데이터 과학 분야에서는 공간 데이터를 조작하고 분석하는 능력이 다양한 가능성을 열어줍니다. 배송 경로를 최적화하는 것부터 자연 자원을 관리하는 것까지 응용 분야는 광범위하고 다양합니다. GeoPandas는 파이썬의 강력한 라이브러리로, 파이썬에서 지리 데이터를 다루는 것을 쉽게 만들어줍니다.
GeoPandas는 pandas가 사용하는 데이터 유형을 확장하여 기하학적 유형에 대한 공간 연산을 허용합니다. 기하학적 연산은 shapely에서 수행됩니다. GeoPandas는 파일 액세스를 위해 Fiona에, 플로팅을 위해 Matplotlib에 의존합니다.
기본적으로 GeoPandas는 매우 인기 있는 pandas 라이브러리의 확장으로, 익숙한 pandas 프레임워크 내에서 지리 데이터를 직관적으로 처리할 수 있습니다. 이는 이미 pandas를 잘 알고 있다면 GeoPandas를 숙달하기에 절반 정도 되었다는 것을 의미합니다!
하지만 GeoPandas를 독특하게 만드는 요소는 무엇일까요? 먼저, 지리 공간 데이터 작업을 간편화하여 pandas에서 다루는 다른 유형의 데이터를 조작하는 것만큼 지리 정보를 읽고 분석하며 시각화하는 작업을 간단하게 만듭니다. 점, 선 또는 다각형과 같은 데이터를 처리할 때도 GeoPandas가 모두 해결해 드립니다.
GeoPandas의 응용 분야는 지리 정보 분석 분야 자체만큼 다양합니다. 도시 계획자들은 보다 효율적인 대중 교통 시스템을 설계하는 데 사용할 수 있고, 환경 과학자들은 토지 이용 변화를 시간이 지남에 따라 추적할 수 있으며, 기업은 지리 데이터를 기반으로 물류를 최적화할 수 있습니다. 가능성은 정말 무한합니다.
이 블로그 포스트에서는 GeoPandas의 기본부터 고급 지리 분석 기술까지 다뤄볼 것입니다. 경험 많은 데이터 과학자이든 막 시작한 분이든, GeoPandas가 데이터 분석 도구상에서 어떻게 가치 있는 통찰을 제공하는지 알 수 있을 것입니다.
Python pandas를 사용하는 다른 블로그 포스트도 확인해 보세요: [링크 추가]
GeoPandas 환경 설정하기
GeoPandas를 사용하여 공간 분석의 흥미로운 세계로 들어가기 전에 제대로 된 환경을 설정하는 것이 중요합니다. 이는 GeoPandas가 올바르게 작동하기 위해 필요한 몇 가지 종속 항목과 함께 GeoPandas를 설치하는 것을 포함합니다. 걱정하지 마세요. 이 과정은 간단하며, 저가 단계별로 안내해 드리겠습니다.
단계 1: Python 설치하기
가장 먼저, 시스템에 Python이 설치되어 있는지 확인하세요. GeoPandas는 Python 라이브러리이므로 Python이 필수입니다. 아직 Python을 설치하지 않은 경우, 공식 Python 웹사이트에서 다운로드하고 사용 중인 운영 체제에 맞는 설치 지침을 따르세요.
단계 2: 가상 환경 설정하기 (선택 사항이지만 추천됨)
파이썬 프로젝트를 위해 가상 환경을 사용하는 것이 좋은 실천 방법입니다. 이렇게 하면 프로젝트의 종속성이 다른 프로젝트와 격리되며 잠재적인 충돌을 피할 수 있습니다. 다음 명령을 사용하여 터미널이나 명령 프롬프트에서 가상 환경을 만들 수 있습니다:
python -m venv geopandas_env
가상 환경을 활성화하려면 다음 명령을 사용하세요:
- Windows에서:
geopandas_env\Scripts\activate
- macOS와 Linux에서:
source geopandas_env/bin/activate
단계 3: GeoPandas 및 종속성 설치
환경이 설정되었으면 GeoPandas를 설치할 차례입니다. GeoPandas에는 파일 액세스를 위한 Fiona, 기하학적 작업을 위한 Shapely 및 플로팅을 위한 matplotlib과 같은 종속성이 몇 가지 있습니다. GeoPandas와 그 종속성을 모두 설치하는 가장 쉬운 방법은 Anaconda 또는 Miniconda를 설치한 경우 conda 명령을 사용하는 것입니다:
conda install geopandas
만약 pip를 사용하고 싶다면, 다음 명령을 사용하여 GeoPandas를 설치할 수 있습니다:
pip install geopandas
참고: pip를 사용하여 GeoPandas를 설치할 때 Windows에서 작업하는 경우 일부 종속성을 수동으로 설치해야 할 수 있습니다. GeoPandas를 설치하고 발생할 수 있는 문제를 처리하는 세부 지침은 GeoPandas 설치 문서를 참조하십시오.
단계 4: 설치 확인
모든 것이 올바르게 설정되었는지 확인하려면 Python 인터프리터 또는 Jupyter Notebook을 열고 GeoPandas를 가져와보세요:
import geopandas as gpd
만약 오류가 발생하지 않았다면, 축하합니다! 이제 GeoPandas를 사용하여 작업을 시작할 준비가 되었습니다.
GeoPandas의 기본: GeoSeries와 GeoDataFrame
GeoPandas는 파이썬에서 지리 정보 데이터를 직관적이고 간단하게 다룰 수 있도록 pandas의 데이터 구조를 기반으로 합니다. GeoPandas의 핵심은 두 가지 주요 데이터 구조인 GeoSeries와 GeoDataFrame입니다. 이를 이해하는 것은 지리 정보 분석을 위해 GeoPandas의 전체 능력을 활용하는 데 필수적입니다.
GeoSeries: 기본 구성 요소
GeoSeries는 본질적으로 각 항목이 도형 또는 기하 객체 세트인 벡터입니다. 이는 Shapely가 지원하는 포인트, 라인, 폴리곤 또는 다른 모양 유형일 수 있습니다. Shapely는 평면 기하 객체를 조작하고 분석하기 위한 Python 라이브러리입니다.
이제 GeoSeries를 설명하기 위한 간단한 예제를 살펴보겠습니다:
from shapely.geometry import Point, Polygon
import geopandas as gpd
# 포인트 GeoSeries 생성
points = gpd.GeoSeries([Point(1, 1), Point(2, 2), Point(3, 3)])
# 포인트 시각화
points.plot()
이 예제에서는 세 개의 점으로 이루어진 GeoSeries를 만들고, 이러한 점들을 .plot() 메서드를 사용하여 시각화합니다. 지오메트릭 데이터를 처리하고 시각화하는 간단함이 GeoPandas를 지리적 분석에 강력하게 만드는 이유입니다.
GeoDataFrame: 공간적으로 활성화된 DataFrame
GeoDataFrame은 GeoSeries가 포함된 탭ular 데이터 구조입니다. 이는 pandas DataFrame과 유사하지만, 기하 정보가 포함된 추가적인 열을 가지고 있습니다. 일반적으로 'geometry'라는 이 특별한 열은 기하학적 객체(예: 점, 선, 다각형)를 보유하고 데이터 세트에서 공간 연산을 가능하게 합니다.
다음은 Shapely 기하학 요소 목록에서 GeoDataFrame을 생성하는 방법입니다.
# 몇 개의 점과 다각형을 정의
polygon = Polygon([(0, 0), (1, 1), (1, 0)])
points = [Point(0.5, 0.5), Point(1.5, 1.5)]
# GeoDataFrame 생성
gdf = gpd.GeoDataFrame({'geometry': points + [polygon]})
# GeoDataFrame 플로팅
gdf.plot(alpha=0.5, linewidth=2, edgecolor='k', color='cyan')
이 예제에서 점과 다각형을 하나의 GeoDataFrame으로 결합한 후 그래픽으로 표시합니다. alpha, linewidth, edgecolor 매개변수를 사용하여 플롯의 모양을 사용자 정의할 수 있습니다.
지리 공간 데이터 읽기
지리 공간 분석에서 가장 흔한 작업 중 하나는 다양한 파일 형식에서 지리 공간 데이터를 읽는 것입니다. GeoPandas는 이를 지원하는 shapefile, GeoJSON 등 여러 형식을 포함한 read_file 함수를 통해 이를 쉽게 할 수 있습니다.
# shapefile 읽기
gdf = gpd.read_file("파일/경로/shapefile.shp")
# GeoJSON 파일 읽기
gdf = gpd.read_file("파일/경로/파일.geojson")
# GeoDataFrame의 처음 몇 행 살펴보기
gdf.head()
이러한 기본 사항을 알았으니 이제 지리 공간 데이터를 탐색하고 분석할 준비가 되었습니다. 다음 섹션에서는 공간 조인, 오버레이 분석, 지리 공간 데이터 시각화와 같은 고급 주제를 다룰 것입니다.
곧 GeoPandas를 사용하여 지리 정보 데이터를 활용하는 기본 작업 몇 가지를 살펴보겠습니다. 이 섹션에서는 지도 데이터를 조작하고 분석하는 방법에 대해 다룰 것이며, 플로팅, 필터링 및 기본적인 공간 작업을 포함합니다. 이러한 작업은 어떠한 지리 정보 분석에도 필수적이며, 더 고급 기술에 대한 튼튼한 기초를 제공할 것입니다.
GeoPandas에서 지리 정보 데이터 다루기
GeoPandas는 지리 정보 데이터를 다루는 과정을 간소화하여 플로팅, 필터링 및 기본 공간 작업과 같은 작업을 직관적이고 효율적으로 수행할 수 있게 해줍니다. 이러한 작업 중 일부를 살펴보고, GeoPandas를 사용하여 지리 정보 데이터를 조작하고 분석하는 방법을 살펴봅시다.
지리 정보 데이터 플로팅
지리 데이터 시각화는 지리 분석에서의 기본적인 작업입니다. GeoPandas는 Matplotlib과 통합되어 데이터를 쉽게 시각화할 수 있습니다:
import geopandas as gpd
import matplotlib.pyplot as plt
# 샘플 지리 데이터 세트를 불러옵니다.
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
# 전 세계 지도를 그립니다.
world.plot()
plt.show()
이 예제에서는 GeoPandas 내장 데이터 세트를 불러와 세계 각국의 지오메트리를 포함합니다. .plot() 메서드를 사용하여 데이터 세트를 지도로 시각화합니다.
데이터 필터링
GeoPandas는 기하학적 및 속성 기반 조건을 기반으로 데이터를 쉽게 필터링할 수 있습니다. 예를 들어, 특정 지역이나 국가 집합에 초점을 맞추고 싶다면:
# 북아메리카 국가를 위한 GeoDataFrame 필터링
north_america = world[world['continent'] == 'North America']
# 필터링된 GeoDataFrame 플롯
north_america.plot()
plt.show()
이 코드 스니펫은 세계 GeoDataFrame을 필터링하여 북아메리카 국가만 포함하고 필터링된 데이터를 플롯합니다.
기본 공간 작업
GeoPandas는 영역, 거리를 계산하고 기하학적 변환을 수행하는 등 다양한 공간 작업을 지원합니다.
# 각 국가의 면적 계산
world['area'] = world.geometry.area
# 지오메트리에 버퍼 작업 수행
buffered_point = south_america.geometry.buffer(1)

첫 번째 작업은 세계 GeoDataFrame의 각 나라에 대한 면적을 계산합니다. 두 번째 예는 버퍼 작업을 보여줍니다. 이 작업은 GeoDataFrame의 지오메트리 주변에 버퍼 영역을 생성합니다.
공간 조인
공간 조인은 GeoPandas의 강력한 기능 중 하나로, 두 GeoDataFrame을 공간적 관계를 기반으로 결합할 수 있습니다.
# 도시의 GeoDataFrame 만들기
도시 = gpd.read_file(gpd.datasets.get_path('naturalearth_cities'))
# 도시와 국가 간의 공간 조인 수행
국가별_도시 = gpd.sjoin(도시, world, op='within')
# 결과 확인
국가별_도시.head()
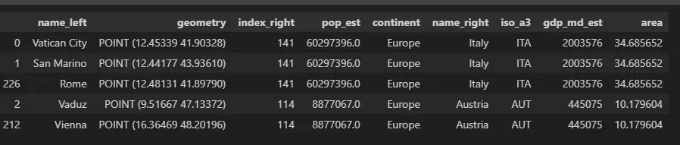
이 예시는 도시의 GeoDataFrame과 국가의 세계 GeoDataFrame 간의 공간 조인을 수행합니다. 결과는 도시와 각 도시가 속한 국가를 포함하는 새로운 GeoDataFrame입니다.
기본 작업의 기반 위에 더 나아가, GeoPandas를 사용하여 고급 지리 공간 분석 기술을 알아보겠습니다. 이 섹션에서는 오버레이 분석, 버퍼 분석, 그리고 최근접 이웃 쿼리와 같이 더 복잡한 작업을 다룰 것입니다. 이러한 기술들은 더 나은 통찰력을 제공하며 복잡한 지리 공간 문제에 대응하기 위해 중요합니다.
GeoPandas를 활용한 고급 지리 공간 분석
GeoPandas는 기본 지리 공간 작업을 단순화할 뿐만 아니라 고급 지리 공간 분석을 위한 강력한 도구도 제공합니다. 이 섹션에서는 이러한 고급 기술 중 일부를 살펴보며 지리 공간 데이터에서 더 심층적인 통찰력을 발견할 수 있도록 도와줍니다.
오버레이 분석
오버레이 분석은 두 개의 GeoDataFrames를 공간 관계에 따라 결합하여 교차점, 합집합 및 차집합과 같은 작업을 수행하는 데 사용됩니다. 이를 통해 공간 데이터의 서로 다른 레이어를 결합하여 새로운 통찰을 얻는 데 도움이 됩니다.
import geopandas as gpd
# 서로 다른 레이어를 나타내는 두 개의 GeoDataFrame 로드
gdf1 = gpd.read_file("경로/레이어1.shp")
gdf2 = gpd.read_file("경로/레이어2.shp")
# 교차점을 찾기 위해 오버레이 분석 수행
intersection = gpd.overlay(gdf1, gdf2, how='intersection')
# 결과를 플로팅
intersection.plot()
이 예제에서는 gpd.overlay를 사용하여 두 공간 레이어간의 교차점을 찾는 데 사용되었는데, 이는 공원 및 도시 경계와 같은 서로 다른 지리적 특징을 나타낼 수 있습니다.
버퍼 분석
버퍼 분석은 기하학 주변에 버퍼 영역을 만들어 근접성 분석에 유용합니다. 예를 들어, 강이나 도로로부터 특정 거리 내의 모든 지역을 찾고 싶을 수 있습니다.
# GeoDataFrame의 각 지점 주변에 1 km 버퍼 생성
buffered_points = gdf1.geometry.buffer(1000)
# 버퍼된 기하학 플롯
buffered_points.plot()
이 코드 스니펫은 gdf1의 각 지오메트리 주변에 1 km의 버퍼 영역을 생성하며, 이는 관심 지점과 같은 피처를 나타낼 수 있습니다.
#최근접 이웃 쿼리
최근접 이웃 쿼리는 “각 학교의 가장 가까운 병원은 무엇인가요?”와 같은 질문에 중요합니다. GeoPandas를 scikit-learn과 같은 라이브러리와 결합하여 이러한 쿼리를 효율적으로 수행할 수 있습니다.
from sklearn.neighbors import BallTree
import numpy as np
# 지오메트리를 좌표의 넘파이 배열로 변환합니다
coordinates = np.array(gdf1.geometry.apply(lambda geom: (geom.x, geom.y)).tolist())
# 효율적인 공간 쿼리를 위해 BallTree를 생성합니다
tree = BallTree(coordinates, leaf_size=15, metric='haversine')
# 특정 지점의 가장 가까운 이웃을 쿼리합니다
distance, index = tree.query([a_specific_point.coords[0]], k=1)
# gdf1에서 가장 가까운 지오메트리를 찾습니다
nearest_geometry = gdf1.iloc[index[0]]
이 스니펫은 scikit-learn의 BallTree를 사용하여 GeoDataFrame 내에서 특정 지점에 가장 가까운 이웃을 효율적으로 찾는 방법을 보여줍니다.
고급 시각화 기법
고급 시각화 기술을 사용하면 지리 정보 데이터의 해석을 높일 수 있어요. GeoPandas는 contextily와 같은 라이브러리와 함께 사용하여 플롯에 베이스맵을 추가하고 matplotlib를 사용하여 더 많은 사용자 정의를 할 수 있어요.
import contextily as ctx
# GeoDataFrame 그림 그리기
ax = gdf1.plot(figsize=(10, 10), alpha=0.5, edgecolor='k')
# 베이스맵 추가
ctx.add_basemap(ax, crs=gdf1.crs.to_string(), source=ctx.providers.Stamen.Terrain)
이 코드는 gdf1의 플롯에 베이스맵을 추가하여 공간 데이터의 시각적 맥락을 향상시킵니다.
다음 섹션에서는 GeoPandas를 활용하여 실제 데이터를 분석하고 시각화하는 방법을 탐색할 거에요.
뉴욕 시의 공공 공원 분석
뉴욕 시의 공공 공원의 분포와 특징을 분석하기 위해 GeoPandas를 사용할 거에요. 어떤 자치구에 가장 많은 공원 면적이 있는지, 공원들의 공간적 분포를 시각화하고 도시 내 공원과의 근접성을 조사할 거에요.
단계 1: 데이터셋 불러오기
먼저, GeoJSON 데이터셋을 GeoDataFrame으로 불러올 거에요:
import geopandas as gpd
# GeoJSON 데이터를 GeoDataFrame으로 로드합니다.
parks_gdf = gpd.read_file("https://data.cityofnewyork.us/api/geospatial/rjaj-zgq7?method=export&format=GeoJSON")
# 면적 계산을 위해 GeoDataFrame이 사영 좌표 체계를 사용하도록합니다.
parks_gdf = parks_gdf.to_crs(epsg=2263)
# EPSG:2263는 뉴욕 롱 아일랜드(피트)를 위한 좌표 체계입니다.
# 각 공원의 면적을 제곱 피트로 계산합니다.
parks_gdf['area'] = parks_gdf.geometry.area
# GeoDataFrame의 처음 몇 행을 검사합니다.
parks_gdf.head()
# 공원을 그래픽으로 표시합니다.
parks_gdf.plot()
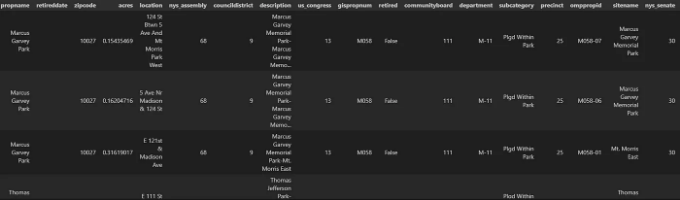
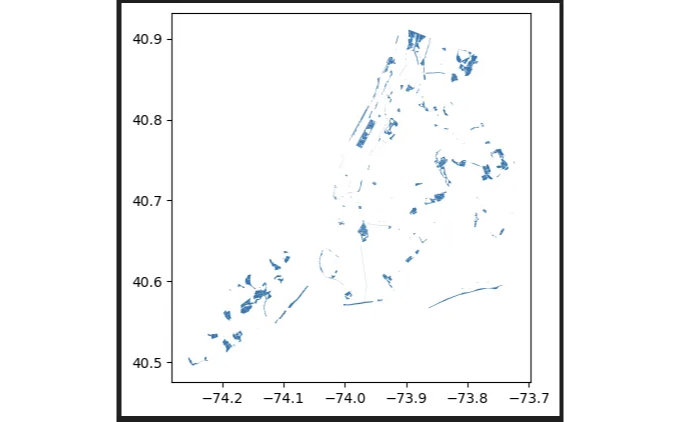
이 코드는 URL에서 데이터 세트를 직접로드하고 GeoDataFrame을 만들어 데이터를 검사하고 구조를 이해하는 데 사용됩니다.
단계 2: 데이터 탐색 및 정리
분석에 앞서 데이터를 탐색하고 정리하는 것이 중요합니다. 이 과정에는 결측값을 확인하고, 사용 가능한 속성을 이해하며, 지오메트리가 유효한지 확인하는 작업이 포함될 수 있습니다.
# 결측값 확인
print(parks_gdf.isnull().sum())
# 데이터 유형 및 속성 확인
print(parks_gdf.dtypes)
# 모든 지오메트리가 유효한지 확인
parks_gdf = parks_gdf[parks_gdf.is_valid]
단계 3: 자치구별 공원 분포 분석
가정하에 데이터셋에는 각 공원이 속한 자치구를 나타내는 열이 포함되어 있다고 가정하면, 자치구별로 데이터를 집계해서 공원 면적의 분포를 분석할 수 있습니다.
# 자치구별로 데이터를 집계하고 공원 면적을 합산합니다.
park_areas_by_borough = parks_gdf.dissolve(by='borough', aggfunc='sum')
# 결과를 시각화합니다.
park_areas_by_borough.plot(column='area', legend=True, cmap='Greens')
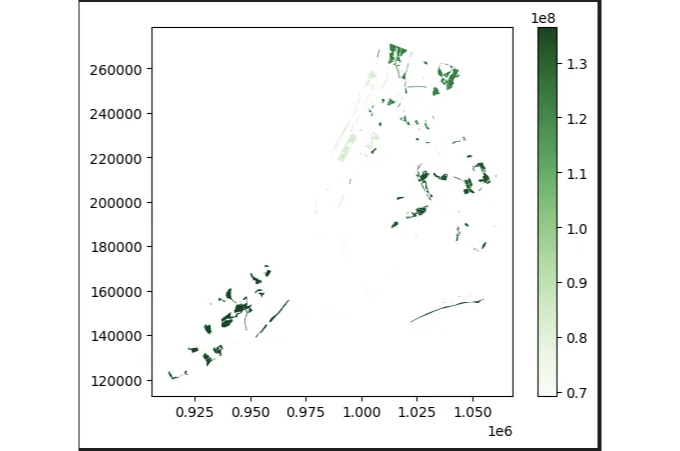
단계 4: 공원의 공간 분포 시각화하기
도시 전체에 걸쳐 공원이 분포하는 공간적 분포를 이해하기 위해 지도상에 공원을 시각화할 수도 있습니다.
import matplotlib.pyplot as plt
import contextily as ctx
# 공원 플로팅
ax = parks_gdf.plot(figsize=(10, 10), color='green', alpha=0.5)
# 베이스맵 추가
ctx.add_basemap(ax, crs=parks_gdf.crs.to_string())
# 제목 설정
ax.set_title("뉴욕시의 공원의 공간 분포")
plt.show()
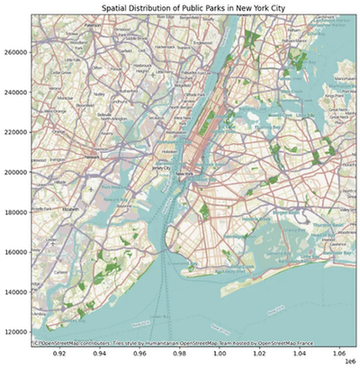
이 시각화를 통해 뉴욕시의 도시 경관 내에서의 공원 밀도와 분포를 이해하는 데 도움이 될 것입니다.
단계 5: 근접성 분석
더 고급화된 분석을 위해, 우리는 공원에서 일정 거리 내에 있는 도시의 어느 지역들을 확인하는 근접성 분석을 수행할 수 있습니다. 이는 도시 계획 및 공중보건 연구에 유용합니다.
from geopandas.tools import sjoin
from shapely.geometry import Point
import numpy as np
# 도시 전체에 대한 포인트 그리드 생성
x = np.linspace(parks_gdf.bounds.minx.min(), parks_gdf.bounds.maxx.max(), num=100)
y = np.linspace(parks_gdf.bounds.miny.min(), parks_gdf.bounds.maxy.max(), num=100)
xx, yy = np.meshgrid(x, y)
grid_points = gpd.GeoDataFrame(geometry=gpd.points_from_xy(xx.flatten(), yy.flatten()), crs=parks_gdf.crs)
# 각 공원 주변 500피트의 버퍼 생성 (필요에 따라 거리 조정 가능)
parks_buffered = parks_gdf.buffer(500)
# 버퍼된 지리 데이터 시리즈를 지리 데이터프레임으로 변환
parks_buffered_gdf = gpd.GeoDataFrame(geometry=parks_buffered)
# 그리드 포인트와 버퍼된 공원 간의 공간 조인 수행
points_near_parks = gpd.sjoin(grid_points, parks_buffered_gdf, how='inner', op='intersects')
# 결과 시각화
ax = points_near_parks.plot(markersize=2, color='blue', alpha=0.5, label='Near Proximity to Parks')
parks_gdf.plot(ax=ax, color='red', alpha=1, label='Parks')
ctx.add_basemap(ax, crs=parks_gdf.crs.to_string())
ax.set_title("뉴욕시의 공원에서 500m 내의 지역")
plt.show()
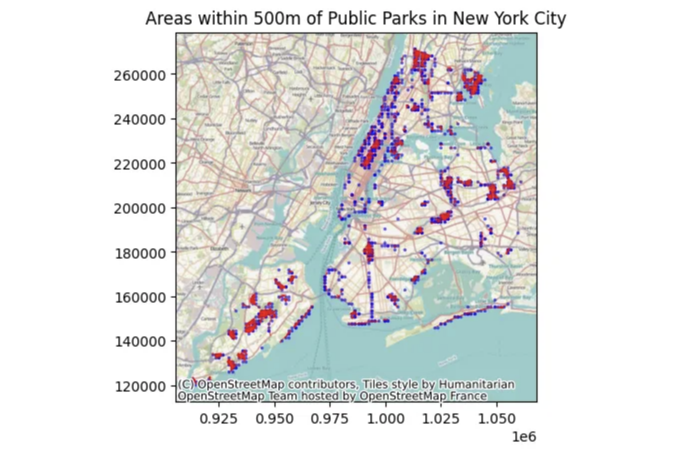
이 근접성 분석은 공원 주변 500m 내 영역을 강조하여 도시 개발 및 접근성 연구에 유용한 통찰력을 제공할 것입니다.
구 당 공원 밀도
공원의 분포를 더 세밀하게 이해하기 위해 구 당 공원 밀도를 계산할 수 있습니다. 이는 각 구 내의 공원 수를 세어 해당 구의 총 면적으로 나누는 것을 포함합니다.
# parks_gdf에 'borough' 열이 있고 면적 계산을 위해 EPSG:2263으로 투영된 상태로 가정합니다
borough_area = parks_gdf.dissolve(by='borough', aggfunc='sum')['area']
# 각 구 내 공원 수 세기
park_count = parks_gdf['borough'].value_counts()
# 제곱 피트 단위의 면적을 마일 단위로 환산하여 공원 밀도 계산
park_density = park_count / (borough_area / (5280**2))
# 공원 밀도 그래프
park_density.plot(kind='bar', title='구 당 공원 밀도 (제곱 마일당 공원 수)')
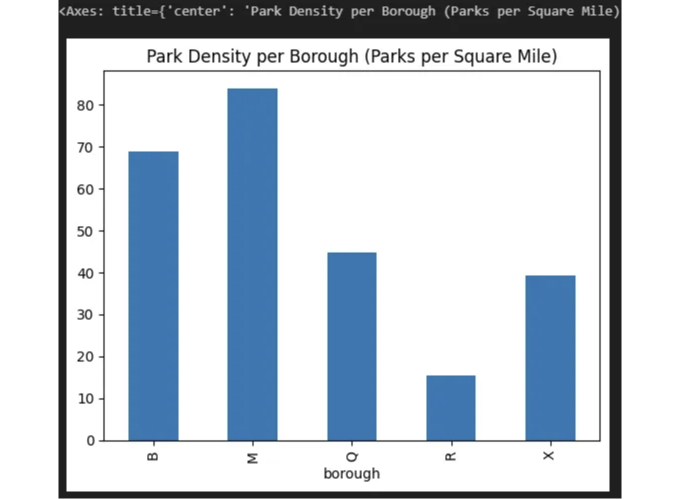
가장 크고 작은 공원
가장 크고 작은 공원을 식별하면 도시 내 중요한 녹지 공간 및 레크리에이션 공간이 부족할 수 있는 지역을 강조할 수 있습니다.
# 가장 큰 공원
largest_park = parks_gdf.iloc[parks_gdf['area'].idxmax()]
# 가장 작은 공원
smallest_park = parks_gdf.iloc[parks_gdf['area'].idxmin()]
print(f"가장 큰 공원: {largest_park['name']} in {largest_park['borough']}, 면적: {largest_park['area']} 제곱피트")
print(f"가장 작은 공원: {smallest_park['name']} in {smallest_park['borough']}, 면적: {smallest_park['area']} 제곱피트")

공원으로부터 관심지점까지의 근접성
학교, 병원 또는 주거 지역 등 다양한 관심지점들과 가장 가까운 공원까지의 근접성을 분석하는 것은 녹지 공간에 대한 대중 접근성에 대한 통찰을 제공할 수 있습니다.
from shapely.geometry import Point
# 위도 및 경도 좌표를 사용하여 관심지점을 정의합니다.
points_of_interest = {
'타임즈 스퀘어': (-73.9855, 40.7580),
'센트럴 파크': (-73.9654, 40.7829),
'브루클린 다리': (-73.9969, 40.7061)
}
# 관심지점을 GeoDataFrame으로 변환합니다.
poi_gdf = gpd.GeoDataFrame(geometry=[Point(lon, lat) for lon, lat in points_of_interest.values()], crs="EPSG:4326")
poi_gdf = poi_gdf.to_crs(parks_gdf.crs) # 정확한 거리 계산을 위해 parks_gdf와 동일한 CRS로 변환합니다.
poi_gdf

# parks_gdf은 공원 정보를 포함하는 GeoDataFrame입니다.
if parks_gdf.sindex is not None: # 공간 인덱스가 있는지 확인합니다.
for index, poi in poi_gdf.iterrows():
# 각 관심지점에 대해 가장 가까운 지오메트리를 공간 인덱스에서 쿼리합니다.
# 경계가 아닌 포인트 지오메트리를 직접 전달합니다.
nearest_index = list(parks_gdf.sindex.nearest(poi.geometry, return_all=True, max_distance=None))[0]
nearest_park = parks_gdf.iloc[nearest_index[0]] # 여러 개의 공원이 있을 경우 첫 번째 가장 가까운 공원에 접근합니다.
# 가장 가까운 공원까지의 거리를 계산합니다 (CRS와 동일한 단위로)
distance = poi.geometry.distance(nearest_park.geometry)
print(f"{index}에 가장 가까운 공원: {nearest_park.geometry}, 거리: {distance:.2f}")

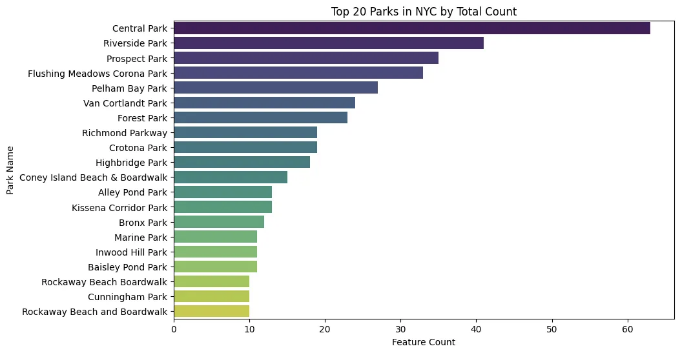
공원 특징 분석
만약 데이터 세트에 공원 기능(놀이터, 스포츠 시설, 수면 등)에 대한 정보가 포함되어 있다면, 우리는 이러한 기능들의 도시 전체 분포를 분석할 수 있습니다.
import seaborn as sns
# 'propname' 열은 공원에 대한 고유한 이름을 포함합니다.
feature_counts = parks_gdf['propname'].value_counts()
# 가장 일반적인 속성 이름(공원) 상위 10개를 선택합니다.
top_10_parks = feature_counts.head(20).reset_index()
top_10_parks.columns = ['공원 이름', '개수']
# 상위 10개 공원에 대한 Seaborn 막대 그래프를 생성합니다.
plt.figure(figsize=(10, 6))
sns.barplot(x='개수', y='공원 이름', data=top_10_parks, palette='viridis')
# 플롯 제목 및 레이블 추가
plt.title('뉴욕시의 상위 10개 공원 (총 개수 기준)')
plt.xlabel('기능 개수')
plt.ylabel('공원 이름')
plt.show()
공원 방문 시기에 대한 시간적 분석 (가상의 내용)
방문 데이터를 생성하고 시간에 따른 공원 방문 여부를 분석하면 공원 이용 추세, 피크 시간 및 잠재적으로 활용되지 않는 공간을 확인할 수 있습니다.
import pandas as pd
import numpy as np
# parks_gdf에 'park_id'와 같이 각 공원에 대한 고유 식별자가 있습니다.
park_ids = parks_gdf.index + 1
parks_gdf['park_id'] = parks_gdf.index + 1
# 샘플 날짜 생성
dates = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D')
# 방문 데이터를 보유할 DataFrame 생성
visitation_data = []
for park_id in parks_gdf['park_id']:
for date in dates:
# 각 공원과 날짜마다 방문자 수를 0에서 500 사이의 무작위 숫자로 생성
visitors = np.random.randint(0, 500)
visitation_data.append({'park_id': park_id, 'date': date, 'visitors': visitors})
# 리스트를 DataFrame으로 변환
vis_df = pd.DataFrame(visitation_data)
# 적어도 1000개의 행이 있는지 확인
assert len(vis_df) >= 1000
# 방문 DataFrame의 처음 몇 행 보기
vis_df.head()
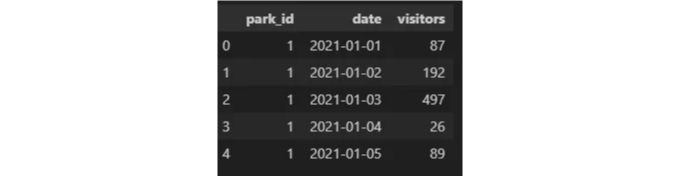
공원 방문 시간에 대한 시간적 분석
가정적인 방문 데이터가 준비되었으므로, 시간 분석을 진행할 수 있습니다. 전체 방문 추세를 탐색하고, 공원 간 방문을 비교하며, 방문 정점 기간을 식별할 것입니다.
전반적인 방문 추세
# 전체 추세를 확인하려면 날짜별로 방문자를 집계합니다.
overall_trends = vis_df.groupby('date')['visitors'].sum()
# 전체 방문 추이 플롯
overall_trends.plot(title='2021년 전체 공원 방문 추이', ylabel='총 방문자 수', xlabel='날짜')
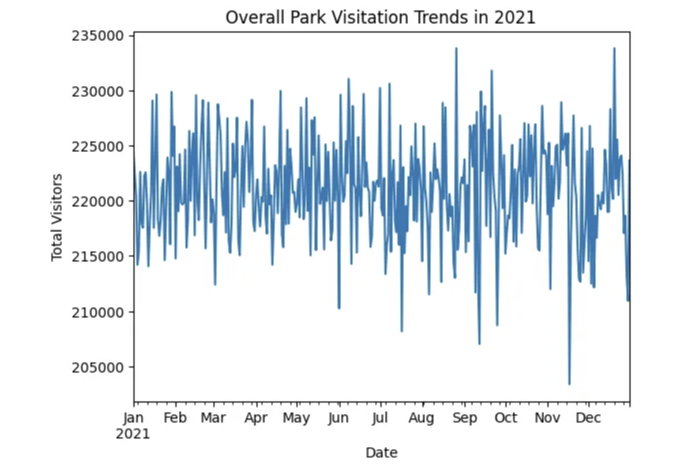
이 그래프는 연중 공원 방문자 수의 변동을 보여줄 것이며, 계절 패턴이나 특정 일자에 발생하는 비정상적으로 높거나 낮은 방문을 식별하는 데 도움이 됩니다.
공원별 방문 추이
방문자 수에 따라 다른 공원의 성과를 비교하려면 선택한 공원의 방문 추이를 플로팅할 수 있습니다.
import matplotlib.pyplot as plt
#비교를 위해 공원의 하위 집합 선택
sample_parks = np.random.choice(park_ids, size=5, replace=False)
#선택한 공원을 위해 방문 데이터 필터링
sample_vis_df = vis_df[vis_df['park_id'].isin(sample_parks)]
#플로팅을 위해 데이터 피벗
pivot_df = sample_vis_df.pivot(index='date', columns='park_id', values='visitors')
#2021년 공원별 방문 추이 표시
pivot_df.plot(kind='area', figsize=(12, 8), stacked=True, title='2021년 공원별 방문 추이', alpha=0.5)
#그래프 사용자 정의
plt.ylabel('방문자 수')
plt.xlabel('날짜')
plt.legend(title='공원 ID', loc='right')
plt.show()
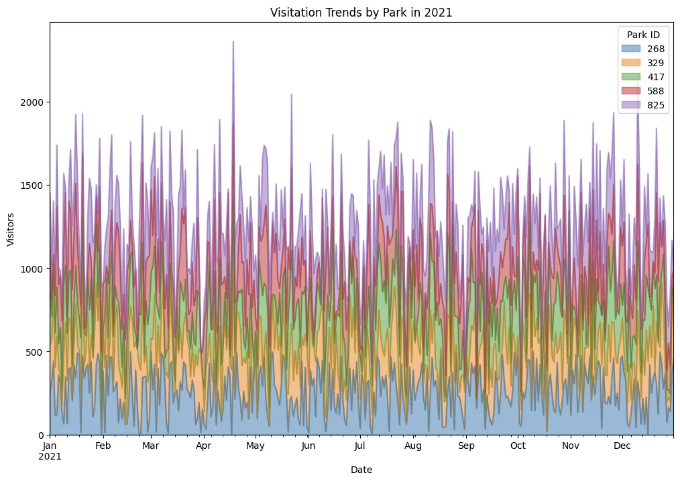
이 시각화는 가장 인기 있는 공원을 확인하는 데 도움이 되며, 각 공원의 방문량이 어떻게 시간이 지남에 따라 변하는지, 그리고 어떤 공원이 유사한 패턴을 보이는지를 확인할 수 있습니다.
최대 방문 기간 식별
우리는 데이터를 분석하여 전반적인 방문량이 가장 높은 날들을 찾고, 특정 이벤트나 휴일이 공원 이용 증가를 견인하는지 확인할 수 있습니다.
# 방문자 수가 가장 많은 상위 10일을 찾습니다
peak_days = overall_trends.nlargest(10)
# 방문자 수가 많은 상위 날짜를 출력합니다
print("방문자가 많은 날짜:")
print(peak_days)
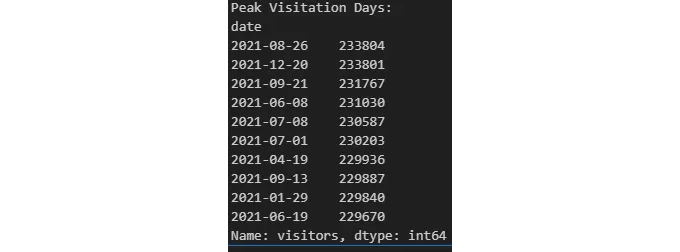
이 분석을 통해 공원 방문에 공휴일, 날씨 조건 또는 특별 행사가 미치는 영향에 대한 통찰을 얻을 수 있습니다.
데이터 프레임 결합하기
Join parks_gdf with vis_df: 두 데이터 프레임을 park_id 열을 기준으로 병합하여 각 공원의 공간 데이터와 방문 데이터를 모두 포함하는 병합된 데이터 프레임을 얻을 것입니다.
# 'park_id' 열을 기준으로 parks GeoDataFrame와 visitation DataFrame을 병합합니다
combined_gdf = parks_gdf.merge(vis_df, on='park_id')
# 병합된 GeoDataFrame을 확인합니다
combined_gdf.head()
방문 데이터 집계
이 예제에서는 한 해 동안 각 공원별 총 방문자 수를 계산해 보겠습니다.
# 방문 데이터를 종합하여 각 공원당 총 방문객 수를 구합니다.
total_visitors_per_park = combined_gdf.groupby('park_id')['visitors'].sum().reset_index()
# 이 종합된 데이터를 공원 데이터와 병합하여 공간 데이터를 유지합니다.
parks_with_visitors_gdf = parks_gdf.merge(total_visitors_per_park, on='park_id')
시각화
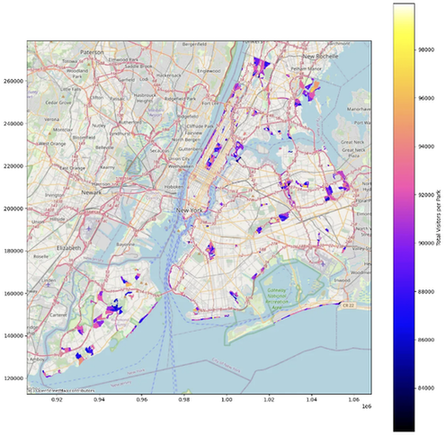
이제 각 공원의 크기를 이용하여 총 방문객 수를 나타내는 방식으로 공원을 시각화할 수 있습니다. 또는 색상을 사용하여 이 데이터를 표현할 수도 있습니다.
# 그림과 축 설정
fig, ax = plt.subplots(1, 1, figsize=(15, 15))
# 공원을 플로팅하고, 각 공원의 포인트 크기를 총 방문객 수에 따라 조절합니다.
# 색상을 cmap에서 찾아보세요: https://matplotlib.org/stable/users/explain/colors/colormaps.html
parks_with_visitors_gdf.plot(ax=ax, column='visitors', legend=True, legend_kwds={'label': "총 방문객 수"},
markersize=parks_with_visitors_gdf['visitors'] / 100, # 마커 크기 조정
cmap='gnuplot2') # 색상 지도 사용
# 참고를 위해 배경지도 추가 (선택 사항, contextily 및 인터넷 접속 필요)
try:
import contextily as ctx
ctx.add_basemap(ax, crs=parks_with_visitors_gdf.crs.to_string(), source=ctx.providers.OpenStreetMap.Mapnik)
except Exception as e:
print(f"배경지도를 추가할 수 없습니다: {e}")
# 플롯 표시
plt.show()
만약 Python을 사용하여 실제 데이터셋을 분석해보고 싶다면, 제 다른 블로그 포스트도 확인해보세요:
Python을 사용하여 처음부터 챗봇을 만드는 흥미진진한 세계에 뛰어들어보세요. 포괄적인 가이드는 여기에서 확인할 수 있습니다: