제가 항상 궁금해했던 것 중 하나는 제안 시스템이에요. 검색 엔진을 열고 검색어를 입력하면 갑자기 여러 가지 완성 제안이 나온다니까요!
그것을 보면서 저는 자주 생각해봤어요: 이걸 어떻게 만들었을까? 나도 같은 것을 할 수 있을까? 필요한 기술과 자원은 무엇일까요? 이런 생각이 들었죠...
처음에는 그에 대해 큰 언어 모델이 필요할 것이라고 생각했는데요... 근데 알고 보니 전혀 그렇지 않았어요!
저는 개인 문서용 챗봇을 만들고 싶어요. 그 챗봇은 문서에 대해 몇 가지 질문을 "제안"할 수 있는 거죠. 새 문서인지 구식 문서인지를 미리 알 필요가 없어요. 함께 LLM(언어 모델 학습)을 사용하여 문서에서 질문을 생성하는 방법에 대해 알아봐요. 이 모든 것은 Hugging Face의 LLM과 파이썬을 사용하며(무료 Google Colab 노트북에서 실행) 오픈 소스 도구만 사용해서 이룰 수 있어요.
ESA: 탐사 능력 분석
목표를 달성하기 위해 필요한 노하우를 얻기 위한 여정을 시작했습니다. 항상 선생님으로서 (더 이상 학교에서 가르치지는 않지만...) 질문에 집중했습니다. 만약 AI가 텍스트나 문서에 대해 질문을 하는 경우는 어떨까요? AI에게 문서를 제공한 다음에 그 문서에 대해 무슨 질문을 할 수 있는지 제안을 요청하는 것처럼 말이죠! 마치 우리가 게임 규칙을 뒤바꾸는 것 같은 느낌입니다!
첫 번째 단계는 어떻게 질문을 생성하는지, 필요한 어떤 리소스가 있는지... 기본적으로 배워야 할 어떤 기술이 있는지를 이해하는 것입니다.
오픈 소스 접근 방식을 원하므로 Hugging Face Hub에서 해당 작업에 전용 모델이 있는지 검색을 시작했습니다. 발견한 것은 기대 이상이었습니다.
허깅 페이스에서는 질문 생성을 위한 모델이 여러 개 있어요! 그 중에 valhalla/t5-small-e2e-qg를 선택하기로 결정했어요. Patil Suraj의 GitHub 레포지토리에서는 이 NLP 작업에 대한 연구를 탐구하고 있어요.
허깅 페이스에서 모델 카드를 찾을 수 있어요.
질문 생성은 텍스트 단락에서 질문을 자동으로 생성하는 작업입니다. 최근 논문들 중에는 UniLM과 ProphetNet이 QG에 대한 SOTA 사전 훈련 가중치를 제공하고 있지만 사용법이 다소 복잡해 보여요.
이 프로젝트는 사전 훈련된 트랜스포머(특히 seq-2-seq 모델)를 사용하여 복잡한 파이프라인 없이 간단한 엔드 투 엔드 방법으로 질문 생성에 대한 오픈 소스 연구를 목표로 하고 있어요. 간소화된 데이터 처리 및 훈련 스크립트를 제공하고 추론을 위한 쉬운 파이프라인을 구축하는 것이 목표입니다.
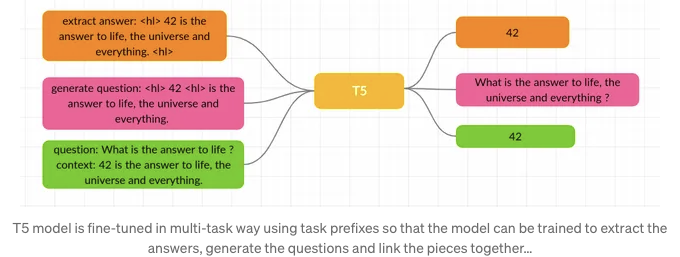
그리고 실제로 그렇습니다! 초기 훈련에서는 이 작업을 수행하기 위해 3가지 다른 모델이 필요했지만 논문 'Transformer-based End-to-End Question Generation'에서 제안된 방법을 사용할 것입니다.
이것은 End-to-End 질문 생성(답변에 중립적)입니다. 여기서 모델은 답변을 제공하지 않고도 질문을 생성하도록 요청됩니다. 우리는 T5 패밀리 모델을 사용할 것이기 때문에 가능합니다. T5 모델(Text-to-Text Transfer Transformer의 약자)은 여러 NLP 작업을 수행할 수 있기 때문에 놀라운 모델입니다:
번역, 질문 응답 및 분류를 포함한 모든 작업은 입력으로 모델 텍스트를 공급하고 어떤 대상 텍스트를 생성하도록 훈련시키는 것으로 표현됩니다. 이를 통해 우리는 다양한 작업 세트에 걸쳐 동일한 모델, 손실 함수, 하이퍼파라미터 등을 사용할 수 있습니다.
알겠어요, 이제 소개는 여기까지하고 코딩하면서 더 많은 내용을 추가해봐요.
어떤 단계가 있을까요…
이 여정은 생각보다 쉽습니다: 함께 코딩하거나 GitHub 레포지토리에서 단계를 따라하기도 가능해요. 거기에서 Colab 노트북 파일을 찾을 수 있어요.
필요한 라이브러리 모두 설치하기
모델 가중치 다운로드하기 (torch 버전)
질문 생성 추론 테스트하기
문서에서 질문 생성하기 (지금은 텍스트 파일로)
보시다시피, 여기서 Document Loaders나 Langchain을 너무 깊게 파고들지 않을 거에요. 목표는 텍스트에서 질문을 생성할 수 있는 AI를 갖는 것입니다.
필요한 모든 라이브러리 설치하기
Google Colab 노트북을 열고 이름을 지어주세요. 이 프로젝트에 특별한 런타임이 필요하지 않아요: 기본 런타임이 충분합니다.
%%capture
!pip install transformers
!pip install nltk
!pip install sentencepiece
!pip install langchain
%%capture 매직은 Jupyter 기반 인터페이스에서 명령의 출력을 숨기는 기능을 제공합니다. 이 경우에는 verbose 콘솔 출력 없이 pip를 사용하여 모든 종속성을 설치할 것입니다.
- nltk는 질문 생성을 위한 특수 end-to-end 파이프라인에 사용되는 기본 라이브러리입니다.
- sentencepiece는 Neural Network 기반 텍스트 생성 시 사전에 어휘 크기가 미리 결정된 비지도 학습 텍스트 토크나이저 및 디토크나이저입니다. (SentencePiece를 사용하면 언어별 전/후 처리에 의존하지 않는 순수한 end-to-end 시스템을 구축할 수 있습니다)
- transformers는 Hugging Face 모델과 상호 작용해야 할 때 필요합니다.
- langchain은 외부 자원과의 상호 작용 및 LLMs와 연결하는 놀라운 기능을 갖춘 도구 상자입니다. 우리는 여기서 텍스트 분리 도구로만 사용할 것입니다.
- pytorch는 모델 가중치를 로드하고 읽을 수 있는 라이브러리입니다. Google Colab 무료 티어에는 이미 Pytorch가 설치되어 있으므로 목록에서 볼 수 없습니다.
torch를 사용하여 Hugging Face에서 .bin 파일 형식 모델을 읽는 핵심 라이브러리가 있습니다: 이제 이론적으로 torch 형식으로 저장된 Hugging Face 모델 중 아무 모델이나 다운로드하고 사용할 수 있습니다. (텐서 플로우가 아닌)...
마지막 단계는 질문 생성 전용 파이프라인을 다운로드하는 것입니다. 이는 Patil Suraj Repo에서 가져온 파이썬 파일인 pipelines.py입니다.
%%capture
!wget https://github.com/patil-suraj/question_generation/raw/master/pipelines.py

질문 생성 추론 테스트
시작해 볼까요?
의존성이 모두 준비되었으면, 파이프라인을 처음으로 생성할 때 모델을 다운로드합니다 (Colab이 대신 처리해 줄 거에요). 이제 몇 가지 질문 생성 추론을 해볼 수 있습니다.
from pipelines import pipeline
repo = 'valhalla/t5-small-e2e-qg'
nlp = pipeline("e2e-qg", model=repo, tokenizer=repo)
ques = nlp("Python is a programming language. Created by Guido van Rossum and first released in 1991.")
print(ques)
print("---")
text2 = "이미지 형성 과정을 잡음 제거 오토인코더의 순차 적용으로 분해하여 확산 모델(DMs)은 이미지 데이터 및 그 이상의 합성 결과에서 최고 수준의 성과를 달성합니다. 또한, 이들의 정의는 이미지 생성 과정을 다시 훈련하지 않고 제어할 수 있는 안내 메커니즘을 제공합니다. 그러나 이 모델들은 일반적으로 픽셀 공간에서 직접 작동하기 때문에 강력한 DM의 최적화는 종종 수백 개의 GPU 일을 소모하고 순차적 평가로 인해 추론 비용이 많이든다. 계산 리소스가 제한된 상황에서 강력한 DM의 훈련을 가능하게 하면서도 그들의 품질과 유연성을 유지하기 위해 우리는 강력한 미리 훈련된 오토인코더의 잠재 공간에서 그들을 적용합니다. 이러한 표현에 대한 확산 모델의 훈련은 복잡성 축소와 세부 정보 보존 사이의 거의 최적점에 처음으로 도달할 수 있도록 하며, 시각적 충실성을 크게 향상시키게 됩니다. 모델 아키텍처에 교차 어텐션 레이어를 도입함으로써, 우리는 확산 모델을 텍스트나 바운딩 박스와 같은 일반 조건 입력에 대한 강력하고 유연한 생성기로 변형시킵니다. 우리의 잠재 확산 모델(LDM)은 이미지 인페인팅에서 최적점에 도달하고, 무조건 이미지 생성, 시맨틱 씬 합성 및 초해상도를 포함한 다양한 작업에서 매우 경쟁력 있는 성과를 나타내며, 픽셀 기반 DM에 비해 계산 요구 사항을 크게 줄입니다."
ques2 = nlp(text2)
print(ques2)
print("---")
볼 수 있듯이, Pipelines (Patil Suraj의 GiHub Repo에서 생성된 pipelines.py 파일에서 가져온)만 가져오고 있습니다. 이미 모든 필요한 종속성을 로드해 주는 python 파일이기 때문에 이것은 괜찮습니다. 여기에는 정보 전용 추출이 있어요...
import itertools
import logging
from typing import Optional, Dict, Union
from nltk import sent_tokenize
import torch
from transformers import(
AutoModelForSeq2SeqLM,
AutoTokenizer,
PreTrainedModel,
PreTrainedTokenizer,
)
수입 후에는 몇 가지 매개변수를 지정하여 nlp 파이프라인을 생성합니다:
- 파이프라인 유형: "e2e-qg"는 훈련된 T5 모델의 능력을 활용하여 답변 없이 질문을 추출할 엔드투엔드 파이프라인입니다.
- 모델: 로컬로 다운로드한 모델을 사용할 것이므로 필수입니다.
- 토크나이저: 로컬로 다운로드한 모델을 사용할 것이므로 필수입니다.
이제 nlp 파이프라인을 호출할 때마다 텍스트를 인수로 전달하기만 하면 됩니다. 모델이 결과로 질문을 생성합니다. 생성된 질문이 모두 포함된 리스트가 출력됩니다.
예제 번호 1
ques = nlp("파이썬은 프로그래밍 언어입니다. 1991년에 Guido van Rossum에 의해 처음 출시되었습니다.")
print(ques)
이 예제는 모델 카드에서 가져온 것입니다. 결과는 python list로 출력됩니다
['프로그래밍 언어란 무엇인가요?', '파이썬을 만든 사람은 누구인가요?', '파이썬이 처음 출시된 날짜는 언제인가요?']
예제 번호 2
제가 귀하의 요청에 따라 테이블 태그를 Markdown 형식으로 변경하겠습니다.
| 문제 | 답변 |
|---|---|
| 어떤 것을 확산 모델이 수행하나요? | 이미지 형성 과정을 노이즈 제거 오토인코더의 순차적 적용으로 분해하여 상태가 좋은 합성 결과를 달성합니다. |
| 어떤 것이 이미지 생성 과정을 재교육 없이 제어하기위한 가이드 메커니즘인가요? | 그들의 공식은 이미지 생성 과정을 다시 훈련하지 않고 제어 할 수 있습니다. |
| 강력한 DM의 최적화는 전혀 몇 일이 걸리나요? | 강력한 DM의 최적화는 보통 GPU 수백 일을 소비하며 시퀀셜 평가로 인해 추론 비용이 높습니다. |
이렇게 해서 테이블을 마크다운 형식으로 변환하였습니다.
여러분 안녕하세요! 오랜 텍스트 파일이나 역사 교과서의 한 장을 처리해야 한다면 어떻게 해야 할까요? 혹은 거대한 논문을 다뤄야 한다면요?
너무 복잡하게 생각하지 말고 함께 알아보겠습니다.

문서(지금은 텍스트 파일)로부터 질문 생성하기
텍스트 파일(텍스트만 포함됨)을 사용할 거에요. 이 텍스트 파일은 Medium 기사인 'BERT: 초심자 친화적 설명'에서 Pushpam Punjabi가 쓴 것을 가져왔어요. 문장의 의미가 중요한 기술 기사라서 좋은 테스트 케이스예요.
!wget https://github.com/fabiomatricardi/Abstractive-Extractive/raw/main/BERTexplanation.txt
그러니까 이제 파일을 다운로드 받고 (내 저장소에서) 이를 doc 변수에 문자열로 로드해보죠.
fname = '/content/BERTexplanation.txt'
with open(fname) as f:
doc = f.read()
f.close()
기사는 약 1800 단어로, 문자 수로는 11032자입니다.
텍스트를 청크로 나누기 위해 LangChain의 RecursiveCharacterTextSplitter를 사용할 것입니다. 각 모델이 가지는 토큰의 최대 수를 초과하지 않도록하기 위함입니다.
텍스트를 나누는 작업을 수행하는 함수를 만들어보겠습니다. 이 함수는 나눌 텍스트, 청크 길이(문자 수), 그리고 오버랩(맥락을 유지하기 위해 필요)을 인자로 받습니다.
def mysplit(text,chunk,overlap):
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# 매우 작은 청크 크기를 설정하여 예시를 보여줍니다.
chunk_size = chunk,
chunk_overlap = overlap,
length_function = len,
)
texts = text_splitter.split_text(text)
return texts
나머지 부분은 쉬워요! 우리는 텍스트에 함수를 호출하고 각 청크마다 질문을 표시하기 위해 목록을 반복합니다. 여기서는 6000자를 사용하고 150개의 오버랩이 있는 함수를 사용하고 있어요.
# 텍스트에 함수를 호출합니다
texts = mysplit(doc,6000,150)
# 각 청크의 질문을 표시하도록 목록을 반복합니다
for test in texts:
print("---")
questions = nlp(test)
for i in questions:
print('- '+i)
셀을 실행하면 다음과 같은 결과를 얻을 수 있어요.
---
- 푸샴 푸잔브이 저자의 책 이름은 무엇인가요?
- NLP의 주요 구성 요소는 무엇인가요?
- 기계는 어떻게 인간 언어를 이해하나요?
- BERT BERT을 이해한 사람은 누구인가요?
---
- 다양한 NLP 작업에 유용한 기술은 무엇인가요?
- BERT는 텍스트 단락의 전반적인 의미와 맥락을 어떻게 더 잘 이해할 수 있나요?
- 챗봇이나 가상 보조 프로그램과 같은 애플리케이션에서는 인간 언어를 이해하고 해석하는 능력이 정확하고 유용한 응답을 제공하는 데 중요합니다.
결론 (지금까지)
일부 질문들이 정말 간결하지 않다는 것을 알 수 있어요. 또한 제목(BERT)이 있으면 "누가 이해하기 쉬운 BERT BERT를 개발했는가?"와 같이 제대로 인식되지 않을 수 있어요.
질문 수를 늘릴 수 있어요. (예를 들어 다음과 같은 방식으로 분할 수를 증가시킬 수 있어요.
texts = mysplit(doc,3700,50)
다음으로 시도해볼 수 있는 몇 가지 단계가 있습니다:
- 첫 번째는 질문을 짝지어 다른 모델을 사용하여 답변을 생성하는 것입니다.
- 또 하나는 답변의 품질을 자동으로 검증하는 방법을 찾는 것입니다. 학생들이 온라인 양식으로 질문에 답변하는 경우, 답변의 품질을 평가하기 위해 우리의 AI를 사용할 수 있습니다.
제 GitHub Repo에서 코드와 Google Colab 노트북을 찾을 수 있습니다: [GitHub Repo 링크]
이 기사를 즐겁게 읽어주셨기를 바랍니다. 이 이야기가 가치를 제공하고 조금이라도 지원하고 싶다면, 어떤 지원이든 환영합니다.
- 이 이야기를 많이 박수 치세요
- 기억하기에 더 관련성이 높은 부분을 강조하세요 (나중에 찾기 쉽고 좀 더 나은 기사를 작성하는 데 도움이 될 거예요)
- 나만의 AI 구축 방법을 배우세요. 무료 eBook 다운로드하러 가기
- 제 링크를 사용하여 Medium 회원가입하기 ($5/월로 무제한 Medium 이야기 읽기)
- Medium에서 저를 팔로우하세요
- 제 최신 기사 읽기 https://medium.com/@fabio.matricardi
더 많은 정보를 원한다면 이곳에서 작은 로컬 모델을 사용한 몇 가지 아이디어가 있어요:

이 이야기는 Generative AI에서 게시되었습니다. LinkedIn에서 우리와 연락하고 최신 AI 이야기에 대한 소식을 받으려면 Zeniteq를 팔로우하세요. 함께 AI의 미래를 만들어 갑시다!
