 및 할인이 모델의 결정에 미치는 영향이 여러 인스턴스에 걸쳐 어떻게 변하는지를 제공하여 그들이 모델의 결정에 미치는 중요성과 일관성을 강조합니다.
예측된 작업 테이블은 다른 기능에 대한 모델의 예측을 제시합니다:
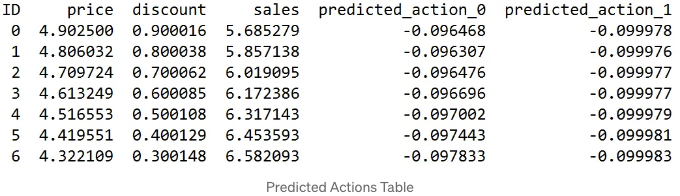
- 가격 조정: 가격에 대한 예측된 작업은 약간 부정적이며(예측 작업 0), 가격이 감소함에 따라 약간의 인하를 시사합니다.
- 할인 조정: 할인에 대한 예측된 작업(예측 작업 1)도 약간 부정적이며, 소폭의 감소를 나타냅니다. 모델은 수익성을 유지하기 위해 신중한 할인을 권장하는 일관된 경향을 보입니다.
- 매출 영향: 가격과 할인이 감소함에 따라 매출이 증가하며, 전형적인 시장 행동을 반영합니다. 모델이 가격과 할인을 약간 감소시킨 것은 수익성을 유지하면서 매출을 최적화할 수 있습니다.
Feature Importance Table은 각 인스턴스에 대해 모델 결정에 영향을 줄인 최상위 두 가지 기능과 그 중요도 값을 식별합니다:
- 판매량: 모든 인스턴스에서 가장 중요한 기능(top_feature1)으로 일관되게 나타납니다.
- 가격 및 할인: 교체 가능 기능(top_feature2)은 다양한 중요도 값을 가지며, 판매량에 높은 중요도 값이 해당 기능이 모델 예측에 미치는 강력한 영향을 나타냅니다.
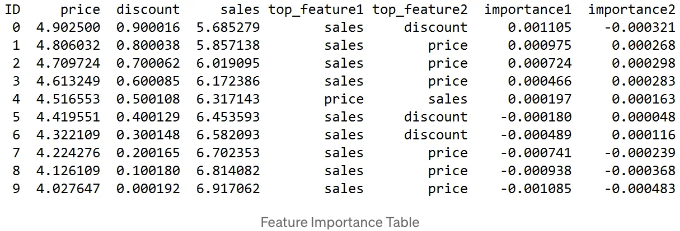
요약하면, 판매가격은 모델의 가격 결정에서 우세한 요소이며, 가격 및 할인은 보조이지만 중요한 역할을 합니다.
6. 결론
본 연구는 소매 가격 전략을 최적화하기 위해 Deep Deterministic Policy Gradient (DDPG) 알고리즘을 활용합니다. 강화 학습 (RL)과 SHAP (Shapley Additive Explanations)을 결합하여 가격 및 할인을 조정하여 매출과 이익을 극대화할 수 있습니다.
장점:
- 적응성: 전통적인 가격 모델과 달리 RL은 실시간 데이터로부터 계속 학습하여 시장 변화에 즉각 대응할 수 있습니다.
- 정밀성: DDPG의 연속적인 행동 공간은 섬세한 가격 결정을 가능하게 합니다.
- 통찰력: SHAP 값은 다양한 요인의 영향에 대한 설명 가능한 통찰력을 제공하여 의사 결정 투명성을 향상시킵니다.
단점:
- 복잡성: 강화 학습 모델을 구현하는 데는 상당한 컴퓨팅 자원과 전문 지식이 필요합니다.
- 데이터 의존성: 강화 학습의 효과는 사용 가능한 데이터의 품질과 양에 매우 의존합니다.
- 안정성: 동적 환경에서 안정적인 학습을 보장하는 것은 어려울 수 있으며 하이퍼파라미터를 세심히 조정해야 합니다.
개선 제안:
- 혼합 모델: 강화 학습과 전통적 최적화 방법을 결합함으로써 안전성과 성능을 향상시킬 수 있습니다.
- 향상된 데이터 통합: 고객 피드백 및 경쟁사 가격과 같은 다양한 데이터 원본을 통합하여 모델의 정확성을 향상시킬 수 있습니다.
- 확장성: 확장 가능한 강화 학습 프레임워크를 개발하여 소매 세그먼트와 시장 전반에 이러한 방법을 도움이 될 수 있습니다.
- 지속적인 모니터링: 비즈니스 목표 및 시장 조건과 일치하는 모델의 결정을 보장하기 위해 모니터링 및 검증 프로세스를 구현합니다.
GitHub의 내 저장소에 있는 Python 스크립트는 다음과 같습니다: datalev001/Reinforcement_price