다른 폴더에서 코드를 가져올 때 항상 빈 init.py 파일을 넣습니다. 이것은 대부분의 파이썬 개발자들에게 거의 반복적인 습관이 되었습니다 - 초보자든 마법사든. 그러나 우리는 init.py에 대해 정말로 알고 있을까요?
이 블로그 포스트에서는 init.py가 어떻게 작동하는지와 비어있지 않은 init.py가 우리 파이썬 개발자로서 어떻게 도움이 되는지 세 가지 방법을 살펴보겠습니다.
init.py란 무엇인가요?
init.py는 폴더를 패키지로 취급해야 한다는 것을 파이썬 해석기에 알려주는 파이썬 파일입니다.
컴파일된 언어인 C 및 C++과 달리, Python의 인터프리터는 필요한 종속성을 실시간으로 가져옵니다. Python에게 코드를 다른 곳에서 사용할 것이라고 신호를 보내려면 폴더에 init.py를 넣으면 됩니다.
그래서 init.py를 게이트키퍼로 생각해보세요. 이 파일은 폴더를 가져올 수 있는 Python 패키지로 변환시켜줍니다.
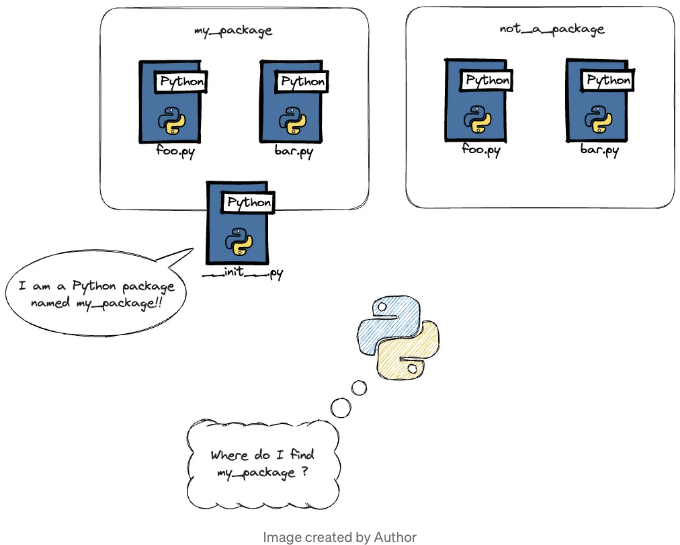
하지만 init.py는 그 이상입니다. Python에서 클래스를 만들 때 종종 init 함수를 생성해야합니다. 이 함수는 객체가 어떻게 구성되어야 하는지를 정의하며 클래스의 객체가 생성될 때 가장 먼저 실행됩니다. 같은 방식으로, init.py는 Python 패키지의 생성자입니다. 패키지가 가져올 때마다 먼저 실행됩니다. 빈 init.py는 Python 패키지의 빈 init 생성자 메서드를 의미합니다. 괜찮지만 더 많은 일을 할 수 없다는 뜻은 아닙니다.
init.py 주의해서 사용하기
init.py는 파이썬 패키지의 생성자이므로, init.py를 어디에 두는지에 대해 신중해야 합니다.
날짜 형식을 처리하는 몇 가지 사용자 정의 유틸리티 함수가 있는 datetime이라는 폴더가 있다고 가정해봅시다:
# ./datetime/utils.py
def increment_date(date: int, increment: int) -> int:
"""밀리초 단위로 타임스탬프 증가"""
return date + increment
우리는 그런 다음 init.py를 추가해서 main.py에서 코드를 가져올 수 있도록합니다:
myfolder
│
├── datetime
│ ├── __init__.py
│ └── utils.py
└── main.py
# main.py
from datetime.utils import increment_date
from datetime import datetime
def main():
timestamp = datetime.timestamp(datetime(2024, 2, 27))
print(increment_date(timestamp, increment=10))
if __name__ == "__main__":
main()
만약 main.py를 실행하면 무엇이 일어날까요?
ImportError: datetime 모듈에서 datetime을 가져올 수 없습니다.
보통, Python 인터프리터는 패키지 발견 과정을 (1) 로컬 디렉토리, (2) 표준 라이브러리, 그리고 (3) 설치된 Python 모듈의 순서로 우선시합니다.
datetime이라는 이름의 폴더에 init.py를 넣음으로써, 우리는 datetime이라는 파이썬 표준 라이브러리를 재정의했기 때문에 datetime.datetime을 가져오는 명령문이 실패했습니다.
이 문제를 피하려면 매우 간단한 수정이 필요합니다: 다른 Python 표준 라이브러리나 설치된 Python 모듈과 동일한 이름을 가진 폴더 아래에 init.py를 넣지 않도록 항상 주의하십시오.
init.py가 어떻게 작동하는지 이해하면, 이것을 활용하여 할 수 있는 좀 더 멋진 것들을 살펴보겠습니다!
1. 패키지 레벨 설정 정의하기
만약 코드 내 모든 Python 파일이 유사한 설정을 공유한다면 어떨까요? 로깅 레벨, 상수, 환경 변수 등. 당신의 패키지 내 모든 Python 파일 상단에 설정을 지정하는 대신, 이를 모두 init.py에 포함시킬 수 있습니다.
# myfolder/__init__.py
import os
import logging
# 패키지 전체의 환경 변수를 로드합니다.
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", None)
# 패키지 레벨 상수를 설정합니다.
MODEL = "gpt-4"
# 로깅 구성을 설정할 수도 있습니다.
logging.basicConfig(level=logging.INFO)
# 패키지 내에서 편리하게 재사용할 수 있는 사용자 지정 데코레이터를 추가하세요.
def foo(func):
@wraps(func)
def wrapper(*args, **kwargs):
logging.info(f"함수 호출 중: {func.__name__}")
result = func(*args, **kwargs)
logging.info(f"함수 {func.__name__} 실행 완료")
return result
return wrapper
당신의 코드베이스에서는 다음과 같이 할 수 있습니다:
# myfolder/bar.py
# 패키지 __init__.py에서 상대적인 임포트
from . import OPENAI_API_KEY, MODEL, foo
from openai import OpenAI
from typing import Optional
client = OpenAI()
@foo
def chat_with_openai(prompt: str, llm: Optional[str] = None) -> Any:
"""Prompt를 LLM에 보내고 응답을 반환합니다"""
llm = llm or MODEL
return client.chat.completions.create(
model=llm,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
)
위 내용에 추가하여 다음과 같은 작업도 가능합니다:
- 기능 플래깅
- 고급 로거 구성 (예: 모든 로그를 폴더에 저장)
- 기본 매개변수 설정 (예: 출력 디렉토리가 제공되지 않은 경우 X에 저장)
- 사용 모니터링 (예: 모든 함수 호출을 클라우드 인스턴스로 보내는 사용자 지정 데코레이터)
- 테마 사용자 정의/정의 (예: 언어 로캘, 라이트/다크 테마)
- 사용자 정의 데코레이터로 오류 처리 중앙화
2. 패키지 가져오기 단순화
코드베이스가 복잡해지면 더 많은 클래스와 함수를 추가하게 될 것입니다. 코드를 응집된 단위로 분리하는 원칙에 따라, 아래와 같은 구조가 생길 수 있습니다:
foo
│
├── llm_email_responder
│ ├── __init__.py
│ ├── base_email_responder.py
│ ├── mail_chimp_responder.py
│ ├── zoho_mail_responder.py
│ └── send_grid_responder.py
└── __init__.py
MailChimp에 대한 LLM 이메일 응답기를 사용하려면 다음이 필요합니다:
from foo.llm_email_responder.mail_chimp_responder import MailChimpResponder
곧 여러 줄의 비슷한 import 문이 생겨나게 되어 코드베이스의 내부 구조를 기억하기 어렵게 만들 수 있습니다.
init.py는 import를 정리하고 코드베이스의 더 낮은 수준의 부분을 보호하면서 개발 경험을 단순화하는 데 사용할 수 있습니다.
# ./foo/llm_email_responder/__init__.py
# 사용자가 더 높은 수준의 구현만큼 자주 사용하지 않을 것으로 예상되므로
# 가장 낮은 수준의 이메일 응답기는 건너뜁니다.
from .mail_chimp_responder import MailChimpResponder
from .zoho_mail_responder import ZohoResponder
from .send_grid_responder import SendGridResponder
__all__ = [
"MailChimpResponder",
"ZohoResponder",
"SendGridResponder",
]
위의 init.py와 함께, 이제 다음과 같이 응답기에 액세스할 수 있습니다:
from foo.llm_email_responder import MailChimpResponder
이것은 개발자 친화적 인터페이스에서 하위 수준의 코드를 노출하는 편리한 방법이지만, 하위 수준 코드베이스에 대한 변경은 반드시 init.py의 변경과 일치해야 함으로 유지 보수 노력이 증가할 것입니다. 또한 하위 수준의 코드 베이스를 노출하는 것이 일관된 아키텍처를 형성하는지 여부를 평가해야 합니다.
싱글톤 패턴
싱글톤 디자인 패턴을 적용하려면 init.py를 사용할 수도 있어요. 이렇게 하면 패키지 전체가 init.py에서 인스턴스화한 동일한 인스턴스를 사용하도록 강제됩니다.
만약 패키지가 원격 서비스에 연결을 설정하거나 대규모 데이터셋을로드하거나, 무거운 작업을 요구하는 어떤 전제조건이 필요하다면, 이 방법이 아주 편리할 거예요.
예를 들어 금융 보고서를 조작하는 LLM 필요를 처리하기 위해 Gemini Pro에 연결해야 한다고 해보죠.
foo
│
├── report_analyser
│ ├── __init__.py
│ ├── outline_extraction.py
│ └── entity_extraction.py
└── __init__.py
.foo/report_analyser/outline_extraction
from langchain_google_vertexai import VertexAI
def extract_outline(page: str, **kwargs) -> str:
llm = VertexAI(
model_name="gemini-pro", location="europe-west2", **kwargs
)
prompt_template = """...
.foo/report_analyser/entity_extraction
from langchain_google_vertexai import VertexAI
def extract_entities(page: str, **kwargs) -> str:
llm = VertexAI(
model_name="gemini-pro", location="europe-west2", **kwargs
)
prompt_template = """...
.foo/report_analyser/entity_extraction
from foo.report_analyser.outline_extraction import extract_outline from foo.report_analyser.entity_extraction import extract_entities
def main(): page = "Long page of document here"
# A connection to VertexAI will be created for
# extracting outline
outline = extract_outline(page, temperature=0.2)
# Another connection to VertexAI will be created
# for extracting entities
entities = extract_entities(page, temperature=0.2)
각 작업을 실행할 때마다 코드베이스가 VertexAI와 새로운 연결을 생성하여 불필요한 네트워크 오버헤드가 발생합니다. 만약 Gemini Pro에 대해 동일한 구성을 사용할 계획이라면, 대신 다음을 수행할 수 있습니다:
# .foo/report_analyser/__init__.py
from langchain_google_vertexai import VertexAI
DEFAULT_LLM = VertexAI(
model_name="gemini-pro",
location="europe-west2",
temperature=0.2,
)
# .foo/report_analyser/outline_extraction
from . import DEFAULT_LLM
from typing import Dict
def extract_outline(
page: str,
custom_llm_parameters: Optional[Dict] = None
) -> str:
if custom_llm_parameters is None:
llm = DEFAULT_LLM
else:
llm = VertexAI(
model_name="gemini-pro",
location="europe-west2",
**custom_llm_parameters
)
prompt_template = """...<Your prompt template here>..."""
prompt = prompt_template.format_prompt(page=page)
return llm.invoke(prompt)
코드를 개선하려면, init.py에서 LLM 연결을 생성하는 부분을 분리하여 별도의 파일로 만들어 LLM 연결 관리자를 만들 수 있습니다. @lru_cache와 결합하면 사용자 정의 구성을 더 효율적으로 처리하고 있는 것을 알 수 있을 것입니다.
init.py에 대해 무엇인지 배우고 더 잘 활용하는 방법에 대한 아이디어를 얻었기를 바랍니다.
파이썬에 대해 더 알고 싶다면, 파이썬에 관한 다른 블로그를 확인해보세요!
다음에 또 만나요, Louis입니다.