이 기사에서는 기초 및 주식 세부 정보에 따라 주식을 순위로 나열할 것입니다. 이 접근 방식은 기존 기사 "Python API를 사용한 기초 주식 분석"에서 주식 그룹의 평균과 표준 편차를 기반으로 비율에 대한 점수 방법을 적용합니다.
면책 조항: 여기서 제공된 정보는 정보 목적으로만 제공되며 개인 재정, 투자 또는 기타 조언을 의도한 것이 아닙니다.
이 기사에서 사용되는 주요 비율은 다음과 같습니다:
- EPS (주당순이익) — 회사 이익 중 각 주식에 할당된 부분
- PE (주가 수익 비율) — 회사의 주가와 주당 순이익 간 관계. 투자자가 해당 섹터의 다른 종목에 비해 주식이 저평가되었는지 또는 고평가되었는지 판단하는 데 도움이 됩니다.
- PEG (예상 이익 성장률) — 주식의 P/E를 예상된 12개월 수익 성장률로 나눈 것. 일반적으로 1보다 낮은 PEG는 좋은 신호이며, 2보다 높은 PEG는 주식이 과도 가격화될 수 있음을 나타냅니다.
- PB (주가순자산가치비율) — 1의 비율은 회사의 주식이 순자산가치에 준하는 가격에 거래되고 있음을 나타냅니다. 1보다 높은 P/B는 회사가 순자산가치에 프리미엄을 지불하고 있음을 시사하며, 1보다 낮은 비율은 회사 자산에 비해 저평가된 주식을 나타낼 수 있습니다.
- ROE (자기자본이익률) — 회사가 자산을 이용하여 이익을 창출하는 데 효과적으로 활용하는 방법을 투자자에게 제공합니다. 더 높은 ROE는 주주 자본을 더 효과적으로 활용하고 주식 수요 증가 및 미래 이익 증가, 그리고 주가 상승으로 이어질 수 있음을 나타냅니다.
- ROCE (총 자본 대지수이익률) — 모든 자본을 기준으로 회사의 수익성을 측정합니다.
- FCFY (재무건전도 비율) — 회사가 주당 기대하는 영업현금흐름과 주당 시장가치를 비교하는 지표. 낮은 비율은 덜 매력적인 투자 기회를 나타냅니다.
- D2E (부채대자본비) — 회사의 총부채를 자기자본과 비교합니다.
- CR (유동비율) — 회사가 유동자산(1년 이내 지급 예정 금액)으로 현재 부채를 갚을 수 있는 능력을 측정합니다. 비율이 높을수록 회사의 유동성이 더 좋습니다.
- QR (당좌비율) — 회사가 재고를 판매하거나 추가 자금을 조달하지 않고 현재 부채를 갚을 수 있는 능력을 측정합니다.
- 자산TO (자산회전율) — 회사 자산이 매출이나 수익을 생성하는 효율성을 측정합니다.
- DY (배당수익률) — 회사가 매년 배당으로 지급하는 금액을 주가에 상대적으로 측정한 비율. 이는 주식 투자의 배당수익률을 추정한 지표입니다.
- 베타 — 주식의 시장 전체 대비 변동성을 측정하는 지표. 시장보다 더 많이 변동하는 주식은 1.0보다 높은 베타를 가집니다. 시장보다 변동성이 낮은 주식은 1.0보다 낮은 베타를 가집니다.
- 52주 범위 — 52주 저점에 가까운 주식과 52주 고점에 가까운 주식을 나타내는 시각화 지표. 예를 들어, 90%는 현재 가격이 52주 고점에 매우 가깝다는 것을 나타냅니다.
- 점수 — 각 주식의 비율 점수 합계
데이터 접근
우리는 yfinance API를 활용하여 Yahoo Finance에서 데이터를 수집할 것입니다. 티커의 info 구성 요소는 여러 구성 요소 중 하나인 (예: 손익 계산서, 현금 흐름 등) 가장 많은 비율들을 제공할 것입니다.
우리는 finviz screener를 웹 스크레이핑하여 관련 주식 심볼 목록을 얻을 것입니다. 연구가 동일 산업의 이상적으로 비슷한 주식 그룹에서 수행되어야 합니다.
코드는 GitHub의 Jupyter 노트북으로 사용 가능합니다.
Python 라이브러리
다음은 필수 Python 라이브러리입니다:
- yfinance — 금융 시장 데이터에 접근하기 위함
- pandas — 데이터 프레임
- numpy — np.nan을 사용함
- requests — http 요청을 만들기 위함
- BeautifulSoup — 웹 스크래핑에 사용됨
- statistics — 표준편차와 평균을 계산하기 위함
라이브러리 가져오기
# 주식 정보 읽기
import yfinance as yf
# DataFrame을 위해
import pandas as pd
import numpy as np
# finviz를 파싱하기 위해
import requests
from bs4 import BeautifulSoup
# 표준 편차와 평균을 계산하기 위해
import statistics
비율 카테고리
비율은 두 그룹으로 나뉩니다: 카테고리 1에는 낮은 값을 선호하는 비율들이 포함되고, 카테고리 2에는 높은 값을 선호하는 비율들이 포함됩니다. 주가 이익비율 (P/E)은 카테고리 1의 예시 비율입니다. 낮은 P/E 비율은 회사가 저렴하거나 역사적 패턴과 비교하여 잘 수행하고 있다는 것을 시사할 수 있습니다. 현금비율 (CR)은 카테고리 2의 예시로, 높은 CR 점수가 바람직합니다. 우리는 거래가 덜 변동적인 회사에 더 관심이 있으므로 베타 점수는 카테고리 1에 속합니다. 그러나 만약 높은 변동성을 가진 회사에 더 관심이 있다면 카테고리 2로 이동할 수 있습니다.
# 카테고리 1 비율 점수 - 낮을수록 더 좋음
CAT1_RATIOS = ['D2E', 'PEG', 'PE fwd', 'PB', 'Beta']
# 카테고리 2 비율 점수 - 높을수록 더 좋음
CAT2_RATIOS = ['ROCE', 'ROE', 'FCFY', 'CR', 'QR', 'Asset TR', 'EPS fwd']
주식 심볼
이전에 언급한대로, 관련 주식 심볼 목록을 얻기 위해 finviz 스크리너를 사용할 것입니다. 아래 코드는 예를 들어, 시가총액이 20억 달러 이상인 "관리되는 가스" 산업의 "유틸리티" 섹터 기업을 위한 필터를 활용하는 것입니다. 요청 매개변수 "f"에는 아래와 같이 필터 값을 받습니다.
def get_symbols():
req = requests.get('https://finviz.com/screener.ashx',
params={
'v': '111',
'f': 'cap_midover,ind_utilitiesregulatedgas',
'o': 'company',
},
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
})
# BeautifulSoup 객체 생성
soup = BeautifulSoup(req.text, 'html.parser')
# 관심 있는 테이블
table = soup.find('table', class_='styled-table-new is-rounded is-tabular-nums w-full screener_table')
# 심볼 수집 배열
symbols = []
for i, row in enumerate(table.find_all('tr')):
# 헤더 행은 건너뛰기
if i != 0:
# 행에서 반복
for j, td in enumerate(row.find_all('td')):
# 심볼은 두 번째 열에 있음
if j == 1:
symbols.append(td.text.strip())
break
return symbols
주식 심볼 가져오기
위의 유틸리티 메소드를 호출하여 symbols 변수를 채우세요.
symbols = get_symbols()
get_symbols 함수를 사용하지 않고 이미 주식 심볼 집합을 알 경우 symbols 변수를 초기화할 수도 있습니다. 아래와 같이 표시됩니다:
symbols = ['ATO', 'NI', ]
비율 계산하기
먼저 유틸리티를 정의하여 yfinance API의 info 메서드를 활용하여 비율을 계산하고 채워넣습니다.
def populate_with_info(data, stock_info):
# print(stock_info)
data['Symbol'].append(stock_info['symbol'])
data['Name'].append(stock_info['longName'])
# 숫자를 가독성 좋은 형식으로 변환합니다
data['Market Cap'].append(human_format(stock_info['marketCap']))
data['Price'].append(stock_info['currentPrice'])
# 사용 가능한 지표가 없을 수도 있습니다; 그런 경우 NaN을 사용합니다
# 가치 평가 비율
if 'priceToBook' in stock_info:
data['PB'].append(stock_info['priceToBook'])
else:
data['PB'].append(np.nan)
if 'forwardEps' in stock_info:
data['EPS fwd'].append(stock_info['forwardEps'])
else:
data['EPS fwd'].append(np.nan)
if 'forwardPE' in stock_info:
data['PE fwd'].append(stock_info['forwardPE'])
else:
data['PE fwd'].append(np.nan)
if 'pegRatio' in stock_info:
data['PEG'].append(stock_info['pegRatio'])
else:
data['PEG'].append(np.nan)
# 신뢰성 재무 비율
if 'debtToEquity' in stock_info:
data['D2E'].append(stock_info['debtToEquity'])
else:
data['D2E'].append(np.nan)
# 수익성 비율
if 'returnOnEquity' in stock_info:
data['ROE'].append(stock_info['returnOnEquity'])
else:
data['ROE'].append(np.nan)
if ('freeCashflow' in stock_info) and ('marketCap' in stock_info):
fcfy = (stock_info['freeCashflow']/stock_info['marketCap']) * 100
data['FCFY'].append(round(fcfy, 2))
else:
data['FCFY'].append(np.nan)
# 유동성 비율
if 'currentRatio' in stock_info:
data['CR'].append(stock_info['currentRatio'])
else:
data['CR'].append(np.nan)
if 'quickRatio' in stock_info:
data['QR'].append(stock_info['quickRatio'])
else:
data['CR'].append(np.nan)
# 기타 정보 (비 비율)
if 'dividendYield' in stock_info:
data['DY'].append(stock_info['dividendYield']*100)
else:
data['DY'].append(0.0)
if 'beta' in stock_info:
data['Beta'].append(stock_info['beta'])
else:
data['Beta'].append(np.nan)
if 'fiftyTwoWeekLow' in stock_info:
data['52w Low'].append(stock_info['fiftyTwoWeekLow'])
else:
data['52w Low'].append(np.nan)
if 'fiftyTwoWeekHigh' in stock_info:
data['52w High'].append(stock_info['fiftyTwoWeekHigh'])
else:
data['52w High'].append(np.nan)
비율을 찾을 수 없는 경우, NaN으로 사전에 추가됩니다. 비율이 NaN으로 설정된 주식은 제거됩니다. 또한 이 방법은 숫자를 사람이 읽을 수 있는 형식으로 변환하는 유틸리티 메서드를 활용합니다. 예를 들어, 5B(십억), 5M(백만) 등으로 표시됩니다.
def human_format(num):
num = float('{:.3g}'.format(num))
magnitude = 0
while abs(num) >= 1000:
magnitude += 1
num /= 1000.0
return '{}{}'.format('{:f}'.format(num).rstrip('0.'), ['', 'K', 'M', 'B', 'T'][magnitude])
마지막으로, 재무상태표와 손익계산서를 사용하여 비율을 계산하는 추가 기법 집합이 있습니다.
def roce(ticker):
income_stm = ticker.income_stmt
ebit = income_stm.loc['EBIT'].iloc[0]
bs = ticker.balance_sheet
return ebit/(bs.loc['Total Assets'].iloc[0]-bs.loc['Current Liabilities'].iloc[0])
def asset_turnover_ratio(ticker):
df_bs = ticker.balance_sheet
y0, y1 = df_bs.loc['Total Assets'].iloc[0], df_bs.loc['Total Assets'].iloc[1]
avg_asset = (y0 + y1)/2
tot_rvn_y0 = ticker.income_stmt.loc['Total Revenue'].iloc[0]/avg_asset
return tot_rvn_y0
def investory_turnover_ratio(ticker):
df_bs = ticker.balance_sheet
y0, y1 = df_bs.loc['Inventory'].iloc[0], df_bs.loc['Inventory'].iloc[1]
avg_inventory = (y0 + y1)/2
return ticker.income_stmt.loc['Cost Of Revenue'].iloc[0]/avg_inventory
지표 수집
주식 심볼에 대한 각 지표를 딕셔너리에 추가해 보겠습니다.
# 나중에 DF를 만들기 위한 데이터 수집 딕셔너리
data = {
'Symbol': [],
'Name': [],
'Market Cap': [],
'EPS fwd': [],
'PE fwd': [],
'PEG': [],
'PB': [],
'ROE' : [],
'ROCE' : [],
'FCFY' : [],
'D2E' : [],
'CR' : [],
'QR' : [],
'Asset TR': [],
'DY' : [],
'Beta': [],
'Price': [],
'52w Low': [],
'52w High': []
}
industry = ''
for symbol in symbols:
ticker = yf.Ticker(symbol)
if not industry:
industry = ticker.info['industry']
else:
industry_current = ticker.info['industry']
if industry_current != industry:
print(f'다른 산업 {industry_current}을(를) 만났습니다, 이전 산업 {industry}입니다. 중단합니다.')
break
populate_with_info(data, ticker.info)
data['ROCE'].append(roce(ticker))
data['Asset TR'].append(asset_turnover_ratio(ticker))
이전에 언급한대로, 이 방법에는 현재 주식의 산업이 이전 주식의 산업과 다른지 간단히 확인하는 절차가 포함되어 있습니다.
DataFrame 생성하기
# 사전을 사용하여 DF 생성
df = pd.DataFrame(data)
# NaN 값을 가진 주식 저장
df_exceptions = df[df.isna().any(axis=1)]
# NaN 값을 가진 주식 제거
df = df.dropna()
# NaN 값을 가진 행을 삭제한 후 인덱스 재설정
df.reset_index(drop=True, inplace=True)
# 52주간 가격 범위 추가
df['52주 범위'] = ((df['가격'] - df['52주 최저가']) / (df['52주 최고가'] - df['52주 최저가'])) * 100
df_exceptions
NaN으로 설정된 비율이 있는 주식은 제거되고, 예외 DataFrame에 저장됩니다. 마지막으로 52주 가격 범위가 포함될 것입니다.

"그리고 비예외 주식에 대한 결과는:
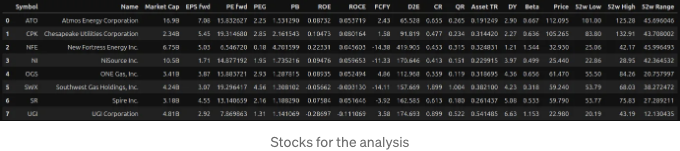
점수
다음 단계는 원시 데이터에 점수를 적용하는 것입니다."
def score(values, value, cat) -> int:
'''
카테고리에 따라 표준 편차와 평균을 기반으로 점수를 계산합니다. 낮은 값을 선호하는 PE와 같은 비율의 경우, 다음과 같이 점수가 계산됩니다:
1. 주어진 PE가 -1 표준 편차와 평균 사이에 있는 경우 1점 반환
2. 주어진 PE가 -2 표준 편차와 -1 표준 편차 사이에 있는 경우 2점 반환
3. PE가 -2 표준 편차를 벗어나는 경우 3점 반환
4. 주어진 PE가 1 표준 편차와 평균 사이에 있는 경우 -1점 반환
5. 주어진 PE가 +1 표준 편차와 +2 표준 편차 사이에 있는 경우 -2점 반환
6. 주어진 PE가 +2 표준 편차를 벗어나는 경우 -3점 반환
높은 값을 선호하는 ROE와 같은 비율의 경우, 다음과 같이 점수가 계산됩니다:
1. 주어진 ROE가 평균과 +1 표준 편차 사이에 있는 경우 1점 반환
2. 주어진 ROE가 +1 표준 편차와 +2 표준 편차 사이에 있는 경우 2점 반환
3. ROE가 +2 표준 편차를 벗어나는 경우 3점 반환
4. 주어진 ROE가 -1 표준 편차와 평균 사이에 있는 경우 -1점 반환
5. 주어진 ROE가 -1 표준 편차와 -2 표준 편차 사이에 있는 경우 -2점 반환
6. 주어진 ROE가 -2 표준 편차를 벗어나는 경우 -3점 반환
Parameters
----------
values : 값들의 목록
value: 평균, 1 표준 편차, -1 표준 편차, 2 표준 편차 또는 -2 표준 편차 내에 있는지 확인할 값
cat: 카테고리 유형, 유효한 값은 1 또는 2입니다.
Returns
-------
score: 주어진 'value'에 대한 점수
'''
std = statistics.stdev(values)
mean = statistics.mean(values)
if cat == 1:
if (mean + (-1 * std)) < value <= mean:
return 1
elif (mean + (-2 * std)) < value <= (mean + (-1 * std)):
return 2
elif value <= (mean + (-2 * std)):
return 3
elif mean < value <= (mean + (1 * std)):
return -1
elif (mean + (1 * std)) < value <= (mean + (2 * std)):
return -2
else:
return -3
else:
if mean <= value < (mean + (1 * std)):
return 1
elif (mean + (1 * std)) <= value < (mean + (2 * std)):
return 2
elif value >= (mean + (2 * std)):
return 3
elif (mean + (-1 * std)) <= value < mean:
return -1
elif (mean + (-2 * std)) <= value < (mean + (-1 * std)):
return -2
else:
return -3
요약하면 다음과 같이 카테고리 1의 비율에 제공되는 값에 대해 다음 점수가 반환됩니다: (평균 - 1 * 표준 편차)과 평균 사이에 비율이 있는 경우 1; (평균 - 2 * 표준 편차)와 (평균 - 1 * 표준 편차) 사이에 비율이 있는 경우 2; (평균 - 2 * 표준 편차)보다 작은 경우 3; 그 반대 경우에는 음수 값이 반환됩니다. 카테고리 2도 비슷한 절차를 따르지만 반대 방향으로 작동합니다. 이러한 점수는 어느 정도 임의적이며, 이상값은 최대 또는 최소 점수를 받습니다. 이상값으로 인한 편향을 제거하려면, 이상값에 대한 점수를 조정하여, 예를 들어 평균 - 2 * 표준 편차보다 낮은 비율의 경우 0을 반환하는 등의 조치를 취할 수 있습니다.
점수 부여를 적용하고, 두 카테고리에 대해 제공된 각 비율에 대한 점수를 합산하는 열을 추가합니다.
df_score = df.copy()
for col in CAT1_RATIOS:
for index, value in df[col].items():
# print(f'{col} - {index} - {value}')
df_score.loc[index, col] = score(df[col], value, 1)
for col in CAT2_RATIOS:
for index, value in df[col].items():
# print(f'{col} - {index} - {value}')
df_score.loc[index, col] = score(df[col], value, 2)
# 총점을 얻기 위해 순위 점수를 추가
df_score['Score'] = df_score[CAT1_RATIOS+CAT2_RATIOS].sum(axis=1)
def make_pretty(styler):
# 열 형식 지정
styler.format({'EPS fwd': '{:.0f}', 'PE fwd': '{:.0f}', 'PEG': '{:.0f}', 'FCFY': '{:.0f}', 'PB': '{:.0f}', 'ROE': '{:.0f}',
'ROCE': '{:.0f}', 'D2E': '{:.0f}', 'CR': '{:.0f}', 'QR': '{:.0f}', 'Asset TR': '{:.0f}', 'DY': '{:.2f}%',
'Beta': '{:.0f}', '52w Low': '${:.2f}', 'Price': '${:.2f}', '52w High': '${:.2f}', '52w Range': '{:.2f}%', 'Score': '{:.0f}'
})
# 바 시각화 설정
styler.bar(subset=['52w Range'], align="mid", color=["salmon", "cornflowerblue"])
# 그리드
styler.set_properties(**{'border': '0.1px solid black'})
# 배경 그라데이션 설정
for ratio in CAT1_RATIOS:
styler.background_gradient(subset=[ratio], cmap='RdYlGn', gmap=-df[ratio])
for ratio in CAT2_RATIOS:
styler.background_gradient(subset=[ratio], cmap='RdYlGn')
styler.background_gradient(subset=['Score'], cmap='PiYG')
# 인덱스 숨기기
styler.hide(axis='index')
# 일부 열에 대해 왼쪽 텍스트 정렬
styler.set_properties(subset=['Symbol', 'Name'], **{'text-align': 'left'})
styler.set_properties(subset=CAT1_RATIOS + CAT2_RATIOS + ['Market Cap', 'Score'], **{'text-align': 'center'})
return styler
마지막으로, DataFrame에 스타일을 추가합니다:
# DF에 테이블 캡션 및 스타일 추가
df_score.style.pipe(make_pretty).set_caption(f'{industry} 주식 스크리너').set_table_styles(
[{'selector': 'th.col_heading', 'props': 'text-align: center'},
{'selector': 'caption', 'props': [('text-align', 'center'),
('font-size', '11pt'), ('font-weight', 'bold')]}])
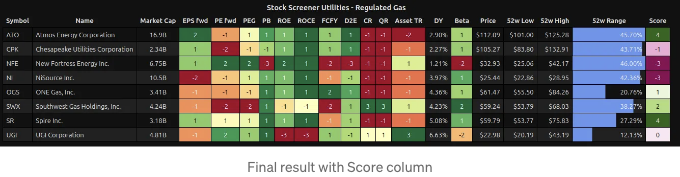
시가총액이 20억 달러 이상인 ATO와 SR은 “Regulated Gas” 산업 중 모든 주식 중에서 가장 높은 점수를 받은 두 가지 유틸리티 섹터 주식입니다. 그러나 ATO의 가격은 현재 52주 최고가에 더 가깝고, SR의 가격은 52주 최저가에 더 가깝습니다.
여러 비율이 현재 주식 가격에 의존하기 때문에 결과는 노트북을 호출하는 시점에 따라 변할 수 있습니다.
결론
이 기사에서는 기초 분석 기반의 주식 순위 결정 방법을 설명하며, 이 방법은 주식 그룹의 평균과 표준 편차를 기반으로 각 비율에 점수를 할당합니다.
분석 목적상, 대부분의 비율은 비슷한 주식 그룹 내에서만 의미가 있는 경우가 많으므로 관련된 주식 그룹을 선택하는 것이 중요합니다.
평가 시스템이 임의적이지만, 이 포스트가 가중 점수와 같은 다른 점수 시스템을 탐구하는 기초를 제시한다고 생각합니다.
정보가 유익하게 느껴졌길 바라며, 피드백을 소중히 여깁니다.