
내가 사용해 본 모든 데이터 분석 및 조작 도구에는 윈도우 연산이 있습니다. 일부는 다른 것보다 유연하고 능력이 높지만, 윈도우에서 계산을 할 수 있는 것이 필수적입니다.
데이터 분석에서 윈도우란 무엇인가요?
윈도우는 어떤 방식으로 관련된 행들의 집합입니다. 이 관련은 동일한 그룹에 속하거나 연속적인 n일에 존재하는 것일 수 있습니다. 필요한 제약 조건으로 윈도우를 생성한 후, 해당 윈도우에서 계산이나 집계를 수행할 수 있습니다.
이 기사에서는 PySpark를 사용하여 창 작업에 대해 포괄적으로 이해할 수 있는 5가지 구체적인 예제를 살펴보겠습니다. 우리는 파티션과 함께 윈도우를 생성하는 방법, 이러한 윈도우를 사용자 정의하는 방법, 그리고 이를 통해 계산을 수행하는 방법을 배울 것입니다.
PySpark는 대규모 데이터 처리에 사용되는 분석 엔진인 Spark의 Python API입니다.
데이터
이 기사를 위해 모의 데이터로 샘플 데이터셋을 준비했고, 해당 데이터셋은 제 저장소에서 다운로드할 수 있습니다. 이 기사에서 사용할 데이터셋은 "sample_sales_pyspark.csv"라고 부릅니다.
자, spark 세션을 시작하고 이 데이터셋으로부터 DataFrame을 생성해 봅시다.
from pyspark.sql import SparkSession
from pyspark.sql import Window, functions as F
spark = SparkSession.builder.getOrCreate()
data = spark.read.csv("sample_sales_pyspark.csv", header=True)
data.show(15)
# output
+----------+------------+----------+---------+---------+-----+
|store_code|product_code|sales_date|sales_qty|sales_rev|price|
+----------+------------+----------+---------+---------+-----+
| B1| 89912|2021-05-01| 14| 17654| 1261|
| B1| 89912|2021-05-02| 19| 24282| 1278|
| B1| 89912|2021-05-03| 15| 19305| 1287|
| B1| 89912|2021-05-04| 21| 28287| 1347|
| B1| 89912|2021-05-05| 4| 5404| 1351|
| B1| 89912|2021-05-06| 5| 6775| 1355|
| B1| 89912|2021-05-07| 10| 12420| 1242|
| B1| 89912|2021-05-08| 18| 22500| 1250|
| B1| 89912|2021-05-09| 5| 6555| 1311|
| B1| 89912|2021-05-10| 2| 2638| 1319|
| B1| 89912|2021-05-11| 15| 19575| 1305|
| B1| 89912|2021-05-12| 21| 28182| 1342|
| B1| 89912|2021-05-13| 7| 9268| 1324|
| B1| 89912|2021-05-14| 17| 22576| 1328|
| B1| 89912|2021-05-15| 16| 20320| 1270|
+----------+------------+----------+---------+---------+-----+
예제 1
우선, 파티션과 정렬 열을 기준으로 윈도우를 생성합니다. DataFrame에서는 각 제품의 누적 판매량을 각 상점별로 계산하려면 윈도우를 다음과 같이 정의합니다:
window = Window.partitionBy("store_code", "product_code").orderBy("sales_date")
누적 판매량을 계산하려면 이 윈도우 위에 sum 함수를 적용하기만 하면 됩니다:
data = data.withColumn("total_sales", F.sum("sales_qty").over(window))
이 코드는 "total_sales"라는 새 열을 만들며, 이전에 정의한 윈도우 상에서 계산된 판매 수량의 누적 합계를 포함합니다.
" B1" 스토어의 첫 30개 행을 확인해봐서 누적값이 올바르게 계산되었는지 확인해보세요:
data \
.filter((F.col("store_code")=="B1")) \
.select("store_code", "product_code", "sales_date", "sales_qty", "total_sales") \
.show(30)
# output
+----------+------------+----------+---------+-----------+
|store_code|product_code|sales_date|sales_qty|total_sales|
+----------+------------+----------+---------+-----------+
| B1| 89912|2021-05-01| 14| 14.0|
| B1| 89912|2021-05-02| 19| 33.0|
| B1| 89912|2021-05-03| 15| 48.0|
| B1| 89912|2021-05-04| 21| 69.0|
| B1| 89912|2021-05-05| 4| 73.0|
| B1| 89912|2021-05-06| 5| 78.0|
| B1| 89912|2021-05-07| 10| 88.0|
| B1| 89912|2021-05-08| 18| 106.0|
| B1| 89912|2021-05-09| 5| 111.0|
| B1| 89912|2021-05-10| 2| 113.0|
| B1| 89912|2021-05-11| 15| 128.0|
| B1| 89912|2021-05-12| 21| 149.0|
| B1| 89912|2021-05-13| 7| 156.0|
| B1| 89912|2021-05-14| 17| 173.0|
| B1| 89912|2021-05-15| 16| 189.0|
| B1| 89915|2021-05-01| 20| 20.0|
| B1| 89915|2021-05-02| 0| 20.0|
| B1| 89915|2021-05-03| 10| 30.0|
| B1| 89915|2021-05-04| 13| 43.0|
| B1| 89915|2021-05-05| 21| 64.0|
| B1| 89915|2021-05-06| 4| 68.0|
| B1| 89915|2021-05-07| 20| 88.0|
| B1| 89915|2021-05-08| 16| 104.0|
| B1| 89915|2021-05-09| 21| 125.0|
| B1| 89915|2021-05-10| 2| 127.0|
| B1| 89915|2021-05-11| 15| 142.0|
| B1| 89915|2021-05-12| 15| 157.0|
| B1| 89915|2021-05-13| 14| 171.0|
| B1| 89915|2021-05-14| 3| 174.0|
| B1| 89915|2021-05-15| 1| 175.0|
+----------+------------+----------+---------+-----------+
첫 15개 행은 제품 89912에 속하므로 총 판매액 열은 판매 수량 열의 값들의 누적 합을 보여줍니다. 16번째 행에서 제품 코드가 변경되어 누적 합이 초기화됩니다. 이는 우리가 스토어 코드와 제품 코드로 분할된 윈도우를 생성했기 때문입니다.
예시 2
창을 생성한 후에는 다양한 집계를 계산할 수 있어요. 예를 들어, 앞에서 정의한 창에 대해 max 함수를 적용하면, 결과는 주어진 상점의 제품의 누적 최대 가격이 될 거예요.
창을 생성하는 코드를 작성할 테니까, 위를 계속 찾지 않아도 돼요.
# 창 정의
window = Window.partitionBy("store_code", "product_code").orderBy("sales_date")
# 누적 최대 가격
data = data.withColumn("max_price", F.max("price").over(window))
# 결과 확인
data \
.filter((F.col("store_code")=="B1")) \
.select("store_code", "product_code", "sales_date", "price", "max_price") \
.show(15)
# 결과
+----------+------------+----------+-----+---------+
|store_code|product_code|sales_date|price|max_price|
+----------+------------+----------+-----+---------+
| B1| 89912|2021-05-01| 1261| 1261|
| B1| 89912|2021-05-02| 1278| 1278|
| B1| 89912|2021-05-03| 1287| 1287|
| B1| 89912|2021-05-04| 1347| 1347|
| B1| 89912|2021-05-05| 1351| 1351|
| B1| 89912|2021-05-06| 1355| 1355|
| B1| 89912|2021-05-07| 1242| 1355|
| B1| 89912|2021-05-08| 1250| 1355|
| B1| 89912|2021-05-09| 1311| 1355|
| B1| 89912|2021-05-10| 1319| 1355|
| B1| 89912|2021-05-11| 1305| 1355|
| B1| 89912|2021-05-12| 1342| 1355|
| B1| 89912|2021-05-13| 1324| 1355|
| B1| 89912|2021-05-14| 1328| 1355|
| B1| 89912|2021-05-15| 1270| 1355|
+----------+------------+----------+-----+---------+
"max_price" 열의 값은 증가하거나 동일하게 유지돼요. 7번째 행에서는 가격이 실제로 낮아지지만, 누적 최대 값이 표시돼서 최대 가격 값은 그대로 유지돌아요.
예제 3
lag 및 lead는 일반적으로 사용되는 윈도우 함수 중 일부입니다. 시계열 데이터를 분석할 때 자주 사용합니다. 현재 행의 앞이나 뒤에 오프셋된 값을 반환합니다.
- lag("sales_qty", 1) : 1행 전
- lag("sales_qty", 2) : 2행 전
- lead("sales_qty", 1) : 1행 후
- lead("sales_qty", 2) : 2행 후
lag의 음수 값을 사용하여 오프셋을 지정할 수 있으므로 lag("sales_qty", 1)은 lead("sales_qty", -1)과 동일합니다. 둘 다 이전 행의 값을 제공합니다. 테스트해 봅시다.
# 창을 정의합니다
window = Window.partitionBy("store_code", "product_code").orderBy("sales_date")
# 전일 판매 수량
data = data.withColumn("prev_day_sales_lag", F.lag("sales_qty", 1).over(window))
data = data.withColumn("prev_day_sales_lead", F.lead("sales_qty", -1).over(window))
# 다른 제품-매장 쌍에 대한 출력 확인
data \
.filter((F.col("store_code")=="A1") & (F.col("product_code")=="95955")) \
.select("sales_date", "sales_qty", "prev_day_sales_lag", "prev_day_sales_lead") \
.show(15)
# 출력 결과
+----------+---------+------------------+-------------------+
|sales_date|sales_qty|prev_day_sales_lag|prev_day_sales_lead|
+----------+---------+------------------+-------------------+
|2021-05-01| 13| NULL| NULL|
|2021-05-02| 3| 13| 13|
|2021-05-03| 22| 3| 3|
|2021-05-04| 17| 22| 22|
|2021-05-05| 20| 17| 17|
|2021-05-06| 14| 20| 20|
|2021-05-07| 10| 14| 14|
|2021-05-08| 10| 10| 10|
|2021-05-09| 15| 10| 10|
|2021-05-10| 15| 15| 15|
|2021-05-11| 8| 15| 15|
|2021-05-12| 9| 8| 8|
|2021-05-13| 13| 9| 9|
|2021-05-14| 6| 13| 13|
|2021-05-15| 21| 6| 6|
+----------+---------+------------------+-------------------+
첫 번째 행의 전일 값은 NULL입니다. 이는 해당 행이 이전 날짜를 가지고 있지 않기 때문에 발생합니다.
예시 4
행을 기반으로 한 창을 정의한 후, rowsBetween 메소드를 사용하여 범위를 좁힐 수 있습니다.
요즘 세 가지 이유로 판매량의 평균을 계산하려면 이 창을 다음과 같이 정의할 수 있습니다:
window = Window \
.partitionBy("store_code", "product_code") \
.orderBy("sales_date") \
.rowsBetween(-3, -1)
첫 번째 매개변수가 시작이고 두 번째 매개변수가 끝입니다. 각 행에 대한 마지막 세 행을 포함하는 창을 사용자 정의했습니다. "-1"은 현재 행의 이전 행을 가리키고 "-3"은 현재 행의 세 번째 이전 행을 나타냅니다.
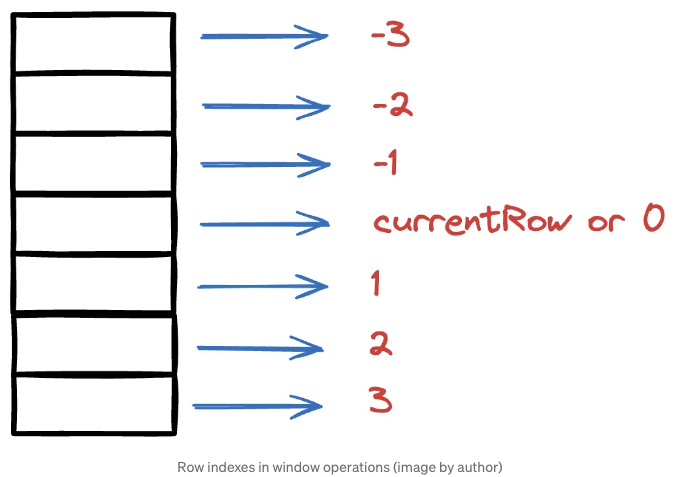
지난 세 날 동안의 평균 판매 수량을 계산하려면 이 윈도우에 mean 함수를 적용하기만 하면 됩니다.
# 윈도우 정의
window = Window \
.partitionBy("store_code", "product_code") \
.orderBy("sales_date") \
.rowsBetween(-3, -1)
# 평균 계산
data = data.withColumn("last_3_day_avg", F.mean("sales_qty").over(window))
# 데이터 표시
data \
.filter((F.col("store_code")=="A1") & (F.col("product_code")=="95955")) \
.select("sales_date", "sales_qty", "last_3_day_avg") \
.show()
# 결과
+----------+---------+------------------+
|sales_date|sales_qty| last_3_day_avg|
+----------+---------+------------------+
|2021-05-01| 13| NULL|
|2021-05-02| 3| 13.0|
|2021-05-03| 22| 8.0|
|2021-05-04| 17|12.666666666666666|
|2021-05-05| 20| 14.0|
|2021-05-06| 14|19.666666666666668|
|2021-05-07| 10| 17.0|
|2021-05-08| 10|14.666666666666666|
|2021-05-09| 15|11.333333333333334|
|2021-05-10| 15|11.666666666666666|
|2021-05-11| 8|13.333333333333334|
|2021-05-12| 9|12.666666666666666|
|2021-05-13| 13|10.666666666666666|
|2021-05-14| 6| 10.0|
|2021-05-15| 21| 9.333333333333334|
+----------+---------+------------------+
예를 들어, 네 번째 행인 "2021-05-04"의 경우, 지난 세 행(13, 3, 22)의 값의 평균인 13.75입니다.
예시 5
입력 데이터의 각 행에서 정의된 창 내의 열의 누적 평균 값을 계산해야 하는 경우를 생각해보세요. 각 행에 대해 계산은 창의 첫 번째 행과 현재 행 사이의 행을 포함해야 합니다.
이를 위해 unboundedPreceding으로 시작점을 정의할 수 있습니다. 마찬가지로, 창의 끝까지 가려면 unboundedFollowing을 사용할 수 있습니다.
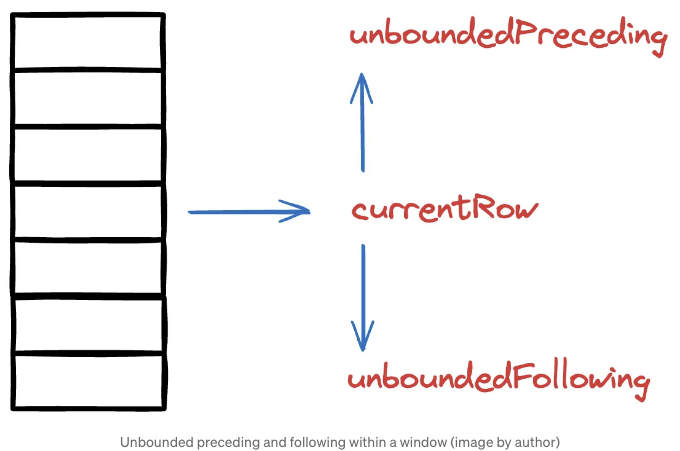
창을 정의한 후 나머지는 동일합니다.
# 윈도우 정의
window = Window \
.partitionBy("store_code", "product_code") \
.orderBy("sales_date") \
.rowsBetween(Window.unboundedPreceding, -1)
# 평균 계산
data = data.withColumn("누적평균", F.mean("sales_qty").over(window))
# 데이터 출력
data \
.filter((F.col("store_code")=="A1") & (F.col("product_code")=="95955")) \
.select("sales_date", "sales_qty", "누적평균") \
.show()
# 결과
+----------+---------+------------------+
|sales_date|sales_qty| 누적평균 |
+----------+---------+------------------+
|2021-05-01| 13| NULL|
|2021-05-02| 3| 13.0|
|2021-05-03| 22| 8.0|
|2021-05-04| 17|12.666666666666666|
|2021-05-05| 20| 13.75|
|2021-05-06| 14| 15.0|
|2021-05-07| 10|14.833333333333334|
|2021-05-08| 10|14.142857142857142|
|2021-05-09| 15| 13.625|
|2021-05-10| 15|13.777777777777779|
|2021-05-11| 8| 13.9|
|2021-05-12| 9|13.363636363636363|
|2021-05-13| 13| 13.0|
|2021-05-14| 6| 13.0|
|2021-05-15| 21| 12.5|
+----------+---------+------------------+
누적평균 열에는 현재 행까지의 모든 행의 평균 판매량이 포함됩니다 (현재 행은 제외됨). 현재 행을 누적 평균 계산에 포함하려면 다음과 같이 윈도우를 정의할 수 있습니다:
window = Window \
.partitionBy("store_code", "product_code") \
.orderBy("sales_date") \
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
마지막으로
윈도우 작업은 데이터 분석에 있어 근본적인 작업입니다. 특히 시계열 데이터를 다루거나 시계열 데이터에 대한 예측 분석을 위해 머신러닝 모델을 만들 때 다양한 피처를 생성하기 위해 윈도우 작업을 사용합니다.
대부분의 데이터 분석 및 조작 도구는 윈도우 작업을 수행하는 데 도움이 되는 기능을 제공합니다. 이 글에서는 PySpark를 사용하여 이러한 작업을 수행하는 방법을 배웠습니다.
읽어 주셔서 감사합니다. 피드백이 있으시면 언제든지 알려주세요.