
음성이 어떤 음조와 조화를 이루거나 어떤 사투리를 쓰거나 전설적인 가수들의 특이한 음색을 복제할 수 있는 세계를 상상해보세요. 이것은 AI 노래 음성 복제를 통해 가능해진 현실입니다.
이 혁신적인 기술은 음악의 예술을 기계 학습의 정밀성과 결합하여 우리가 원하는 어떤 목소리로도 새로운 노래를 만들거나 고전적인 곡을 재해석할 수 있게 해줍니다.
AI 음성 복제는 특이한 음성의 특성을 포착하고 놀라운 정확도로 재현하는 기술입니다. 이 디지털 연금술을 통해 우리는 기존의 목소리를 복제하는 것뿐만 아니라 완전히 새로운 목소리를 만들어내는 것도 가능해집니다.
컨텐츠 생성을 혁신한 도구입니다. 맞춤 노래부터 사용자 정의 보이스 오버까지 다양한 크리에이티브 가능성을 열어줍니다. 이는 언어와 문화적인 장벽을 초월하는 세계를 제공합니다.
본 글의 목적은 기술적인 독자들을 대상으로 AI 보이스 클로닝 기술을 활용하는 포괄적인 Python 가이드를 제공하는 것입니다. 이 기술은 선택한 아티스트의 음조로 또는 사용자 자신의 목소리로 어떠한 오디오든 변환할 수 있는 종단 간 솔루션입니다.
이 튜토리얼 글은 다음과 같이 구성되어 있습니다:
1. 기술적 배경
이 기사에서 사용할 기술은 Singing Voice Conversion (SVC)이라는 시스템인 SO-VITS-SVC입니다. SO-VITS-SVC는 "SoftVC VITS Singing Voice Conversion"의 약어로, SVC의 정교한 구현을 나타냅니다.
SO-VITS-SVC 시스템은 심층 학습 기술을 사용하여 노래 목소리 변환(SVC)을 복잡하게 구현한 것입니다. 이 시스템을 이해하려면 사용된 특정 기계 학습 아키텍처와 알고리즘에 대한 이해가 필요합니다.
1.1 변분 추론과 생성 적대 네트워크
- SO-VITS-SVC의 중심에는 Text-to-Speech (VITS) 아키텍처에 대한 변분 추론이 있습니다. 이 시스템은 변분 오토인코더(VAEs)와 생성 적대 네트워크(GANs)를 빈틈없이 결합하고 있습니다.
- VAEs는 SVC에서 오디오 신호의 중요한 표현인 멜 스펙트로그램 분포를 모델링하는 데 사용됩니다. VAE 구성 요소는 음성의 잠재 변수를 캡처하는 데 도움이 됩니다.
- VAE 손실 함수는 아래 수식과 같이 표현됩니다. 여기서 x는 입력 멜 스펙트로그램, z는 잠재 변수이며 KL은 Kullback-Leibler 발산을 나타냅니다.
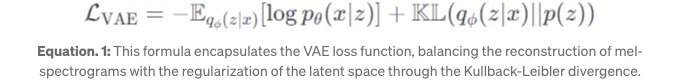
- GANs enhance the realism of the synthesized audio. The discriminator in the GAN critiques the output of the generator, improving its accuracy. The GAN loss function is given by:
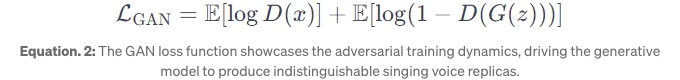
For a comprehensive understanding of Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), you might want to refer to the original papers introducing these concepts:
- VAEs: Kingma, D. P., and Welling, M. "Auto-Encoding Variational Bayes." arXiv:1312.6114, 2013.
- GANs: Goodfellow, I. J., et al. "Generative Adversarial Nets." arXiv:1406.2661, 2014.
1.2 얕은 확산 프로세스
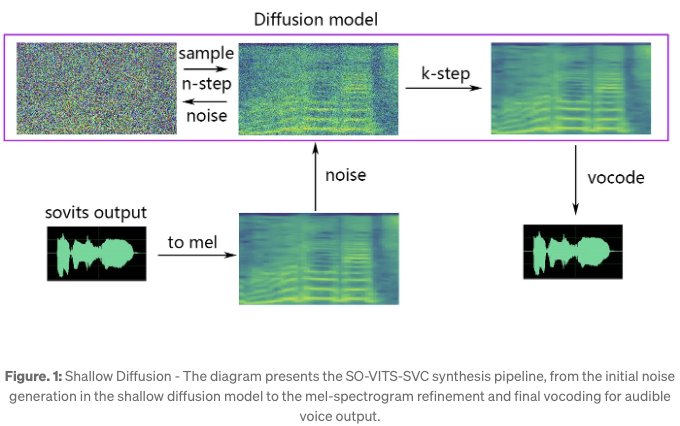
- 인접 다이어그램에 나와 있는 것처럼, 얕은 확산 프로세스는 소음 샘플로 시작되어 일련의 변환을 통해 구조화된 멜 스펙트로그램으로 점진적으로 정제됩니다.
-
초기 노이즈 샘플: 확산 프로세스의 시작점으로 작용하는 노이즈의 시각적 표현입니다.
-
변환 단계: 노이즈는 확산 모델 내에서 일련의 단계를 거치며 비구조적인 상태에서 구조화된 멜 스펙트로그램으로 전환됩니다. 아래와 같이 설명할 수 있으며, 여기서 xt는 t단계에서의 데이터를 나타내고 ϵ은 가우시안 노이즈를 나타냅니다.

- SO-VITS-SVC의 맥락에서 '얕은'이라고 할 때는 아마도 계층이나 단계가 적은 것을 의미하며, 계산 효율성과 오디오 품질 사이의 균형을 맞출 것으로 예상됩니다.
-
멜 스펙트로그램 정제: 이 과정의 결과는 노래하는 목소리의 오디오 콘텐츠를 담은 멜 스펙트로그램으로, 다음 합성 단계에 사용할 준비가 된 상태입니다.
-
보코딩: 최종 보코딩 단계에서 멜 스펙트로그램을 오디오 웨이브폼으로 변환하여, 그것이 들리는 노래하는 목소리가 됩니다.
확산 모델에 대한 깊은 탐구를 위해 다음 자료들이 상세한 설명과 연구 맥락을 제공합니다:
- Sohl-Dickstein, J., et al. “Deep Unsupervised Learning using Nonequilibrium Thermodynamics.” arXiv:1503.03585, 2015.
- Ho, J., et al. “Denoising Diffusion Probabilistic Models.” arXiv:2006.11239, 2020.
1.3 SVC 시스템과 합성 프로세스의 통합
- 멜-스펙트로그램 정제:
얕은 확산 모델이 소음을 더 응집된 형태로 구조화한 후에, 이전에 언급된 다이어그램에서 시각화된 대로 결과 멜-스펙트로그램은 노래하는 목소리의 세세한 오디오 콘텐츠를 포착합니다. 이 멜-스펙트로그램은 초기 구조가 없는 데이터와 최종 음성 출력 사이의 중요한 다리 역할을 합니다.
- 보코딩:
보코더는 그 후 정제된 멜 스펙트로그램을 오디오 웨이브폼으로 변환하는 데 사용됩니다. 이 단계는 시각 데이터가 청각적인 노래 목소리로 변환되는 과정입니다. 보코더의 역할은 멜 스펙트로그램에서 포착된 음높이, 음색 및 리듬의 미묘한 점을 합성하여 최종 노래 목소리를 생성하는 것입니다.
- 훈련 및 최적화:
이 고품질 음성 합성을 달성하기 위해 SO-VITS-SVC 시스템은 엄격한 훈련과 최적화를 거칩니다. 훈련에는 VAE, GAN 및 확산 모델 구성 요소의 기여를 균형있게 조절하는 병합 손실 함수를 최적화하는 과정이 포함됩니다.
이 최적화는 확률적 경사 하강법이나 Adam과 같은 알고리즘을 사용하여 진행되며, 전반적인 손실을 최소화하는 것을 최종 목표로 합니다. 이 과정을 통해 최종 출력이 음색, 음높이 및 리듬 측면에서 목표 노래 목소리와 유사하게 되도록 보장합니다.
- 최종 산출물:
이 프로세스의 최종 산출물은 대상 노래하는 목소리와 매우 유사한 합성음성입니다. 소스의 음악성과 표현의 미묘함을 유지하면서 대상의 음조 특성을 채택하는 능력은 SO-VITS-SVC 시스템의 정교함을 증명합니다.
머신러닝과 딥러닝에 처음 접하는 사람들을 위해 교육 플랫폼에서 제공하는 기초 자료와 코스는 필요한 배경 지식을 쌓는 데 초석이 될 수 있습니다:
- Coursera — 딥러닝 전문화: https://www.coursera.org/specializations/deep-learning
- MIT OpenCourseWare — 딥러닝 입문: https://ocw.mit.edu/courses/6-036-introduction-to-deep-learning-spring-2021/
1.4 IPython 라이브러리 사용
GitHub에서 호스팅되는 SO-VITS-SVC Fork는 실시간 노래 음성 변환을 위해 특별히 설계된 전문 도구입니다. 원본 SO-VITS-SVC 프로젝트의 이 Fork는 CREPE를 사용하여 더 정확한 음높이 추정을 제공하는 등 강화된 기능을 제공합니다. 또한 GUI(Graphical User Interface), 더 빠른 학습 시간, pip를 사용하여 도구를 쉽게 설치할 수 있는 편의성을 제공합니다.
또한 QuickVC를 통합하고 원본 저장소에서 발견된 일부 문제를 수정합니다. 이 Fork는 실시간 음성 변환을 지원하여 목소리 복제 작업에 사용할 수 있는 다목적 도구입니다. 또한 설치 및 설정 과정을 단순화하여 목소리 복제 기술을 실험하고 싶은 사용자들에게 더 쉽게 접근할 수 있습니다.
2. 추론: 어떤 아티스트의 AI 목소리로 노래하기
추론은 신경망 모델이 특정 음성을 이해하기 위해 데이터 세트에서 훈련된 후, 해당 학습된 음성으로 새로운 콘텐츠를 생성하는 과정을 의미합니다.
이 단계에서는 사전 훈련된 모델에 새로운 입력(원시 가창 음성 오디오)을 제공하여 해당 아티스트의 AI 음성과 함께 '노래'할 수 있는 시기입니다. 그 모델은 이후 해당 원시 음성 오디오에서 아티스트의 가창 스타일을 모방하는 출력을 생성합니다.
2.1 SO-VITS-SVC 환경 설정하기
간편하게 가상 환경을 갖춘 Jupyter Notebook을 사용할 것입니다. 그러므로 그곳에서 스타팅하는 것을 권장합니다.
- Anaconda 설치하기: 시스템에 Anaconda를 다운로드하고 설치하세요. 이를 통해 다른 프로젝트를 위한 격리된 환경을 만들 수 있습니다.
- Anaconda 터미널을 열고 다음 명령을 실행하여 새 환경을 생성하세요.
conda create -n sovits-svc
- 만약 VS Code를 사용한다면 커널 선택에서 환경을 참조할 수 있습니다. 그렇지 않으면 Anaconda를 계속 사용할 경우 conda activate로 환경을 활성화하고 Jupyter notebook을 실행하세요.
conda activate sovits-svc
- 노트북 내에서 환경에 필요한 라이브러리를 설치하세요.
!python -m pip install -U pip wheel
%pip install -U ipython
%pip install -U so-vits-svc-fork
- 나중에 !svc 명령을 실행할 때 아래와 같은 문제를 피하기 위해 아나콘다 환경으로 이동하여 torchaudio를 pip uninstall torchaudio로 제거하고 pip install torchaudio로 다시 설치해야 합니다.
이제 깨끗한 보컬(즉, 배경 소음이 없는)에 사전 훈련된 모델을 사용하여 '노래 음성 변환'을 수행할 준비가 되었습니다.
2.1 사전 훈련된 모델을 사용하여 노래 목소리 생성하기
1) 사전 훈련된 모델 선택하기
환경이 준비되었으면, 다음 단계는 사전 훈련된 모델을 얻는 것입니다. 여러 사전 훈련된 모델이 제공되어 사용할 수 있습니다. Drake부터 Michael Jackson까지! 옵션은 다음과 같습니다:
어떤 모델을 사용할지 결정되면, .pth Pytorch 모델 파일과 관련된 config.json을 검색하고 다운로드해야 합니다:
from huggingface_hub import hf_hub_download
import os
# 저장소 ID와 로컬 디렉터리를 설정합니다. Drake의 모델을 사용할 것입니다.
repo_id = 'Entreprenerdly/drake-so-vits-svc'
local_directory = '.'
# config.json 파일을 다운로드합니다.
config_file = hf_hub_download(
repo_id=repo_id,
filename='config.json',
local_dir=local_directory,
local_dir_use_symlinks=False
)
# 현재 디렉터리에 config 파일 경로를 만듭니다.
local_config_path = os.path.join(local_directory, 'config.json')
print(f"config 파일 다운로드 완료: {local_config_path}")
# 모델 파일을 다운로드합니다.
model_file = hf_hub_download(
repo_id=repo_id,
filename='G_106000.pth',
local_dir=local_directory,
local_dir_use_symlinks=False
)
# 현재 디렉터리에 모델 파일 경로를 만듭니다.
local_model_path = os.path.join(local_directory, 'G_83000.pth')
print(f"모델 파일 다운로드 완료: {local_model_path}")
2) 깨끗한 오디오 파일 선택
다음으로, 변환을 위해 깨끗한 오디오 파일을 다운로드할 것입니다. 사용할 오디오 파일은 Google 드라이브를 통해 액세스하고 다운로드할 수 있습니다.
Justin Bieber의 깨끗한 보컬 트랙이며, 선택한 모델을 사용하여 음성 변환을 위해 SO-VITS-SVC 시스템에 입력할 수 있습니다.
이것은 가장 깔끔하지 않을 수 있지만, 오디오 파일을 변환하기 전에 자체 오디오 파일을 준비할 때는 생성된 오디오에서 의도하지 않은 아티팩트나 품질 문제를 피하기 위해 가능한 깨끗하게 유지하는 것이 매우 중요합니다.
원본 오디오의 품질은 목소리 변환의 충실도에 큰 영향을 미치므로 항상 고품질의 깨끗한 녹음을 권장합니다.
import requests
vocals_url = 'https://drive.google.com/uc?id=154awrw0VxIZKQ2jQpHQQSt__cOUdM__y'
response = requests.get(vocals_url)
with open('vocals.wav', "wb") as file:
file.write(response.content)
display(Audio('vocals.wav', autoplay=True))
3) 추론 실행하기
SO-VITS-SVC 모델을 사용하여 음성 변환을 수행하려면 오디오 파일, 모델 체크포인트 및 구성 파일의 경로를 지정해야 합니다. 아래는 경로를 설정하고 추론을 실행하는 방법입니다.
이 명령을 실행하는 환경이 SO-VITS-SVC 도구가 설치된 환경에서 !svc 명령에 액세스할 수 있는 환경에서 실행되는지 확인하세요. 예를 들어 명령 프롬프트나 SO-VITS-SVC 도구가 설치된 환경에서 실행되는 스크립트와 같은 환경입니다.
from IPython.display import Audio, display
import os
# 파일 이름
audio_filename = 'vocals.wav'
model_filename = 'G_106000.pth'
config_filename = 'config.json'
# 전체 로컬 경로 구성
audio_file = f"\"{os.path.join('.', audio_filename)}\""
model_path = f"\"{os.path.join('.', model_filename)}\""
config_path = f"\"{os.path.join('.', config_filename)}\""
# 추론 명령 실행
!svc infer {audio_file} -m {model_path} -c {config_path}
4) 출력 표시
추론을 실행한 후에는 Jupyter 노트북이나 IPython 인터페이스에서 바로 출력 오디오를 표시할 수 있습니다. 다음의 코드 스니펫을 사용하면 결과 오디오 파일을 재생할 수 있습니다:
from IPython.display import Audio, display
# 출력 오디오 파일의 경로
output_audio_path = "vocals.out.wav"
# 결과 오디오를 표시
display(Audio(output_audio_path, autoplay=True))
5) 선택 사항 — GUI 사용하여 추론 수행하기
그래픽 인터페이스를 선호하는 사용자들을 위해, SO-VITS-SVC 시스템은 음성 변환을 수행하기 위한 선택적 GUI를 제공합니다.
이 기능이 풍부한 GUI는 명령 줄 작업의 대안을 제공하여 추론 프로세스를 간소화합니다. 다음을 사용하여 시작할 수 있습니다.
svcg
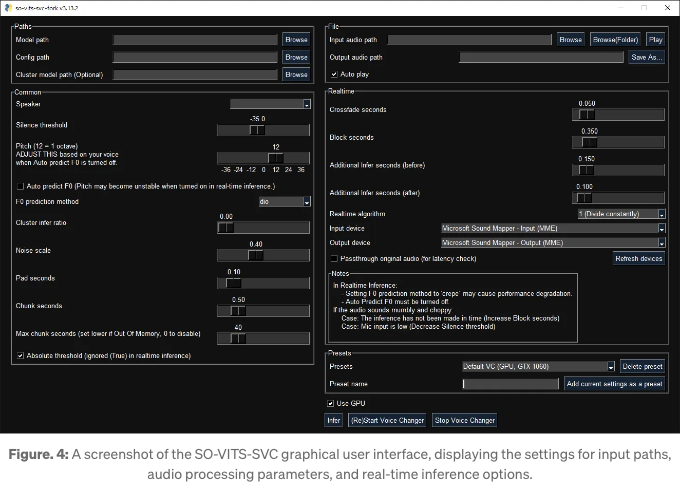
- 설정: GUI를 실행하고 모델, 구성 및 오디오 파일의 필요한 경로를 '찾아보기' 버튼을 사용하여 구성합니다.
- 모델 선택: 'Model path' 필드를 통해 적절한 사전 훈련된 모델을 선택합니다.
- 구성: 모델에 해당하는 구성 파일을 'Config path' 필드에서 선택합니다.
- 오디오 입력: 'Input audio path'를 사용하여 변환할 대상 오디오 파일을 로드합니다.
- 추론: 필요한 경우 추가 매개변수를 조정하여 변환 프로세스를 시작하려면 'Infer' 버튼을 클릭합니다.
- 출력: GUI를 통해 직접 생성된 출력을 저장하고 듣어보며 품질이 예상과 일치하는지 확인합니다.
GUI는 실시간 추론 기능도 제공하여 조정을 즉시 하고 즉각적인 청각적 피드백도 받을 수 있습니다.
스크립팅이나 명령 줄 도구에 익숙하지 않은 사용자들을 고려하여 사용하기 쉽게 설계되었습니다.
2. 모델 훈련: 당신처럼 노래하는 방법을 AI에게 가르치기
이제 SO-VITS-SVC 시스템을 사용하여 사용자 지정 노래 목소리 변환 모델을 훈련하는 데 필요한 단계들을 보여드리겠습니다. 데이터셋 준비부터 환경 설정 및 모델 훈련, 기존 오디오 클립에서 노래하는 목소리를 생성하는 추론까지 순서대로 진행하겠습니다.
모델 훈련 과정에 착수하기 전에 중요한 점이 있습니다. 이 작업은 컴퓨팅이 많이 필요하며, 높은 성능의 GPU와 상당한 VRAM이 필요합니다. 보통 10GB 이상이 필요합니다.
이러한 요구 사항을 충족하지 못하는 개인용 하드웨어를 사용하는 분들을 위해, Google Colab은 강력한 GPU와 충분한 메모리에 접근할 수 있는 대안을 제공합니다. T4 GPU가 충분합니다. 추론은 그렇게 많은 VRAM이 필요하지 않습니다.
2.1 데이터 준비
Hugging Face에서 제공되는 다양한 음성 데이터셋을 활용하여 사용자 정의 so-vits-svc 모델을 훈련할 수 있습니다. 그러나 고유한 음성 특성으로 모델을 개인화하고자 한다면, 자신의 목소리를 녹음하는 것이 더 흥미로운 방법일 것입니다.
당신만의 목소리 샘플 녹음하기
- 샘플 길이: 가능하다면 최적의 길이인 10초씩 말하고 노래하는 자신을 녹음해보세요. 이 길이는 당신의 목소리의 세세한 특징을 캡처하기에 적합하며 처리하는 데 너무 많은 요구를 안 합니다.
- 샘플의 양: 데이터가 많을수록 더 좋습니다. 적어도 200개의 목소리 샘플을 목표로 해보세요. 50개의 노래 샘플과 150개의 말하기 샘플이 적절한 혼합입니다.
- 총 오디오 길이: 적어도 5분의 총 오디오를 모으는 것이 목표입니다. 이것은 모델이 학습할 튼튼한 기반을 제공합니다.
- 다양한 콘텐츠: 발음학적으로 균형 잡힌 문장들을 읽어 다양한 음운을 다루세요. IEEE는 말 음질 측정을 위한 권장 사항으로 이러한 문장들의 목록을 제공하며 이는 다양성 있는 데이터셋에 기여할 수 있습니다.
- 녹음 도구: Audacity는 당신의 샘플 녹음에 완벽한 무료 오픈 소스 소프트웨어입니다. 이것은 WAV 파일의 쉬운 녹음, 편집 및 내보내기를 가능하게 합니다.
목소리 샘플 더욱 준비하기
- 배경 소음 제거: 오디오 트랙에서 배경 소음을 제거해야 할 수 있습니다. Spleeter는 이를 위한 우수한 파이썬 라이브러리입니다. 아래 예시를 참고하세요. 그러나 반드시 WAV 파일로 저장해야 합니다. 더 자세한 내용은 깃허브 저장소를 참조해주세요.
!pip install spleeter
from spleeter.separator import Separator
# 주어진 구성으로 분리기를 초기화합니다.
# 여기서 'spleeter:2stems'는 음성을 보컬과 반주 두 부분으로 분리하려고 한다는 것을 의미합니다.
separator = Separator('spleeter:2stems')
# 분리기를 오디오 파일에 적용합니다.
# 이 함수는 오디오 파일을 두 개의 파일로 분리합니다: 보컬이 포함된 파일과 배경 음악이 포함된 파일입니다.
separator.separate_to_file('audiofile.wav', './')
- 15초 단위로 오디오 트랙 분할하기: AudioSlicer를 사용하여 광범위한 오디오 파일을 10-15초 단위로 나눠 모델 학습에 적합한 스니펫으로 만들 수 있습니다.
from audioslicer import slice_audio
# 입력 오디오 파일 경로
input_audio_path = 'long_audio_file.wav'
# 스니펫이 저장될 출력 디렉토리 경로
output_directory = 'output/snippets/'
# 각 오디오 스니펫의 길이(초)
snippet_length = 15
# 오디오 파일을 스니펫으로 나눕니다.
slice_audio(input_audio_path, output_directory, snippet_length)
2.2 자동 전처리
현재 디렉토리에 dataset_raw 폴더가 생성되었고, 녹음 파일은 dataset_raw/'speaker_id' 디렉토리에 저장되어 있습니다. 아래 폴더 구조에 설명된 대로, 노래 목소리 변환 모델을 위한 전처리 및 학습 단계를 시작할 준비가 되었습니다.
.
├── dataset_raw
│ └── {speaker_id}
│ └── {wav_file}.wav
전 처리 단계에는 오디오 데이터를 모델 학습을 위해 준비하는 3가지 주요 단계가 포함됩니다 — !svc pre-resample, !svc pre-config, !svc pre-hubert로 최종적으로 !svc train을 실행합니다.
전체 훈련 코드는 entprenerdly.com을 방문해주시기 바랍니다. Entrprenerdly는 튜토리얼, 코드 및 전략을 모두 제공합니다. 이러한 리소스들은 실용적인 지식을 얻을 수 있도록 설계되었습니다.

2.3 Training Configuration
학습을 시작하기 전에 모델을 구성하여 최적의 학습 조건을 확보하는 것이 중요합니다. 이는 전처리 중에 생성된 config.json 파일을 편집하는 작업을 포함합니다. 이 구성 파일 내의 주요 매개변수는 다음과 같습니다: log_interval, eval_interval, epochs, batch_size:
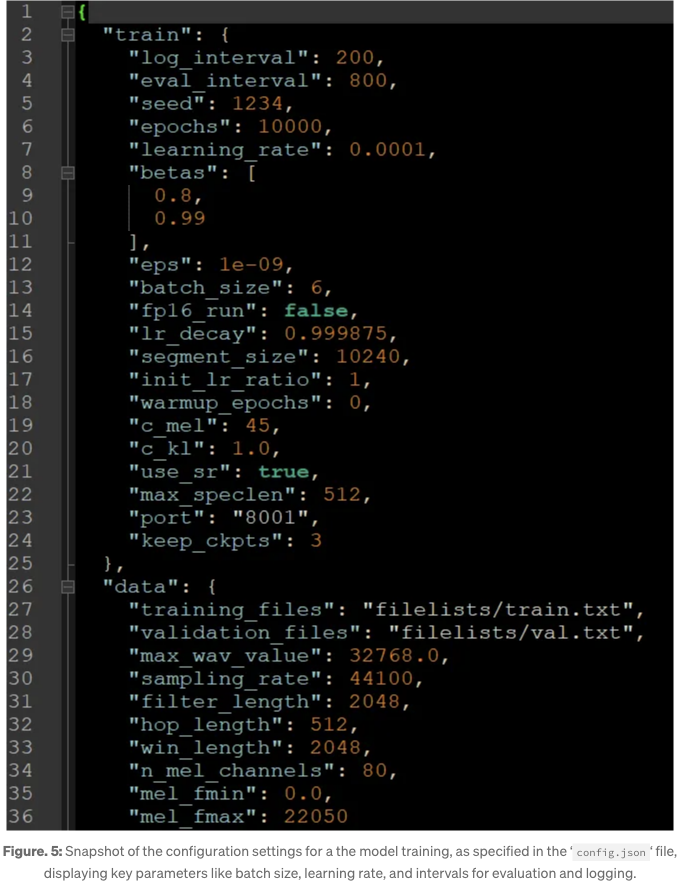
데이터셋은 200개의 샘플이 있고 배치 크기는 20입니다. 따라서 각 에포크는 10단계와 같습니다. 100 에포크를 목표로 한다면 1,000단계가 됩니다. 에포크 수에 1을 추가하는 것이 좋습니다. 마지막 단계가 저장되도록 하기 위해서입니다.
기본 설정은 10,000 에포크를 제안할 수 있지만, 하드웨어와 데이터셋 크기에 따라 조정해야 할 수도 있습니다. 실용적인 접근법은 20,000단계를 목표로 삼고 훈련을 계속하기 전에 성능을 평가하는 것입니다.
2.4 훈련 시작
svc train 명령어로 실제 모델 훈련을 시작하세요. 이 명령은 dataset/44k/'speaker_id' 디렉토리에서 전처리된 데이터와 config/44k/config.json의 설정을 활용하여 머신러닝 프로세스를 시작합니다.
전체 교육 코드는 entreprenerdly.com을 방문해주세요. Entrprenerdly는 튜토리얼, 코드, 그리고 전략을 모두 담은 호스팅 서비스입니다. 이러한 자료들은 실용적인 지식을 전해줄 수 있도록 설계되었습니다.
2.5 모델 추론
모델을 학습하고 세밀하게 조정하며 유효성을 검증한 후, 다음 단계는 이전 섹션에 따라 소스 오디오를 대상 음성으로 변환하는 추론을 실행하는 것입니다.
from IPython.display import Audio, display
import os
# 파일 이름
audio_filename = 'vocals.wav' # 훈련된 모델을 적용할 보컬
model_filename = 'model.pth' # 생성된 모델 파일
config_filename = 'config.json' # 생성된 구성 파일
# 전체 로컬 경로 구성
audio_file = f"\"{os.path.join('.', audio_filename)}\""
model_path = f"\"{os.path.join('.', model_filename)}\""
config_path = f"\"{os.path.join('.', config_filename)}\""
# 추론 명령 실행
!svc infer {audio_file} -m {model_path} -c {config_path}
추론을 실행한 후에는 더 나은 결과물을 더 섬세하게 조정하고 싶을 수 있습니다. 예를 들어, 소스 오디오가 노래였고 배경 음악과 혼합해야 하는 경우나 음정을 조정하고 싶은 경우, Audacity나 다른 디지털 오디오 워크스테이션과 같은 오디오 처리 도구를 사용하여 선호에 맞게 트랙을 혼합하고 조정할 수 있습니다.
4. 해결책의 실용적 응용
- 음악 제작 향상 — 프로듀서들은 가수의 다른 음성 질감과 스타일을 실험해볼 수 있으며 아티스트의 물리적 존재 없이도 이를 시도할 수 있습니다. 새로운 트랙을 개념화하거나 다양한 음 높이와 음색으로 배경 보컬을 추가하는 데 특히 유용할 수 있습니다.
- 맞춤형 음악 체험 — 팬들이 다른 아티스트의 목소리로 즐겨 듣는 노래의 버전을 받거나 사용자 정의 모델을 사용하여 자신의 목소리로 노래하게끔 받는 서비스를 상상해보세요.
- 영화 및 애니메이션 더빙 — SO-VITS-SVC를 통해 영화, 만화, 게임의 더빙은 특히 원래 배우가 사용 불가능할 때 다양한 캐릭터 목소리로 보이스 오버를 생성하여 이점을 얻을 수 있습니다. 다양한 언어 버전 간 일관된 보컬 성능을 만들어낼 수 있습니다.
- 교육 도구 — 언어 학습에서 SO-VITS-SVC를 사용하면 학습자가 여러 언어의 올바른 악센트와 억양으로 읽힌 텍스트를 자신의 목소리로들을 수 있어 이해력을 향상시킬 수 있습니다. 청취 및 말하기 기술을 발전시키는 데 도움이 됩니다.
- 목소리 복원 — 말하는 능력을 잃은 개인들을 위해 SO-VITS-SVC는 그들의 목소리 레코딩을 기반으로 훈련을 받아 원래 목소리의 본질을 유지하면서 의사소통 능력을 회복할 수 있습니다.
- 역사적 목소리 부활 — 지난 시대의 연설을 살려내어 박물관이나 교육 콘텐츠에서 흥미로운 청각 경험을 제공할 수 있습니다.
결론
이 기술의 함의는 깊고 넓은 영향을 미치고 있습니다. 가까운 미래에는 독립 아티스트가 AI를 활용하여 역사적인 어떤 목소리와도 듀엣할 수 있는 음악 제작의 민주화를 볼 수도 있을 것입니다. 또는 교육자들이 언어 장벽을 세계적으로 제거하는 데 활용할 수도 있을 것입니다. 그러나 SO-VITS-SVC의 참된 잠재력은 우리가 아직 완전히 이해하거나 상상조차 못한 장기적인 응용 분야에 있습니다.
시각적 취향에만 맞추는 것이 아니라 청각적 편안함에도 개인화된 모든 디지털 상호 작용이 세계를 상상해보세요. 시각적인 광경뿐만 아니라 청각적인 축제가 되는 가상 현실 세계를 상상해보세요. 모든 캐릭터, 모든 존재가 실제 사람의 목소리와 구분이 안 가는 목소리로 당신과 대화할 수 있는 세계입니다. SO-VITS-SVC는 고유한 음성 아이덴티티를 가진 가상 존재를 위한 선구자가 될 수 있습니다. 이들은 다양한 언어와 스타일에서 노래하고 말하며 상호 작용할 수 있는 능력을 가질 것입니다.
이러한 프로젝트와 더불어 AI, 데이터 과학, 기술 분야의 또 다른 혁신적인 데이터 기반 개발을 위해 독자 여러분이 www.entreprenerdly.com의 다양한 정보 자원을 탐험할 것을 장려합니다.
