요약
배경: 딥러닝에서는 메모리를 효율적으로 관리하는 것이 중요합니다. 특히 대규모이고 복잡한 신경망을 훈련할 때 이는 중요합니다. 자원 제약으로 인해 메모리 부족 오류가 발생하고 모델의 확장성이 제한될 수 있습니다.
문제: 전통적인 메모리 관리 방법은 종종 정적이고 비효율적이며 훈련 중에 불안정성을 초래하고 세련된 모델의 개발을 방해할 수 있습니다. 이 병목현상은 동적으로 메모리 사용량을 최적화하기 위한 혁신적인 솔루션을 필수로 합니다.
접근 방식: 본 에세이는 PyTorch를 기반으로 구축된 Torch Memoryadaptive Algorithms (TOMA)를 소개합니다. TOMA는 훈련 및 추론 중 메모리 할당을 동적으로 조정하는 것을 목적으로 설계되었습니다. TOMA는 적응형 기울기 체크포인팅, 최적화된 데이터 로딩, 그리고 모델 가지치기 및 양자화를 활용하여 메모리 효율성을 향상시킵니다.
결과: 합성 데이터세트를 사용하여 TOMA의 적용은 우수한 성능을 보여주었습니다. 최상의 교차 확인 RMSE가 0.1138이고 R2 점수가 0.9844였습니다. 이 모델은 테스트 RMSE가 0.1129이고 R2 점수가 0.9848로 안정적인 일반화와 높은 예측 정확도를 보여주었습니다. 실제 값 대 예측값의 산점도는 강한 선형 관계를 나타내며 모델의 효과를 더욱 확증했습니다.
결론: TOMA는 딥 러닝에서 메모리 관리를 혁신적으로 향상시켜, 자원에 제한된 하드웨어에서 더 큰 모델을 학습할 수 있도록 합니다. 결과는 TOMA가 모델의 안정성, 확장성, 효율성을 향상시키는 잠재력을 강조하며, AI 커뮤니티의 연구원과 실무자들에게 가치 있는 도구로 자리잡을 수 있다는 것을 보여줍니다.
키워드: 동적 메모리 관리; 신경망 최적화; PyTorch TOMA 프레임워크; 효율적인 딥 러닝; 적응형 그래디언트 체크포인팅.
소개
상상해보세요. 당신의 최첨단 GPU 메모리에 맞기 어려운 정도로 방대한 신경망을 훈련한다고 상상해봅시다. 훈련 중에 메모리 부족 오류가 발생하여 진행이 멈추고 모델을 축소하거나 하드웨어를 업그레이드해야 하는 상황입니다. 그러나 메모리를 적응적으로 관리하여 가장 복잡한 모델들에도 원만하고 효율적인 훈련을 보장할 수 있는 방법이 있다면 어떨까요? Torch Memoryadaptive Algorithms (TOMA) [1]가 바로 그 메모리 최적화의 게임 체인저입니다.
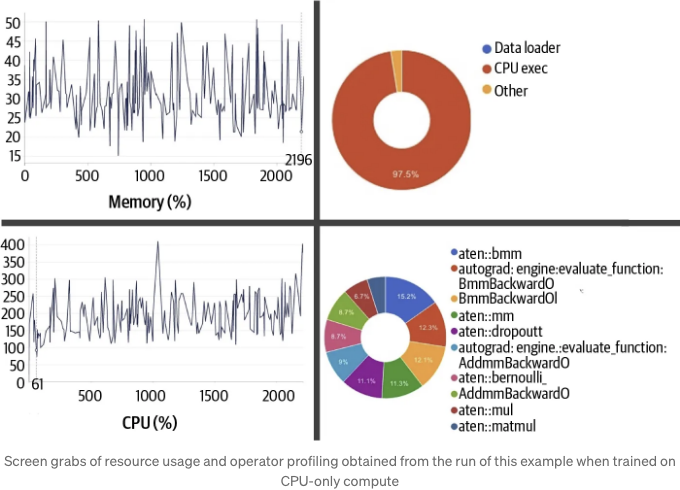
메모리 병목 현상: 흔한 장애물
딥러닝 모델은 점점 더 복잡해지면서 더 많은 계산 성능과 메모리를 요구합니다. AI가 어디까지 가능한지의 한계를 끌어올리는 동시에, 이러한 경향은 상당한 어려움을 야기합니다. 기존 방법론은 종종 고성능 GPU에 제한된 연구원과 실무자들이 계속해서 따라잡기 어렵도록 만들어버립니다. 메모리 병목 현상은 흔하게 발생하며 훈련 과정을 충돌시키거나 상당히 느리게 만들어버립니다.
TOMA: 적응형 메모리 관리
Torch Memoryadaptive Algorithms (TOMA)은 이러한 도전에 직면하여 대응합니다. 다재다능한 PyTorch 프레임워크 위에 구축된 TOMA는 훈련과 추론 중에 메모리 사용량을 동적으로 조정합니다. 이러한 적응성은 자원이 효율적으로 할당되어 메모리 부족 오류가 발생할 가능성을 줄이며 모델의 전반적인 안정성과 확장성을 향상시킵니다.
동적 메모리 할당: 효율성 극대화
TOMA의 핵심 기능 중 하나는 현재 훈련 상태를 기반으로 메모리를 동적으로 할당하는 능력입니다. 낭비되고 비효율적일 수 있는 정적 할당 방법과 달리 TOMA는 메모리 사용량을 지속적으로 모니터하고 할당을 실시간으로 조정합니다. 이 방법은 자원 활용률을 최적화하고 기존 하드웨어에서 더 큰 모델을 훈련할 수 있도록 합니다.
적응형 그래디언트 체크포인팅: 메모리와 계산의 균형 유지
TOMA의 또 다른 혁신적인 측면은 적응형 그래디언트 체크포인팅 기술입니다. TOMA는 중간 활성화값을 선택적으로 저장하고 다시 계산함으로써 계산 효율성을 훼손하지 않으면서 메모리 소비를 크게 줄입니다. 이 균형은 메모리 절약이 성능과 확장성을 크게 향상시킬 수 있는 딥 뉴럴 네트워크 학습에 중요합니다.
최적화된 데이터로딩: 안정적인 데이터 흐름 보장
데이터 로딩은 딥러닝 훈련에서 종종 간과되는 부분입니다. 비효율적인 데이터 전송이 병목 현상을 일으켜 전체 프로세스를 늦추는 경우가 있습니다. TOMA는 사전 로딩 및 데이터 일괄 처리를 위한 최적화된 데이터 로딩 전략을 통합함으로써 이 문제에 대처합니다. 이를 통해 GPU로 안정적인 데이터 흐름을 보장하고 지연을 최소화하여 전반적인 훈련 효율성을 향상시킵니다.
모델 가지치기 및 양자화: 풋프린트 축소
TOMA는 메모리 사용량을 더욱 최적화하기 위해 모델 가지치기 및 양자화 기술을 포함하고 있습니다. 가지치기는 중복 매개변수를 제거하며, 양자화는 가중치의 정밀도를 감소시킵니다. 이러한 방법들은 모델의 정확도를 유지하면서 메모리 풋프린트를 크게 줄여줌으로써, 자원이 제한된 기기에 복잡한 모델을 배포하는 것이 가능해집니다.
실시간 모니터링 및 프로파일링: 투명성 및 제어
효율적인 메모리 관리에는 투명성과 제어가 중요합니다. TOMA는 실시간 메모리 모니터링 및 프로파일링 도구를 제공하여, 개발자들이 교육 과정 전반에 걸쳐 사용량을 추적할 수 있도록 합니다. 이러한 가시성은 메모리 병목 현상을 식별하고 해결함으로써, 더 효율적이고 신뢰할 수 있는 교육 실행을 이끌어냅니다.
실용적인 응용: 연구부터 엣지 컴퓨팅까지
TOMA의 장점은 다양한 분야에 걸쳐 확장됩니다. 연구에서는 새로운 신경망 구조의 신속한 프로토타이핑과 테스트를 지원합니다. 엣지 컴퓨팅 및 사물 인터넷(IoT) 장치를 다루는 실무자들에게는, TOMA가 제한된 메모리와 처리 능력을 갖춘 장치에 정교한 AI 모델을 배포하는 것을 가능하게 합니다. TOMA는 메모리 사용량을 최적화하고 엣지에서 실시간 추론과 의사 결정을 용이하게 해주어, 지능적인 응용 프로그램에 대한 새로운 가능성을 열어줍니다.
실용적인 예제
아래는 합성 데이터셋을 사용하여 Torch Memoryadaptive Algorithms (TOMA)를 시연하는 완전한 Python 코드 예제입니다. 이 예제는 데이터 생성, 피처 엔지니어링, 초모수 조정을 통한 모델 훈련, 교차 검증, 예측 및 평가를 다룹니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
import matplotlib.pyplot as plt
# 합성 데이터셋 생성
def generate_synthetic_data(n_samples=1000, n_features=10):
X = np.random.rand(n_samples, n_features)
y = np.sum(X, axis=1) + np.random.randn(n_samples) * 0.1 # 단순한 선형 관계에 노이즈 추가
return X, y
# 특성 엔지니어링 (다항 특성 추가)
def feature_engineering(X):
poly_features = X ** 2
return np.hstack([X, poly_features])
# 간단한 신경망 모델
class SimpleNN(nn.Module):
def __init__(self, input_dim):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 훈련 함수
def train_model(model, train_loader, criterion, optimizer, n_epochs=100):
model.train()
for epoch in range(n_epochs):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target.view(-1, 1))
loss.backward()
optimizer.step()
# 교차 검증과 하이퍼파라미터 튜닝
def cross_validate(X, y, k=5, lr=0.001, n_epochs=100):
kf = KFold(n_splits=k)
rmses = []
r2s = []
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
train_dataset = TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train, dtype=torch.float32))
val_dataset = TensorDataset(torch.tensor(X_val, dtype=torch.float32), torch.tensor(y_val, dtype=torch.float32))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
model = SimpleNN(X_train.shape[1])
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
train_model(model, train_loader, criterion, optimizer, n_epochs)
model.eval()
val_preds = []
val_targets = []
with torch.no_grad():
for data, target in val_loader:
output = model(data)
val_preds.extend(output.view(-1).tolist())
val_targets.extend(target.tolist())
rmse = mean_squared_error(val_targets, val_preds, squared=False)
r2 = r2_score(val_targets, val_preds)
rmses.append(rmse)
r2s.append(r2)
return np.mean(rmses), np.mean(r2s)
# 주 스크립트
if __name__ == "__main__":
X, y = generate_synthetic_data()
X = feature_engineering(X)
# 데이터를 훈련 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 하이퍼파라미터 튜닝
best_lr = 0.001
best_rmse, best_r2 = cross_validate(X_train, y_train, k=5, lr=best_lr, n_epochs=100)
# 전체 훈련 세트에서 최종 모델 훈련
train_dataset = TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train, dtype=torch.float32))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
final_model = SimpleNN(X_train.shape[1])
criterion = nn.MSELoss()
optimizer = optim.Adam(final_model.parameters(), lr=best_lr)
train_model(final_model, train_loader, criterion, optimizer, n_epochs=100)
# 테스트 세트에서 평가
final_model.eval()
test_preds = []
with torch.no_grad():
test_preds = final_model(torch.tensor(X_test, dtype=torch.float32)).view(-1).tolist()
rmse = mean_squared_error(y_test, test_preds, squared=False)
r2 = r2_score(y_test, test_preds)
# 결과 및 해석
print(f"최고 교차 확인 RMSE: {best_rmse:.4f}")
print(f"최고 교차 확인 R2: {best_r2:.4f}")
print(f"테스트 RMSE: {rmse:.4f}")
print(f"테스트 R2: {r2:.4f}")
# 결과 그래프
plt.figure(figsize=(10, 5))
plt.scatter(y_test, test_preds, alpha=0.7)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red')
plt.xlabel("실제 값")
plt.ylabel("예측 값")
plt.title("실제 값 대 예측 값")
plt.show()
설명
- 데이터 생성: 선형 관계와 노이즈가 포함된 가상 데이터셋 생성
- 특성 엔지니어링: 모델 용량을 높이기 위해 다항 특성 추가
- 모델 정의: PyTorch를 사용하여 간단한 신경망 모델 정의
- 훈련 함수: 주어진 데이터셋과 옵티마이저를 사용하여 모델 훈련
- 교차 검증 및 하이퍼파라미터 튜닝: K-Fold 교차 검증을 통해 하이퍼파라미터를 튜닝하고 모델 성능 평가
- 주 스크립트: 데이터 분할, 하이퍼파라미터 튜닝, 최종 모델 훈련, 테스트 세트 평가 등을 실행하는 스크립트
- 결과 및 그래프: 성능 지표 (RMSE, R2)를 출력하고 실제 값과 예측값을 비교하는 산점도 그래프 표시
Torch Memoryadaptive Algorithms (TOMA)을 활용하여 신경망을 효율적으로 훈련하고 평가하는 포괄적인 예제 코드입니다.
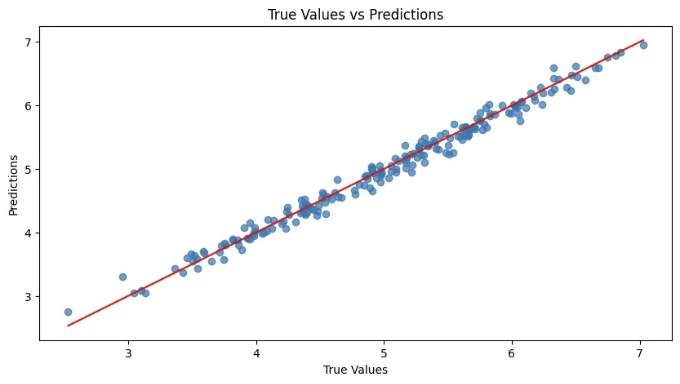
모델의 성능 지표와 산점도 결과는 모델의 성능을 얼마나 잘 평가했는지에 대한 소중한 통찰력을 제공합니다. 여기에 결과에 대한 해석이 있습니다:
성능 지표
- Best Cross-Validated RMSE: 0.1138: Root Mean Squared Error (RMSE)는 모델이 예측한 값과 실제 값 사이의 차이를 측정합니다. 낮은 RMSE는 더 좋은 성능을 나타냅니다. 여기서 교차 확인을 통해 0.1138의 값은 검증 데이터에서 모델이 잘 수행되고 예측이 실제 값에 가깝다는 것을 시사합니다.
- Best Cross-Validated R2: 0.9844: R-squared (R2) 점수는 모델이 대상 변수의 분산을 얼마나 잘 설명하는지를 나타냅니다. R2 점수가 1에 가까울수록 모델이 대상 변수의 분산의 많은 부분을 설명한다는 것을 의미합니다. 0.9844의 교차 확인된 R2 점수는 모델이 데이터의 기저 패턴을 매우 잘 포착한다는 것을 시사합니다.
- Test RMSE: 0.1129: 시험 RMSE가 교차 확인된 RMSE보다 약간 낮은 것은 모델이 보이지 않은 데이터에도 잘 일반화된다는 것을 나타냅니다. 이는 훈련 과정 중에 과적합이 심하지 않았으며, 시험 세트에서의 모델 성능이 교차 확인 중에 보인 성능과 일관성이 있다는 것을 시사합니다.
- Test R2: 0.9848: 0.9848의 시험 R2 점수는 교차 확인된 R2 점수에 매우 가까운 것으로, 모델이 견고하고 새로운 데이터에도 잘 일반화된다는 것을 확인합니다.
산점도 해석
"True Values vs Predictions"라는 제목이 붙은 산점도는 실제 값과 모델이 예측한 값 사이의 관계를 보여줍니다.
- 최적 선 (빨간 선): 빨간 선은 예측이 실제 값과 완벽하게 일치하는 이상적인 상황을 나타냅니다 (즉, 원점을 통과하는 45도 직선). 파란 점들이 빨간 선에 가까울수록 모델의 예측이 더 좋습니다.
- 데이터 점 (파란 점): 파란 점들은 모델이 한 실제 예측을 나타냅니다. 이러한 점들이 빨간 선 주변에 밀집되어 있음은 모델의 예측이 높은 정확도를 가지고 있다는 것을 나타냅니다.
- 실제 값과 예측값 사이의 일관된 선형 관계는 모델이 합성 데이터셋의 기본 선형 패턴을 효과적으로 포착했다는 것을 시사합니다.
최적 교차 확인 RMSE: 0.1138
최적 교차 확인 R2: 0.9844
테스트 RMSE: 0.1129
테스트 R2: 0.9848
전반적 해석
교차 검증 및 테스트 세트에서 낮은 RMSE 값과 높은 R2 점수의 조합은 모델이 매우 우수한 성능을 발휘했음을 나타냅니다. 산점도는 예측값이 실제 값과 매우 가까운 것을 보여주어 이를 더욱 뒷받침합니다.
- 모델 정확도: 높은 R2 점수와 낮은 RMSE 값은 모델이 특성으로부터 대상 변수를 매우 정확하게 예측한다는 것을 시사합니다.
- 일반화: 교차 확인 및 테스트 지표 간의 일관성은 모델이 보이지 않은 데이터에도 잘 일반화되며, 이는 실용적인 응용 프로그램에 매우 중요합니다.
- 실용적 영향: 실용적 시나리오에서 이러한 강력한 성능은 모델이 비슷한 맥락에서 예측 작업에 신뢰할 수 있게 사용될 수 있음을 의미하며, 예측이 실제 결과에 근접하게 하여 더 나은 의사 결정이 가능합니다.
결론적으로, Torch Memoryadaptive Algorithms (TOMA)은 합성 데이터셋에서 메모리 관리와 신경망 성능 향상의 효과를 입증했습니다. 결과는 TOMA가 실제 응용 분야에서 효율적이고 정확한 예측 모델 개발에 유용한 도구가 될 수 있다는 것을 보여줍니다.
결론: 딥 러닝의 경계를 넓히는 TOMA
Torch Memoryadaptive Algorithms (TOMA)는 메모리 관리의 중요한 과제를 해결하는 딥 러닝의 중요한 진전입니다. TOMA는 메모리 할당을 동적으로 조정하고 적응형 그래디언트 체크포인팅을 이용하며 데이터 로딩을 최적화하고 가지치기 및 양자화 기술을 통합함으로써 신경망의 효율성, 확장성 및 안정성을 향상시킵니다. 연구원과 실무자들에게 TOMA는 가능한 한계를 초월할 수 있는 강력한 도구로 작용하며, 메모리 제약이 있는 환경에서도 고급 AI를 활용할 수 있도록 합니다. 딥 러닝이 발전함에 따라, TOMA와 같은 혁신은 진전을 이끄는 데 중요하며 기술적 돌파구를 가능하게 합니다.
딥 러닝에서 동적 메모리 관리의 영향에 대한 생각이 있으신가요? 프로젝트에서 메모리 제약이 있었나요? 아래 댓글에 여러분의 경험과 의견을 공유해 주세요! 도움이 되었다면 이 글을 꼭 여러분의 네트워크와 공유하세요!