
소개
이전 글에서 기본 데이터 구조에 대해 논의했습니다.
- 이 글에서는 몇 가지 일반적인 데이터 구조 (연결 리스트, 큐, 스택, 해시 테이블, 이진 트리, 이진 힙)의 JavaScript 구현을 살펴보았습니다.
- 이 시리즈에서는 프린스턴의 기본 데이터 구조에 대한 구체적인 내용을 Java 구현을 통해 배웠습니다.
기본 데이터 구조 이외에도 여전히 유용한 데이터 구조가 있습니다. 이러한 데이터 구조들은 우리 애플리케이션의 성능을 향상시키는 데 도움이 될 수 있습니다.
안내
본 글에서는 두 가지 데이터 구조를 고려하여 실제 프론트엔드 애플리케이션 사례를 개선해보겠습니다.
- Trie (접두사 트리)
- 그래프 — 인접 리스트 표현
1. Trie (접두사 트리)
다음 스크린샷은 자동 완성 검색 바에서 가져온 것입니다. 제가 배열에 단어들을 넣어 후보 제시 항목으로 사용했어요. 실제로 목록에서 단어를 검색할 때 성능이 아주 좋지 않다고 해요. (소스 코드를 확인해주세요)
성능을 향상시킬 수 있는 방법이 있을까요?
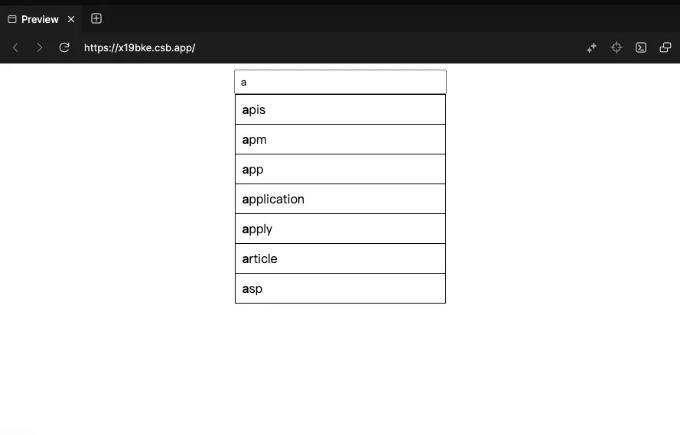
- 위 케이스의 원본 솔루션은 후보 항목을 배열에 저장하는 것입니다. 배열을 필터링하여 동일한 접두사를 가진 항목을 검색하는 데 걸리는 시간은 O(L)입니다. 여기서 L은 배열의 길이입니다.
- 성능을 개선하기 위해 후보 항목을 Trie 구조에 저장할 수 있습니다. 이 경우 단어의 길이를 나타내는 n에 대해 O(n)이 걸립니다.
Trie의 정의
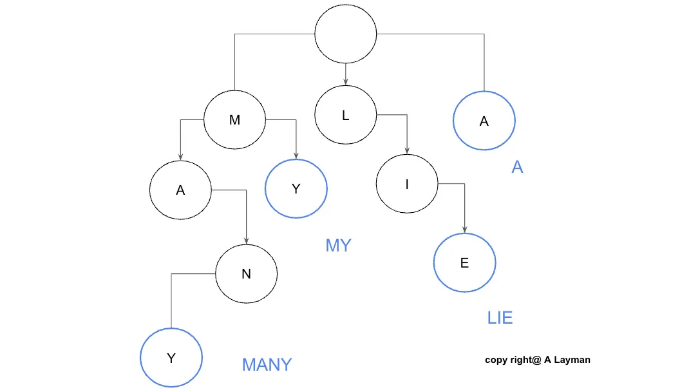
구현 방법
TypeScript에서 어떻게 작동하는지 확인해 보겠습니다.
- TrieNode 구조 만들기
- 역할
-
- HashTable을 사용하여 자식을 효율적으로 저장, 검색 및 나열함 (O(1))
-
- addChild는 쉽게 단일 가지를 탐색할 수 있도록 자식을 반환해야 함
-
- 문자가 단어의 끝인 경우 isCompleted를 true로 표시합니다. 그 노드 아래에 새로운 자식이 추가될 때 업데이트됩니다.
-
- Trie 구조 만들기
- 책임
- TrieNode의 인스턴스를 소유하여 단어 삽입, 단어 검색 및 특정 접두사로 단어 확인 수행
- Trie에 단어 삽입
- addWord는 자식을 재귀적으로 추가하는 것을 목표로 한다.
- 이는 연결 리스트를 탐색하는 방법과 유사하다. 자식을 추가하고 입력 문자열의 끝에 도달할 때까지 포인터를 자식으로 이동시킨다.
- 성능
- 시간 복잡도: O(n), n은 단어의 길이이다.
- 공간 복잡도: O(1)
- Trie에서 단어 검색
- getLastCharacterNode 함수는 입력 문자열의 끝에 도달했을 때에만 노드를 검색하고, 그 외의 경우에는 null을 반환합니다.
- 성능
- 시간 복잡도: O(n), 여기서 n은 문자열의 길이입니다.
- 공간 복잡도: O(1)
- Trie에서 단어 검색하기 (DFS 사용)
- getLastCharacterNode를 사용하여 검색하는 단점은 다음 자식 노드를 찾을 수 없다면 작동을 멈출 수 있다는 것입니다.
- 예를 들어, abc를 삽입한 후 a.c인 경우 true를 반환해야 하는 새로운 요구 사항이 있다고 가정해보겠습니다.
- 대안적인 해결책은 다음 글자가 .인 경우에는 모든 다음 자식을 시도하는 것입니다.
- Trie에서 특정 접두어를 가진 단어가 있는지 확인하기
- 마지막 문자 노드를 얻은 후 getSuggestedNextCharacters 목록의 자식 키
- 성능
- 시간 복잡성: O(n), n은 단어의 길이입니다.
- 공간 복잡성: O(1)
2. 그래프 — 인접 리스트 표현
그래프 시각화 예시가 있습니다. 이 그래프를 탐색하는 새로운 요구 사항이 있다면 우리 코드의 성능이 나빠질 수 있습니다. (소스 코드 확인)
성능을 향상시킬 방법이 있을까요?

- 현재 소스 코드에는 순회 알고리즘이 구현되어 있지 않습니다. 만약 구현해야 한다면, O(V * E)가 걸릴 것입니다. 여기서 V는 노드의 수이고, E는 간선의 수입니다(각 노드마다 해당 노드의 이웃 노드를 얻기 위해 모든 간선을 확인해야 합니다).
- 성능을 개선하기 위해 데이터 구조를 재구성하고 인접 리스트를 만듭니다. 이는 O(V + E)가 소요됩니다. 여기서 V는 노드의 수이고, E는 그래프 순회에 필요한 간선의 수입니다.
정의
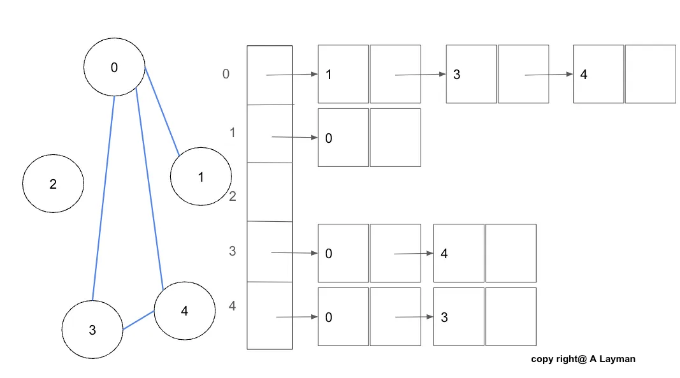
구현
TypeScript에서 어떻게 작동하는지 확인해 봐요.
- Edge 구조체를 만들기
- Edge는 두 개의 노드 사이의 연결이에요
- 역할
- 노드와의 관계 확인: hasSourceNode 및 hasTargetNode는 노드가 Edge의 일부인지 아닌지 확인할 수 있어요 (라인 14 ~ 20)
- 노드 구조 생성하기
- 노드는 엣지의 출발지 또는 도착지입니다.
- 책임
-
- 링크드 리스트를 사용하여 이웃 엣지를 효율적으로 저장 및 검색합니다 (O(n)) (라인 26 ~ 42)
-
- 노드와의 관계를 기반으로 차수, 인바운드 차수, 아웃바운드 차수를 제공합니다 (라인 8 ~ 20)
-
- 그래프 구조
- 그래프는 노드와 엣지로 이루어진 비선형 데이터 구조입니다.
- 책임
-
- 노드와 엣지를 저장합니다.
-
- 노드와 엣지에 대한 작업을 수행합니다 (예: 추가, 탐색 등).
-
- 그래프 순회
두 가지 종류의 순회가 있습니다. 너비 우선 탐색 (라인 731)과 깊이 우선 탐색 (라인 3651).
- 목적:
- BFS: 다음 레이어 방문 전에 모든 이웃을 걸어다닌다
- DFS: 모든 이웃을 걸어다니기 전에 가장 먼 레이어에 도착
- 시간 복잡도:
- BFS, 너비 우선 탐색: O(V + E), V는 노드 수, E는 간선 수
- DFS, 깊이 우선 탐색: O(V + E), V는 노드 수, E는 간선 수
- 공간 복잡도:
- BFS, 너비 우선 탐색: O(V), V는 노드 수
- DFS, 깊이 우선 탐색: O(V), V는 노드 수
참고
- Trie 데이터 구조 이해하기
- 해시 테이블 대 트라이 (접두사 트리)
- 트라이 데이터 구조 | 삽입 및 검색
- 그래프 알고리즘 재방문
- 그래프
요약
기다려 주셔서 감사합니다. 저는 션입니다. 소프트웨어 엔지니어로 일하고 있어요.
이 글은 제 노트입니다. 만약에 어떤 실수가 있다면 자유롭게 조언해주세요. 당신의 피드백을 기다리고 있어요.
-
저를 구독해 주세요
-
기사를 공유하는 페이스북 페이지
-
최신 사이드 프로젝트: 매일 학습
관련 주제
두방향 바인딩을 Knout.js와 ReactJS에서 어떻게 사용하는지 알아보세요!
SignalR을 사용하여 채팅방 애플리케이션을 만드는 방법을 배워보세요.
'효과적인 SQL'에 대한 내 반성:
IT 및 네트워크:
데이터베이스: