
오픈 소스 대형 언어 모델의 성능이 계속해서 향상되면서, 코드 작성 및 분석, 추천, 텍스트 요약 및 질문-응답(QA)을 포함한 다양한 응용 프로그램에 진입하고 있습니다. QA 관련 질문에 대해 언어 모델이 자주 실패하는데, 이는 훈련 중에 사용되지 않은 문서와 관련된 질문들에 적용될 때 발생합니다. 그리고 이러한 내부 문서들 중 많은 것들은 규정 준수, 영업 비밀 또는 개인 정보 보호를 위해 기업의 벽 안에 유지되어야 합니다. 이러한 문서에 대해 쿼리를 실행할 때, 언어 모델은 가상 현상을 겪는데, 이는 관련 없거나 가짜 또는 일관성 없는 내용을 생성합니다.
이러한 도전과제를 해결하기 위한 하나의 기술은 검색 보강 생성(Retrieval-Augmented Generation, RAG)입니다. 이는 답변 생성 이전에 훈련 데이터 소스 외부의 권위 있는 지식 베이스를 참조하여 언어 모델의 응답을 개선하는 과정을 포함합니다. RAG 어플리케이션은 말뭉치로부터 관련 문서 단편을 가져오는 검색 시스템과, 검색된 단편을 컨텍스트로 사용하여 답변을 생성하는 언어 모델로 구성됩니다. 당연히, 말뭉치의 품질과 그것이 표현된 벡터 공간, 즉 임베딩(embeddings)은 RAG의 정확도에 중요한 역할을 할 것입니다.
본 기사에서는 FAISS 벡터 공간의 다차원 임베딩을 renumics-spotlight 시각화 라이브러리를 사용하여 2차원으로 시각화하는 방법을 살펴보겠습니다. 특정 핵심 벡터화 매개변수를 변화시킴으로써 RAG 응답 정확도를 향상시킬 기회를 찾아보겠습니다. 그리고 선택한 언어 모델로는 TinyLlama 1.1B Chat을 채택할 것인데, 이는 Llama 2와 동일한 아키텍처와 토크나이저를 갖추고 있습니다 [1]. 이 모델은 리소스 풋프린트가 상당히 작고 빠른 실행 시간을 가지고 있으면서 정확도가 비례적으로 감소하지 않는 장점을 갖추고 있습니다. 이는 빠른 실험에 이상적입니다.
목차
1.0 환경 설정 2.0 설계 및 구현 2.1 LoadFVectorize 모듈 2.2 주요 모듈 3.0 테스트 실행 3.1 청크 크기 및 중첩 매개변수 테스트 4.0 최종 생각
1.0 환경 설정
이 실험은 8GB RAM을 갖춘 MacBook Air M1에서 수행될 예정입니다. 여기서 사용하는 Python 버전은 3.10.5입니다. 먼저, 이 프로젝트를 관리하기 위해 가상 환경을 생성해 봅시다. 환경을 생성하고 활성화하기 위해 다음을 실행해 봅시다:
python3.10 -m venv mychat
source mychat/bin/activate
Library renumics-spotlight은 UMAP와 유사한 시각화를 사용하여 고차원 임베딩을 더 관리하기 쉬운 2D 시각화로 줄이는 동시에 중요한 속성을 보존합니다 [2]. 이제 필요한 모든 라이브러리를 설치해 보겠습니다:
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf
pip install renumics-spotlight
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
위의 마지막 줄은 M1 프로세서에서 하드웨어 가속을 사용하여 TinyLlama를 로드하는 데 사용될 메탈 지원이 포함된 llama-cpp-python 라이브러리를 설치하는 것을 의미합니다. Metal을 사용하면 계산이 GPU에서 실행됩니다.
환경이 준비되었으므로 시스템 설계를 살펴보고 구현을 따라갑시다.
2.0 디자인 및 구현
이 QA 시스템에는 그림 1에 설명된 두 모듈이 있습니다.
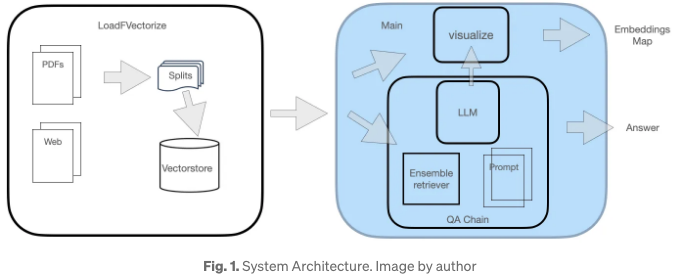
LoadFVectorize 모듈은 PDF 또는 웹 문서를 로드하는 작업을 포함합니다. 초기 테스트 및 시각화를 위해, 최근에 출시된 (2023년 12월) 440페이지의 벤더 배포 가이드가 관심 문서로 사용됩니다. 이 모듈은 문서의 분할 및 벡터화를 처리합니다.
두 번째 모듈은 LLM을 로드하고 FAISS 검색기를 인스턴스화한 후, LLM, 검색기 및 사용자 정의 프롬프트를 포함하는 검색 체인을 생성하는 것으로 구성되어 있습니다. 마지막으로 벡터 공간 시각화를 시작합니다.
두 모듈의 세부 정보는 더 설명되어 있습니다.
2.1 Module LoadFVectorize
이 모듈은 3가지 함수로 구성되어 있습니다:
- load_doc 함수는 온라인 pdf 문서를 로드하고, 512자씩 묶어 chunk 단위로 나누며 100자의 overlap을 가지고 문서 목록을 반환합니다.
- vectorize 함수는 위 load_doc 함수를 호출하여 문서의 chunked 목록을 가져와 임베딩을 생성하고 opdf_index 로컬 디렉토리에 저장한 뒤 FAISS 인스턴스를 반환합니다.
- load_db 함수는 opdf_index 디렉토리 내에 FAISS 벡터 저장소가 있는지 확인하고, 없는 경우 vectorize 함수를 호출하여 문서를 로드하고 벡터화합니다. 최종적으로 FAISS 객체를 반환합니다.
이 모듈의 전체 코드 목록은 아래와 같습니다.
# LoadFVectorize.py
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 온라인 pdf에 접근
def load_doc() -> 'List[Document]':
loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&version=9.15.0")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
return docs
# 벡터화 및 디스크에 저장
def vectorize(embeddings_model) -> 'FAISS':
docs = load_doc()
db = FAISS.from_documents(docs, embeddings_model)
db.save_local("./opdf_index")
return db
# 디스크에서 벡터 저장소를 로드하려고 시도
def load_db() -> 'FAISS':
embeddings_model = HuggingFaceEmbeddings()
try:
db = FAISS.load_local("./opdf_index", embeddings_model)
except Exception as e:
print(f'Exception: {e}\n디스크에 인덱스가 없음, 새로 생성 중...')
db = vectorize(embeddings_model)
return db
2.2 메인 모듈
주요 모듈은 먼저 TinyLlama에 대한 프롬프트 템플릿을 정의합니다. 템플릿은 다음과 같습니다:
|system|'context'/s``|user|'question'/s``|assistant|
LLM 메모리 사용량을 더 줄이기 위해, TheBloke의 HuggingFace 레포지토리 [3]에서 TinyLlama의 양자화된 버전을 채택할 것입니다. 이는 모델 매개변수에 더 적은 비트를 사용하는 방식입니다. 이 LLM에 대한 추가적인 배경 정보나 활성화 기술에 대해 더 자세히 알고 싶은 분들은 이전에 작성한 기사를 확인해보세요. GGUF 형식으로 양자화된 LLM을 로드하기 위해 LlamaCpp를 사용합니다. 이전 모듈에서 반환된 FAISS 객체를 사용하여 FAISS retriever가 생성됩니다. 이러한 객체들을 사용하여 RetrievalQA 체인을 생성하고 질문에 사용합니다.
아래 코드는 이러한 단계를 포착합니다.
# main.py
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.llms import LlamaCpp
from langchain_community.embeddings import HuggingFaceEmbeddings
import LoadFVectorize
from renumics import spotlight
import pandas as pd
import numpy as np
# 프롬프트 템플릿
qa_template = """<|system|>
정확하게 대답하는 친근한 채팅 봇입니다.
알 수 없는 답변일 경우 공손하게 알려드릴 것입니다.
다음 맥락을 사용하여 아래 질문에 답변해주세요:
{context}</s>
<|user|>
{question}</s>
<|assistant|>
"""
# 프롬프트 인스턴스 생성
QA_PROMPT = PromptTemplate.from_template(qa_template)
# LLM 로드
llm = LlamaCpp(
model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# 벡터화 및 retriever 생성
db = LoadFVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
# QA 체인 정의
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=faiss_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
query = 'What versions of TLS supported by Client Accelerator 6.3.0?'
result = qa_chain({"query": query})
print(f'--------------\nQ: {query}\nA: {result["result"]}')
visualize_distance(db,query,result["result"])
벡터 공간 시각화 자체는 위 코드 목록의 마지막 줄인 visualize_distance에 의해 처리됩니다. 이 기능 또한 이 모듈에 정의되어 있습니다.
visualize_distance 함수에서는 먼저 FAISS 객체의 dict 속성에 액세스해야 합니다. 이는 인스턴스 변수용 사전입니다. 이를 통해 docstore에 액세스할 수 있습니다. 인스턴스 변수 index_to_docstore_id는 키 인덱스로 값 docstore-id의 사전입니다. 벡터화에 사용된 총 문서 수는 인덱스 객체의 ntotal 속성으로 나타냅니다.
vs = db.__dict__.get("docstore")
index_list = db.__dict__.get("index_to_docstore_id").values()
doc_cnt = db.index.ntotal
벡터 공간을 대략적으로 복원하기 위해 우리는 단순히 객체 인덱스의 메서드인 reconstruct_n을 기본 매개변수와 함께 호출합니다:
embeddings_vec = db.index.reconstruct_n()
이제 인덱스 목록으로 문서 저장소 ID 목록이 있으므로, 관련 문서 객체를 찾아 해당 ID, 문서 메타데이터, 문서 내용 및 벡터 공간 내 임베딩을 포함하는 리스트를 생성해보겠습니다. 아래 코드를 참조해주세요.
doc_list = list()
for i, doc_id in enumerate(index_list):
a_doc = vs.search(doc_id)
doc_list.append([doc_id, a_doc.metadata.get("source"), a_doc.page_content, embeddings_vec[i]])
그런 다음 이 리스트를 사용하여 열 제목이 있는 데이터프레임을 생성한 후, 시각화를 만들기 위해 spotlight 호출에 사용될 것입니다.
df = pd.DataFrame(doc_list, columns=['id', 'metadata', 'document', 'embedding'])
시각화를 진행하기 전에 질문과 답변을 통합할 방법을 찾아야 합니다. 질문 및 답변을 위한 별도의 데이터프레임을 생성하고 주요 데이터프레임과 병합하여 두 데이터가 나머지 문서 청크와 함께 어디에 나타나는지 보여줄 수 있도록합니다:
# 질문 및 답변을 위한 행 추가
embeddings_model = HuggingFaceEmbeddings()
question_df = pd.DataFrame(
{
"id": "question",
"question": question,
"embedding": [embeddings_model.embed_query(question)],
})
answer_df = pd.DataFrame(
{
"id": "answer",
"answer": answer,
"embedding": [embeddings_model.embed_query(answer)],
})
df = pd.concat([question_df, answer_df, df])
이 공간에서 질문과 문서 간의 유클리드 거리를 찾으려면 질문을 위한 임베딩을 만든 다음 문서와 질문 임베딩 차이에 대해 numpy의 linalg.norm을 사용하십시오:
question_embedding = embeddings_model.embed_query(question)
# 벡터 거리를 나타내는 열 추가
df["dist"] = df.apply(
lambda row: np.linalg.norm(
np.array(row["embedding"]) - question_embedding
),axis=1,)
데이터프레임을 얻었으면 spotlight.show를 호출하여 시각화를 생성합니다.
spotlight.show(df)
왔어요! 이렇게 하면 브라우저 창에서 spotlight가 열리고 pandas 데이터프레임이 탐색 준비가 됩니다.
아래 GitHub 저장소에서 모든 코드에 액세스할 수 있습니다:
3.0 테스트 실행
첫 번째 실험을 용이하게하기 위해 선택된 샘플 질문은 아래와 같습니다:
채택된 문서에 따르면, 올바른 답은 :
또한, 다음 추가 정보가 응답에 포함될 수 있습니다.
아래는 위 질문에 대한 TinyLlama의 응답입니다:
이 응답은 실제 답변과 꽤 유사해 보이지만, 이 TLS 버전들이 기본값은 아니라는 점에서 완전히 정확하지는 않습니다.
Fig. 2는 스포트라이트의 스크린샷을 나타냅니다. 왼쪽 상단의 테이블 섹션에는 데이터프레임의 모든 열이 표시되고 시각화는 유사성 맵 탭 뷰 내에서 표시됩니다.
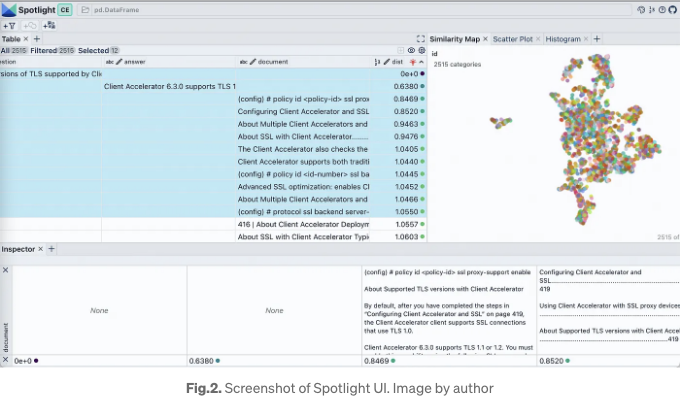
가시적인 열 버튼을 사용하여 표시되는 열을 제어할 수 있습니다. "dist"로 테이블을 정렬하면 상위에 질문, 답변 및 가장 관련성 높은 문서 스니펫이 나타납니다. 임베딩 시각화를 살펴보면 여기의 거의 모든 문서를 하나의 클러스터로 나타냅니다. 이는 원래 pdf가 특정 제품의 배포 가이드임을 감안할 때 합리적일 것으로 생각됩니다. Similarity Map 탭 내의 필터 아이콘을 클릭하면 선택한 문서 목록만 강조 표시되며 나머지는 회색으로 표시됩니다(Fig. 3 참조).
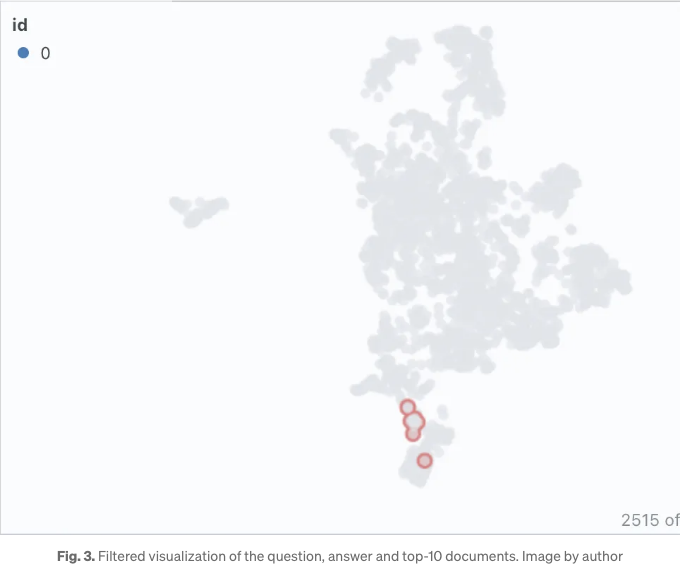
3.1 테스트 청크 크기 및 겹치기 매개변수
리트리버가 RAG 성능에 중요한 영향을 미친다고 해서, 우리는 임베딩 공간에 영향을 주는 몇 가지 매개변수를 살펴보겠습니다. 테이블 1은 문서 분할 중 TextSplitter의 청크 크기 (1000, 2000) 및/또는 오버랩 (100, 200) 매개변수가 다양하게 변할 때, TinyLlama의 응답을 포착하고 정리합니다.
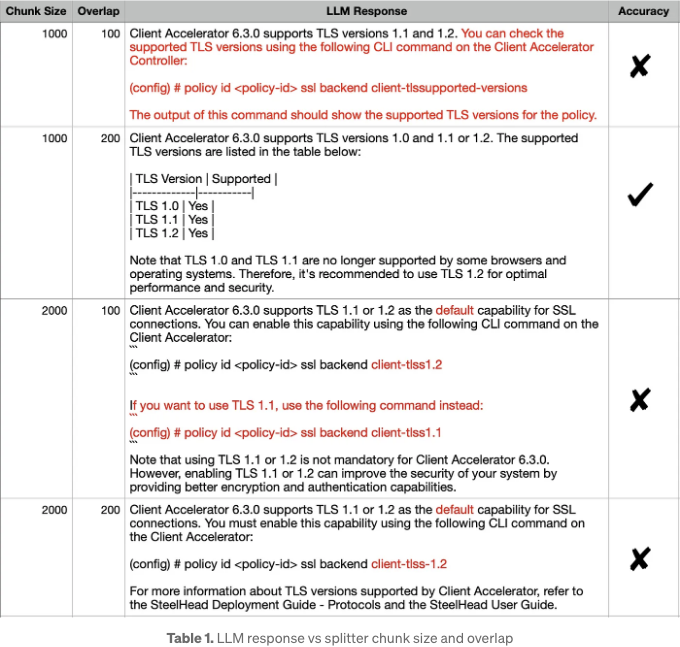
첫눈에, 모든 조합의 LLM 응답이 비슷해 보입니다. 그러나 정확한 답변과 각 응답을 주의 깊게 비교하면, 정확한 답변은 (1000, 200) 조합에 해당합니다. 다른 응답에서의 부정확한 세부사항은 빨간색으로 강조되었습니다. 이러한 행동을 설명하기 위해, Fig. 3은 각 조합에 대한 임베딩 맵을 옆으로 나란히 보여줍니다.
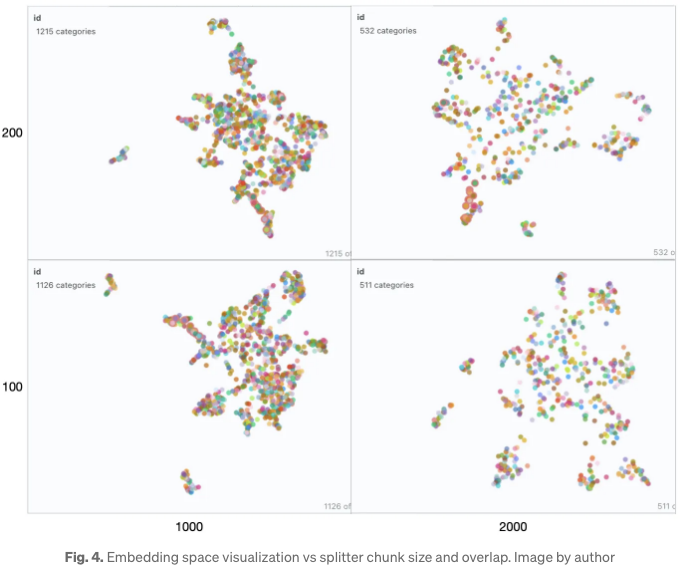
왼쪽부터 오른쪽으로 청크 크기를 증가시키면서 벡터 공간이 더 드문 형태로 변해갑니다. 아래에서 위로 가면 겹침이 두 배가 된 곳에서도 벡터 공간의 특성이 급격하게 변하지는 않습니다. 이 모든 맵에서 전체 컬렉션은 여전히 한 클러스터처럼 보이며 몇 개의 이상치만 존재합니다. 이는 생성된 응답에서 명확히 반영되며, 이들은 상당히 유사합니다. 질의가 클러스터의 중심에 있는 경우, 이웃들이 다를 가능성이 높으므로 이러한 매개변수의 변화에 따라 응답이 상당히 달라질 수 있습니다.
RAG 애플리케이션이 특정 질문에 대해 기대한 답변을 제공하지 않는 경우, 해당 질문들과 함께 위와 같은 시각화를 생성함으로써 말뭉치를 어떻게 분할하여 전체 성능을 개선할지에 대한 추가 통찰을 얻을 수 있습니다.
그리고 좀 더 설명하기 위해, 상관 없는 도메인의 두 개의 위키백과 문서가 차지하는 벡터 공간을 시각화해 봅시다. 이를 위해 LoadFVectorize 모듈 내 load_doc 함수의 첫 줄을 수정하여 웹 기반 두 URL의 WebBasedLoader를 구현하면 됩니다. 하나는 그래미 어워즈에 관한 것이고, 다른 하나는 JWST 망원경에 대한 것입니다. 아래와 같이 나타납니다.
def load_doc():
loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])
documents = loader.load()
...
나머지 코드는 그대로 유지하고 있는 것을 확인하면, 우리는 그림 5에 나타난 벡터 공간 시각화를 얻을 수 있습니다.
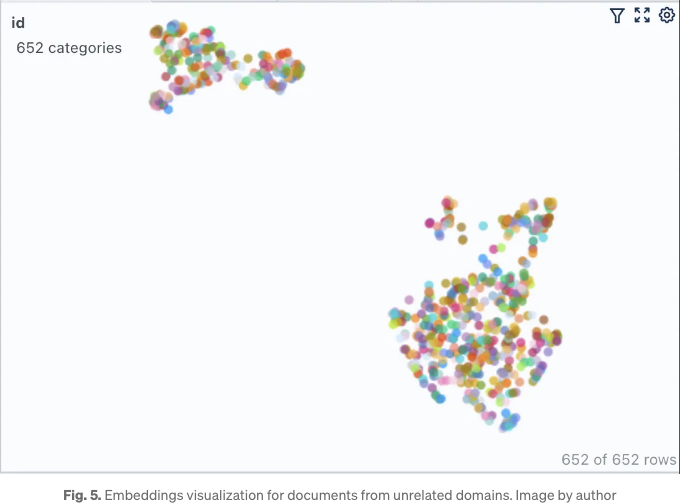
예상대로, 여기에는 두 개의 명확하게 겹치지 않는 클러스터가 있습니다. 우리가 두 클러스터 모두 벗어난 질문을 하면, 검색기에서 얻는 결과 문맥은 적어도 LLM에게 도움이 되지는 않을 것이지만 오히려 해로울 것입니다. 그리고 재미로, 나는 이전에 묻은 같은 질문을 한 번 더 던져보기로 결정했습니다. 그리고 확실히 LLM은 환각하기 시작했습니다.
여기 우리 시스템 디자인에는 벡터 저장을 위해 FAISS를 사용했습니다. 만약 당신이 ChromaDB를 사용하고 비슷한 시각화를 수행하는 방법을 궁금해 한다면, 당신은 운이 좋습니다. renumics-spotlight 라이브러리 개발자 중 Markus Stoll이 여기에 관련된 흥미로운 기사를 썼습니다. 확인해보세요.
4.0 마무리
Retrieval-Augmented Generation (RAG)은 내부 문서에 교육되지 않은 큰 언어 모델(LM)을 활용할 수 있게 해줍니다. RAG은 벡터 저장소에서 여러 관련 문서 청크를 검색하여 LM이 생성을 위한 문맥으로 사용합니다. 따라서 임베딩의 품질은 RAG 성능에 중요한 역할을 합니다.
이 기사에서는 주요 벡터화 매개변수 중 일부가 전체 LM 성능에 미치는 영향을 시연하고 시각화했습니다. 우리는 리소스 풋프린트가 훨씬 작지만 여전히 높은 정확도를 자랑하는 TinyLlama 1.1B Chat를 선택했습니다. 라이브러리 'renumics-spotlight'를 사용하여 FAISS 벡터 공간 전체를 데이터프레임으로 표현하는 방법을 보여주었으며, 이를 사용하여 한 줄의 코드로 임베딩을 시각화했습니다. Spotlight의 직관적인 UI를 통해 질문에 대한 벡터 공간을 탐색하고, 이를 통해 LM의 응답을 더 잘 이해할 수 있습니다. 특정 벡터화 매개변수를 조정함으로써, 성능을 향상시키기 위해 생성 및 행동을 제어할 수 있습니다.
읽어 주셔서 감사합니다!