데이터 시각화는 탐색적 데이터 분석의 중요한 부분이에요. 데이터를 분석하고 시각화함으로써 데이터의 분포, 변수 간의 관계, 그리고 이상값을 파악하는데 도움이 되죠.

파이썬에는 시각화를 빠르고 효율적으로 만들 수 있는 다양한 라이브러리가 있어요. 파이썬을 사용하여 탐색적 데이터 분석 시 흔히 사용되는 시각화 유형은 다음과 같아요:
- 막대 그래프: 다른 범주 간의 비교를 보여줄 때 사용돼요.
- 선 그래프: 시간이나 다른 범주에 따른 추이를 보여줄 때 사용돼요.
- 파이 차트: 각 범주의 비율이나 백분율을 보여줄 때 사용돼요.
- 히스토그램: 단일 변수의 분포를 보여줄 때 사용돼요.
- 히트맵: 서로 다른 변수 간의 상관 관계를 보여줄 때 사용돼요.
- 산점도: 두 연속 변수 사이의 관계를 보여줄 때 사용돼요.
- 상자 그림: 변수의 분포를 보여주고 이상값을 식별할 때 사용돼요.
Python을 사용한 데이터 시각화 작성 단계
- 비즈니스 문제 이해: 첫 번째 단계로, 올바른 시각화를 얻을 수 있도록 집중할 수 있습니다.
- 필요한 라이브러리 가져오기: Pandas, Seaborn, Matplotlib, Plotly와 같은 필수 라이브러리를 가져옵니다.
- 데이터셋 로드: 시각화하려는 데이터셋을 불러옵니다.
- 데이터 정제 및 전처리: 결측치, 중복 및 이상치를 제거하고 범주형 데이터를 수치 데이터로 변환하여 데이터를 정제하고 전처리합니다.
- 통계 요약: 평균, 중위수, 최빈값, 표준 편차 및 상관 계수와 같은 기술 통계를 계산하여 변수 간의 관계를 이해합니다.
- 데이터 시각화 및 해석: 데이터의 분포, 관계 및 패턴을 이해하기 위해 시각화를 생성합니다. 이후 시각화를 해석하여 데이터에 대한 깨달음을 얻고 결론을 도출합니다.
1. 비즈니스 문제 이해
심혈관 질환은 전 세계적으로 주요 사망 원인입니다. 세계 보건 기구(WHO)에 따르면, 매년 약 1,790만 명이 심장 질환으로 사망합니다. 이들 사망의 85%는 심근경색 및 뇌졸중으로 인한 것입니다.
이 기사에서는 Kaggle의 Heart Attack 데이터셋을 탐색하고 Python을 사용하여 EDA를 위한 데이터 시각화를 만들어볼 것입니다.
해당 데이터셋에는 환자들의 연령, 성별, 혈압, 콜레스테롤 수준 등과 같은 다양한 변수에 대한 데이터가 포함되어 있습니다. 이 데이터셋의 목표는 환자의 의료 속성에 기반하여 해당 환자가 심근 경색 발병 위험에 노출되었는지를 예측하는 것입니다.
2. 필요한 라이브러리 가져오기
# 라이브러리 가져오기
import pandas as pd
import numpy as np
# 데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
3. 데이터 세트 로드하기
판다스 데이터프레임에 데이터를 로드하고 탐색을 시작해봅시다.
heart = pd.read_csv('heart.csv')
데이터를 로드했으니, 데이터프레임의 처음 몇 행을 살펴보며 데이터의 모습을 파악해봅시다.
heart.head()
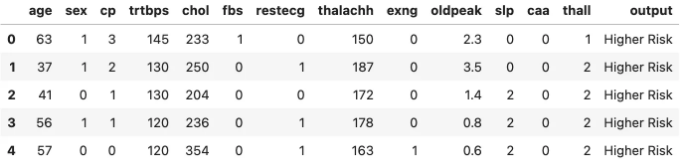
데이터셋은 환자가 심장마비를 겪었는지 여부를 나타내는 출력 열을 포함한 총 14개의 열을 가지고 있는 것을 확인할 수 있습니다. 이제 시각화 작업을 시작해봅시다.
4. 데이터 정리 및 전처리
데이터 정리의 목적은 분석하고 시각화할 준비를 하는 것입니다.
# Null 값이 있는지 확인
heart.isnull().sum().sort_values(ascending=False).head(11)

여기서는 누락된 값이 없는 것을 확인할 수 있습니다.
# 중복된 값 체크
heart.duplicated().sum()

# 중복된 값 삭제
heart.drop_duplicates(keep='first', inplace=True)

이제 데이터가 깔끔해졌어요.
5. 통계 요약
# 데이터셋의 통계 요약을 얻기
heart.describe().T
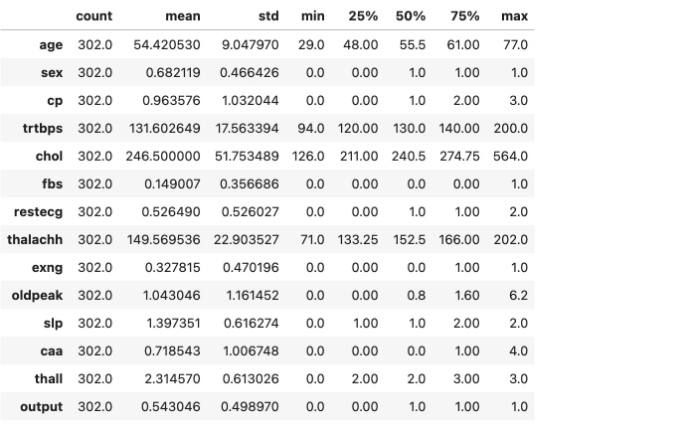
가장 중요한 결론은 대부분의 열에서, 평균 값이 중앙값(50번째 백분위: 50%)과 유사하다는 것입니다.
6. 데이터 시각화 및 해석
- 성별 기반 데이터 시각화
# 심장 발작 대 성별 비교
df = pd.crosstab(heart['output'],heart['sex'])
sns.set_style("white")
df.plot(kind="bar",
figsize=(6,6),
color=['#c64343', '#e1d3c1']);
plt.title("심장 발작 위험 대 성별", fontsize=16)
plt.xlabel("0 = 낮은 위험 1 = 높은 위험", fontsize=16)
plt.ylabel("수량", fontsize=16)
plt.legend(["여성","남성"], fontsize=14)
plt.xticks(rotation=0)
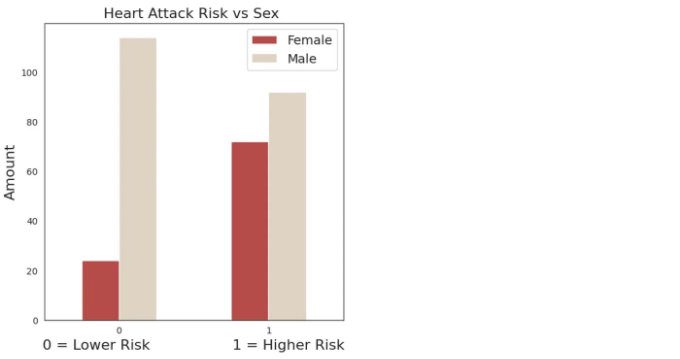
fig = px.pie(heart2,
names= "sex",
template= "presentation",
hole= 0.6,
color_discrete_sequence=['#e1d3c1', '#c64343']
#color_discrete_sequence=px.colors.sequential.RdBu
)
# layout
fig.update_layout(title_text='Gender Distribution',
title_x=0.5,
font=dict( size=18),
autosize=False,
width=500,
height=500,
showlegend=False)
fig.add_annotation(dict(x=0.5, y=0.5, align='center',
xref = "paper", yref = "paper",
showarrow = False, font_size=22,
text="<span style='font-size: 26px; color=#555; font-family:Arial'>Gender<br></span>"))
fig.update_traces(textposition='outside', textinfo='percent+label', rotation=20)
fig.show()
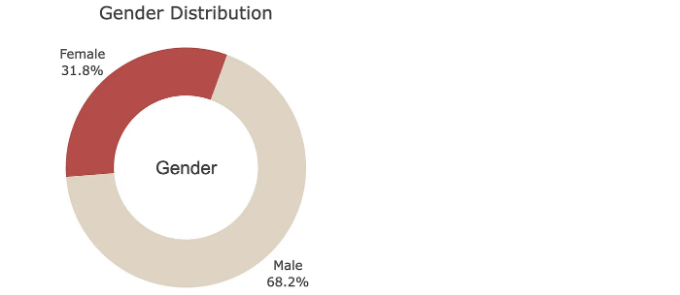
해석: 남성은 심장 공격의 위험이 더 높습니다.
- 연령별 데이터 시각화
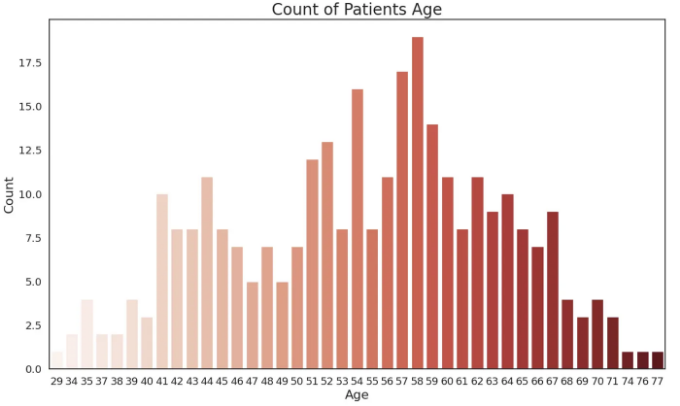
plt.figure(figsize=(14,8))
sns.set(font_scale=1.2)
sns.set_style("white")
sns.countplot(x=heart["age"],
palette='Reds')
plt.title("환자 연령별 수", fontsize=20)
plt.xlabel("연령", fontsize=16)
plt.ylabel("수", fontsize=16)
plt.show()
# 연령에 기반한 분석
sns.set(font_scale=1.3)
plt.figure(figsize=(8,6))
sns.set_style("white")
sns.distplot(heart['age'],
color='red',
kde=True)
plt.title("환자 연령대 분포", fontsize=20)
plt.xlabel("연령", fontsize=16)
plt.ylabel("밀도", fontsize=16)
plt.show()
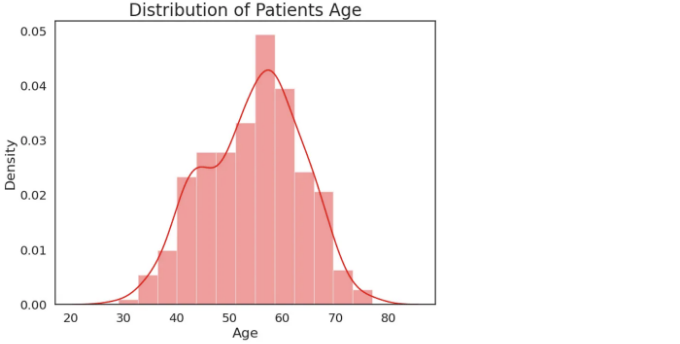
해석: 대부분의 환자의 나이는 50-60대입니다. 그 중에서도 가장 많은 환자의 나이는 58세입니다.
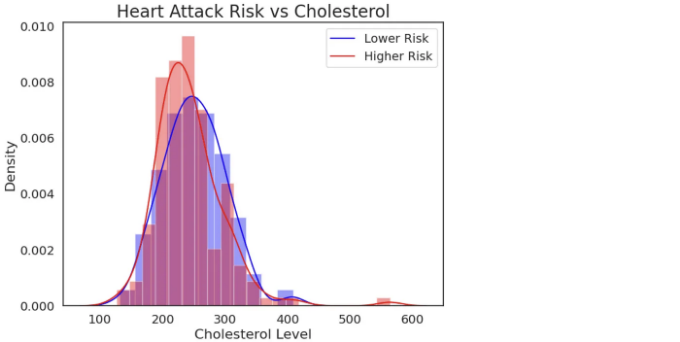
- 콜레스테롤 수준에 따른 데이터 시각화
# 심장병 vs 콜레스테롤 분석
sns.set(font_scale=1.3)
plt.figure(figsize=(8,6))
sns.set_style("white")
sns.distplot(heart[heart["output"]==0]["chol"],
color="blue")
sns.distplot(heart[heart["output"]==1]["chol"],
color="red")
plt.title("심장병 발병 위험 vs 콜레스테롤", size=20)
plt.xlabel("콜레스테롤 수준", fontsize=16)
plt.ylabel("밀도", fontsize=16)
plt.legend(["낮은 위험","높은 위험"], fontsize=14)
plt.show()
plt.figure(figsize=(8,6))
sns.lineplot(y="chol",
x="age",
data=heart,
color="red")
plt.title("Cholesterol with Age",fontsize=20)
plt.xlabel("Age",fontsize=16)
plt.ylabel("Cholesterol Level",fontsize=16)
plt.show()
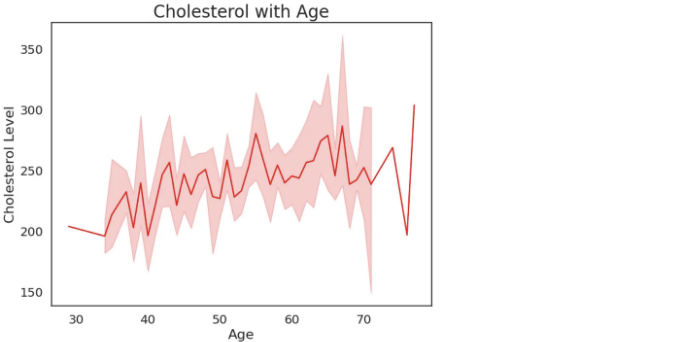
해석:
- 환자들의 대부분은 콜레스테롤 수치가 200–300 사이에 있습니다.
- 나이가 들수록 체내 콜레스테롤 수치가 증가할 가능성이 높습니다.
- 가슴 통증 유형별 데이터 시각화
# 가슴 통증 유형에 따른 심근경색과의 관계
df = pd.crosstab(heart3['cp'], heart['output'])
# 크로스탭을 시각적으로 더 효과적으로 표현
sns.set(font_scale=1.3)
sns.set_style("white")
df.plot(kind='bar',
figsize=(11,7),
color=['#e1d3c1', '#c64343']);
plt.title("심근경색 발병 위험 vs. 가슴 통증 유형", fontsize=20)
plt.xlabel("가슴 통증 유형", fontsize=16)
plt.ylabel("수량", fontsize=16)
plt.legend(['낮은 위험','높은 위험'], fontsize=14)
plt.xticks(rotation=0);
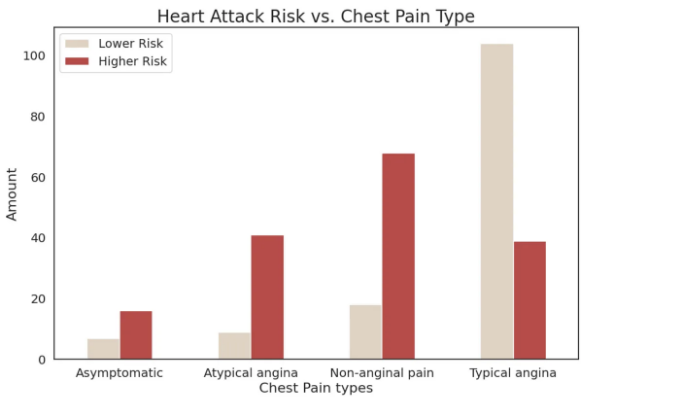
해석:
- 대부분의 환자는 전형적인 협심증 유형을 가지고 있습니다.
- 비협심통을 겪는 환자들은 심근경색 발생 위험이 높습니다.
- 상관 관계 기반 데이터 시각화
plt.figure(figsize=(12,10))
sns.set(font_scale=0.9)
sns.heatmap(heart.corr(),
annot=True,
cmap='Reds')
plt.title("변수 간 상관 관계", size=15)
plt.show()
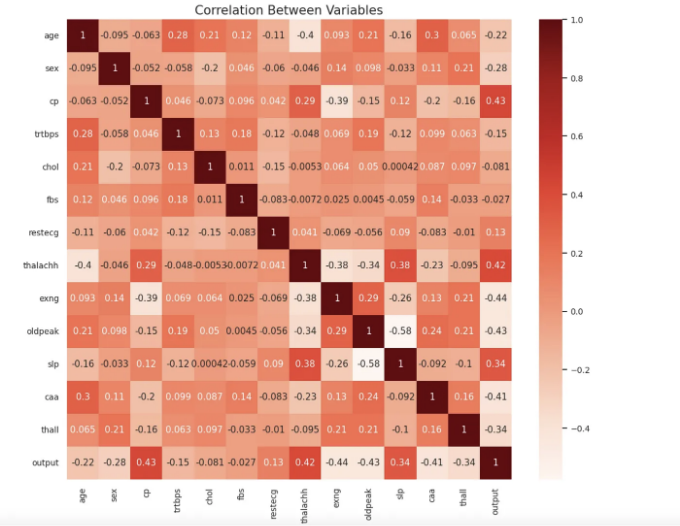
해석:
열이 히트맵을 통해 다음 사항을 알 수 있습니다.
- 가슴 통증 유형(cp)과 결과(Output)
- 최대 심박수(thalachh)와 결과(Output)
- 경사(sp)와 결과(Output)
또한 약한 상관 관계를 확인할 수도 있습니다.
- oldpeak: 이전 최고점과 결과(Output)
- caa: 주요 혈관 수 및 결과(Output)
- exng: 운동 유도성 협심증
결론
이 게시물에서는 막대 차트, 파이 차트, 라인 차트, 히스토그램, 히트맵과 같은 몇 가지 플롯을 생성하여 데이터 시각화를 사용하여 데이터 세트를 조사했습니다.
탐색적 데이터 분석(EDA)과 데이터 시각화의 주요 목적은 어떤 가정을 하기 전에 데이터를 이해하는 데 도움을 주는 것입니다. 이것들은 분포, 요약 통계, 변수 간의 관계 및 이상치를 볼 수 있도록 도와줍니다.
Python 기초 개념
감사합니다! 🚀 "Python Fundamentals"에서 더 많은 콘텐츠를 찾아보실 수 있어요 💫
쉽게 설명한 것 🚀
"In Plain English" 커뮤니티의 일원이 되어 주셔서 감사합니다! 계속하기 전에:
- 글에 박수를 보내고 작가를 팔로우해주세요 ️👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | 뉴스레터
- 다른 플랫폼에서도 만나보세요: Stackademic | CoFeed | Venture | Cubed
- PlainEnglish.io에서 더 많은 콘텐츠를 확인해보세요