최신 기계 학습 연구 소식을 따라가기 어려우신가요? LLMs, 벡터 데이터베이스 또는 RAGs에 관한 논문 양에 압도당하셨나요?
백엔드 쪽에서는, 이 어시스턴트는 RAG(Retrieval Augmented Generation) 프레임워크로 구동될 것입니다. 이는 확장 가능한 서버리스 벡터 데이터베이스, VertexAI의 임베딩 모델, 그리고 OpenAI의 LLM을 활용합니다.
프론트엔드 쪽에서는 이 어시스턴트가 Streamlit으로 제작된 인터랙티브하고 쉽게 배포 가능한 웹 애플리케이션에 통합될 것입니다.
이 프로세스의 모든 단계는 아래에서 자세히 설명되며, 재사용하고 수정할 수 있는 동반되는 소스 코드가 함께 제공됩니다👇.
준비되셨나요? 함께 알아봐요 🔍.
독자 분들께서 독해를 시작하기 전에, 여기 Github에서 전체 소스 코드를 확인하실 수 있어요.
1 — Papers With Code로부터 데이터 수집
Papers With Code(일명 PWC)는 연구원과 실무자들을 위한 무료 웹사이트로, 최신의 최첨단 머신러닝 논문, 소스 코드, 데이터 세트를 찾고 따르는 곳이에요.
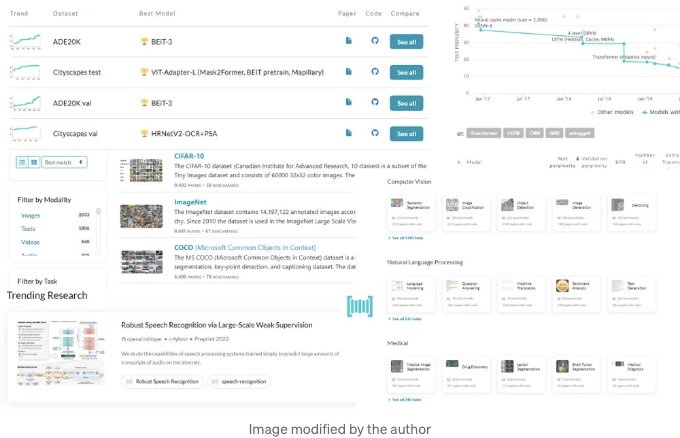
다행히도, PWC와 상호 작용하여 연구 논문을 프로그래밍 방식으로 검색할 수도 있습니다. 이 Swagger UI를 살펴보면 모든 사용 가능한 엔드포인트를 찾고 시도해 볼 수 있습니다.
예를 들어, 특정 키워드로 논문을 검색해 보겠습니다.
인터페이스에서 이렇게 할 수 있습니다: papers/ 엔드포인트를 찾아 쿼리( q ) 인자를 채웁니다.
표 태그를 Markdown 형식으로 바꾸세요.
그리고 실행 버튼을 클릭하세요.
동등하게, 이 동일한 검색을 수행하려면 다음 URL을 클릭하면 됩니다.
출력 응답은 결과의 첫 페이지만을 보여줍니다. 다음 페이지는 "next" 키에 접근하여 이용할 수 있습니다.
이 구조를 이용하면 "대형 언어 모델"에 일치하는 7200개의 논문을 검색할 수 있습니다. URL을 요청하는 함수를 이용하여 모든 페이지에 대해 루프를 돌림으로써 간단히 수행할 수 있습니다.
import requests
import urllib.parse
from tqdm import tqdm
def extract_papers(query: str):
query = urllib.parse.quote(query)
url = f"https://paperswithcode.com/api/v1/papers/?q={query}"
response = requests.get(url)
response = response.json()
count = response["count"]
results = []
results += response["results"]
num_pages = count // 50
for page in tqdm(range(2, num_pages)):
url = f"https://paperswithcode.com/api/v1/papers/?page={page}&q={query}"
response = requests.get(url)
response = response.json()
results += response["results"]
return results
query = "Large Language Models"
results = extract_papers(query)
print(len(results))
# 7200
결과를 추출하면 해당 결과를 기반이로 LangChain 문서로 변환하여 단순히 청크화하고 색인화합니다.
문서 객체에는 두 개의 매개변수가 있습니다:
- page_content (str): 논문 초록의 텍스트를 저장하는 매개변수
- metadata (dict): 추가 정보를 저장하는 매개변수. 우리의 사용 사례에서는 id, arxiv_id, url_pdf, 타이틀, 저자, 발표일을 유지할 것입니다
from langchain.docstore.document import Document
documents = [
Document(
page_content=result["abstract"],
metadata={
"id": result["id"] if result["id"] else "",
"arxiv_id": result["arxiv_id"] if result["arxiv_id"] else "",
"url_pdf": result["url_pdf"] if result["url_pdf"] else "",
"title": result["title"] if result["title"] else "",
"authors": result["authors"] if result["authors"] else "",
"published": result["published"] if result["published"] else "",
},
)
for result in results
]
문서를 임베드하기 전에 작은 조각들로 나눠야 합니다. 이렇게 하면 LLMs의 입력 토큰 관련 제한을 극복할 수 있고 각 조각마다 세부 정보를 제공할 수 있습니다.
우리는 길이가 1200 자이며 chunk_overlap가 200 인 Chunking을 통해 문서를 나누었더니 11,000개가 넘는 조각들이 생성되었습니다.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1200,
chunk_overlap=200,
separators=["."],
)
splits = text_splitter.split_documents(documents)
len(splits)
# 11308
2 — 업스태시에서 인덱스 생성하기
문서 임베딩(및 메타데이터)을 저장하기 위해서는 먼저 인덱스를 생성해야 합니다.
이 튜토리얼에서는 서버리스 데이터베이스인 업스태시를 사용할 것입니다.
인덱스를 생성하려면 여기에 로그인하고 몇 가지 매개변수를 입력하는 지침을 따르면 됩니다:
- 지역: 근처에 위치한 지역을 선택해주세요.
- 차원 = 768로 설정하세요(VertexAI의 임베딩 차원)
- 거리 메트릭 = 코사인으로 설정하세요.
인덱스를 만든 후에는 upstash-vector를 설치해야 합니다.
pip install upstash-vector
이를 통해 인덱스에 연결을 설정할 수 있습니다.
from upstash_vector import Index
index = Index(
url="<UPSTASH_URL>",
token="<UPSTASH_TOKEN>"
)
3 — Embed the chunks and index them into Upstash
To embed the chunks and index them into the vector db, we’ll create a simple class that imitates LangChain Vectorstore implementation.
This class will be named UpstashVectorStore and will have the following methods:
- Upstash Vector Store 클래스의 init 생성자는 Upstash Index와 Embeddings 객체를 예상합니다.
- 문서를 임베딩하고 일괄적으로 색인에 추가하려면 add_documents 를 사용합니다.
- similarity_search_with_score 를 사용하여 인덱스를 쿼리하고 상위 k개의 가장 관련성 높은 문서 및 해당 점수를 검색합니다.
다음은 전체 구현입니다:
from typing import List, Optional, Tuple, Union
from uuid import uuid4
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from tqdm import tqdm
from upstash_vector import Index
class UpstashVectorStore:
def __init__(self, index: Index, embeddings: Embeddings):
self.index = index
self.embeddings = embeddings
def delete_vectors(
self,
ids: Union[str, List[str]] = None,
delete_all: bool = None,
):
if delete_all:
self.index.reset()
else:
self.index.delete(ids)
def add_documents(
self,
documents: List[Document],
ids: Optional[List[str]] = None,
batch_size: int = 32,
):
texts = []
metadatas = []
all_ids = []
for document in tqdm(documents):
text = document.page_content
metadata = document.metadata
metadata = {"context": text, **metadata}
texts.append(text)
metadatas.append(metadata)
if len(texts) >= batch_size:
ids = [str(uuid4()) for _ in range(len(texts))]
all_ids += ids
embeddings = self.embeddings.embed_documents(texts, batch_size=250)
self.index.upsert(
vectors=zip(ids, embeddings, metadatas),
)
texts = []
metadatas = []
if len(texts) > 0:
ids = [str(uuid4()) for _ in range(len(texts))]
all_ids += ids
embeddings = self.embeddings.embed_documents(texts)
self.index.upsert(
vectors=zip(ids, embeddings, metadatas),
)
n = len(all_ids)
print(f"Successfully indexed {n} dense vectors to Upstash.")
print(self.index.stats())
return all_ids
def similarity_search_with_score(
self,
query: str,
k: int = 4,
) -> List[Tuple[Document, float]]:
query_embedding = self.embeddings.embed_query(query)
query_results = self.index.query(
query_embedding,
top_k=k,
include_metadata=True,
)
output = []
for query_result in query_results:
score = query_result.score
metadata = query_result.metadata
context = metadata.pop("context")
doc = Document(
page_content=context,
metadata=metadata,
)
output.append((doc, score))
return output
이 클래스를 사용하여 청크를 색인화해 봅시다:
from langchain.embeddings import VertexAIEmbeddings
from upstash_vector import Index
index = Index(
url="<UPSTASH_URL>",
token="<UPSTASH_TOKEN>",
)
embeddings = VertexAIEmbeddings(model_name="textembedding-gecko@003")
upstash_vector_store = UpstashVectorStore(index, embeddings)
ids = upstash_vector_store.add_documents(splits, batch_size=25)
이 과정은 분할 수, 연결 속도 및 선택한 배치 크기에 따라 시간이 걸릴 수 있습니다.
색인 프로세스가 완료되면 UI에서 벡터 및 해당 메타데이터를 확인할 수 있습니다: 이는 레코드의 빠른 검사와 쉬운 관리(예: 삭제)에 도움이 됩니다.
4 — 색인 된 논문에 대한 질문하기
추상이 올바르게 Upstash에 색인된 상태로, 이제 자연어로 상호작용하며 ML 주제에 대한 구체적인 질문을 할 수 있습니다.
이게 생각보다 훨씬 쉽습니다.
이를 위해 먼저, 질문을 받아 관련 문서를 벡터 저장소에서 검색하고 이를 사용하여 프롬프트를 작성하는 함수를 정의합시다.
def get_context(query, vector_store):
results = vector_store.similarity_search_with_score(query)
context = ""
for doc, score in results:
context += doc.page_content + "\n===\n"
return context
def get_prompt(question, context):
template = """
주어진 문맥을 사용하여 질문에 답하는 것이 여러분의 작업입니다.
문맥 외의 것을 꾸며내지 마세요.
적어도 350자 이상으로 대답해 주세요.
%CONTEXT%
{context}
%Question%
{question}
Hint: 문맥을 그대로 복사하지 마세요. 여러분만의 말로 표현해 주세요.
대답:
"""
prompt = template.format(question=question, context=context)
return prompt
영감이 떨어질 때가 있죠? 시작하는 데 도움이 될 질문이에요:
query = (
"Retrieval Augmented Generation (RAG) 프레임워크 뒤의 문제는 무엇인가요?"
)
context = get_context(query, upstash_vector_store)
prompt = get_prompt(query, context)
다음은 문맥을 받은 후의 프롬프트 모습입니다:
주어진 문맥을 활용해 질문에 답해 보는 것이 당신의 과제입니다.
문맥 밖의 것은 광장을 만들지 마세요.
적어도 350자 이상으로 답하세요.
%CONTEXT%
Retrieval-Augmented Generation (RAG)은 대규모 언어 모델의 환각을 완화하기 위한
유망한 접근 방식입니다. 그러나 기존 연구는 서로 다른 대규모 언어 모델에 대한
검색 증강 생성의 영향에 대한 철저한 평가가 부족하여, 서로 다른 대규모 언어 모델에
대한 RAG의 능력에 대한 잠재적 병목 현상을 식별하는 것이 어려운 상황입니다.
우리는 이 논문에서 Retrieval-Augmented Generation이 대규모 언어 모델에 미치는 영향을
체계적으로 조사합니다. RAG가 요구하는 4가지 기본 능력인 노이즈 강건성, 부정 거부,
정보 통합 및 반사적 강건성에 대한 다양한 대규모 언어 모델의 성능을 분석합니다.
이를 위해 RAG 평가를 위한 새로운 말뭉치인 Retrieval-Augmented Generation
Benchmark (RGB)를 설정합니다. 이 RGB는 영어와 중국어 모두에서 RAG 평가에 사용되는
새로운 말뭉치로, 해당 말뭉치 내의 인스턴스를 의미 있는 능력에 따라 4개의 별도의
테스트베드로 분류합니다. 그런 다음 RGB에서 6개의 대표적인 대규모 언어 모델을
평가하여 RAG를 적용할 때 현재 대규모 언어 모델의 도전에 대해 진단합니다.
===
대단한 능력을 갖고 있지만 대규모 언어 모델(LM)은 종적으로 알려진 정보에만 의존하여
사실적인 정확성을 가지지 않는 응답을 종종 생성합니다. Retrieval-Augmented Generation
(RAG)은 LM을 관련 지식 검색으로 보완하는 무작위 접근법으로 이러한 문제를 줄입니다.
그러나 검색이 필요한지, 또는 지식이 관련성이 있는지 여부에 상관없이 일정 수의 검색
내용을 무작위로 가져와 포함한다면, LM의 다양성이 감소하거나 도움이 되지 않는
응답 생성으로 이어질 수 있습니다. 우리는 Self-Reflective Retrieval-Augmented
Generation(Self-RAG)이라는 새로운 프레임워크를 소개합니다. 이 프레임워크는 검색 및
자기 반성을 통해 LM의 품질과 정확성을 향상시킵니다. 우리의 프레임워크는 필요 시
검색 결과를 가져와 동적으로 변화시키며, 특수 토큰인 반성 토큰을 사용하여 검색 결과와
LM의 생성물을 생성하고 반성합니다. 반성 토큰을 생성하면 LM이 추론 단계에서 조절 가능해져
다양한 작업 요구에 맞게 동작할 수 있습니다.
...
이제 LLM에게 대답 생성을 요청해보세요.
from langchain.chat_models import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_deployment="<AZURE_DEPLOYMENT>",
model="<MODEL_NAME>",
)
answer = llm.predict(prompt)
왔쪄요! 🥁
검색 증강 생성 (RAG) 프레임워크는 핍을 피할 수 없는 검색 및 필요하지 않거나 관련성 없는 단락을 포함하여 도움이 되지 않는 응답 생성으로 이어질 수 있는 문제와 같은 문제가 있을 수 있습니다. 또한, 기존 연구는 RAG가 다양한 대형 언어 모델 (LLM)에 미치는 영향을 철저히 평가하지 않아 RAG의 다양한 LLM에 대한 기능 병목 현상을 식별하기 어렵게 만들고 있습니다. 이러한 문제를 해결하기 위해, 연구자들은 자기 반성 검색 증강 생성(Self-RAG) 프레임워크를 제안했으며, 이 프레임워크는 검색 및 자기 반성을 통해 LM의 품질과 사실성을 향상시킵니다. LLM의 다른 문제점 중 하나는 그들의 잊기죽임입니다. 그들은 시간이 흐를수록 개선되지 않거나 인간처럼 새로운 지식을 습득하지 않습니다. 이를 해결하기 위해, 연구자들은 RAG를 사용하여 문제 해결 성능을 향상시키는 방법을 탐구하고, ARM-RAG 시스템을 제안했습니다. 이 시스템은 높은 훈련 비용이 필요 없이 성공을 통해 학습합니다.
꽤 괜찮지 않아요?
이 다이어그램으로 전체 워크플로우를 요약해 볼게요.
5— Streamlit 애플리케이션에 통합하기
UI에서 RAG와 상호 작용하기 위해 Streamlit 애플리케이션에 통합할 수 있어요.
다음은 Markdown 형식으로 변환한 것입니다:
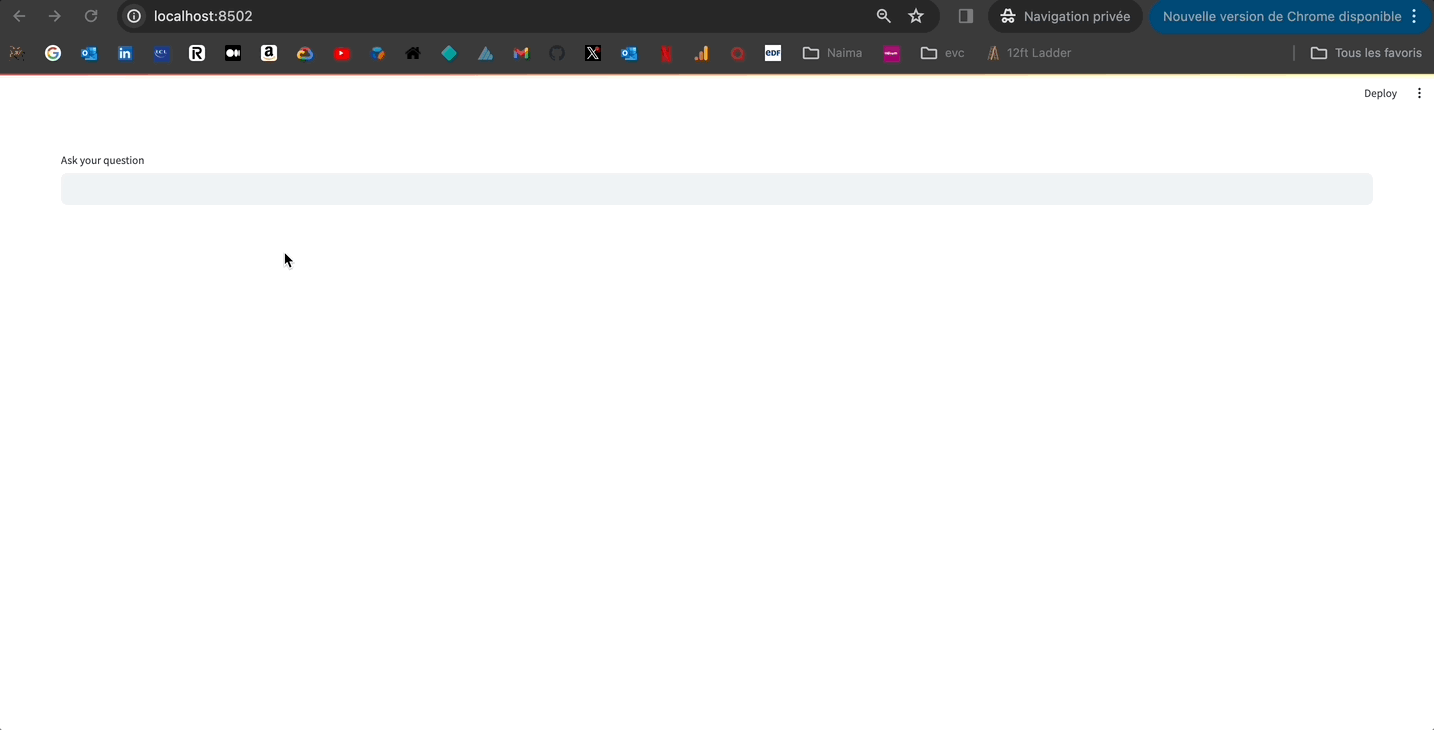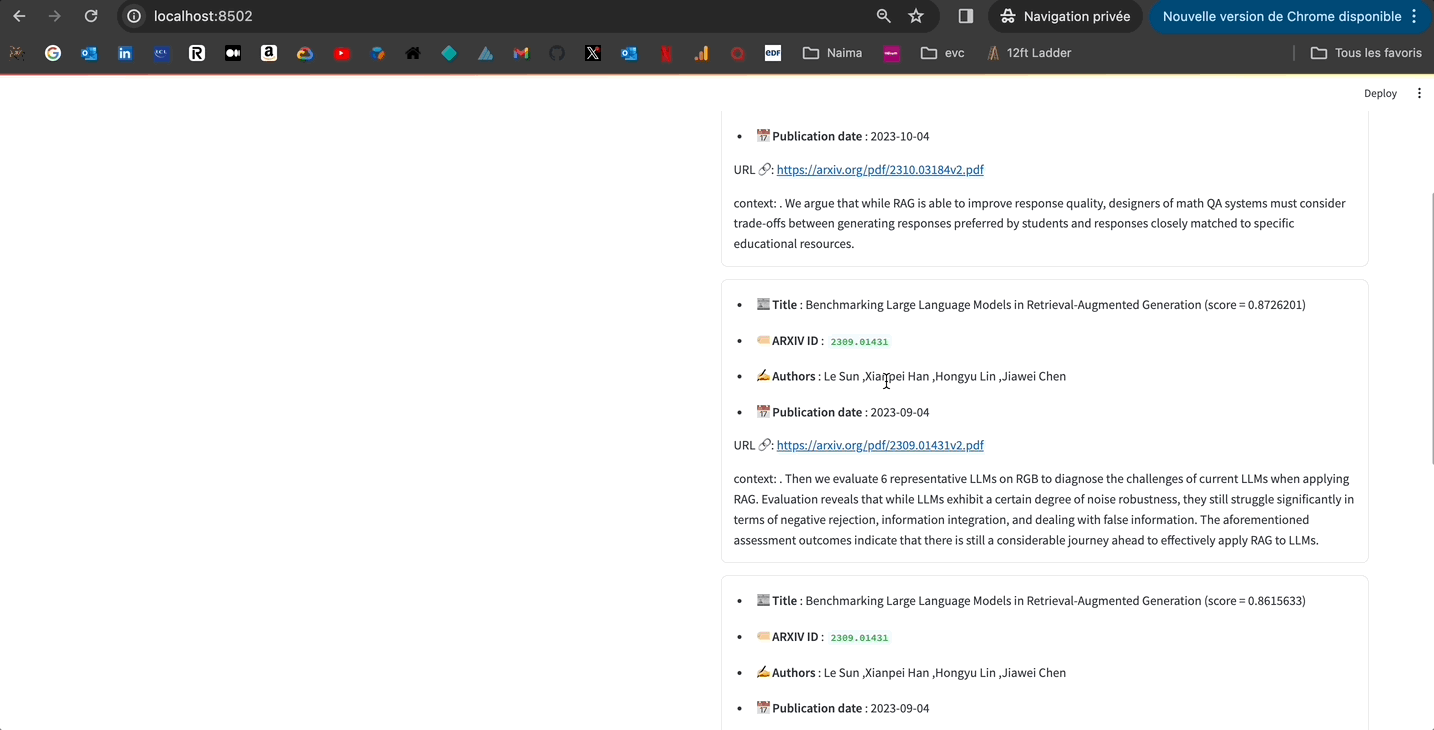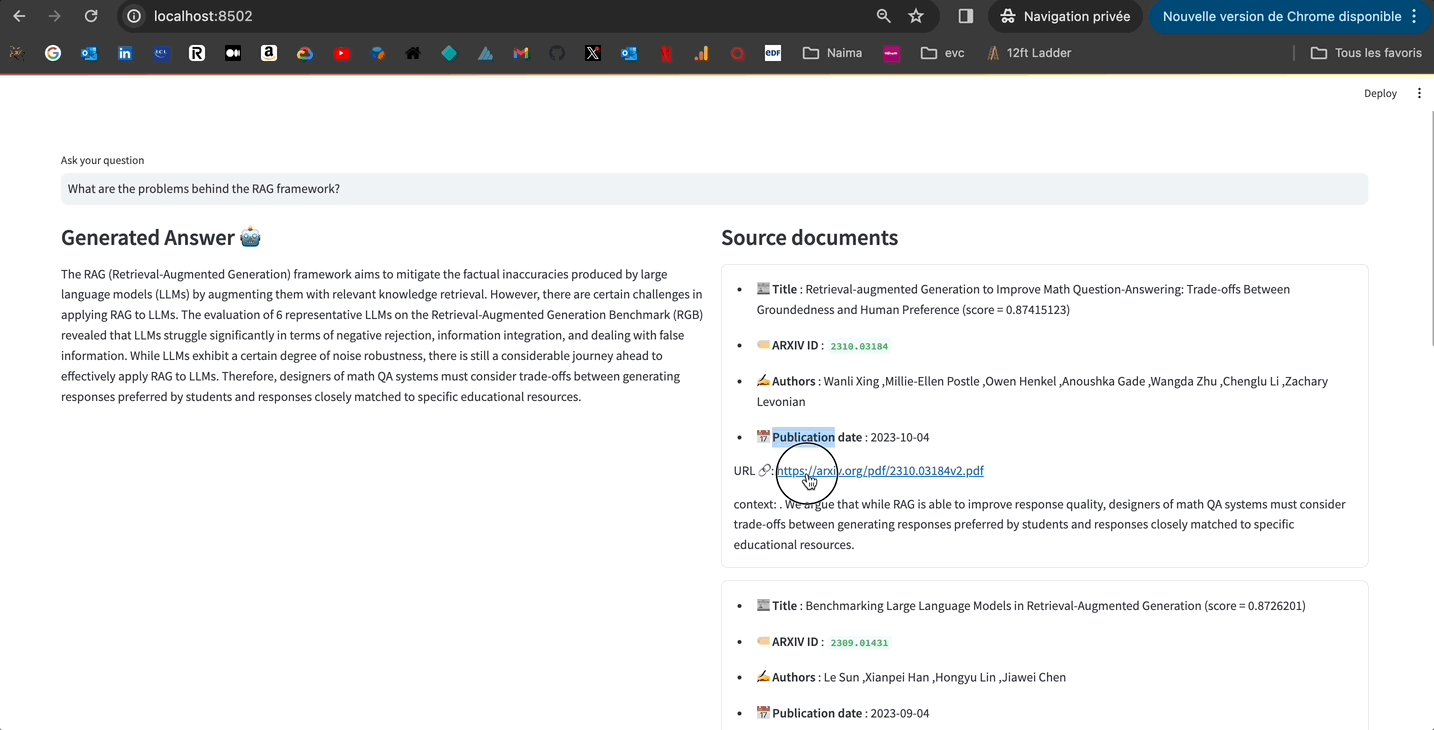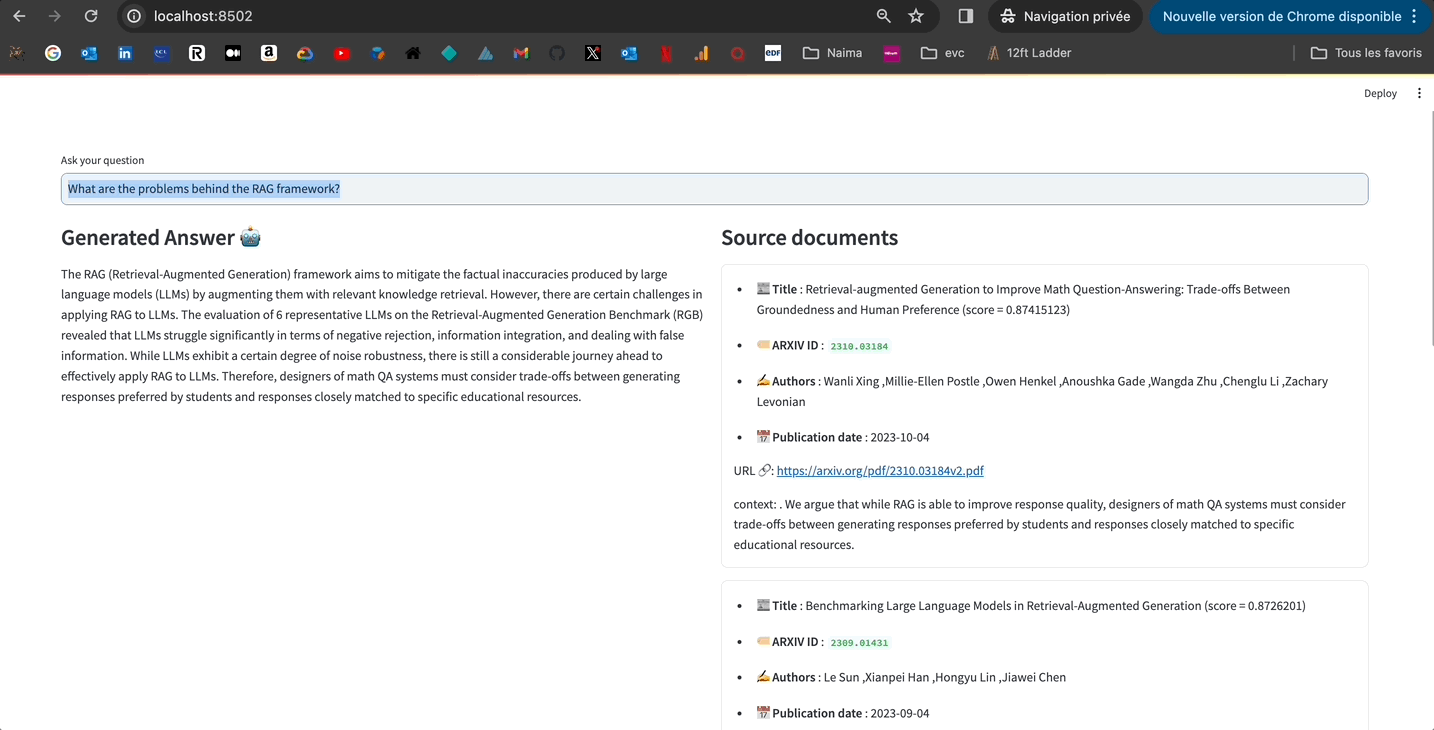
혹시 앱을 로컬에서 시도해보고 코드를 만져보고 싶으시면 언제든지 환영합니다.
몇 가지 핵심 포인트
많은 분들이 이미 자료와 대화하는 RAGs를 구축하셨습니다.
제가 실제로 그러한 프로젝트의 실용성에 대해 솔직한 피드백을 드리겠습니다. 제 목표는 여러분이 RAGs를 만들지 않도록 방해하는 것이 아니라 이러한 솔루션에 대한 과대광고를 완화시키기 위해 세심한 의견을 제공하는 것입니다.
우선 이점에서 시작해보겠습니다:
- RAGs를 통해 외부 자료에 접근할 수 있습니다. 예를 들어, 저희가 개발한 앱은 Mistral이나 LLama2와 같은 최근 오픈 소스 LLM에 대한 정확한 답변을 제공합니다. ChatGPT에 이러한 모델에 대해 질문을 하면 얻을 수 있는 것들을 확인해보세요.

- RAG를 사용하면 생성된 응답을 지탱하는 소스 문서를 인용할 수 있습니다. 이는 사용자 신뢰를 높이고 디버깅 및 해석 가능성에 도움을 줍니다.
- RAG는 답변을 지탱하기 위해 외부 데이터만 활용하므로 LLM의 환형 경향을 제한합니다.
- RAG는 상대적으로 쉽게 구축할 수 있습니다. 모델을 훈련하거나 세부 조정할 필요가 없기 때문에 비싼 컴퓨팅 자원이 필요하지 않습니다.
그러나 RAG는 마법같이 즉시 해결되는 해결책은 아닙니다. "기업" 세계에서 이를 산업화하려면 고려해야 할 중요한 측면이 있습니다.
- 그들의 영향력은 제공된 데이터에 따라 달라집니다. 예시 앱에서 우리는 논문 초록만 사용했습니다. 이는 일반적인 질문에 답변하는 데 좋은 시작점을 제공하지만 쿼리가 너무 복잡하고 전체 텍스트에 액세스가 필요한 경우에는 도움이 되지 않습니다.
- 외부 구현된 RAG는 잘 작동하는 경우가 드뭅니다. 데모 목적으로는 좋지만 답변을 심층적으로 조사하기 시작하면 품질이 실망스러움을 빨리 깨닫게 됩니다. 그래서 철저한 조정, 평가 지표 및 인간의 개입이 필요합니다.
- RAG는 모든 것에 대한 해결책이 아닙니다. 스타일 복사와 같은 일부 응용 프로그램은 모델 세부 조정으로 수행하는 것이 더 나은 결과를 보입니다.
- RAG는 LLM의 컨텍스트 크기에 의해 제한됩니다. LLM의 컨텍스트 크기가 1백만 토큰이 되더라도 해당 데이터 양으로 프롬프트하는 것이 좋은 아이디어는 아닙니다.
결론
지금까지 읽어주셔서 감사합니다.
만약 이 어시스턴트를 향상시키고 다음 단계로 나아가길 원한다면, 아래 아이디어를 탐색하거나 구현해 보세요.
- 요약이 아닌 전체 텍스트 사용
- 메타데이터 필터링과 벡터 검색 보완
- 밀도 검색이 아닌 하이브리드 검색 시도하기: 키워드 검색이 의왜 검색을 놀랍게 향상시킵니다.
- 검색 후 문서 재랭크: 이를 통해 보다 많은 문서를 검색하고 중요한 것들을 자세히 살펴볼 수 있습니다.
- 사용자 쿼리 확장
- 임베딩 세밀 조정
이전에 작성한 개선된 검색 기술에 관한 글이에요.
여기 👇에서 확인해보세요.
읽어 주셔서 감사합니다 📖.