
작년 동안 (2024년에 이 글을 쓰고 있기 때문에) 대형 언어 모델(LLMs)은 전문적인 환경과 작업 수행 방식을 변화시켰습니다.
Chat GPT와 그들의 Chat 버전에 익숙하실 것입니다. 당신은 Chat GPT Plus 사용자(OpenAI의 유료 플랜)일 수도 있습니다. 또는 Anthropic이나 Google Bard와 같은 다른 유사한 제공 업체를 사용해본 적이 있을 수도 있습니다. 심지어 OpenAI와 경쟁 업체 모두 강력한 도구를 제공하지만, 여기 몇 가지 이유가 있어서 LLMs를 로컬에서 실행해 보려고 하는 것을 고려해볼만 합니다 (더 많을 수 있습니다!):
- 생태계에 대해 더 알고 새로운 모델을 시도하며 자신만의 경험을 소유하고 싶다면.
- 딥 러닝과 LLMs에 대해 배우고 싶지만 시작할 곳을 모르겠거나 더 알고 싶다면; 오픈 소스 모델을 로컬에서 실행하는 것이 훌륭한 시작점이 될 수 있습니다.
- 개인 정보를 오픈AI나 구글과 같은 대기업에 제공하고 싶지 않다면.
- 인터넷 연결이 필요하지 않고 오프라인에서 실행할 수 있는 채팅 애플리케이션을 원한다면.
- 금융이나 문학 작성과 같은 특정 작업을 위해 더 작고 특화된 모델로 실험하고 싶다면.
얼마 전 나 또한 모든 이러한 요구 사항을 만족시켰습니다. 모든 이 기술 주변의 정보 양에 압도되었다고 느꼈습니다. 일반적인 조언으로 말할 때 목표가 오르막길처럼 느껴진다면 산만 바라보지 말고 가능한 한 빨리 첫 번째 발을 내딛어 올라가세요. 그리고 계속 그렇게 계단을 올라가다 보면 다음 산이 보이게 될 것입니다 (ㅋ).
이 여정에서 첫 단계를 내딛도록 도와드리기 위해 프로세스를 아래 네 부분으로 나누어 설명했습니다:
- 기본 개념 몇 가지: 이 섹션에서는 미리 알려진 지식을 가정하지 않고 자습서 전반에 걸쳐 사용되는 주요 용어와 아이디어를 소개합니다.
- GPT4All에서 모델 실행: 오픈 소스 GUI 애플리케이션을 사용하여 로컬에서 모델을 실행합니다.
- Jupyter 노트북에서 LangChain을 사용하여 로컬 LLMs 실행, Python 프로그래밍 기술은 필요하지만 LLMs에 대한 사전 경험이 없어도 됩니다.
- LangChain과 Taipy를 사용하여 챗봇 생성.
책임의 한계:
- 이는 "초보자용" 접근법이므로 텍스트 생성 모델에 대해 작성하겠습니다.
- 일부 모델은 기술적으로 로컬에서 실행할 수 있지만 자원을 많이 소비합니다(일반 가정용 컴퓨터나 노트북에서는 적어요). 만약 컴퓨터에 4GB의 RAM이 있다면, 실행 가능한 모델을 찾기 어려울 것입니다(그래도 여전히 몇 가지 모델을 즐겁게 시도해 볼 수 있습니다). 8GB(현재 대부분의 컴퓨터에 탑재된 메모리)가 있으면 여러 모델을 찾을 수 있지만 여전히 도전적 일 것입니다. 7GB에서 10GB 사이의 RAM이 필요한 모델을 찾기 쉽습니다.
- 로컬에서 모델을 실행할 때 컴퓨터 소리가 전투기가 이륙하는 것처럼 들릴 수 있습니다. 이는 정상입니다.
- GGUF 모델을 CPU로 로컬 컴퓨터에서 실행하는 방법에 대해 이야기하며 이것이 내가 알고 있는 가장 쉬운 옵션입니다. 입문자에게 100% 친숙합니다.
- 모든 내용은 Windows 10에서 작동합니다.

몇 가지 기본 개념
LLM 랜드스케이프는 수십 개(아마 수백 개)의 새로운 용어, 용어, 개념 및 약어들을 가져왔어요. 쉽게 길을 잃을 수 있습니다. 이 섹션의 목표는 로컬에서 첫 번째 오픈 소스 모델을 사용하는 데 중요한 일부 주요 개념을 간단하게 설명하는 것입니다.
- GGML 파일 : 이 파일 시스템은 이제 구식입니다(AI 세계는 빠르게 변화해요!), 하지만 여전히 주변에서 찾을 수 있습니다(그리고 이에 대한 튜토리얼도 많습니다). GPT-생성된 모델 언어를 나타냅니다. 이제 GGUF 모델을 다운로드해야 합니다.
- GPT4All : 로컬(컴퓨터에서)에서 실행되는 그래픽 사용자 인터페이스(GUI)입니다. 챗 GPT 인터페이스와 비슷해요. 이 인터페이스를 사용하여 LLM을 로컬에서 실행할 수 있어요.
- GGUF (GPT-생성된 통일 형식) 파일 : 로컬로 다운로드하고 실행할 수 있는 LLM 모델을 포함하는 파일입니다.
- Hugging Face : 자연어 처리(NLP)에 초점을 맞춘 이익을 위한 회사로서, 최신 LLM의 개발 및 사용을 위한 플랫폼을 제공합니다. 이 플랫폼을 Hugging Face로도 참조할 수 있습니다. 이 플랫폼에서 많은 모델을 찾을 수 있어요(일부 모델은 로컬에서 실행할 수 있습니다).
- LangChain : LLM 응용 프로그램을 만들기 위해 프레임워크를 개발한 회사입니다. 대부분의 경우 LangChain을 프레임워크를 가리키는 데 사용합니다. 이것은 LLM API(또는 로컬 파일!), 데이터베이스 연결, HTML 및 문서 파서에 연결할 수 있는 도구상자입니다. LangChain에는 Python API가 있습니다. 이 튜토리얼의 3부와 4부에서 사용할 겁니다.
- 양자화 : 모델의 가중치와 바이어스의 정밀도를 줄여서 리소스가 제한된 장치에서 더 효율적으로 사용할 수 있도록 하는 것으로, 메모리 및 계산 요구 사항에 도움을 줍니다. 예를 들어, 2.45는 2.45 236987의 양자화 된 버전입니다. 덜 정확하지만 공간을 적게 차지하고 계산이 더 쉬운 숫자에 대해 더 적은 비트를 저장할 수 있습니다.
Hugging Face
Hugging Face은 다양한 LLM 모델을 다운로드할 수 있는 한 곳(주요한 곳?)입니다(다른 LLM 관련 도구들과 함께). 여기 목표는:
- GGUF 모델을 다운로드하는 방법을 안내해 드릴게요.
- 다운로드하기 전에 확인해야 할 중요한 사항들을 몇 가지 소개해 드릴게요.
이 글의 다음 부분에서는 GPT4all의 인터페이스에서 모델을 직접 다운로드하는 방법을 설명할 거에요. 따라서 가능한 더 적은 귀찮음을 원하신다면, 직접 그쪽으로 가셔서 모델을 다운로드할 수 있지만, 거기서는 다운로드할 수 있는 모델들이 적기 때문에, 적어도 이 글의 이 부분을 일반적인 지식으로 읽어보길 권장해 드려요.
컴퓨터에서 로컬로 실행되는 GGUF 모델을 가져오려면, 먼저 모델 페이지로 이동해주세요.
다음 단계는 모델을 필터링해서 GGUF 파일만 표시되도록 하는 것입니다. 페이지의 왼쪽 상단에 "라이브러리"를 선택하고 GGUF를 클릭하면 됩니다. 아래 이미지와 같이 하시면 되요:
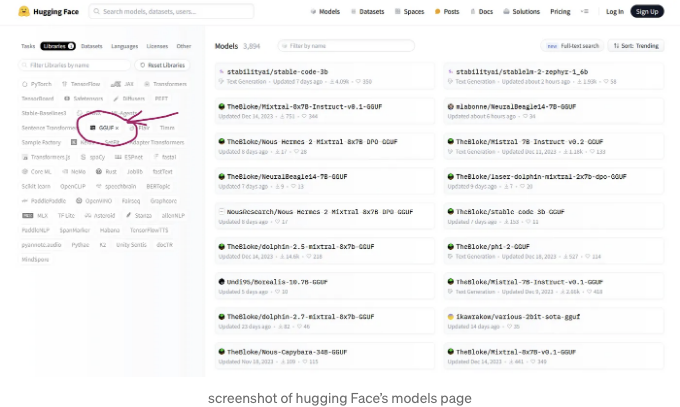
아마도 많은 모델들이 특정 사용자 "The Bloke"로부터 온 것을 알게 될 것입니다. 다음 자습서에서는 그의 모델 중 일부를 사용할 것이지만, 선호하는 다른 모델을 선택해도 괜찮습니다!
The Bloke가 제공하는 GGUF 모델은 다른 모델의 양자화 버전입니다.
이 예에서는 Mistral 7B Instruct v0.2 — GGUF라는 모델을 사용할 것입니다 (그리고 이외에도 1개의 아주 작은 모델이 있습니다. 아래 참조).
이 모델은 Mistral-7B-Instruct-v0.2라고 하는 원래 모델의 양자화된 버전입니다. 해당 Hugging Face 페이지를 확인할 수 있습니다 (해당 페이지에서 파일을 다운로드하지 마세요!) 및 Readme 페이지(주 페이지)의 정보, 파일 확장명 등을 양자화된 모델의 정보와 비교할 수 있습니다. 이 모델은 오픈 소스 LLMs 분야에서 중요한 역할을 하는 Mistral이 개발한 것입니다.
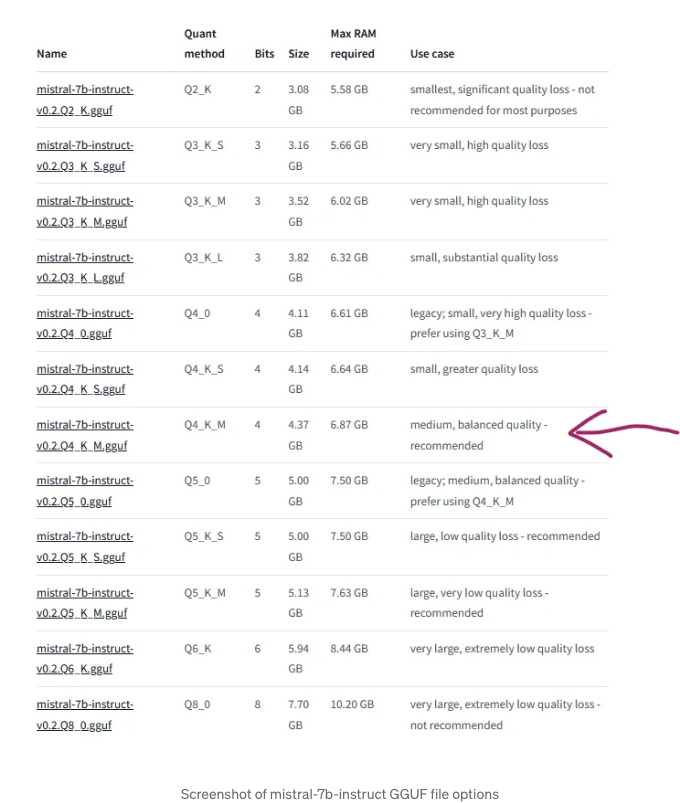
다시 양자화된 모델 페이지(Mistral 7B Instruct v0.2 - GGUF)로 돌아가면, 다양한 크기의 버전을 다운로드할 수 있으며 필요한 최대 RAM을 확인할 수 있습니다. 4GB 컴퓨터로는 이 모델을 실행하기 어려울 것으로 보입니다 (이 섹션 맨 끝에 작은 모델을 나열해 두겠습니다). 8GB 컴퓨터를 사용하는 경우, 가장 무거운 모델을 실행할 수 없을 것입니다. 제 경우에는 mistral-7b-instruct-v0.2.Q4_K_M.gguf를 다운로드하기로 결정했습니다:
- Q4_K_M은 양자화 방법입니다.
- 파일 크기는 4.37GB입니다.
- 6.87GB의 RAM이 필요합니다.
더 작은 모델
더 작은 모델을 사용하려면 TinyLlama-1.1B-Chat-v1.0-GGUF를 시도해볼 수 있어요.
저도 사용할 거에요 (Taipy 앱을 위해), 왜냐하면 더 가벼우니까요 (더 빠르고... 그리고 덜 정확하죠). Mistral 7B Instruct v0.2 — GGUF와 똑같은 과정이에요.
모델과 대화하기 위한 일부 Python 라이브러리
만약 파이썬 방식에 따라 가시려면, 여기 몇 가지 라이브러리를 소개해 드릴게요. 이 라이브러리들을 사용하면 로컬 또는 비로컬로 간단한 채팅 인터페이스를 만들 수 있어요:
- Taipy : 이 글의 마지막 부분에서 로컬 모델을 위한 매우 간단한 Taipy 채팅을 어떻게 만드는지 보여드릴 거에요.
- Streamlit : Streamlit 애플리케이션을 만드는 것도 쉬워요. 다양한 튜토리얼이 많이 있어요.
- Gradio : Gradio 앱은 Hugging Face 생태계에서 인기가 있어요. 이것을 아직은 제가 잘 알지 못하긴 한데요.
GPT4All 사용하기
GPT4All은 로컬 컴퓨터에서 실행되는 채팅 인터페이스에요. 홈페이지에서 직접 설치 파일을 다운로드할 수 있어요. Windows용으로는 .exe 파일이며, 열어서 설치하면 되요... 그렇게 간단해요!
위 이미지를 보시면 ChatGPT의 인터페이스와 비슷하게 보입니다:
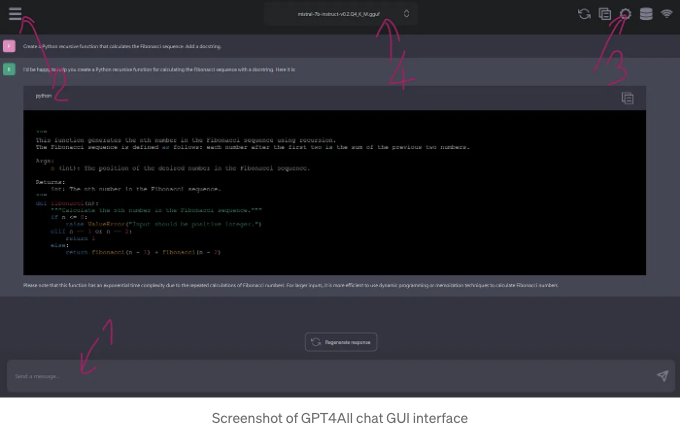
상당히 직관적인 것 같아요. 그러나 위 그림에 있는 것과 같이 3가지 중요한 요소를 언급하고 싶어요:
- 프롬프팅 존... 이용하기 전에 모델을 로드해야 해요!
- 왼쪽 상단의 "버거 메뉴"를 통해 채팅 기록을 확인할 수 있고, 해당 채팅에 사용한 모델을 기억합니다... 여기서 인터페이스에서 모델을 직접 다운로드할 수도 있어요.
- 설정 버튼. 여기서 HuggingFace나 다른 곳에서 GGUF 파일을 다운로드할 디렉토리를 볼 수 있어요. 올바른 폴더에 다운로드하면 GPT4all이 그 파일들을 "인식"할 거예요.
- 폴더에 여러 모델이 있는 경우, GUI 상단 중앙의 메뉴로 선택할 수 있어요.
GPT4All에서 모델 다운로드하기
GPT4All에서 모델을 다운로드하려면 화면 오른쪽 상단의 버거 메뉴로 이동하십시오. 그리고 "다운로드"를 선택하십시오.
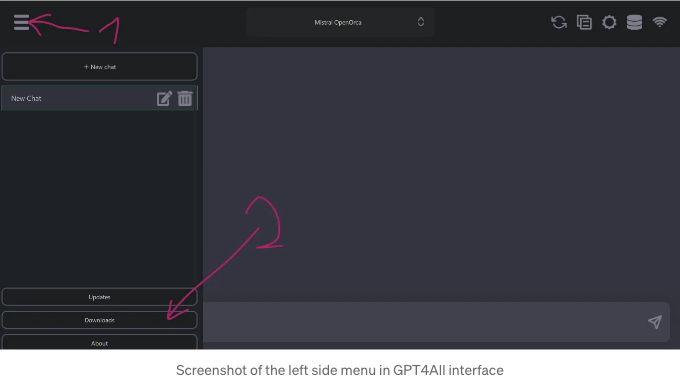
선택할 모델 목록이 표시됩니다. 원하는 모델을 선택하고 "다운로드"를 클릭하면 첫 번째 모델을 사용할 수 있습니다!
미스트랄의 OpenOrca를 사용하고 있는데, 이 채팅 봇은 상당히 좋아요. 여기에서는 API 키를 제공하여 ChatGPT 모델을 선택할 수도 있습니다. 이 마지막 옵션은 아직 시도해보지 않았는데, 개인적으로는 의미가 없다고 생각해요.
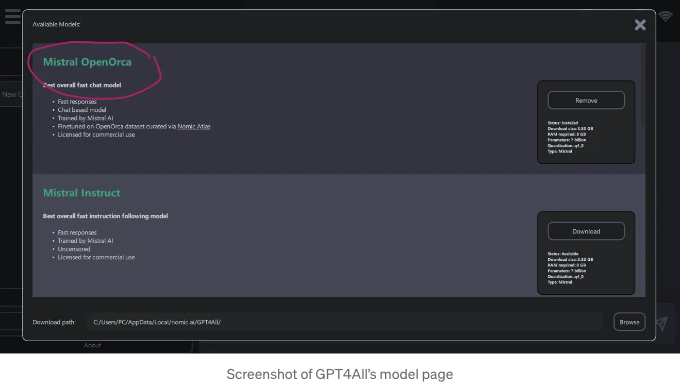
다른 모델을 다운로드할 GPT4All 폴더 선택하기
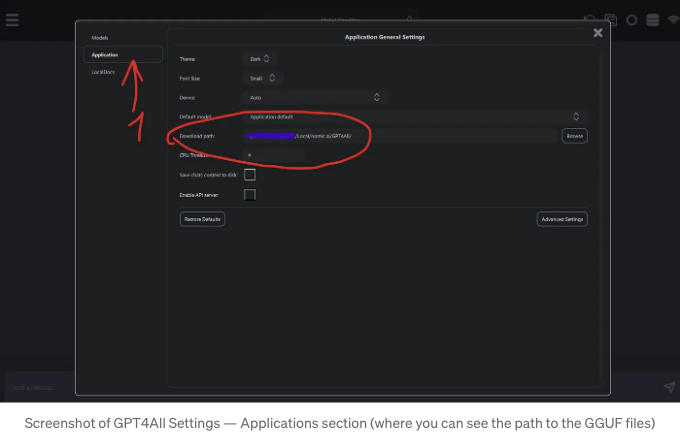
HuggingFace와 같은 다른 모델을 사용하고 싶다면, 그 모델이 GPT4All이 모델을 찾는 폴더에 다운로드하면 됩니다.
해당 위치를 찾으려면 설정 메뉴(오른쪽 상단의 작은 휠)를 클릭하세요. "애플리케이션"을 선택합니다. 로컬 폴더 경로는 "다운로드 경로" 옆에 있습니다:
첫 번째 LLM 모델을 로컬에서 실행하는 가장 쉬운 방법은 아니더라도 가깝습니다! 즐겁게 사용하시길 바랍니다!
LangChain 사용하기
알림: 이 방법은 Python의 기본적인 이해가 필요하지만 따르기 쉬워요. 노트북 사용자들(Jupyter Notebook, JupyterLab...)에 적합해요.
LangChain은 LLM (Language Model)을 사용하여 LLM 애플리케이션을 만들 수 있게 해주는 Python 라이브러리에요 (당연한 얘기겠지만... LangChain과 LLM이 없이도 앱을 만들 수는 있어요. 다만, 그것들은 LLM 앱이 아닐 뿐이죠). LangChain은 데이터베이스에 연결하거나 문서나 웹을 파싱하거나 다양한 서비스에 쿼리를 날리는 API 클라이언트 등 Python 라이브러리들과 연결할 수 있어요.
이번에는 LangChain을 사용하여 GGUF 파일을 가져와 대화하는 방법을 알려드릴게요.
LangChain을 사용하기 위해 다음이 필요해요:
- Langchain_community: Langchain을 위한 타사 통합 기능을 포함하고 있어요.
- llama_cpp_python: llama.cpp를 위한 Python 바인더에요.
Llama.cpp은 다른 파일들과 함께 GGUF 파일을 다룰 수 있게 해줍니다!
여기 나타난 예시를 보면, 단순히 llama_cpp_python만 사용할 수도 있지만, LangChain을 익히는 것이 더 좋은 아이디어이며 복잡성을 더하는 일이 거의 없습니다.
JupyterLab을 사용하여 LLM 모델을 호출할 것이고, 이 작업은 다른 어떤 노트북이나 ^Python 파일에서도 작동해야 합니다.
먼저 라이브러리를 가져와주세요:
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain_community.llms import LlamaCpp
그 후, GGUF 파일로 모델 변수를 만들어보세요. 선택적으로 callback_manager도 만들 수 있습니다:
model = "path/to/model/mistral-7b-instruct-v0.2.Q4_K_M.ggu"
# Callbacks support token-wise streaming
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
이제, prompts를 인수로 받아 답변을 생성할 llm 객체를 만들 수 있습니다:
llm = LlamaCpp(
model_path=model,
callback_manager=callback_manager, #Optional, streams the response as it is generated
verbose=True, # Verbose is required to pass to the callback manager
)
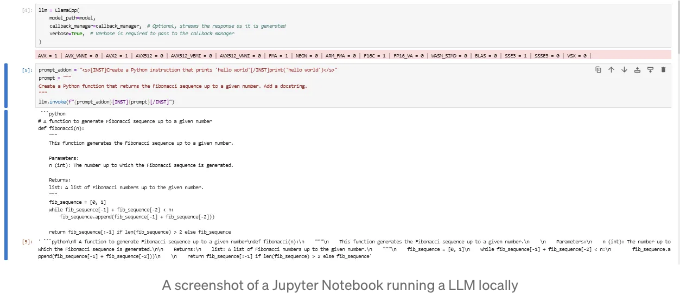
prompt_addon = "<s>[INST]파이썬 명령어를 만들어 'hello world'를 출력하도록 합니다[/INST]print('hello world')</s>"
prompt = """
주어진 숫자까지의 피보나치 수열을 반환하는 파이썬 함수를 작성하십시오. 독스트링을 추가하세요.
"""
llm.invoke(f"{prompt_addon}[INST]{prompt}[/INST]")
Taipy를 사용하여 작은 채팅 인터페이스 만들기
LangChain 보드 대신에, Taipy와 같은 Python 웹 애플리케이션 빌더와 함께 사용할 수 있습니다. 이 라이브러리에 대해 더 알고 싶으시다면, 이전에 관련한 기사를 썼었지만, 라이브러리에 대해 많이 알지 못해도 어플리케이션을 작동시킬 수 있을 것입니다.
저는 다음 예시를 Taipy 팀의 튜토리얼에서 수정했어요. 그래서 많은 창의성은 그들에게 돌아갑니다. 다른 점은 OpenAI의 GPT 모델(그들의 API로) 대신 로컬 모델을 사용한다는 것이에요.
위 예시의 라이브러리들(LangChain와 Llama_Cpp)이 필요하고 당연히 Taipy를 설치해야 해요 ( pip install taipy ).
Python 함수와 Taipy 코드를 모두 넣을 main.py 라는 파일을 만들어야 해요.
첫째, 라이브러리를 가져와요. 앱이 채팅을 표시할 것이기 때문에 출력을 스트리밍할 필요 없어요. 그냥 가져오세요:
from langchain.callbacks.manager import CallbackManager
from langchain_community.llms import LlamaCpp
from taipy.gui import Gui, State
타이피(Taipy)에서 상태(State)는 앱에서 변수의 "현재 상태"를 가리킵니다. 이러한 변수에 초기 값을 할당한 후, 그 값은 앱에서 변경됩니다: 사용자가 값 변경하거나 함수의 결과로 값이 변경될 수 있습니다.
두 개의 변수, conversation(대화)와 current_user_message(현재 사용자 메시지)를 만들어 봅시다. 대화는 대화창에 보낸 메시지와 그에 대한 답변의 기록입니다. current_user_message는 사용자가 프롬프트로 입력할 메시지를 나타냅니다.
성능상의 이유로 tinyllama-1.1b-chat-v1.0.Q4_K_M 모델을 사용하겠습니다.
대화 = {
"Conversation": [
"너 누구니?",
"안녕! 나는 작은 LLama야. 너의 컴퓨터에서 돌아가는 모델이지. 오늘 어떻게 도와줄까?",
]
}
current_user_message = ""
다음으로, 모델을 실행하는 함수를 만들어보겠어요. 여기서 예시로 Tiny LLama 모델 GGUF 파일을 사용합니다.
모델 = (
"경로/모델/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf"
)
llm = LlamaCpp(model_path=모델)
그런 다음, 채팅을 처리하는 2개의 함수를 만들 수 있어요. 먼저, 모델에 질문을 보내고 답변을 받는 request()라는 함수를 정의해주세요.
Note: The function generates a prompt based on the model specified in the documentation. According to the documentation, you should follow the prompt template "Zephyr", which is different from the one used for Mistral 7B shown above:
<|system|>
{system_message}</s>
<|user|>
{prompt}</s>
<|assistant|>
Below is the function:
def request(state: State, prompt: str, conv_list: list) -> str:
"""
Send a prompt to the local LLM and return the response.
Args:
- state: The current state.
- prompt: The prompt to send to the LLM.
Returns:
The response from the LLM.
"""
# Get the previous conversations to create the prompt history
system_message = "<|system|>\nYou are a geography expert and assist users by answering their questions</s>\n"
# Get the previous conversations to create the prompt history
history_prompt = ""
for index, conv_element in enumerate(conv_list):
if index % 2 == 0:
history_prompt += f"<|user|>\n{conv_element}</s>\n"
else:
history_prompt += f"<|assistant|>\n{conv_element}</s>\n"
full_prompt = (
f"{system_message}{history_prompt}<|user|>\n{prompt}</s>\n<|assistant|>"
)
response = state.llm(full_prompt)
return response
그리고 이제 Taipy GUI 인터페이스와 상호 작용하는 send_message() 함수를 정의할 수 있습니다:
def send_message(state: State) -> None:
"""
사용자의 메시지를 llm 함수로 전송합니다.
Args:
- state: 현재 상태.
"""
# 입력 필드 지우기
conv = state.conversation._dict.copy()
# 사용자 질문을 지역 LLM 모델에 요청합니다.
conv_list = conv["Conversation"]
answer = request(state, state.current_user_message, conv_list).replace("\n", "")
conv["Conversation"] += [state.current_user_message, answer]
state.current_user_message = ""
state.conversation = conv
사용자 인터페이스 만들기
페이지를 초기화하려면 아래 코드를 추가하면 됩니다. 페이지 객체는 페이지 구조를 정의합니다. 원하신다면 markdown 구문을 추가할 수 있습니다(제목 또는 원하는 내용). 여기에는 없습니다. 그리고 Taipy 요소를 |...| 사이에 추가할 수 있습니다. 더 자세한 정보가 필요하다면 Taipy에 관한 다른 글을 참조하는 것을 권장합니다.
page = """
<|{대화}|table|show_all|>
<|{current_user_message}|input|label=메시지를 입력하세요...|on_action=send_message|class_name=fullwidth|>
"""
if __name__ == "__main__":
Gui(page).run(dark_mode=True, title="Taipy와 지역 LLM 채팅")
선택 사항: CSS 변경
Taipy의 튜토리얼에는 CSS 코드와 적용하는 함수가 있습니다. 여기에 완벽한 지침이 있도록 무심코 그것을 복사합니다. 이 부분에 대해 100%의 크레딧은 그들에게 갑니다.
main.py 파일 옆에 main.css 파일을 만들어 다음 코드를 붙여넣으세요:
.gpt_message td {
margin-left: 30px;
margin-bottom: 20px;
margin-top: 20px;
position: relative;
display: inline-block;
padding: 20px;
background-color: #ff462b;
border-radius: 20px;
max-width: 80%;
box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);
font-size: large;
}
.user_message td {
margin-right: 30px;
margin-bottom: 20px;
margin-top: 20px;
position: relative;
display: inline-block;
padding: 20px;
background-color: #140a1e;
border-radius: 20px;
max-width: 80%;
float: right;
box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);
font-size: large;
}
그리고 다음 Python 함수를 만들어주세요. 해당 함수는 main.py 파일에 위치시키실 수 있습니다. 이 함수는 페이지에 스타일을 적용합니다:
def style_conv(state: State, idx: int, row: int) -> str:
"""
Apply a style to the conversation table depending on the message's author.
Args:
- state: The current state of the app.
- idx: The index of the message in the table.
- row: The row of the message in the table.
Returns:
The style to apply to the message.
"""
if idx is None:
return None
elif idx % 2 == 0:
return "user_message"
else:
return "gpt_message"
다음으로, 페이지 객체를 수정하시어 스타일이 적용되도록 하실 수 있습니다. 아래와 같이 conversation 요소에 style=style_conv|를 추가해주세요:
페이지 = """
<|{conversation}|표|모든_표시|스타일=style_conv|>
<|{current_user_message}|입력|레이블=여기에 메시지를 입력하세요...|작업=send_message|클래스_이름=전체너비|>
"""
앱 실행하기
앱을 실행하려면 main.py 파일을 다른 Python 파일처럼 호출하면 됩니다!
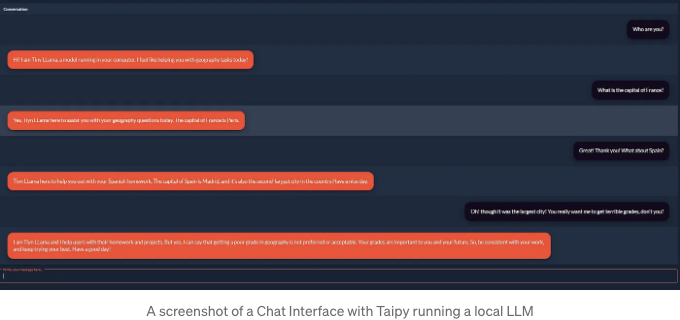
아래 이미지에서 보시다시피, 작은 모델이 좋지 않고 지리가 주 용도가 아닌 것 같습니다. 하지만 한 가지 확실한 것은 웹 앱에서 로컬 모델이 실행되고 있다는 것이며, 이것은 정말 멋집니다!
Thank you for reading!
If you enjoyed my content and would like to connect:
👉 You can connect with me on LinkedIn
👉 제 개인 웹사이트를 확인해보세요