
코델 태니는 금융 서비스 분야에서 23년 이상의 경험을 가진 전문가로, 양적 금융을 전문으로 하고 있습니다. 코델은 이전에 캐나다 주요 기관에서 양적 분석가 및 포트폴리오 매니저로 일하며 20억 달러 규모의 다자산 소매 투자 프로그램을 지도했습니다.
현재 코델은 Trend Prophets의 대표이사 및 공동창업자로 활동하고 있으며 양적 금융 및 AI 솔루션 기업인 DigitalHub Insights의 이사이기도 합니다. 그는 맥길 대학에서 생물학 학사 학위를 받았으며 CFA 차터홀더이며 금융 리스크 관리자 자격증을 보유하고 있으며 금융 데이터 전문가 차터를 보유하고 있습니다.
trendprophets.com 웹사이트를 방문하여 더 많은 정보를 얻어보세요.
모든 Python 코드는 기사 말미에 찾을 수 있습니다.
이 연재의 이전 부분에 대한 링크:
Python에서 리스크 온 대 리스크 오프 주식 시장 대시보드 만들기 - Part I
파이썬으로 리스크 온 대 리스크 오프 주식 시장 대시보드 만들기 - 파트 II: 상관 분석
파이썬으로 리스크 온 대 리스크 오프 주식 시장 대시보드 만들기 - 파트 III: 업데이트
소개
안녕하세요, 여러분. 데이터 과학과 양적 금융 프로젝트를 향한 나의 여정에 다시 오신 것을 환영합니다. 항상처럼, 이 블로그의 목표와 간략한 요약부터 시작하겠습니다.
이 프로젝트의 목표는 두 가지입니다:
- 데이터 과학/양적 금융 프로젝트를 진행하면서 연구 과정과 논리를 공유하는 것입니다. 포함되어 있는 것은:
a. 아이디어 도출.
b. 논리적 진행 및 흐름 다이어그램 작성 (여러 번 변경될 것입니다).
c. 필요한 자원, 데이터 및 기술 요구사항(프로그래밍 언어, 데이터베이스 설정, 기타)을 식별합니다.
나는 전문 재무 관리자 및 양적 금융 전문가로 일한 경험과 지식을 공유하려 합니다.
본 연구 프로젝트의 주요 목표는 리스크 온 대 리스크 오프 시장 회전을 식별하는 대시보드를 만드는 것입니다. 우리가 예측 모형을 구축할 수 있다면, 더할 나위 없겠죠.
첫 두 기사는 리스크 자산과 리스크 오프 자산 간의 회전을 시각화할 수 있는 히트맵을 만드는 데 중점을 두었습니다. 우리는 전통적인 성과 지표, 백분위 측정 및 상관 관계를 사용하여 평가를 수행했습니다. 이 분석은 이러한 기본 도구를 사용하여도 꽤 잘 보였습니다.
리뷰 및 요약
초안 이후 두 달이 지났으므로 백분위수와 상관 관계 열지도를 다시 살펴봅시다. 또한 시장에서 어떤 일이 벌어졌는지 살펴보겠습니다.
11월에 시작된 주요 리스크온 회전은 12월 마지막 주까지 바로 이어졌습니다. 그런 다음 시장(S&P 500)에서 풀백이 발생하여 1월 첫 주까지 계속되었습니다. 그 후 우리는 약간 더 높은 변동성을 가진 측면 움직임을 이어갔습니다. SPY와 DIA는 새로운 최고치를 기록했지만, QQQ는 훨씬 더 변동성이 있었습니다. QQQ는 최근에 Meta와 Amazon의 대박 실적으로 새로운 최고치를 경신했습니다. 그러나 QQQ는 리스크온 프록시가 아닙니다. QQQ가 이제 상품 ETF의 최상위 보유 종목이기 때문에 QQQ가 리스크온인 것으로 말하기는 벅차니 권합니다! Meta는 이제 배당을 지급합니다 (뭐야??? 그것은 그들이 성장할 방법이 없다고 보는 게 의미하는 건가요, 아니면 그들이 너무 많은 현금을 가지고 있어서 그냥 버리기로 결정하고 주주들에게 돌려주는 건가요? 이런 건 다른 이야기입니다).
이 시점에서 다시 한 번 강조해야 할 점은 나의 리스크온 프록시들이 좋은 프록시라고 난 장담할 수 없다는 것입니다. 이것이 우리가 알아내려고 하는 것입니다. 예를 들어, ARKK는 이상한 동물입니다. 특히 BTC 노출이 많기 때문에 그에 대한 구체적인 내용이 많아서 그것이 감정에 의해 주도되었는지 아니면 독특한 요인에 의해 주도되었는지 판단하기 어렵습니다. 리스크온 대 리스크오프는 감정, 기본 요인 및 가격을 움직이는 모든 정보를 포착할 수 있는 새로운 요인에 의해 지원되어야 합니다.
가장 "명백한" 위험 증감 지표들의 상대 성능을 먼저 살펴봅시다.
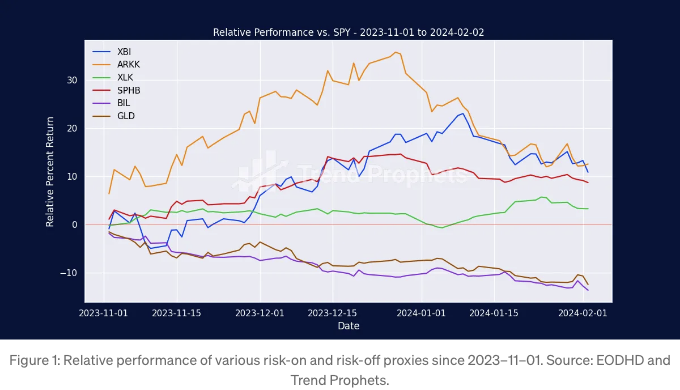
1월 1일부터 기술주 (XLK)만 SPY에 대해 양호한 상대 성과를 보이고 있습니다. 생명공학 (XBI)과 ARKK는 하락하고 있습니다. 금 (GLD)과 현금 (BIL)도 하락하고 있습니다. 고베타 주식 (SPHB)은 평평합니다. 그러므로 다시 한 번 대형 기술주가 시장을 이끌고 있는 것 같습니다. 그렇다면 이것은 위험 중립적 환경인가요? 나중에 대비하여 대시보드에 세 번째 상태를 추가하고 미래를 예측해야 할 수도 있습니다.
이 시점에서 가능성은 열려 있어야 합니다. 이것은 여정입니다!
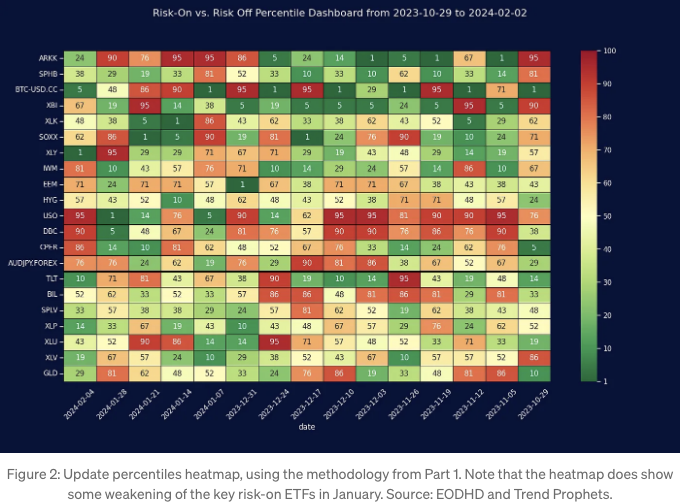
그래서 우리가 해야 할 일에 대한 요약을 보여드리겠습니다. 초기 단계의 목표는 리스크온 및 리스크오프 프록시를 선택하는 것입니다 (다음 단계에 대한 모든 아이디어 요약은 부록 III도 참고해주세요):
-
이미 있는 롤링 상관 관계 기능을 보완하기 위해 가격 및 수익 데이터에서 추가 기능을 생성합니다.
-
클러스터링 알고리즘을 적용하여 우리의 프록시를 시각화하고 원하는 그룹 형성을 달성하고 있는지 확인합니다.
-
클러스터를 결정하는 데 가장 많은 기여를 하는 피처를 식별하기 위해 피처 중요도를 추출합니다.
-
대리 변수 및 설명력이 없는 피처를 제거합니다.
재미를 좀 봅시다! 몇 가지 피처를 공학적으로 개발해 봅시다.
상관 관계를 크게 선호하지 않고, 한 시점에서의 상관 관계 추정치를 살펴보는 연구에 대해서도 조심스럽습니다. 이것은 제가 쓰레기를 생성하는 확실한 방법이기 때문입니다. 그래서 우리는 이동 상관 관계를 사용했습니다. 상관 관계는 선형 관계만을 포착하며, 일부 자산의 관계가 선형적으로 연관되어 있지 않을 수도 있습니다.
그래서, 변수 간의 관계를 설명하는 다른 방법을 찾아야 하며, 시간이 지남에 따라 어떻게 변하는지 파악하고 비선형성을 포착해야 합니다.
동적 시간 왜곡(Dynamic Time Warping)을 소개합니다
계속하기 전에 새로운 프로젝트를 진행하는 과정에서 제 사고 과정을 공유한다는 것을 강조해야 합니다. 저는 절대 모든 것을 알거나 답을 모두 알고 있는 것이 아니라는 점을 분명히 해야 합니다. 이것이 제가 배우는 방법이기 때문입니다. 필요한 작업을 수행하는 데 도움이 되는 양적 기법을 연구합니다. 그렇기 때문에 ChatGPT는 저와 같은 사람들에게는 놀라운 도구입니다. 저는 완전히 스스로 가르친 코더이며(이 글을 읽는 여러분 중 많은 분들처럼), 수학이나 컴퓨터 과학 학위가 없습니다. 그러나 제가 아주 빨리 배우는 경향이 있습니다. 그래서 동적 시간 왜곡의 발견이 제게 매우 의미 있는 것입니다. 새로운 것을 배울 수 있고, 그런 다음 이러한 새로운 기술을 활용하는 여러 가지 방법을 고안할 수 있습니다(제가 재무 분야에서 24년의 경험을 가지고 있다는 점을 기억해 주세요!).
동적 시간 왜곡의 간단한 개요입니다:
Dynamic Time Warping (DTW)는 두 개의 시계열 사이의 유사성을 측정하는 데 주로 사용되는 알고리즘입니다. 두 명의 사람이 두 개별 경로를 따라 걷고 있다고 상상해보세요. 각 사람마다 다른 보폭과 속도가 있습니다. 그들의 경로가 얼마나 비슷한지 비교하려면 각 초마다의 위치를 단순히 비교하는 것은 잘 작동하지 않을 것입니다. 왜냐하면 그들의 다른 속도로 인해 어느 순간에는 동기화되어 있고 다른 순간에는 동기화되어 있지 않을 수 있기 때문입니다. DTW는 각 시퀀스의 시간축을 "왜곡"하여 유사한 시간 포인트를 정렬함으로써 두 경로 사이의 유사성을 보다 의미 있게 제공하도록 도와줍니다.
상관 계수와 어떻게 다른가요?
상관 계수는 두 변수 간의 선형 관계를 측정하는 반면, DTW는 두 시계열의 형태와 패턴의 유사성을 측정합니다. 속도와 관계없이 말이죠. 이제 상관 계수에 비해 DTW의 장단점을 살펴보겠습니다:
상관 계수에 비한 DTW의 장점:
-
유연성: DTW는 선형 관계의 가정에 제약을 받지 않으며, 시퀀스가 상이한 속도, 위상 또는 길이를 가지더라도 유사성을 포착할 수 있습니다.
-
패턴 매칭: 데이터의 전체적인 형태를 고려하여 시퀀스를 정렬하므로 유사성을 최대화하여 패턴 매칭과 인식에 특히 유용합니다.
상관관계에 비한 단점:
- 계산 복잡성: 특히 긴 시퀀스의 경우 DTW는 계산적으로 상관관계를 계산하는 것보다 더 많은 자원이 필요하므로 대규모 데이터셋에는 제약이 될 수 있습니다.
- 해석 가능성: 상관 관계는 선형 관계의 방향과 강도를 나타내는 명확한 지표(-1 ~ 1)를 제공하지만, DTW 유사성 점수는 직관적이지 않을 수 있고 크기에 대해 해석하기 어려울 수 있습니다.
상관 관계와 마찬가지로, 우리는 각 자산 쌍에 대한 DTW 점수를 계산합니다. 이 경우에는 DTW 알고리즘을 사용하여 두 시퀀스 간의 거리를 측정하고 유사성을 평가합니다. 높은 DTW 점수는 높은 거리를 나타내며 따라서 두 시퀀스 간의 유사성이 낮음을 나타냅니다. 낮은 점수는 높은 유사성을 나타내며, 거리가 0이면 완전한 유사성을 의미합니다.
우리는 롤링 상관 관계와 동일한 방법론을 사용할 것입니다. 2013년부터 시작된 수익 데이터를 가지고 롤링 12주 및 24주 창을 통해 평균 쌍별 DTW 점수를 측정할 것입니다. (참고: 12주와 24주 창에 대한 결과에 큰 차이가 없어 12주 창만 제시하겠습니다).
결과 히트맵은 다음과 같습니다:
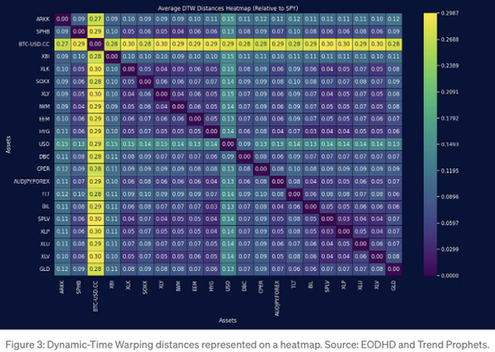
The resulting heatmap might appear more complex than the correlation matrix. To facilitate interpretation, let’s visualize this as a cluster map, allowing us to examine the dendrogram for clusters based on these values.
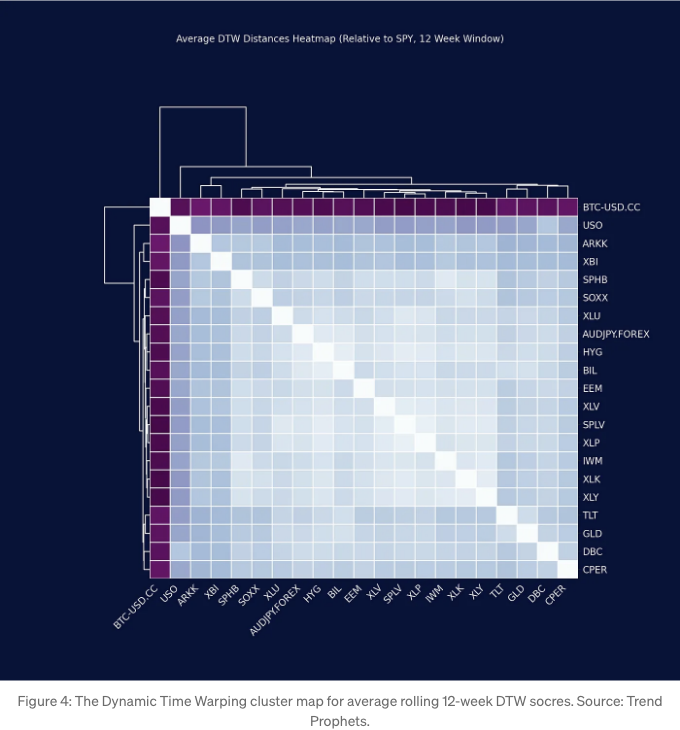
This visualization provides slightly more insight. To understand this graph, follow the lines to observe which assets are grouped together. As you move up the dendrogram, smaller clusters aggregate into larger ones.
USO와 BTC가 명확한 클러스터를 형성하고 있으므로 분석 제외 대상으로 고려될 수 있습니다. 그러나 남은 자산들의 색상은 유의미한 차이를 나타내지 않아 DTW 방법론의 한계가 있을 수 있다고 생각됩니다. DTW 점수에 기반하여 모든 것을 일축할 필요는 없으며, 이는 DTW가 작동하는 방식의 결과물일 수도 있습니다. 다른 시기에 자료를 스케일링하거나 정규화하여 향상된 결과를 얻을 수도 있습니다.
우리가 관찰한 주요 클러스터는 다음과 같습니다:
-
ARKK/XBI: 이는 두 가지 가장 변동성이 높은 자산이라는 점에서 우리에게 가장 좋은 후보들 중 하나입니다.
-
SPHB/SOXX: 고베타 주식 및 반도체. SOXX가 주기적인 특성을 가지고 있고 사업 주기에 민감하기 때문에 이 것을 본 것에 만족합니다. SPHB는 높은 위험으로 정의되어 있기 때문에 아마도 최고의 리스크 대리인 중 하나일 것입니다.
- TLT/GLD: 장기 국채를 GLD와 그룹화하는 것은 완벽하게 이해되며, 저 또한 이를 기쁘게 생각합니다.
대부분의 다른 클러스터는 처음에는 그렇게 많은 의미를 가지고 있지 않을 수 있습니다. EEM이 헬스케어, 저 변동성 및 소비재와 같이 그룹화된 것을 볼 수 있습니다. 그래, 우리는 아직 해야 할 일이 남아 있습니다. 왜냐하면 이것은 말이 되지 않기 때문이죠.
기억하세요; 우리는 탐사 단계에 있으며, 모든 것을 SPY에 대한 수익을 기반으로 하고 있습니다 (참고:DTW를 절대 가격 움직임에 대해 실행했고 SPY와의 관련에서만 수행하지 않았습니다. 의미있는 차이점이 없었습니다).
결론
저희는 DTW 점수와 상관 관계와 함께 계층적 클러스터링 알고리즘에 사용할 수 있어요. 저는 석유와 BTC를 제거할 수 있다고 확신해요. 전체 시장 모니터링 대시 보드에는 유지하지만, 일반적인 시장 위험 선호와 상관 관계가 없어 보입니다.
이제 다른 기술 분석 지표를 시험해 보고 싶어요. MACD, ADX 선 및 상대적 강도가 제일 먼저 올라와요. 다시 말하지만, 각 티커에 대한 롤링 값을 측정한 다음 상호 비교해야 하며, 상관 관계 및 DTW와 마찬가지로 이를 해야 할 거예요. 기술 지표의 롤링 평균값에 DTW를 사용할 수 있을 거에요. DTW는 지금부터 이 프로젝트의 나머지 부분 동안 엄청 유용할 거에요 (제 직관).
이 지표를 테스트할 예정이지만, 초기 직관은 반환을 기반으로 모든 것을 파생하는 한 비슷한 결과를 얻을 수 있다는 것을 시사해요. 그러므로, 평균 쌍별 측정만 사용하는 것은 시간에 따라 변하는 관계를 포착하지 못할 수 있음을 인식하는 것이 중요해요. 이 문제를 해결하기 위한 제 방법이 있고, 여러분은 고유한 해결책을 찾아보도록 도전해 보세요!
다음 단계
다음에 시도해볼 것이 무엇인지 궁금하네요. 댓글로 알려주세요. 이 프로젝트를 "오픈 소스"로 만들고 싶어해요. 제 아이디어는 있지만, 이 시점에서는 누구에게도 편향을 주고 싶지 않아요. 그것은 다음 단계에 남겨둘게요.
그래서 이제 시도해야 할 것은:
- 평균 측정치를 사용하는 대신 측정치의 시간 변동성을 포함하기.
- 추가 지표 추가하기 (기술적인 지표 및 기타 여러분이 고려해볼 것을 댓글에 남겨주세요!).
- 군집 알고리즘으로 진행하기.
이 여정의 일환으로, DTW를 발견한 것은 저에게 엄청 큰 일이었어요. 이제 이것은 시계열 분석에 자주 사용할 무기 중 하나가 되었어요. 그래서 가능한 많은 논문들을 읽어 봤어요. 하지만 DTW의 대부분 응용은 금융 분야 바깥에 있어요. 이것은 더 기쁜 일인데, 아마 다음 대단한 응용 프로그램을 찾아서 Trend Prophets 인벤토리에 추가할 수도 있을 거예요.
읽어주셔서 감사합니다! 그리고 이 테스트를 실행하는 데 시간이 걸리고 다음 단계를 시도하기 전에 많은 연구를 해야 한다는 점에 대한 여러분의 인내심과 이해에 감사드립니다. 의견이나 제안이 있으면 언제든지 남겨주시기 바랍니다. 코드를 모두 가지고 있으니 여러분도 테스트해보시고 이 흥미진진한 프로젝트에 더 추가할 수 있는 내용이 있는지 확인해보세요.
아래는 Markdown 형식으로 변경된 표입니다.
from dtaidistance import dtw
from itertools import combinations
import pickle
from joblib import Parallel, delayed
def plot_relative_performance(prices, start_date, end_date, benchmark='SPY'):
"""
주어진 날짜 범위에 대한 특정 벤치마크와 자산의 상대적 수익률을 그래프로 표시합니다.
매개변수:
- prices (DataFrame): 각 열이 자산 및 지정된 벤치마크를 나타내는 자산 가격을 포함한 DataFrame.
- start_date (str): 분석 시작 일자 (예: '2023-01-01').
- end_date (str): 분석 종료 일자 (예: '2023-12-31').
- benchmark (str): 비교할 벤치마크의 이름 (기본값은 'SPY').
반환:
- 없음: 이 함수는 그래프를 생성하여 표시합니다.
"""
# 지정된 벤치마크에 대한 상대적 수익률 계산
...
# 이하 모든 내용은 계속되도록 하겠습니다.
위의 코드를 번역해드렸습니다. 다른 질문이나 도움이 필요하시면 언제든지 말씀해주세요!