디자인 패턴은 미래에 이를 유지하는 것이 더 쉬운 방식으로 반복되는 여러 가지 문제를 해결할 수 있게 해줍니다.
이를 감안할 때 각 디자인 패턴을 알아야 특정 문제를 해결할 때 더 큰 유연성을 가질 수 있습니다.
내가 보는 문제는 보통 이 디자인 패턴 중 하나를 배우려고 할 때 실제로 직면한 문제를 알지 못한 채로 아주 긴 설명들을 마주하게 된다는 것입니다.
이 이야기에서는 공장 메서드 패턴을 가능한 간단히 설명해 보겠습니다. 이렇게 함으로써 해당 패턴이 해결하고 있는 문제와 어떻게 구현되는지 이해할 수 있을 것입니다.
Factory Method 패턴을 사용하지 않은 예제
다른 종류의 문서인 이력서와 보고서를 가진 예제를 만들어 봅시다.
이러한 문서 유형은 고유한 생성자를 가질 것입니다:
from abc import ABC, abstractmethod
# 제품 인터페이스 정의
class Document(ABC):
@abstractmethod
def create(self):
pass
# 구체적인 제품 생성
class Resume(Document):
def create(self):
return "이력서 생성됨"
class Report(Document):
def create(self):
return "보고서 생성됨"
이후에는 이 유형의 문서를 선택하는 함수가 있을 것입니다:
def create_document(document_type: str) -> Document:
if document_type == "resume":
return Resume()
elif document_type == "report":
return Report()
else:
raise ValueError(f"알 수 없는 문서 유형: {document_type}")
이후 팩토리 메서드 패턴을 통해 이 함수의 구현을 개선할 수 있음을 나중에 확인하게 될 것입니다.
나머지 코드는 문서 유형을 사용하는 방법을 보여줍니다:
def client_code(document_type: str):
document = create_document(document_type)
print(document.create())
if __name__ == "__main__":
print("이력서 생성:")
client_code("resume")
print("\n보고서 생성:")
client_code("report")
팩토리 메서드 사용
리팩토링에서는 여전히 각 객체의 생성자가 있습니다:
from abc import ABC, abstractmethod
# 제품 인터페이스 정의
class Document(ABC):
@abstractmethod
def create(self):
pass
# 구체적인 제품 생성
class Resume(Document):
def create(self):
return "이력서 생성됨"
class Report(Document):
def create(self):
return "보고서 생성됨"
그러나 이제 각 유형의 문서 생성을 탈 중앙화했습니다:
# 팩토리 메서드를 사용하여 생성자 클래스 정의
class DocumentCreator(ABC):
@abstractmethod
def factory_method(self):
pass
def create_document(self):
# 제품을 얻기 위해 팩토리 메서드 호출
document = self.factory_method()
return document.create()
# 구체적인 생성자 구현
class ResumeCreator(DocumentCreator):
def factory_method(self):
return Resume()
class ReportCreator(DocumentCreator):
def factory_method(self):
return Report()
새로운 문서 유형을 추가하는 것은 새로운 구체적인 생성자 클래스를 만드는 것만큼 간단합니다.
나머지 코드는 문서 유형을 사용하는 방법을 보여줍니다:
def client_code(creator: DocumentCreator):
print(creator.create_document())
if __name__ == "__main__":
print("이력서 생성 중:")
resume_creator = ResumeCreator()
client_code(resume_creator)
print("\n보고서 생성 중:")
report_creator = ReportCreator()
client_code(report_creator)
차이점 설명
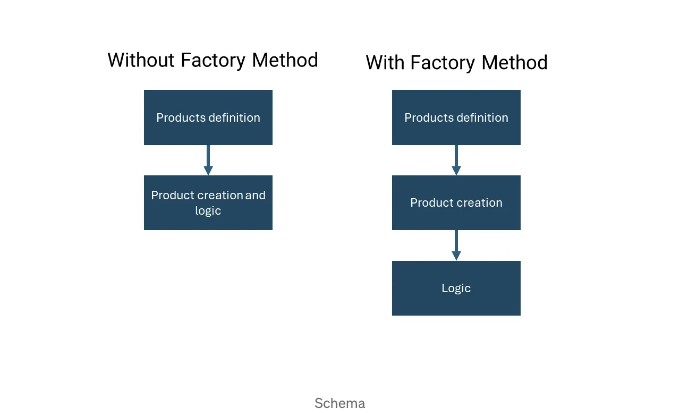
주요 차이점은 팩토리 메서드 패턴을 사용하지 않을 때, 객체를 프로그램 로직을 정의하는 곳과 동일한 위치에서 생성한다는 것입니다.
def create_document(document_type: str) -> Document:
if document_type == "resume":
return Resume()
elif document_type == "report":
return Report()
else:
raise ValueError(f"Unknown document type: {document_type}")
위의 예제는 매우 간단합니다. 새로운 문서 유형을 추가하거나 삭제할 때 이 논리를 변경하는 것은 비교적 쉬우지만, 더 복잡한 경우에는 더 비용이 많이 들 수 있습니다.
게다가, 이것에는 훌륭한 논리가 없습니다. 각 if/else 이후에 일련의 동작이 수행된다고 상상해보세요.
비교
- 팩토리 메소드 없이: 문서 생성 로직은 create_document 함수에 중앙 집중화되어 있습니다. 이는 더 간단하지만 코드를 유연하게 만들고 유지하기 어렵게 만듭니다. 새로운 유형의 문서를 추가하려면 create_document 함수를 수정해야 하며, 이로 인해 버그가 발생할 수 있고 전체 함수의 로직을 이해해야 합니다.
- 팩토리 메소드 사용: 생성 로직이 분산됩니다. 각 구체적인 생성자는 자체 유형의 문서를 생성하는 방법을 알고 있습니다. 새로운 유형의 문서를 추가하는 것은 새로운 구체적인 생성자 클래스를 만드는 것만큼 간답습니다. 이 접근 방식은 개방/폐쇄 원칙을 준수하며 코드를 보다 모듈식으로 만들고 확장하기 쉽게 만듭니다.
어떻게 인식할까요?
이 패턴을 사용해야 하는 시점은 로직 일부가 서로 다른 객체 유형을 생성하는 if/else if/else를 사용하고 있을 때 가장 쉽게 인식할 수 있습니다.
예시
def mainfuntion(): if option==1: Object1=Object_constructor() action1() action2() elif option==2: Object2=Object_constructor2() action3() action4() else: Object3=Object_constructor3() action5() action6()
우리는 보듯이, 이 논리는 사용된 객체의 유형에 매우 의존합니다. 다른 유형의 객체를 사용해야 한다면 프로그램의 논리를 바꿀 필요가 있습니다.
이러한 패턴을 보게 되면, 팩토리 메서드를 사용하여 개선을 고려할 수 있습니다.
결론
인터넷에서 찾을 수 있는 것들과는 조금 다른 방식으로 이 디자인 패턴을 설명해 보았어요. 가능한 가장 간단한 방법으로 설명해 보았답니다.
저는 이러한 패턴에 대해 다양한 정보원에서 배우는 것이 이상적이라고 생각해요. 각각의 예시를 보면서 개념을 더 깊이 이해할 수 있을 거예요.
이야기가 마음에 들기를 바랍니다.
관심 가져 주셔서 정말 감사합니다!