
Streamlit은 데이터 과학자와 분석가들이 쉽게 대화형 웹 애플리케이션을 만들 수 있게 하는 오픈 소스 앱 프레임워크입니다.
인기있던 요청에 힘입어, 본 글은 보다 모듈식으로 접근한 다중 페이지 Streamlit 애플리케이션 만들기 과정을 다룹니다. 페이지의 핵심 쉘부터 시작합니다.
Data at Depth는 독자들의 지원을 받는 미디어입니다. 새로운 글을 받아보고 제 작품을 지원하기 위해 무료 또는 유료 구독자가 되는 것을 고려해 주세요.
파이썬을 몇 줄만 사용하면 데이터 스크립트를 공유 가능한 웹 앱으로 변환할 수 있어요.
Streamlit을 사용하여 다중 페이지 대화형 애플리케이션을 만드는 방법을 안내해 드릴게요. 이번에는 국제 난민기구 (UNHCR) 데이터셋을 활용해서 원산지국 및 피난사 실제 나라를 추적하는 애플리케이션을 만들 거에요.
이 애플리케이션은 다음과 같은 세 가지 데이터 시각화 페이지를 갖을 거예요:
- 피난 사실 대상 나라 개요 (피난처 10대 국가)
- 피난처 국가별 분석
- 코로플레스 지도를 활용한 피난신청국 전체 개요
우리가 할 일은 Streamlit 셸 애플리케이션과 데이터 세트를 이용해 모든 것을 처음부터 만들어보는 것입니다.
Streamlit 셸 애플리케이션 다중 페이지 구조 만들기
모듈화된 다중 페이지 Streamlit 애플리케이션을 만들기 위해 우리는 먼저 애플리케이션의 기본 구조를 설정할 것입니다.
이는 각 페이지에 대한 별도의 함수를 만들고 페이지 간 탐색을 관리하는 주요 함수를 만드는 것을 포함합니다.
아래는 각 페이지를 셸로 사용하여 3페이지 Streamlit 애플리케이션을 설정하는 코드입니다.
import streamlit as st
# 페이지 1: 개요
def page_overview():
st.subheader("연도 범위별 전체 비민 결정")
# 시각화 코드를 여기에 넣으세요.
# 페이지 2: 국가별 분석 및 그룹화된 막대 차트
def page_country_analysis():
st.subheader("국가별 분석")
# 시각화 코드를 여기에 넣으세요.
# 페이지 3: 코로플레스 맵
def page_choropleth():
st.subheader("비민 결정의 세계적 분포")
# 시각화 코드를 여기에 넣으세요.
# 주요 앱 및 네비게이션
def main():
st.set_page_config(page_title="비민 결정 대시보드", layout="wide", initial_sidebar_state="expanded")
st.sidebar.title("네비게이션")
menu_options = ["전체 비민 결정", "국가 분석", "글로벌 매핑"]
menu_choice = st.sidebar.selectbox("이동", menu_options)
if menu_choice == "전체 비민 결정":
page_overview()
elif menu_choice == "국가 분석":
page_country_analysis()
elif menu_choice == "글로벌 매핑":
page_choropleth()
if __name__ == "__main__":
main()
코드 설명:
- Streamlit 라이브러리를 가져옵니다.
- 각 페이지를 위한 별도의 함수를 정의합니다: page_overview(), page_country_analysis(), page_choropleth().
- 각 함수에는 페이지 목적을 나타내는 subheader가 포함되어 있습니다. 데이터 시각화 코드는 나중에 추가됩니다.
- 페이지 구성을 설정하고 네비게이션을 처리하는 main() 함수를 정의합니다.
- st.sidebar.selectbox를 사용하여 세 개의 페이지 사이를 이동하는 사이드바 메뉴를 생성합니다.
- 사용자의 선택에 따라 해당 페이지 함수가 호출되어 페이지 내용이 표시됩니다.
- 스크립트를 실행할 때 main() 함수가 호출됩니다.
이 쉘은 다중 페이지 Streamlit 애플리케이션의 기본 구조를 설정합니다. 다음 섹션에서는 각 페이지 함수에 데이터 시각화 코드를 추가할 것입니다.
이 코드를 실행하려면 터미널 프롬프트에 액세스해야 합니다. 저는 PyCharm의 내장 터미널 프롬프트를 사용합니다:
애플리케이션은 기본 브라우저에서 실행됩니다. 셸 애플리케이션을 처음으로 살펴보겠습니다:
테이블 태그를 Markdown 형식으로 변경해 주세요.
그들의 데이터는 여기에서 자유롭게 접근할 수 있습니다.
다운로드 페이지로 이동한 후에는 선택한 데이터에 대해 더욱 구체적으로 설정할 수 있습니다:
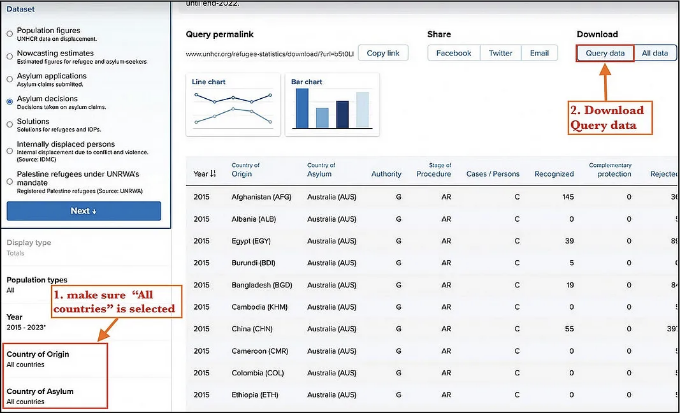
UNHCR 다운로드 페이지 - "원국"과 "청국"을 선택합니다.
이 프로젝트에서는 각 난민의 출신 국가와 애쉬럼 국가를 가져와 봅시다.
이 데이터를 통해 우리는 두 방향으로의 이동을 보여주는 난민 데이터를 가지고 있습니다:
- 출신 국가에서 — 애움 신청자들이 이동하는 곳
- 애움 국가에서 — 애움 신청자들이 오는 곳
데이터셋을 다운로드한 후에, 우리는 어떤 데이터를 다루고 있는지 확인하기 위해 스프레드시트 형식으로 열어볼 수 있습니다:
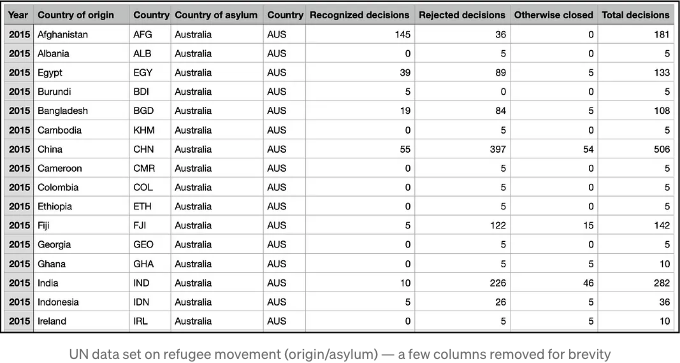
This project focuses on the following data fields:
- Country of origin: The country from which a person seeking asylum is coming
- Country of asylum: The country where a person is actually seeking asylum
- Recognized decisions: The total number of asylum seekers accepted per country (in numeric format)
- Rejected decisions: The number of asylum seekers denied asylum
Both the country of origin and asylum have a 3-letter ISO code, which serves as a reliable unique identifier.
이제 애플리케이션의 각 페이지를 함께 만들어 봅시다.
페이지 1: 망명을 받는 상위 10개 국가 (막대/선버스트 차트)
첫 번째 페이지로, 우리는 망명을 받는 상위 10개 국가를 보여주는 막대 차트를 만들 것입니다. 그리고 재미있게도, 가끔 해석하기 어려울 수도 있는 아름다운 선버스트 차트도 만들어 볼 거에요.
우리는 글로벌 망명 결정을 연도 범위별로 보여주는 데이터 시각화 코드를 page_overview() 함수에 추가할 거에요.
데이터 세트를 로드하고 선택한 연도 범위에 따라 데이터를 필터링한 다음 두 가지 시각화를 만들어야 합니다: 총 난민 심사 결과 상위 10개 국가를 보여주는 수평 막대 차트와 출신 국가별로 나눈 Sunburst 차트입니다.
import pandas as pd
import plotly.express as px
# 데이터 세트 로드
data = pd.read_csv('asylum-decisions.csv')
# 난민 심사 결과 수를 얻는 도우미 함수
def get_asylum_counts(df, group_by_column):
return df.groupby([group_by_column])[
['Recognized decisions', 'Rejected decisions', 'Total decisions']].sum().reset_index()
-
데이터 로드:
-
데이터 세트는 pd.read_csv()를 사용하여 로드되어 data 변수에 저장됩니다.
- 도우미 함수:
- get_asylum_counts(df, group_by_column): 이 함수는 데이터를 지정된 열로 그룹화하고 인정된, 거부된 및 총 결정의 합계를 계산합니다.
우리는 데이터에 액세스하기 위해 초기 셸 애플리케이션 상단에 이 코드를 추가해야 합니다.
데이터 시각화가 포함된 page_overview() 함수의 전체 코드는 다음과 같습니다:
# 페이지 1: 개요
def page_overview():
st.subheader("연도 범위별 전체 추방 판정 (범위 선택)")
year_filter = st.slider("연도 범위", int(data['Year'].min()), int(data['Year'].max()),
(int(data['Year'].min()), int(data['Year'].max())))
filtered_data = data[(data['Year'] >= year_filter[0]) & (data['Year'] <= year_filter[1])]
asylum_counts = get_asylum_counts(filtered_data, 'Country of asylum')
top_countries = asylum_counts.sort_values(by='Total decisions', ascending=False).head(10)
fig_bar = px.bar(top_countries, x='Total decisions', y='Country of asylum', orientation='h',
title="총 추방 판정 상위 10개 국가",
color='Total decisions', color_continuous_scale=px.colors.sequential.YlOrRd)
fig_bar.update_layout(showlegend=False, height=400, yaxis={'categoryorder': 'total ascending'})
fig_bar.update_coloraxes(showscale=False) # 색상 스케일 제거
st.plotly_chart(fig_bar)
top_countries_origins = filtered_data[filtered_data['Country of asylum'].isin(top_countries['Country of asylum'])]
fig_sunburst = px.sunburst(top_countries_origins, path=['Country of asylum', 'Country of origin'], values='Total decisions',
title="원산지별 상위 10개 국가의 출신국 분포",
color='Total decisions', color_continuous_scale=px.colors.qualitative.Bold)
fig_sunburst.update_layout(height=600, showlegend=False)
fig_sunburst.update_coloraxes(showscale=False) # 색상 스케일 제거
st.plotly_chart(fig_sunburst)
위 코드에서 설명한 내용:
- 슬라이더(st.slider)를 사용하여 데이터 필터링을 위한 연도 범위를 선택합니다.
- 선택한 연도 범위를 기반으로 데이터가 필터링되며, 추방 판정 횟수가 계산됩니다.
- 데이터를 정렬하여 총 추방 판정 상위 10개 국가를 결정합니다.
- 수평 막대 차트(px.bar)를 사용하여 총 추방 판정 상위 10개 국가를 시각화합니다. 범례와 색상 스케일은 showlegend=False 및 update_coloraxes(showscale=False)를 사용하여 제거됩니다.
- 상위 10개 국가의 출신국을 나타내기 위해 태양 편포 차트(px.sunburst)가 생성됩니다. 범례와 색상 스케일 역시 showlegend=False 및 update_coloraxes(showscale=False)를 사용하여 제거됩니다.
위 코드를 사용하여 진행 상황을 테스트하고, 성장 중인 애플리케이션을 저장하고 실행할 수 있습니다. 시각적 결과는 다음과 같습니다:
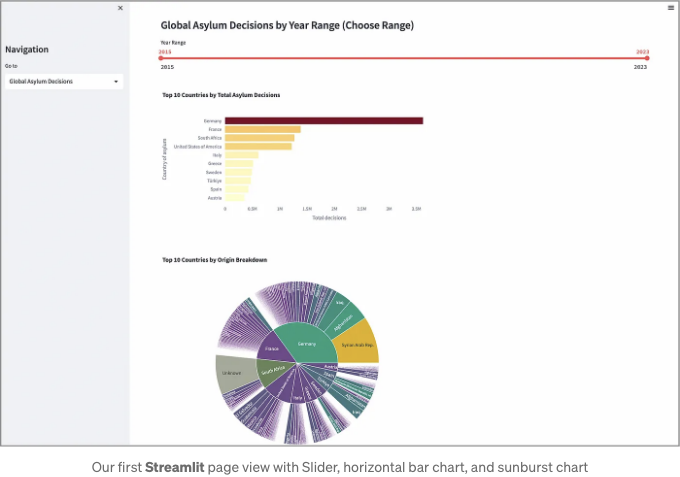
슬라이더를 조정하여 좀 더 집중된 연도 범위를 설정할 수 있습니다. 또한 Plotly sunburst 차트로는 실제 국가 (내부 원에서)를 클릭하여 더 상세한 숫자 세트를 생성할 수 있습니다:
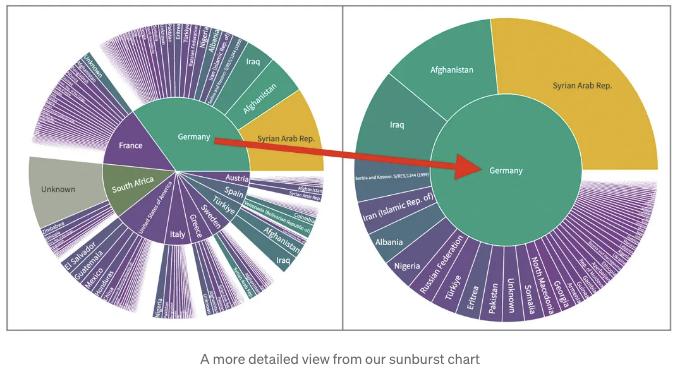
이 보기에서 각 국가 위로 마우스를 올리면 실제 숫자를 볼 수 있습니다.
좋아요! 이제 우리 페이지 2에 국가별 데이터를 몇 가지 추가해보겠습니다.
페이지 2: 국가별 데이터 시각화
이제 페이지_country_analysis() 함수에 데이터 시각화 코드를 추가하여 선택한 국가의 난민 심사 결정을 표시할 수 있습니다.
이 과정에는 두 가지 시각화가 포함됩니다: 연도별 인정된 및 거부된 난민 심사 결정 수를 보여주는 그룹화된 막대형 차트와 선택한 국가의 총 인정된, 거부된 및 총 심사 결정을 보여주는 수평 막대형 차트:
# 페이지 2: 국가별 분석과 그룹화된 막대 차트
def page_country_analysis():
st.subheader("국가별 분석")
country = st.selectbox("국가 선택", data['Country of asylum'].unique())
country_data = data[data['Country of asylum'] == country]
country_data_long = pd.melt(country_data, id_vars=['Year'],
value_vars=['Recognized decisions', 'Rejected decisions'],
var_name='결정 유형', value_name='수량')
fig_grouped_bar = px.bar(country_data_long, x='Year', y='수량', color='결정 유형', barmode='group',
title=f"{country}의 연도별 입국 결정",
labels={'수량': '결정 수'},
color_discrete_sequence=px.colors.sequential.YlOrRd)
fig_grouped_bar.update_layout(height=400, showlegend=True)
st.plotly_chart(fig_grouped_bar)
total_decisions = country_data[
['Recognized decisions', 'Rejected decisions', 'Total decisions']].sum().reset_index()
total_decisions.columns = ['결정 유형', '수량']
fig_horizontal_bar = px.bar(total_decisions, x='수량', y='결정 유형', orientation='h',
title=f"{country}의 총 입국 결정",
color='결정 유형', color_discrete_sequence=px.colors.sequential.YlOrRd)
fig_horizontal_bar.update_layout(height=300, showlegend=False)
st.plotly_chart(fig_horizontal_bar)
코드 설명:
- 드롭다운 (st.selectbox)을 사용하여 데이터 세트의 국가 목록에서 국가를 선택합니다.
- 선택한 국가를 기반으로 데이터가 필터링됩니다.
- pd.melt()를 사용하여 데이터를 wide에서 long 형식으로 변환하여 그룹화된 막대 차트를 생성합니다.
- 선택한 국가에 대해 연도별로 인정된 및 거부된 입국 결정의 수를 시각화하는 그룹화된 막대 차트 (px.bar)가 생성됩니다. 범례는 showlegend=True를 사용하여 표시됩니다.
- 선택한 국가의 인정된, 거부된 및 총 결정 수를 계산하고 수평 막대 차트 (px.bar)를 사용하여 표시합니다. 범례는 showlegend=False를 사용하여 제거됩니다.
이 코드를 간단히 복사하여 Page 2의 셸 애플리케이션에 붙여넣고 명령 프롬프트에서 실행할 수 있습니다. 결과:
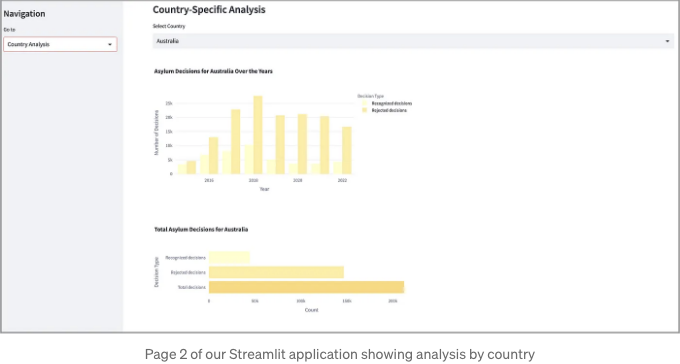
그럼, 이제 세 분의 길을 거쳐 왔어요. 마지막 페이지로 아름다운 전 세계 Choropleth 지도를 만들어 볼게요.
페이지 3: 전 세계 Choropleth 지도
이제 선택한 연도에 대한 전 세계 망명 결정의 분포를 표시하기 위해 데이터 시각화 코드를 page_choropleth() 함수에 추가해 보겠습니다. 이것은 각 나라별로 망명 결정의 총합을 시각화하는 choropleth 지도를 만드는 과정을 포함합니다.
# Page 3: Choropleth Mapping
def page_choropleth():
st.subheader("전체 지도 매핑")
year = st.selectbox("연도 선택", sorted(data['Year'].unique()), key='year_select')
year_data = data[data['Year'] == year]
asylum_counts = get_asylum_counts(year_data, 'Country of asylum')
st.subheader(f"{year}년 전체 난민 심사 분포")
fig = px.choropleth(asylum_counts, locations="Country of asylum", locationmode='country names',
color="Total decisions",
hover_name="Country of asylum", color_continuous_scale=px.colors.sequential.YlOrBr)
fig.update_layout(height=500)
st.plotly_chart(fig)
st.subheader(f"{year}년 각 국가별 난민 심사결과")
sorted_asylum_counts = asylum_counts.sort_values(by='Total decisions', ascending=False)
st.dataframe(sorted_asylum_counts)
위 코드를 설명하자면:
- 드롭다운 (st.selectbox)을 사용하여 데이터 세트에 있는 연도 목록에서 연도를 선택합니다.
- 선택한 연도를 기반으로 데이터를 필터링하고 난민 결정 횟수를 계산합니다.
- 선택한 연도에 대한 각 국가의 총 난민 결정을 시각화하기 위해 코로플레스 맵 (px.choropleth)이 생성됩니다. 색상 스케일은 color_continuous_scale=px.colors.sequential.YlOrBr를 사용하여 설정합니다.
- 난민 결정을 국가별로 내림차순으로 정렬된 데이터 테이블 (st.dataframe)이 표시됩니다.
앞 페이지와 마찬가지로 이 코드를 페이지_choropleth() 함수에 복사하여 저장하고 실행하면 멋진 결과가 나타납니다:
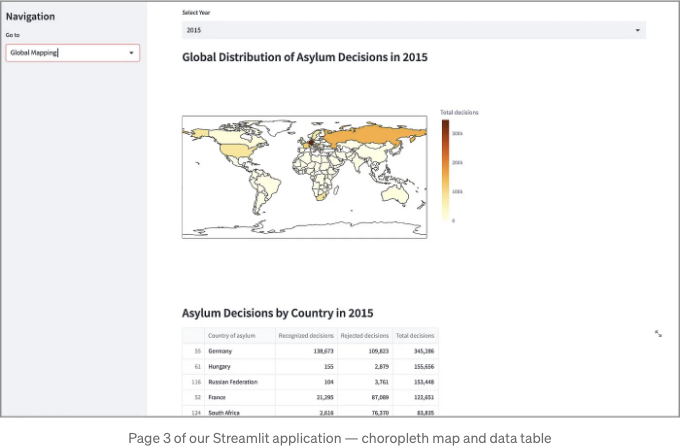
정말 멋지네요.
네, 멀티페이지 스트림릿 애플리케이션을 만드는 것이 그렇게 간단합니다.
만약 빌드에 문제가 있다면 코드(그리고 데이터셋)는 GitHub에서 찾을 수 있습니다. 여기
요약하자면...
Streamlit은 Plotly와 같은 표준 Python 데이터 시각화 라이브러리를 사용하여 빠르고 쉽게 데이터 시각화를 생성할 수 있는 훌륭한 애플리케이션입니다.
이 프로젝트는 다양한 범위의 연도에 걸쳐 글로벌 UNHCR 망명 데이터를 나타내는 3페이지의 Streamlit 애플리케이션을 보여줍니다.
우리는 사용자에게 이 데이터에 대해 다양한 이야기와 관점을 제공하기 위해 6가지 다른 데이터 시각화를 만들었습니다.
다중 페이지 애플리케이션 셸을 먼저 만들면 각 차트와 페이지를 쉽게 추가, 제거 또는 수정할 수 있습니다. 예를 들어, 네 번째 페이지를 추가하고 싶다면 "Page 4" 함수를 만들고 해당 페이지에 시각화를 추가한 다음 페이지 논리에 추가 메뉴 항목을 추가하면 됩니다(첫 번째 단계에서 만듦).
이 내용이 유익하고 도움이 되었기를 바랍니다.
GitHub 저장소: 여기
이 유형의 내용이 마음에 든다면 작가로서 저를 지원하고 싶다면 제 Substack를 구독해 주세요.
Substack에서 매주 두 번 뉴스레터와 다른 플랫폼에서는 찾을 수 없는 기사를 게시하고 있어요.