목차
소개
LLM이 필요한 이유 미세 조정 vs. 컨텍스트 주입 LangChain이란 무엇인가요?
단계별 튜토리얼
- LangChain을 사용하여 문서를 로드합니다.
- 문서를 텍스트 청크로 분할합니다.
- 텍스트 청크에서 임베딩으로 변환합니다.
- 사용할 LLM을 정의합니다.
- 프롬프트 템플릿을 정의합니다.
- 벡터 스토어를 생성합니다.
LLM이 필요한 이유
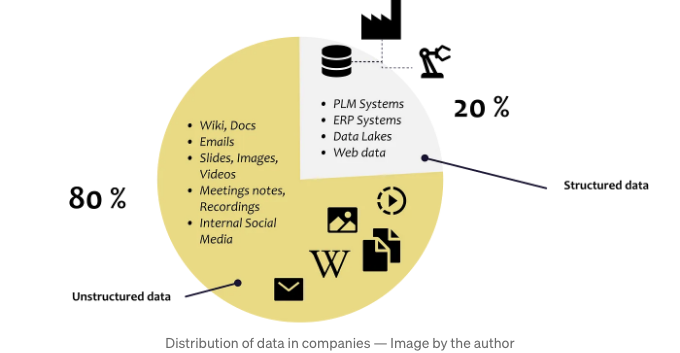
언어의 진화는 우리를 오늘날까지 끌어올렸습니다. 우리는 이를 통해 지식을 효율적으로 공유하고 협력할 수 있게 되었습니다. 결과적으로, 대부분의 집단적인 지식은 미구조화된 채로 기록된 텍스트를 통해 유지되고 전달됩니다.
지난 20년 동안 정보와 프로세스를 디지털화하기 위한 노력들은 주로 관계형 데이터베이스에 계속해서 더 많은 데이터를 축적하는 데 초점을 맞췄습니다. 이 방식은 전통적인 분석 기계 학습 알고리즘들이 데이터를 처리하고 이해하는 데 도움이 됩니다.
그러나 구조화된 방식으로 점점 더 많은 데이터를 저장하는 데 쏟아지는 지속적인 노력에도 불구하고, 우리는 여전히 우리의 지식 전체를 포착하고 처리하는 데 한계를 겪고 있습니다.
GPT3.5의 개발과 발전은 우리에게 다양한 데이터셋을 효과적으로 해석하고 분석할 수 있는 엄청난 성과를 나타내는 중요한 이정표입니다. 요즘엔 텍스트, 이미지, 오디오 파일 등 다양한 형식의 콘텐츠를 이해하고 생성할 수 있는 모델들이 있죠.
파인 튜닝 vs. 컨텍스트 주입
일반적으로, 대형 언어 모델이 모르는 질문에 대답할 수 있도록 하는 두 가지 근본적으로 다른 접근 방식이 있습니다: 모델 파인 튜닝 및 컨텍스트 주입
파인 튜닝
세밀 조정은 기존 언어 모델을 추가 데이터로 훈련하여 특정 작업에 최적화하는 것을 의미합니다.
처음부터 언어 모델을 훈련시키는 대신 BERT 또는 LLama와 같은 사전 훈련된 모델을 사용하고, 그런 다음 사용 사례별 훈련 데이터를 추가하여 특정 작업의 요구 사항에 맞게 조정합니다.
스탠포드 대학교 팀은 LLM Llama를 사용했고 사용자/모델 상호 작용이 어떻게 보일 수 있는지에 대한 50,000개의 예제를 사용하여 세밀 조정했습니다. 결과는 사용자와 상호 작용하고 쿼리에 응답하는 챗봇이 되었습니다. 이 세밀 조정 단계는 모델이 최종 사용자와 상호 작용하는 방식을 변경했습니다.
→ 세밀 조정에 대한 오해
PLLMs(Pre-trained Language Models)의 세밀 조정은 특정 작업에 모델을 맞추는 방법이지만, 모델에 자체 도메인 지식을 주입할 수는 없습니다. 이는 모델이 이미 방대한 양의 일반 언어 데이터로 교육되었으며, 특정 도메인 데이터는 대부분 이미 학습한 내용을 덮어쓸 정도로 충분하지 않기 때문입니다.
따라서 모델을 세밀 조정할 때 가끔 올바른 답변을 제공할 수 있지만, 사전 훈련 중 학습한 정보에 크게 의존하기 때문에 종종 실패할 수 있습니다. 이 정보들이 특정 작업에 정확하거나 관련성 있는지 여부가 제대로 반영되어 있지 않을 수도 있기 때문입니다. 다시 말해, 세밀 조정은 모델이 어떻게 의사소통하는 방식에 적응하는 데 도움이 되지만, 그것이 무엇을 의사소통하는지에 대해서는 그렇지 않을 수도 있습니다. (Porsche AG, 2023)
이것이 맥락 주입이 중요한 이유입니다.
맥락 중심 학습 / 맥락 주입
컨텍스트 주입을 사용할 때, 우리는 LLM을 수정하지 않고 프롬프트 자체에 주제와 관련된 컨텍스트를 주입하는 데 집중합니다.
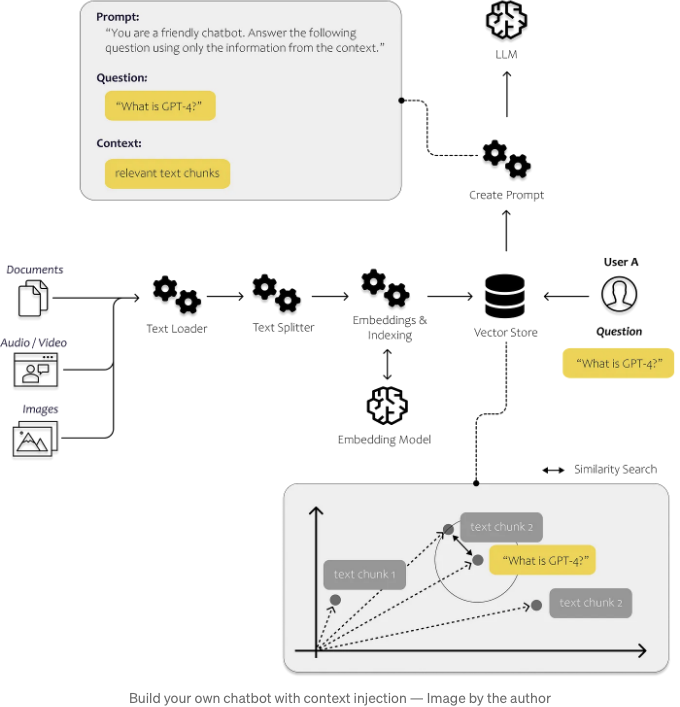
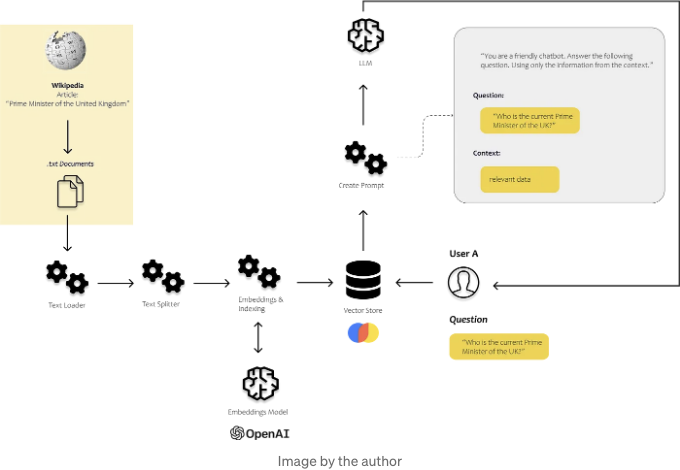
따라서 우리는 어떻게 적절한 정보를 포함시킬지에 대해 고려해야 합니다. 아래 그림에서 전체적으로 어떻게 작동하는지에 대해 간략히 볼 수 있습니다. 우리는 가장 관련 있는 데이터를 식별할 수 있는 프로세스가 필요합니다. 이를 위해 컴퓨터가 텍스트 조각끼리 비교할 수 있도록 하는 것이 필요합니다.
이 작업은 임베딩을 통해 수행될 수 있습니다. 임베딩을 사용하면 텍스트를 벡터로 변환하여 텍스트를 다차원 임베딩 공간에서 나타낼 수 있습니다. 공간에서 서로 가까운 점들은 종종 동일한 문맥에서 사용됩니다. 이 유사성 검색이 영원히 걸리지 않도록하기 위해 벡터를 벡터 데이터베이스에 저장하고 인덱싱합니다.
이 기사의 목적은 우리 자신의 텍스트와 문서를 분석할 수 있는 간단한 솔루션을 만들고, 이를 통해 획득한 통찰을 사용하여 해결책이 사용자에게 돌아가도록 하는 과정을 보여주는 것입니다. 종단간 솔루션을 구현하는 데 필요한 모든 단계와 구성 요소를 설명하겠습니다.
그렇다면 LLMs의 기능을 어떻게 활용하여 우리의 요구를 충족시킬 수 있을까요? 한 단계씩 살펴보겠습니다.
단계별 자습서 - 여러분의 첫 번째 LLM 앱
이어지는 내용에서는 LLMs를 활용하여 우리의 개인 데이터에 대한 질문에 대답하는 데 사용하려고 합니다. 이를 위해 우리의 개인 데이터 내용을 벡터 데이터베이스로 전송하여 시작하겠습니다. 이 단계는 텍스트 내에서 관련 섹션을 효율적으로 찾을 수 있도록 함으로써 중요합니다. 우리는 이 데이터와 LLMs의 기능을 사용하여 텍스트를 해석하고 사용자의 질문에 답변할 것입니다.
우리는 챗봇이 제공한 데이터를 기반으로 한 질문에만 답변하도록 안내할 수도 있습니다. 이렇게 함으로써 챗봇이 주어진 데이터에 집중하고 정확하고 관련성 있는 응답을 제공할 수 있도록 할 수 있어요.
우리의 사용 사례를 구현하기 위해 LangChain에 많이 의존할 것입니다.
LangChain이란?
"LangChain은 언어 모델을 기반으로 한 애플리케이션을 개발하기 위한 프레임워크입니다." (Langchain, 2023)
따라서, LangChain은 채팅봇, 요약 도구 및 기본적으로 LangChain의 강점을 활용하여 작성하고자 하는 도구와 같은 다양한 LLM 애플리케이션의 생성을 지원하기 위해 설계된 Python 프레임워크입니다. 이 라이브러리는 필요한 다양한 구성 요소를 결합합니다. 이러한 구성 요소를 이른바 "체인"이라고 불리는 것으로 연결할 수 있습니다.
LangChain의 가장 중요한 모듈은 다음과 같습니다 (Langchain, 2023):
- Models: 다양한 모델 유형에 대한 인터페이스
- Prompts: 프롬프트 관리, 프롬프트 최적화 및 프롬프트 직렬화
- Indexes: 문서 로더, 텍스트 분할기, 벡터 저장소 - 데이터에 빠르고 효율적으로 액세스 가능하게 함
- Chains: 체인은 단일 LLM 호출을 넘어서 호출 시퀀스를 설정할 수 있게 합니다
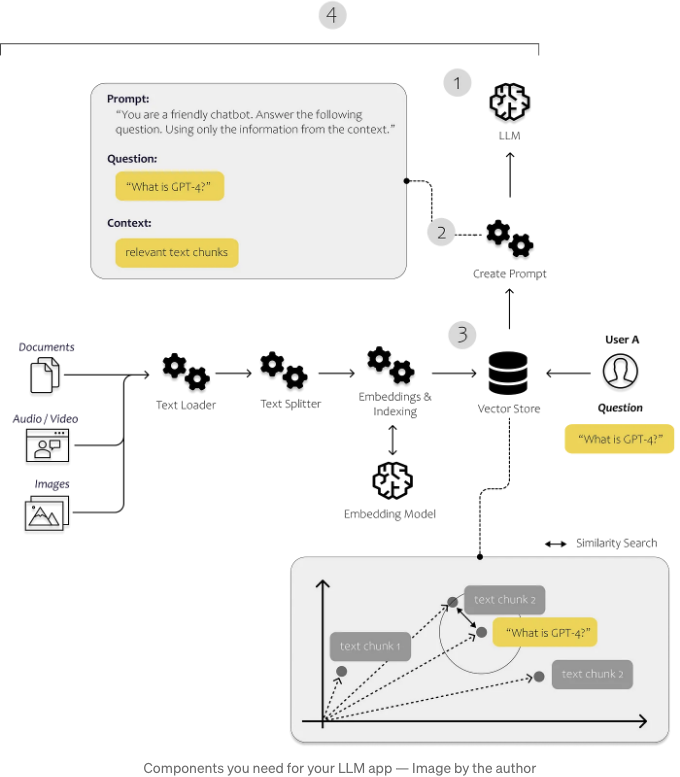
아래 이미지에서는 이러한 구성 요소들이 어떻게 작용하는지 확인할 수 있습니다. 문서 로더 및 텍스트 분할기를 사용하여 우리만의 비구조화된 데이터를로드하고 처리합니다. 프롬프트 모듈을 사용하여 발견된 콘텐츠를 프롬프트 템플릿에 삽입하고 마지막으로 모델 모듈을 사용하여 프롬프트를 모델로 전송합니다.
- 에이전트: 에이전트는 LLM을 사용하여 어떤 조치를 취할지 결정하는 개체입니다. 조치를 취한 후에는 그 조치의 결과를 관찰하고 그 작업이 완료될 때까지 이 과정을 반복합니다.
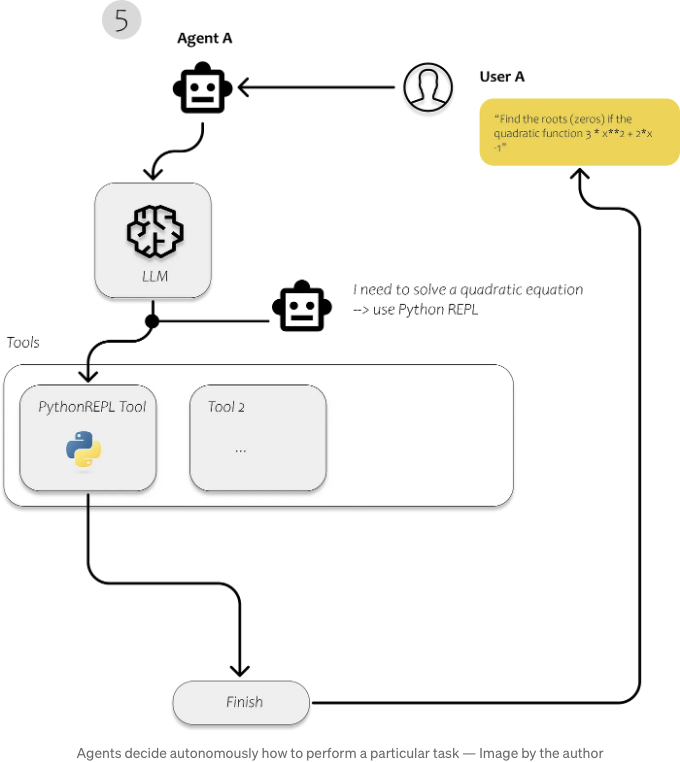
우리는 문서를 로드하고 분석하며 효율적으로 검색할 수 있도록 만들기 위해 첫 번째 단계에서 Langchain을 사용합니다. 텍스트를 색인화한 후에는 사용자의 질문에 대답하기 위해 관련 텍스트 조각을 인식하는 것이 훨씬 더 효율적이어야 합니다.
우리 간단한 응용 프로그램에 필요한 것은 물론 LLM입니다. 우리는 OpenAI API를 통해 GPT3.5를 사용할 것입니다. 그런 다음 LLM에 우리 자신의 데이터를 공급할 수 있게 해주는 벡터 저장소가 필요합니다. 그리고 각 쿼리마다 다른 작업을 수행하려면 각 쿼리에 대해 무엇이 발생해야 하는지 결정하는 에이전트가 필요합니다.
우리가 시작해 보죠. 먼저 우리 자신의 문서를 가져와야 합니다.
다음 섹션에서는 LangChain의 Loader Module에 포함된 모듈에 대해 설명하여 다른 출처에서 다양한 유형의 문서를 로드하는 방법을 설명합니다.
1. LangChain을 사용하여 문서 로드하기
LangChain은 다양한 소스에서 문서를 로드할 수 있습니다. LangChain 문서에서 가능한 문서 로더 목록을 찾을 수 있습니다. 그중에는 HTML 페이지, S3 버킷, PDF, Notion, Google 드라이브 등의 로더가 포함되어 있습니다.
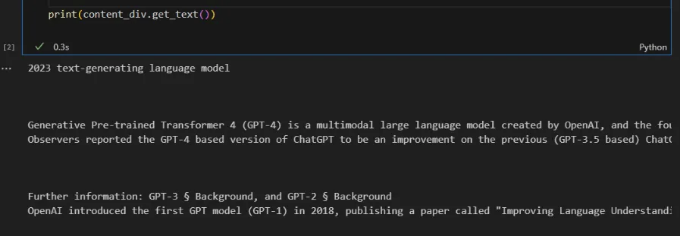
간단한 예제에서는 GPT3.5의 훈련 데이터에 포함되지 않은 데이터를 사용합니다. GPT4에 관한 위키피디아 문서를 사용하겠습니다. GPT3.5가 GPT4에 대해 제한된 지식을 가지고 있을 것으로 가정합니다.
이 간단한 예제에서 LangChain 로더 중 하나를 사용하지 않고, BeautifulSoup을 사용하여 위키피디아에서 텍스트를 직접 가져오겠습니다.
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/GPT-4"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 페이지의 모든 텍스트 찾기
text = soup.get_text()
# 콘텐츠 div 찾기
content_div = soup.find('div', {'class': 'mw-parser-output'})
# div에서 원치 않는 요소 제거
unwanted_tags = ['sup', 'span', 'table', 'ul', 'ol']
for tag in unwanted_tags:
for match in content_div.findAll(tag):
match.extract()
print(content_div.get_text())
2. 문서를 텍스트 조각으로 분할하기
다음으로, 우리는 텍스트를 텍스트 청크라 불리는 작은 섹션으로 나눠야 합니다. 각 텍스트 청크는 임베딩 공간에서 데이터 포인트를 나타내며, 컴퓨터가 이러한 청크들 간의 유사성을 결정할 수 있게 합니다.
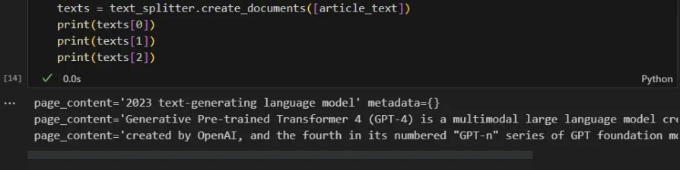
다음 텍스트 스니펫은 langchain의 텍스트 분할 모듈을 활용하고 있습니다. 특정 사례에서는 크기가 100이고 오버랩이 20인 청크를 지정하고 있습니다. 일반적으로 더 큰 텍스트 청크를 사용하는 것이 흔하지만, 사용 사례에 최적화된 크기를 찾기 위해 조금 실험할 수 있습니다. 단, 각 LLM에는 토큰 제한이 있다는 것을 기억해야 합니다 (GPT 3.5의 경우 4000 토큰). 우리는 텍스트 블록을 프롬프트에 삽입하고 있기 때문에 전체 프롬프트가 4000 토큰 이하인지 확인해야 합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
article_text = content_div.get_text()
text_splitter = RecursiveCharacterTextSplitter(
# 매우 작은 청크 크기로 설정하여 표시합니다.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([article_text])
print(texts[0])
print(texts[1])
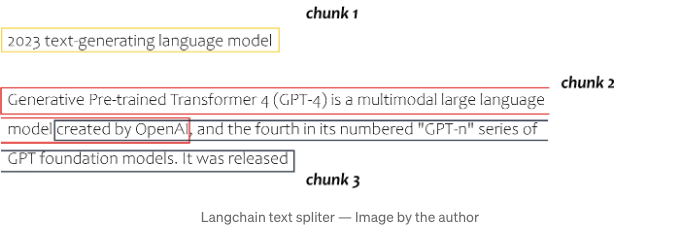
전체 텍스트가 다음과 같이 분할됩니다:
3. 텍스트 청크에서 임베딩으로
이제 텍스트 구성 요소를 알고리즘과 비교할 수 있도록 이해하기 쉽고 비교할 수 있는 형태로 바꿔야 합니다. 우리는 인간의 언어를 비트와 바이트로 나타내는 디지털 형태로 변환할 방법을 찾아야 합니다.
이 그림은 대부분의 사람에게 명백해 보일 수 있는 간단한 예를 제시합니다. 그러나 우리는 컴퓨터가 "찰스"라는 이름이 여성이 아닌 남성과 관련되어 있음을 이해할 수 있는 방법을 찾아야 하며, 찰스가 남자이면 왕이고 여왕이 아님을 학습시켜야 합니다.
지난 몇 년 동안 새로운 방법과 모델이 등장했는데, 그 방법이 바로 이겁니다. 우리가 원하는 것은 단어의 의미를 n차원 공간으로 변환하여 텍스트 청크를 서로 비교하고 유사성을 측정할 수 있는 방법입니다. 임베딩 모델은 일반적으로 단어가 사용되는 문맥을 분석함으로써 정확히 이를 학습하려고 노력합니다. 차, 커피, 아침이 종종 동일한 문맥에서 사용되기 때문에 이러한 단어들은 예를 들어 차와 콩보다 n차원 공간에서 서로 더 가깝습니다. 차와 콩은 발음은 비슷하지만 함께 사용되는 경우가 거의 없습니다. 임베딩 모델은 각 단어에 대한 벡터를 제공해주어 임베딩 공간에서 단어를 나타낼 수 있습니다. 마지막으로, 벡터를 사용하여 단어 사이의 유사성을 계산하는 등의 수학적 계산을 수행할 수 있습니다.
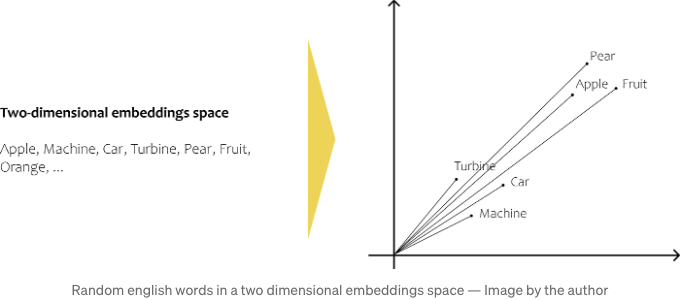
텍스트를 임베딩으로 변환하는 방법에는 Word2Vec, GloVe, fastText 또는 ELMo 등 여러 가지가 있습니다.
임베딩 모델
단어 간 유사성을 포착하기 위해 Word2Vec은 간단한 신경망을 사용합니다. 우리는 이 모델을 대량의 텍스트 데이터로 훈련시키고 각 단어에 n차원 임베딩 공간에서 점을 할당하고 따라서 단어의 의미를 벡터 형식으로 설명할 수 있는 모델을 만들고자 합니다.
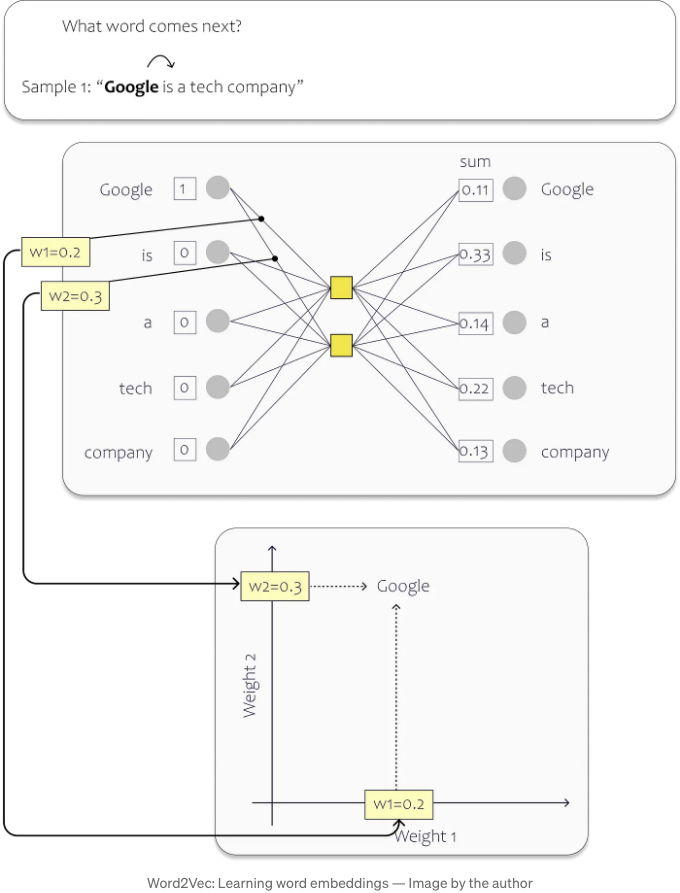
훈련 과정에서 우리는 데이터 세트의 각 고유한 단어에 입력 레이어의 뉴런을 할당합니다. 아래 이미지에서 간단한 예시를 확인할 수 있어요. 이 경우, 은닉 레이어에는 두 개의 뉴런만이 포함되어 있습니다. 두 개인 이유는 단어를 2차원 임베딩 공간에 매핑하려고 하기 때문이에요. (실제로 기존 모델은 훨씬 더 크며, 단어를 더 높은 차원 공간에 표현합니다. - 예를 들어, OpenAI의 Ada 임베딩 모델은 1536 차원을 사용합니다.) 훈련 과정 후 개별 가중치는 임베딩 공간에서의 위치를 나타냅니다.
이 예시에서는 데이터 세트가 "Google is a tech company."라는 단일 문장으로 구성되어 있습니다. 문장의 각 단어는 신경망(NN)의 입력으로 작용합니다. 결과적으로 우리 네트워크는 다섯 개의 입력 뉴런을 갖게 됩니다.
훈련 과정에서 각 입력 단어의 다음 단어를 예측하는 데 초점을 맞춥니다. 문장의 시작에서 시작할 때, "Google"이라는 단어에 해당하는 입력 뉴런은 값 1을 받고, 나머지 뉴런은 값 0을 받습니다. 이 특정 시나리오에서 네트워크를 "is" 단어를 예측할 수 있도록 훈련하는 것이 목표입니다.
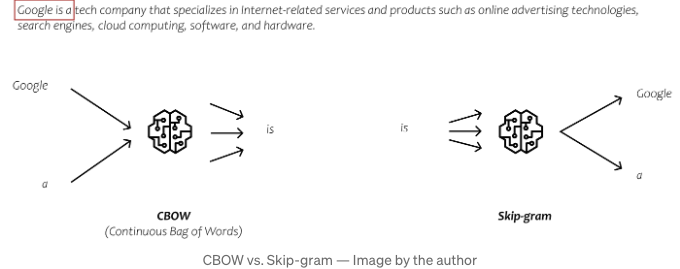
실제로 임베딩 모델을 학습하는 여러 가지 방법이 있습니다. 각각은 학습 과정 중 출력을 예측하는 독특한 방식을 가지고 있어요. 두 가지 흔히 사용되는 방법은 CBOW(Continuous Bag of Words)와 Skip-gram입니다.
CBOW에서는 주변 단어를 입력으로 삼아 중심 단어를 예측하려고 합니다. 반대로 Skip-gram에서는 중심 단어를 입력으로 삼아 좌우에 등장하는 단어를 예측하려고 합니다. 하지만 이러한 방법들의 복잡한 부분에 대해서는 자세히 다루지 않겠어요. 이러한 방식들은 단어들 사이의 관계를 잡아내는 표현인 임베딩을 제공해줍니다. 이를 통해 방대한 양의 텍스트 데이터의 맥락을 분석합니다.
더 많은 임베딩 정보를 원한다면 인터넷에 다양한 정보가 많이 있어요. 그러나 시각적이고 단계별 안내를 선호한다면 Josh Starmer의 StatQuest 영상인 'Word Embedding and Word2Vec'을 시청하면 도움이 될 수 있어요.
모델 삽입으로 돌아가기
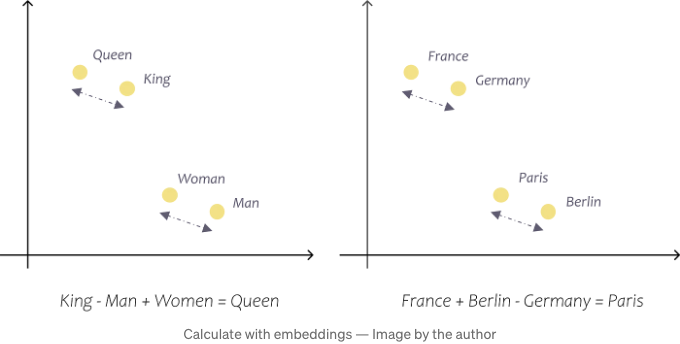
간단한 예제를 사용하여 설명한 것이 2차원 임베딩 공간에서 적용되는 것 뿐만 아니라 더 큰 모델에도 적용됩니다. 예를 들어, 표준 Word2Vec 벡터는 300차원이고, OpenAI의 Ada 모델은 1536차원을 가지고 있습니다. 이러한 사전 훈련된 벡터는 단어간의 관계와 의미를 정밀하게 포착하여 계산을 수행할 수 있도록 합니다. 예를 들어, 이러한 벡터를 사용하여 France + Berlin - Germany = Paris, 또는 faster + warm - fast = warmer와 같은 결과를 얻을 수 있습니다. (Tazzyman, n.d.)
다음에서는 OpenAI API를 사용하여 OpenAI의 LLM뿐만 아니라 임베딩 모델도 활용하려고 합니다.
참고: Embedding 모델과 LLM의 차이점은 Embedding 모델이 단어나 구절의 의미와 관련성을 포착하기 위해 벡터 표현을 생성하는 데 중점을 두는 반면, LLM은 제공된 프롬프트나 쿼리를 기반으로 일관성 있고 맥락에 부합하는 텍스트를 생성하도록 훈련된 다목적 모델입니다.
OpenAI Embedding 모델
OpenAI의 다양한 LLM과 마찬가지로, Ada, Davinci, Curie 및 Babbage와 같은 다양한 임베딩 모델 중에서 선택할 수 있습니다. 이 중 Ada-002는 현재 가장 빠르고 비용 효율적인 모델이며, Davinci는 일반적으로 가장 높은 정확도와 성능을 제공합니다. 그러나 사용 사례에 가장 적합한 모델을 찾으려면 직접 시도해보세요. OpenAI Embedding에 대해 자세히 이해하고 싶다면 OpenAI 문서를 참조할 수 있습니다.
Embedding 모델에 대한 우리의 목표는 텍스트 청크를 벡터로 변환하는 것입니다. 두 번째 세대의 Ada의 경우, 이러한 벡터는 1536개의 출력 차원을 갖고 있어서 1536차원 공간 내에서 특정 위치나 방향을 나타냅니다.
OpenAI에서는 이 임베딩 벡터를 다음과 같이 설명합니다:
“숫자적으로 유사한 임베딩은 의미적으로도 유사합니다. 예를 들어, "canine companions say"의 임베딩 벡터와 "woof"의 임베딩 벡터는 "meow"보다 더 유사할 것입니다." (OpenAI, 2022)
한 번 시도해 보겠습니다. 우리는 OpenAI의 API를 사용하여 텍스트 스니펫을 임베딩으로 변환합니다.
import openai
print(texts[0])
embedding = openai.Embedding.create(
input=texts[0].page_content, model="text-embedding-ada-002"
)["data"][0]["embedding"]
len(embedding)
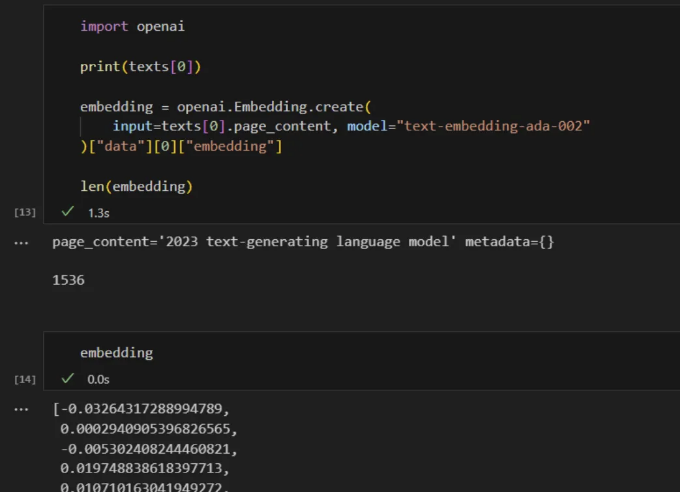
우리는 "2023 텍스트 생성 언어 모델"이라는 첫 번째 텍스트 청크를 1536 차원의 벡터로 변환합니다. 각 텍스트 청크에 대해 이 작업을 수행함으로써, 우리는 1536 차원의 공간에서 어떤 텍스트 청크가 서로에게 더 가깝고 유사한지 관찰할 수 있습니다.
한번 해보세요. 우리는 사용자의 질문을 텍스트 청크와 비교하기 위해 질문에 대한 임베딩을 생성한 다음, 이를 공간 내의 다른 데이터 포인트와 비교합니다.
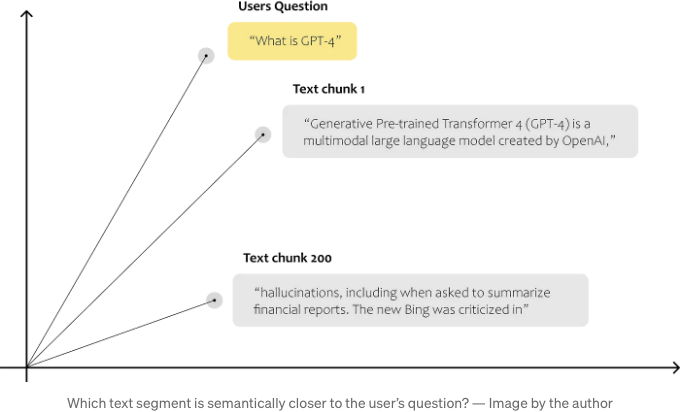
텍스트 청크와 사용자 질문을 벡터로 표현하면, 다양한 수학적 가능성을 탐색할 수 있어요. 두 데이터 포인트 간 유사성을 결정하려면, 다차원 공간에서 이들의 근접성을 계산해야 합니다. 이는 거리 측정 방법을 사용하여 달성됩니다. 점들 사이의 거리를 계산하기 위해 사용할 수 있는 여러 가지 방법이 있어요. Maarten Grootendorst는 그의 Medium 포스팅 중 하나에서 이들 중 아홉 가지를 요약해뒀어요.
일반적으로 사용되는 거리 측정 방법 중 하나는 코사인 유사도에요. 그러니 사용자의 질문과 텍스트 청크 사이의 코사인 유사도를 계산해보겠습니다:
import numpy as np
from numpy.linalg import norm
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
from bs4 import BeautifulSoup
import pandas as pd
import openai
####################################################################
# 문서 불러오기
####################################################################
# 스크랩할 위키피디아 페이지 URL
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# URL로 GET 요청 보내기
response = requests.get(url)
# BeautifulSoup을 사용하여 HTML 내용 파싱
soup = BeautifulSoup(response.content, 'html.parser')
# 페이지의 모든 텍스트 찾기
text = soup.get_text()
####################################################################
# 텍스트 분할
####################################################################
text_splitter = RecursiveCharacterTextSplitter(
# 아주 작은 청크 크기 설정, 예시용
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([text])
####################################################################
# 임베딩 계산
####################################################################
# 새로운 리스트에 모든 텍스트 청크 추가
text_chunks=[]
for text in texts:
text_chunks.append(text.page_content)
df = pd.DataFrame({'text_chunks': text_chunks})
####################################################################
# 텍스트 임베딩 얻기
####################################################################
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
####################################################################
# 사용자 질문에 대한 임베딩 계산
####################################################################
users_question = "What is GPT-4?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
# 계산된 코사인 유사도를 저장할 리스트 생성
cos_sim = []
for index, row in df.iterrows():
A = row.ada_embedding
B = question_embedding
# 코사인 유사도 계산
cosine = np.dot(A,B)/(norm(A)*norm(B))
cos_sim.append(cosine)
df["cos_sim"] = cos_sim
df.sort_values(by=["cos_sim"], ascending=False)
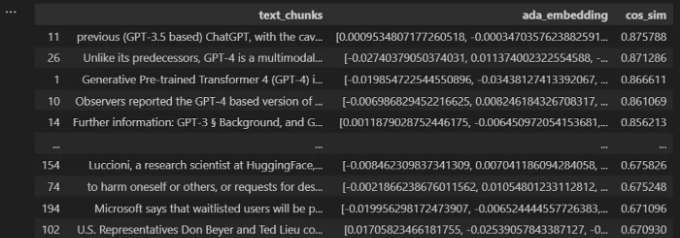
이제 우리는 질문에 답변하기 위해 LLM에 제공할 텍스트 청크의 수를 선택할 수 있는 옵션이 있습니다.
다음 단계는 사용하고 싶은 LLM을 결정하는 것입니다.
4. 사용할 모델 정의하기
Langchain은 OpenAI의 GPT 및 Huggingface를 포함한 다양한 모델 및 통합을 제공합니다. 우리가 OpenAI의 GPT를 Large Language Model로 사용하기로 결정하면, 첫 번째 단계는 API 키를 정의하는 것입니다. 현재 OpenAI는 일정량의 무료 사용 용량을 제공하지만, 한 달에 일정 토큰 수를 초과하면 유료 계정으로 전환해야 합니다.
만약 우리가 GPT를 사용하여 Google을 사용하는 방식과 유사한 짧은 질문에 답하는 데 사용한다면, 비용이 비교적 낮게 유지됩니다. 그러나 개인 데이터와 같이 방대한 맥락을 제공해야 하는 질문에 GPT를 사용한다면, 쿼리가 빠르게 수천 개의 토큰으로 늘어날 수 있습니다. 이로 인해 비용이 상당히 증가합니다. 하지만 걱정하지 마세요, 비용 한도를 설정할 수 있습니다.
토큰이란 무엇인가요?
더 간단히 말하면, 토큰은 기본적으로 단어나 단어 그룹입니다. 그러나 영어에서는 동사 시제, 복수형 또는 복합 단어와 같이 단어가 각기 다른 형태를 가질 수 있습니다. 이를 처리하기 위해 우리는 하위 단어 토크나이제이션을 사용할 수 있으며, 이는 단어를 뿌리, 접두사, 접미사 및 다른 언어적 요소와 같은 작은 부분으로 나누는 것을 의미합니다. 예를 들어, "tiresome"이라는 단어는 "tire"와 "some"으로 분할될 수 있으며, "tired"는 "tire"와 "d."로 나눌 수 있습니다. 이렇게 함으로써, 우리는 "tiresome"과 "tired"가 동일한 뿌리를 공유하고 유사한 유도를 가졌음을 인식할 수 있습니다. (Wang, 2023)
OpenAI는 토큰화기를 제공하여 어떤 것이 토큰으로 간주되는지 감을 잡을 수 있습니다. OpenAI에 따르면, 일반 영어 텍스트에 대한 하나의 토큰은 일반적으로 ~4개의 문자에 해당합니다. 이는 대략 ¾ 단어에 해당합니다 (따라서 100개의 토큰은 약 75단어와 동일합니다). OpenAI의 웹사이트에서 토큰화 앱을 찾아서 실제로 토큰으로 간주되는 것을 알아볼 수 있습니다.
오픈AI에서 사용자 계정에서 API 키를 찾을 수 있어요. 가장 간단한 방법은 구글에서 "OpenAI API 키"로 검색하는 것이에요. 이렇게 하면 새 키를 생성할 수 있는 설정 페이지로 바로 이동해요.
파이썬에서 사용하려면, 키를 "OPENAI_API_KEY"라는 새 환경 변수로 저장해야 해요:
import os
os.environ["OPENAI_API_KEY"] = "testapikey213412"
원하는 LLM을 선택한 후에는 몇 가지 매개변수를 미리 설정할 수 있어요. 오픈AI 플레이그라운드에서는 다양한 매개변수를 조정해보고 원하는 설정을 결정하기 전에 여러 가지로 놀 수 있는 기회가 주어져요.
Playground WebUI의 오른쪽에는 오픈AI에서 제공하는 여러 매개변수가 있습니다. 이 매개변수들을 사용하여 LLM의 출력에 영향을 미칠 수 있습니다. 살펴볼 가치 있는 두 가지 매개변수는 모델 선택과 온도입니다.
다양한 다른 모델 중에서 선택할 수 있습니다. Text-davinci-003 모델은 현재 가장 크고 강력합니다. 반면에 Text-ada-001과 같은 모델은 더 작고 빠르며 비용 효율적입니다.
아래는 OpenAI의 가격표 요약을 볼 수 있습니다. 에이다는 가장 강력한 다빈치 모델보다 싸며 성능이 충분하다면 비용을 절약하고 더 빠른 응답 시간을 달성할 수 있습니다.
먼저 다빈치를 사용하여 시작하고, 에이다로도 충분한 결과를 얻을 수 있는지 평가할 수 있습니다.
자, Jupyter Notebook에서 시도해봅시다. 우리는 langchain을 사용하여 GPT에 연결하고 있어요.
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.7)
만약 모든 속성을 포함한 리스트를 보고 싶다면 __dict__를 사용해주세요:
llm.__dict__
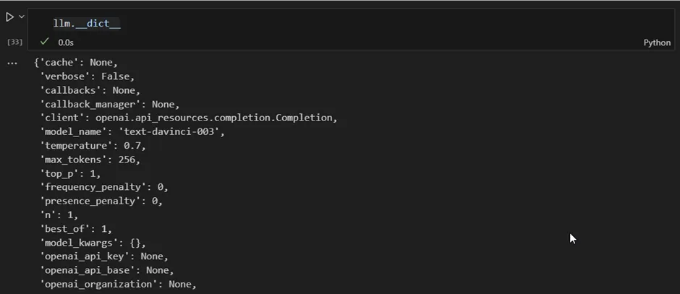
만약 특정 모델을 지정하지 않으면, langchain 커넥터는 기본적으로 "text-davinci-003"을 사용합니다.
이제 Python에서 모델을 직접 호출할 수 있습니다. 단순히 llm 함수를 호출하고 입력으로 프롬프트를 제공하면 됩니다.
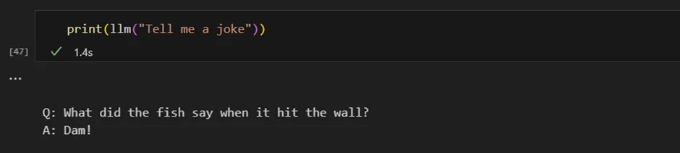
일반적인 인류 지식에 대해 GPT에게 물어볼 수 있습니다.
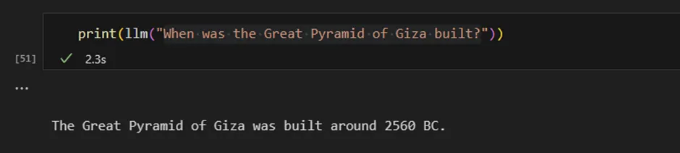
GPT는 훈련 데이터에 포함되지 않은 주제에 대해서는 제한된 정보만 제공할 수 있습니다. 이는 공개적으로 이용할 수 없는 구체적인 세부 사항이나 훈련 데이터가 마지막으로 업데이트된 후 발생한 사건을 포함합니다.
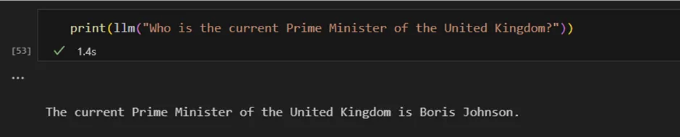
그러면 모델이 최신 이슈에 대한 질문에 대답할 수 있도록 어떻게 할 수 있을까요?
이전에 언급했던 것처럼 이를 수행할 수 있는 방법이 있습니다. 우리는 모델에 필요한 정보를 prompt 안에 주입해주어야 합니다.
영국의 현 장권자에 대한 질문에 답하기 위해, "영국 총리 목록" 위키피디아 문서에서 정보를 prompt에 넣어줍니다. 이 과정을 요약하면 다음과 같습니다:
- 문서를 불러옵니다
- 텍스트를 텍스트 청크로 분할합니다
- 텍스트 청크에 대한 임베딩을 계산합니다
- 모든 텍스트 청크와 사용자의 질문 사이의 유사성을 계산합니다
import requests
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
import numpy as np
from numpy.linalg import norm
import pandas as pd
import openai
####################################################################
# 문서 로드
####################################################################
# 스크레이핑할 위키피디아 페이지 URL
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# URL로 GET 요청 보내기
response = requests.get(url)
# BeautifulSoup을 사용하여 HTML 컨텐츠 파싱
soup = BeautifulSoup(response.content, 'html.parser')
# 페이지의 모든 텍스트 찾기
text = soup.get_text()
####################################################################
# 텍스트 분할
####################################################################
text_splitter = RecursiveCharacterTextSplitter(
# 아주 작은 청크 크기 설정(강조 용도)
chunk_size=100,
chunk_overlap=20,
length_function=len,
)
texts = text_splitter.create_documents([text])
####################################################################
# 임베딩 계산
####################################################################
# 모든 텍스트 청크를 포함하는 새 리스트 생성
text_chunks = []
for text in texts:
text_chunks.append(text.page_content)
df = pd.DataFrame({'text_chunks': text_chunks})
# text-embedding-ada 모델에서 임베딩 가져오기
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input=[text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
####################################################################
# 사용자 질문과의 유사도 계산
####################################################################
# 사용자 질문에 대한 임베딩 계산
users_question = "영국의 현 재 총리는 누구인가요?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
이제 사용자 질문과 가장 유사한 텍스트 청크를 찾아보겠습니다:
from langchain import PromptTemplate
from langchain.llms import OpenAI
# 사용자 질문에 대한 임베딩 계산
users_question = "영국의 현 재 총리는 누구인가요?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
# 계산된 코사인 유사도를 저장할 리스트 생성
cos_sim = []
for index, row in df.iterrows():
A = row.ada_embedding
B = question_embedding
# 코사인 유사도 계산
cosine = np.dot(A, B) / (norm(A) * norm(B))
cos_sim.append(cosine)
df["cos_sim"] = cos_sim
df.sort_values(by=["cos_sim"], ascending=False)
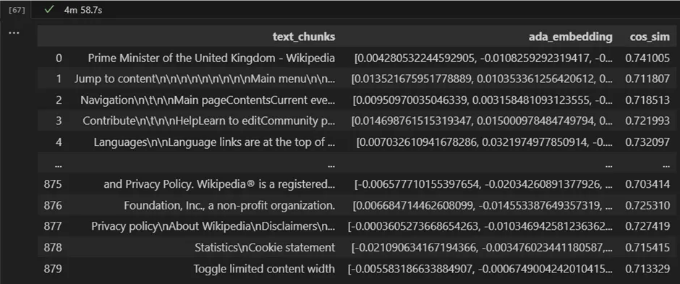
텍스트 조각들이 좀 어수선해 보이지만, 한번 시도해 보자면서 텍스트 세그먼트를 식별했구나.
우리 모델이 질문에 대답할 수 있는 능력이 있는지 테스트해볼까? 이를 위해서는 모델에게 원하는 작업을 명확히 전달하는 방식으로 prompt를 구성해야 해.
5. Prompt 템플릿 정의
이제 우리가 찾고자 하는 정보가 포함된 텍스트 조각들이 있으니, prompt를 작성해야 해. prompt 내에서도 모델이 질문에 답변하도록 원하는 방식을 지정해야 해. 우리가 모드를 정의할 때는, LLM이 답변을 생성하는 원하는 동작 스타일을 명시하는 것이다.
LLM은 다양한 작업에 활용될 수 있으며, 가능한 여러 가지 예시를 살펴보겠습니다:
- 요약: "다음 텍스트를 임원들을 위해 3단락으로 요약해주세요: [TEXT]"
- 지식 추출: "다음 기사를 기반으로, 사람들이 집을 구매하기 전에 고려해야 할 사항은 무엇인가요?"
- 콘텐츠 작성 (이메일, 메시지, 코드 등): "프로젝트 문서에 대한 업데이트를 요청하는 이메일을 Jane에게 작성해주세요. 비공식적이고 친근한 톤을 사용해주세요."
- 문법 및 스타일 개선: "표준 영어로 수정하고 친근한 톤으로 변경해주세요: [TEXT]"
- 분류: "각 메시지를 지원 티켓 유형으로 분류해주세요: [TEXT]"
이 예시를 통해, Wikipedia에서 데이터를 추출하고 사용자와 대화하는 것처럼 상호작용하는 솔루션을 구현하고 싶습니다. 이를 통해 원동력을 부여하고 도움을 주는 헬프 데스크 전문가처럼 질문에 답변하길 원합니다.
LLM을 올바른 방향으로 안내하기 위해, 다음 지시사항을 프롬프트에 추가하겠습니다:
위의 정보를 Markdown 형식으로 표로 변경하세요.
해당 템플릿을 사용하여 우리의 프롬프트에 맥락과 사용자의 질문을 모두 통합하고 있습니다. 그 결과로 나온 응답은 다음과 같습니다:

의왹으로, 심지어 이 간단한 구현으로도 어느 정도 만족스러운 결과물이 만들어졌습니다. 영국 총리들에 관해 시스템에 몇 가지 추가 질문을 해보도록 하겠습니다. 모든 것을 그대로 유지하고 사용자의 질문만 대체해 보겠습니다:
users_question = "영국의 첫 번째 총리는 누구였나요?"

기능은 일부 정상적으로 작동하는 것으로 보입니다. 그러나 저희의 목표는 이 느린 프로세스를 견고하고 효율적인 것으로 변환하는 것입니다. 이를 달성하기 위해 임베딩 및 인덱스를 벡터 저장소에 저장하는 인덱싱 단계를 도입합니다. 이를 통해 전체 성능을 향상시키고 응답 시간을 줄일 수 있습니다.
6. 벡터 저장소 생성 (벡터 데이터베이스)
벡터 저장소는 벡터로 표현할 수 있는 대량의 데이터를 저장하고 검색하는 데 최적화된 데이터 저장소 유형입니다. 이러한 유형의 데이터베이스는 유사성 측정이나 다른 수학적 연산과 같은 다양한 기준에 따라 데이터의 하위 집합을 효율적으로 질의하고 검색할 수 있습니다.
텍스트 데이터를 벡터로 변환하는 것은 첫 번째 단계입니다. 그러나 우리의 요구 사항에 충분하지는 않습니다. 만약 우리가 벡터를 데이터 프레임에 저장하고 매번 쿼리를 받을 때마다 단어 간 유사성을 단계별로 확인하여 검색한다면, 전체 프로세스는 매우 느려질 것입니다.
임베딩을 효율적으로 검색하기 위해서는 인덱싱이 필요합니다. 인덱싱은 벡터 데이터베이스의 두 번째 중요한 구성 요소입니다. 인덱스는 각 쿼리를 모든 문서 또는 항목과의 유사성을 계산할 필요 없이 가장 관련성 있는 문서나 항목에 매핑하는 방법을 제공합니다.
최근 몇 년간 다양한 벡터 저장소가 출시되었습니다. 특히 LLMs 분야에서는 벡터 저장소에 대한 주목이 급증했습니다.
이제 한 가지를 선택해서 우리의 사용 사례에 적용해 보겠습니다. 이전 섹션에서 한 것과 비슷하게, 우리는 다시 임베딩을 계산하고 벡터 저장소에 저장합니다. 이를 위해 LangChain과 chroma에서 적합한 모듈을 사용하고 있습니다.
- 사용자의 질문에 답변하기 위해 사용할 데이터를 수집하세요:
import requests
from bs4 import BeautifulSoup
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
# 스크래핑할 위키피디아 페이지의 URL
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# URL로 GET 요청 보내기
response = requests.get(url)
# BeautifulSoup을 사용하여 HTML 콘텐츠 파싱
soup = BeautifulSoup(response.content, 'html.parser')
# 페이지에서 모든 텍스트 찾기
text = soup.get_text()
text = text.replace('\n', '')
# 쓰기 모드로 'output.txt'라는 새 파일 열고 파일 객체를 변수에 저장
with open('output.txt', 'w', encoding='utf-8') as file:
# 문자열을 파일에 작성
file.write(text)
- 데이터를 로드하고 데이터를 텍스트 청크로 나누는 방법을 정의하세요.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 문서를 로드합니다.
with open('./output.txt', encoding='utf-8') as f:
text = f.read()
# 텍스트 스플리터를 정의합니다.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 100,
length_function = len,
)
texts = text_splitter.create_documents([text])
- 텍스트 청크에 대한 임베딩을 계산하고 벡터 저장소에 저장할 임베딩 모델을 정의하세요 (여기서는 Chroma를 사용합니다).
아래는 테이블 태그를 Markdown 형식으로 변환한 코드입니다.
<img src="/TIL/assets/img/2024-07-14-AllYouNeedtoKnowtoBuildYourFirstLLMApp_28.png" />
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 임베딩 모델 정의
embeddings = OpenAIEmbeddings()
# 텍스트 청크 및 임베딩 모델을 사용하여 벡터 스토어 채우기
db = Chroma.from_documents(texts, embeddings)
4. 사용자 질문에 대한 임베딩 계산, 벡터 스토어에서 유사한 텍스트 청크 찾아서 사용하여 프롬프트 만들기
<img src="/TIL/assets/img/2024-07-14-AllYouNeedtoKnowtoBuildYourFirstLLMApp_29.png" />
from langchain.llms import OpenAI
from langchain import PromptTemplate
users_question = "영국의 현 재 총리는 누구입니까?"
# 우리의 벡터 저장소를 사용하여 유사한 텍스트 청크를 찾습니다
results = db.similarity_search(
query=user_question,
n_results=5
)
# 프롬프트 템플릿 정의
template = """
당신은 도움을 주는 채팅 봇입니다! 다음 컨텍스트 섹션을 고려하여 질문에 답하십시오.
주어진 컨텍스트만 사용하세요. 확실하지 않은 경우와 답변이 문서에 명시적으로 기재되어
있지 않은 경우 "죄송합니다, 해당 내용을 도와드릴 방법을 모르겠어요" 라고 말해주세요.
컨텍스트 섹션:
{context}
질문:
{users_question}
답변:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])
# 프롬프트 템플릿 채우기
prompt_text = prompt.format(context = results, users_question = users_question)
# 정의된 LLM에 요청하기
llm(prompt_text)

요약
LLM이 데이터에 관한 질문을 분석하고 답변할 수 있도록 하려면 보통 모델을 세밀 조정하지 않습니다. 대신, 세밀 조정 과정에서의 목표는 모델의 특정 작업에 효과적으로 응답할 수 있는 능력을 향상시키는 것입니다. 새로운 정보를 가르치는 대신입니다.
알파카 7B의 경우, LLM (LLaMA)은 챗봇처럼 행동하고 상호작용하도록 세밀하게 조정되었습니다. 모델의 응답을 개선하는 데 초점을 맞추었으며 완전히 새로운 정보를 가르치는 데 중점을 두지는 않았습니다.
따라서 우리 자체 데이터에 대한 질문에 답변할 수 있도록 Context Injection 접근 방식을 사용합니다. Context Injection을 사용한 LLM 앱을 만드는 것은 비교적 간단한 과정입니다. 주요 도전 과제는 데이터를 벡터 데이터베이스에 저장하도록 조직화하고 형식을 맞추는 것에 있습니다. 이 단계는 컨텍스트적으로 유사한 정보를 효율적으로 검색하고 신뢰할 수 있는 결과를 보장하는 데 중요합니다.
이 기사의 목표는 임베딩 모델, 벡터 스토어 및 LLM을 사용하여 사용자 쿼리를 처리할 때의 미니멀리스트 접근 방식을 보여주는 것이었습니다. 이 기술들이 어떻게 함께 작동하여 계속 변화하는 사실에도 관련성 있고 정확한 답변을 제공할 수 있는지 보여줍니다.
- 무료로 구독하여 새로운 이야기를 발행할 때 알림을 받으세요.
- 한 달에 3개 이상의 무료 이야기를 읽고 싶으세요? — 월 5달러로 미디움 회원이 되세요. 가입할 때 제 추천 링크를 사용하면 저를 지원할 수 있습니다. 추가 비용은 없습니다.
참고 자료
AssemblyAI (감독). (2022, 1월 5일). 단어 임베딩에 대한 완전한 개요. YouTube 동영상 링크
Grootendorst, M. (2021, 12월 7일). 데이터 과학에서의 9가지 거리 측정 방법. Medium. 링크
Langchain. (2023). LangChain에 오신 것을 환영합니다 - 🦜🔗 LangChain 0.0.189. 링크
Nelson, P. (2023). Search and Unstructured Data Analytics Trends | Accenture. Search and Content Analytics Blog. 링크
OpenAI. (2022). Introducing text and code embeddings. 링크
OpenAI (Director). (2023, March 14). What can you do with GPT-4? 링크
Porche AG. (2023, 5월 17일). ChatGPT 및 기업 지식: "내 비즈니스 부문을 위한 챗봇을 어떻게 만들 수 있을까?" #NextLevelGermanEngineering. 링크
Tazzyman, S. (2023). 신경망 모델. NLP-Guidance. 링크
Wang, W. (2023, 4월 12일). 트랜스포머 기반 모델에 대한 심층적인 분석. Medium.