생성적 AI

배경
대형 언어 모델 또는 다른 생성 모델을 생각할 때, 먼저 떠오르는 하드웨어는 GPU입니다. GPU 없이는 생성적 AI, 기계 학습, 심층 학습, 데이터 과학 등의 많은 발전이 불가능했을 것입니다. 15년 전, 게이머들이 최신 GPU 기술에 열광했다면, 오늘날 데이터 과학자와 기계 학습 엔지니어들도 이 분야의 소식을 따라가며 함께 관심을 가지고 있습니다. 보통 게이머들과 기계 학습 사용자는 서로 다른 종류의 GPU와 그래픽 카드를 사용한다고 볼 수 있습니다.
게임 사용자들은 일반적으로 소비자용 그래픽 카드(예: NVIDIA GeForce RTX 시리즈 GPU)를 사용하고, ML 및 AI 개발자들은 주로 데이터 센터 및 클라우드 컴퓨팅 GPU(예: V100, A100 또는 H100)에 대한 뉴스를 따릅니다. 게임 그래픽 카드는 일반적으로 GPU 메모리가 훨씬 적습니다(2024년 1월 기준 최대 24GB). 반면 데이터 센터 GPU는 일반적으로 40GB에서 80GB 정도의 범위에 있습니다. 또한 가격도 다른 중요한 차이점입니다. 대부분의 소비자용 그래픽 카드의 가격이 최대 3000달러가 될 수 있는 반면, 대부분의 데이터 센터 그래픽 카드는 그 가격부터 시작하여 수십만 달러까지 쉽게 올라갈 수 있습니다.
저를 포함한 많은 사람들이 그래픽 카드를 게임이나 일상적인 용도로 사용할 수 있기 때문에, 같은 그래픽 카드를 사용하여 LLM 모델의 학습, 미세 조정 또는 추론에 사용할 수 있는지 궁금할 수 있습니다. 2020년에 저는 소비자용 그래픽 카드를 데이터 과학 프로젝트에 사용할 수 있는지에 대해 포괄적인 기사를 썼습니다. 당시에는 대부분 작은 ML이나 딥 러닝 모델이었고, 6GB 메모리를 가진 그래픽 카드라도 많은 학습 프로젝트를 처리할 수 있었습니다. 그러나 본 기사에서는 수십억 개의 매개변수를 가진 대형 언어 모델에 이러한 그래픽 카드를 사용할 것입니다.
본 기사에서는 24GB GPU 메모리를 가진 GeForce 3090 RTX 카드를 사용했습니다. 참고로, A100 및 H100과 같은 데이터 센터 그래픽 카드는 각각 40GB 및 80GB의 메모리를 가지고 있습니다. 또한 전형적인 AWS EC2 p4d.24xlarge 인스턴스는 총 320GB의 GPU 메모리를 가진 8개의 GPU(V100)를 가지고 있습니다. 간단한 소비자용 GPU와 전형적인 클라우드 ML 인스턴스 간의 차이가 상당히 크다는 것을 보실 수 있습니다. 그러나 질문은, 우리가 단일 소비자용 그래픽 카드에서 대형 모델을 학습할 수 있는지 여부인데요? 가능하다면, 팁과 교훈은 무엇인가요? 이 기사의 나머지 부분을 읽어보세요.
아무런 LLM 모델이나 교육 데이터 집합을로드하기 전에 그러한 프로세스에 필요한 하드웨어 및 소프트웨어를 찾아야합니다.
언급한 바와 같이, 나는 소비자 GPU 중에서도 가장 높은 메모리(24GB) 중 하나를 갖고 있는 NVIDIA GeForce RTX 3090 GPU를 사용했습니다(참고로, 4090 모델도 동일한 메모리 크기를 가지고 있습니다). 이 GPU는 유명한 A100 GPU에 있는 것과 동일한 Ampere 아키텍처를 기반으로 하고 있습니다. GeForce RTX 3090 GPU 사양에 대해 더 자세히 알아볼 수 있습니다.
모든 테스트를 거친 후, 24GB가 10억 개의 매개변수를 갖는 LLM과 작업을 수행하는 데 필요한 최소한의 GPU 메모리라고 생각합니다.

그래픽 카드 외에도 PC의 좋은 환기 시스템이 필요합니다. 세밀한 조정 중에 GPU의 온도가 쉽게 올라가고 팬으로는 충분히 식힐 수 없는 경우가 있습니다. 높은 GPU 온도는 GPU 성능을 낮출 수 있고, 처리 시간이 더 오래 걸릴 수 있습니다.
하드웨어 외에도 여기서 언급해야 할 몇 가지 소프트웨어 고려 사항이 있습니다. 먼저, Windows 사용자라면 안타깝게도 나쁜 소식이 있어요. 일부 라이브러리와 도구는 Linux에서만 작동합니다. 특히, 모델 양자화에 자주 사용되는 bitsandbytes는 Windows 친화적이지 않습니다. 어떤 사람들은 Windows용 래퍼를 만들었지만 (예를 들어 여기), 그들은 장단점이 있어요. 그래서 제 추천은 WSL에 Linux를 설치하거나 저와 같이 듀얼 부팅 시스템을 사용하여 LLM 작업 중에 완전히 Linux로 전환하는 것입니다.
또한, PyTorch와 호환되는 CUDA 버전을 설치해야 합니다. 제 추천은 CUDA 12.3을 설치하는 것입니다 (링크). 그런 다음 이 페이지로 이동하여 시스템, CUDA 버전 및 패키지 관리자 시스템에 따라 올바른 PyTorch를 다운로드하고 설치해야 합니다 (https://pytorch.org/).
export BNB_CUDA_VERSION=123
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/<YOUR-USER-DIR>/local/cuda-12.3
마지막으로 시스템에 다음 패키지를 설치해야 합니다. 충돌을 피하기 위해 시스템에 이미 설치된 다른 패키지와 충돌을 피하기 위해 새 가상 환경(venv)을 만드는 것을 권장합니다. 또한, 아래는 제가 성공적으로 사용한 패키지 버전들입니다:
torch==2.1.2
transformers==4.36.2
datasests==2.16.1
bitsandbytes==0.42.0
peft==0.7.1
기술적 배경
이제 시스템에서 LLMs를 사용하기 위해 모든 하드웨어와 소프트웨어를 준비했으니, 다음 섹션에서 마주할 기술적 개념에 대해 매우 간단히 검토하는 것이 좋습니다.
대형 언어 모델은 수백만 또는 수십억 개의 매개변수로 구성됩니다. 일반적으로 수십억 또는 때로는 수조의 토큰으로 훈련된 사전 훈련된 모델을 사용하는데 굉장히 긴 훈련 과정과 수백만 달러가 들었습니다. 이러한 모델 매개변수 각각은 32비트(4바이트)의 메모리를 차지하고 로드하기 위해 필요합니다. 일반적으로 10억 개의 매개변수당 약 4GB의 메모리가 필요하다고 생각할 수 있습니다. 로드(및 이후 추론 또는 후속 모델 훈련)를 위해 메모리 사용량을 줄이는 한 가지 기술은 "양자화"입니다. 이 기술에서는 모델 가중치의 정밀도를 32비트의 완전 정밀도에서 16비트(fp16 또는 bfloat16), 8비트(int8) 또는 그 이하로 줄입니다.
모델 가중치의 정밀도를 줄이면 제한적인 메모리에 더 큰 모델을 로드할 수 있지만 모델 성능을 희생해야 합니다. 그러나 일부 연구에서는 fp32와 bfloat16 간의 모델 성능 차이가 중요하지 않다고 제안하며, 많은 유명한 모델(Llama2 포함)이 bfloat16로 사전 훈련되었습니다.
양자화는 단일 GPU에서 메모리가 24GB인 대형 언어 모델을 세밀하게 조정하거나 추론할 때 반드시 사용해야 하는 기술입니다. 나중에 볼 것처럼 bitsandbytes 라이브러리를 사용하여 모델 양자화를 구현할 수 있습니다.
가장 엄격한 양자화 기술을 사용하더라도 수십억 개의 매개변수를 가진 작은 크기의 LLM 모델을 사전 훈련할 수 없습니다. 크리스 프레글리 등은 최근 발표된 'AWS에서의 생성적 AI' 도서에서 모델 훈련에 필요한 메모리에 대한 좋은 규칙을 설명했습니다. 그들은 모델의 10억 개의 매개변수당 16비트 반 정밀도에서 6GB의 메모리가 필요하다고 설명했죠.
기억해야 할 것은 메모리 크기가 훈련 이야기의 일부일 뿐이라는 점입니다. 사전 훈련을 완료하는 데 필요한 시간도 또 하나의 중요한 측면입니다. 예를 들어 가장 작은 Llama2 모델인 Llama2 7B는 70억 개의 매개변수를 가지고 훈련을 완료하는 데 184320 GPU 시간이 걸렸습니다.
그래서 대부분의 사람들(상당한 하드웨어 자원과 예산을 갖춘 사람들도)는 특정 사용 사례에 맞게 사전 훈련된 모델을 사용하고 세밀하게 조정하려는 경향이 있습니다. 그러나 한정된 자원(예: 단일 GPU)으로 완전한 세밀 조정을 수행하는 것은 다소 어려울 수 있습니다. 이에 따라 모델 매개변수의 한정된 부분만 업데이트하는 "효율적인 매개 조정" (PEFT) 이 보다 현실적으로 보입니다.
다양한 PEFT 기술 중에서, LoRA (Low Ranking Adaption)는 그 계산 효율성으로 매우 인기가 높습니다. 이 기술에서는 원래 모델의 가중치를 모두 고정시키고 대신 Transformer 아키텍처의 특정 레이어에 추가할 수 있는 저랭크 행렬을 학습합니다. LLM을 세세히 조정할 때 LoRA를 사용하는 경우, 모델 가중치의 0.5%를 업데이트합니다.
QLoRA는 저랭크 행렬 LoRA에 우리가 설명한 양자화 개념을 결합한 변형입니다. 특히, QLoRA 구현에서는 모델을 세세히 조정하기 위해 nf4 또는 Normal Float 4를 사용할 것입니다. QLoRA는 단일 소비자 GPU로 대규모 모델을 세세히 조정하는 경우 연구 사례에서 매우 유용합니다.
코딩 타임
마지막으로, 이제 코딩할 시간입니다!
내 GitHub 리포지토리에서 작동하는 주피터 노트북을 찾을 수 있어요. 이 코드의 많은 부분은 Mathieu Busquet의 깔끔한 글에서 영감을 받아 따랐어요.
코드를 한 줄씩 설명하지는 않겠지만, 단일 GPU에서 대규모 모델을 세밀하게 조정하는 데 중요한 부분을 강조할 거에요.
트랜스포머 모델
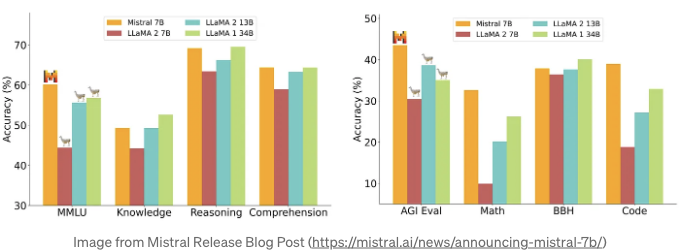
우선, 이 테스트에 Mistral 7B 모델(mistralai/Mistral-7B-v0.1)을 선택했어요. Mistral AI가 개발한 Mistral 7B 모델은 2023년 9월에 공개된 오픈 소스 LLM이에요 (논문 링크). 많은 측면에서 이 모델은 Llama2와 같은 유명한 모델들을 능가해요 (다음 차트를 참고하세요).
데이터셋
또한, 저는 fine-tuning을 위해 Databricks databricks-dolly-15k dataset를 사용했어요 (CC BY-SA 3.0 라이선스하에 제공됨). fine-tuning 시간을 줄이기 위해 이 데이터의 작은 부분(1000행)을 사용했고 컨셉을 증명했어요.
구성 요소
모델 로딩 시, GPU 메모리 제한을 극복하기 위해 다음과 같은 양자화 구성을 사용했어요.
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
이 양자화 구성은 bfloat16 계산 데이터 유형과 nf4(4비트 Normal Float)인 저정밀 스토리지 데이터 유형을 가지고 있기 때문에 단일 GPU에서 모델 세밀 조정에 매우 중요해요. 실제로는 QLORA 가중치 텐서가 사용될 때, 텐서를 bfloat16로 비양자화하고 16비트에서 행렬 곱셈을 수행하게 됩니다(자세한 내용은 원본 논문 참조).
또한 이전에 언급한 대로, 양자화와 함께 LoRA를 사용하여 메모리 제한을 극복하기 위한 QLoRA를 사용 중이에요. 여기 LoRA를 위한 제 설정입니다:
lora_config = LoraConfig(
r=16,
lora_alpha=64,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj"],
bias="none",
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
제 LoRA 구성에는 랭크로 16을 사용했어요. 4부터 16 사이의 랭크로 설정하는 것이 학습 가능한 매개변수의 수를 줄이고 모델 성능 사이의 적절한 균형을 얻기 위해 권장됩니다. 마지막으로, Mistral 7B 트랜스포머 모델의 일부 선형 계층에 LoRA를 적용했습니다.
학습 및 모니터링
제 개인적인 그래픽 카드를 사용하여 4 에포크 (1000 단계)의 학습을 완료할 수 있었어요. 지역 GPU에서 LLM을 학습하는 이러한 테스트 중 하나의 목적은 어떠한 제한 없이 하드웨어 리소스를 모니터링하는 것이에요. 학습 중 GPU를 모니터링하는 가장 간단한 도구 중 하나는 Nvidia 시스템 관리 인터페이스 (SMI)입니다. 단순히 터미널을 열고 명령줄에 다음을 입력하세요:
nvidia-smi
또는 지속적인 모니터링과 업데이트를 위해 다음을 사용하세요 (1초마다 새로고침):
nvidia-smi -l 1
이렇게 하면 GPU에서 각 프로세스의 메모리 사용량을 확인할 수 있습니다. 다음 SMI 보기에서 저는 모델을 불러왔고 약 5GB의 메모리를 사용했습니다 (양자화 덕분에). 또한 Anaconda3 Python (Jupyter 노트북) 프로세스로 모델이 불러와진 것을 확인할 수 있습니다.
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:29:00.0 On | N/A |
| 30% 37C P8 33W / 350W | 5346MiB / 24576MiB | 5% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1610 G /usr/lib/xorg/Xorg 179MiB |
| 0 N/A N/A 1820 G /usr/bin/gnome-shell 41MiB |
| 0 N/A N/A 108004 G ...2023.3.3/host-linux-x64/nsys-ui.bin 8MiB |
| 0 N/A N/A 168032 G ...seed-version=20240110-180219.406000 117MiB |
| 0 N/A N/A 327503 C /home/***/anaconda3/bin/python 4880MiB |
+---------------------------------------------------------------------------------------+
그리고 이곳은 훈련 과정 중 약 30단계 이후의 메모리 상태입니다. 보시다시피, 사용 중인 GPU 메모리는 현재 약 15GB입니다.
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:29:00.0 On | N/A |
| 30% 57C P2 341W / 350W | 15054MiB / 24576MiB | 100% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1610 G /usr/lib/xorg/Xorg 179MiB |
| 0 N/A N/A 1820 G /usr/bin/gnome-shell 40MiB |
| 0 N/A N/A 108004 G ...2023.3.3/host-linux-x64/nsys-ui.bin 8MiB |
| 0 N/A N/A 168032 G ...seed-version=20240110-180219.406000 182MiB |
| 0 N/A N/A 327503 C /home/***/anaconda3/bin/python 14524MiB |
+---------------------------------------------------------------------------------------+
SMI는 GPU 메모리 사용량을 모니터링하는 간단한 도구이지만, 더 자세한 정보를 제공하는 고급 모니터링 도구들도 몇 가지 있습니다. 그 중 하나가 PyTorch Memory Snapshot인데, 이에 관해 더 읽어볼 수 있는 흥미로운 기사가 있습니다.
개요
본 문서에서는 Mistral 7B와 같은 대규모 언어 모델을 단일 24GB GPU(예: NVIDIA GeForce RTX 3090 GPU)에서 세밀하게 조정할 수 있는 것을 보여드렸습니다. 그러나 자세히 설명한 대로 QLoRA와 같은 특별한 PEFT 기술이 필요합니다. 또한 모델의 배치 크기가 중요하며, 한정된 자원 때문에 보다 오랜 시간의 훈련이 필요할 수 있습니다.