요약
문맥: 제로샷 러닝(Zero-shot learning, ZSL)은 머신 러닝에서 cutting-edge한 방법론으로, 모델이 사전 노출 없이 새로운 객체를 인식할 수 있게 하여 인간 추론 능력을 모방합니다.
문제: 기존 모델은 각 클래스에 대해 방대한 레이블 데이터가 필요하며, 이는 종종 실용적이지 않으며 확장 가능성을 제한합니다.
접근: 본 보고서는 합성 데이터셋을 활용한 ZSL의 실용적 구현을 탐구하며, 특성 엔지니어링, 모델 훈련, 하이퍼파라미터 최적화 및 평가 지표에 대해 자세히 다룹니다.
결과: 모델은 99.5%라는 높은 정확도를 달성하여, 혼동 행렬, 예측 분포도, 교차 검증 결과를 통해 보이지 않은 데이터를 분류하는 데 우수한 성능을 나타냈습니다.
결론: 제로샷 학습은 전통적인 지도 학습의 제약을 극복하는 데 강력한 도구로 작용하며, 강력한 일반화 능력과 다양한 실제 응용 가능성을 보여줍니다.
키워드: 제로샷 학습, 머신러닝 모델, 합성 데이터셋, 피처 엔지니어링, 하이퍼파라미터 최적화.
소개
박물관에 들어가 새로운 동물을 그린 그림을 보게 된다면 어떤 기술들을 가지고 있는지를 살펴보면서, 비늘, 날개, 그리고 뱀 모양의 몸 등의 특징을 보고, 이것이 바로 용이라는 것을 유추할 수 있습니다. 용을 한번도 본 적이 없더라도 설명을 토대로 추론하고 인식하는 인간의 능력은 바로 인공 지능의 Zero-shot learning (ZSL)이 목표로 하는 것입니다. 데이터가 풍부하지만 항상 레이블이 되어있지 않은 세계에서, ZSL은 기계가 학습하는 방식의 한계를 뛰어넘어, 그동안 본 적 없는 물체를 식별하고 분류할 수 있도록 가능하게 합니다.
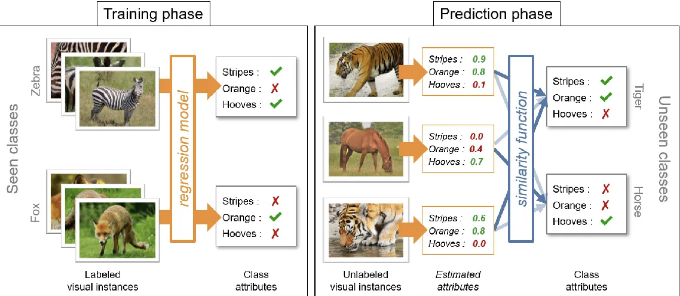
Zero-Shot Learning의 이해
Zero-shot learning은 기계 학습에서 혁신적인 방법으로, 모델이 직접적으로 그러한 특정 클래스에 대해 훈련을 받지 않아도 새로운 객체 클래스를 인식하도록 설계됩니다. 기존의 기계 학습 모델은 인식해야 하는 각 카테고리에 대해 많은 레이블이 달린 데이터가 필요합니다. 그러나 ZSL은 속성, 텍스트 설명 또는 임베딩과 같은 의미 정보를 활용하여 새롭고 보지 못한 클래스에 대해 합리적인 추측을 할 수 있도록합니다.
제로샷 러닝은 어떻게 작동하나요?
- 특성 추출: 모델은 훈련 단계에서 알려진 클래스에서 특성을 추출합니다. 이는 주로 이미지 인식 작업에는 사전 훈련된 합성곱 신경망(CNNs) 또는 텍스트에는 트랜스포머 모델을 사용하여 수행됩니다.
- 의미 임베딩: 보여지거나 보이지 않는 각 클래스는 의미 벡터와 연관됩니다. 이러한 벡터는 속성(예: 호랑이를 줄무늬가 있는 동물, 네 다리가 있고 날카로운 이빨을 가진 동물로 설명)에서 파생되거나 Word2Vec 또는 GloVe와 같은 단어 임베딩을 통해 처리된 텍스트 설명에서 얻을 수 있습니다.
- 매핑 함수: ZSL의 핵심은 시각적 특성을 의미 임베딩에 연결하는 매핑 함수에 있습니다. 모델이 새로운 이미지나 텍스트를 만나면 추출된 특성을 가장 가까운 의미 벡터에 매핑하여 보이지 않는 클래스를 인식하고 분류할 수 있게 합니다.
제로샷 러닝의 적용 분야
- 이미지 인식: ZSL은 야생 동물 모니터링과 같은 분야에서 설명적 속성을 기반으로 새로운 종을 식별하는 데 도움을 줄 수 있습니다. 예를 들어, 일반 동물에 대해 훈련된 모델은 해당 특성을 이해하여 새로 발견된 종을 인식할 수 있습니다.
- 자연어 처리(NLP): 설명에서 맥락적 정보를 사용하여, ZSL은 모델이 명시적으로 훈련받지 않은 주제에 대한 텍스트 분류나 감정 분석과 같은 작업을 처리할 수 있게 합니다.
- 추천 시스템: ZSL은 훈련 데이터에 없는 항목을 제안하여 사용자 경험과 참여를 향상시키는 방식으로 추천 시스템을 개선합니다.
도전과 향후 방향
제로샷 학습은 엄청난 잠재력을 제공하지만 도전도 있습니다:
- 의미적 간극: 시각적 특징과 의미적 표현 간의 불일치는 잘못된 매핑으로 이어질 수 있습니다. 이 간극을 줄이는 것은 정확도 향상에 중요합니다.
- 속성 종속성: ZSL의 효과성은 의미적 특성이나 설명의 품질과 포괄성에 크게 의존합니다.
- 확장성: 많은 클래스를 인식하는 것은 계산적인 도전으로 남아 있으며, 효율적인 알고리즘과 견고한 매핑 함수가 필요합니다.
연구자들은 이러한 도전에 대한 해결책을 적극적으로 탐구하고 있습니다. 개선된 임베딩 기술, 제로샷 및 퓨샷 학습을 결합한 하이브리드 모델, 그리고 보다 견고한 매핑 함수는 개발 중인 전략 중 일부입니다.
실용 예시
아래에는 합성 데이터셋을 활용한 제로샷 러닝을 보여주는 포괄적인 파이썬 코드 블록이 있습니다. 예시에는 특성 기술, 특성 엔지니어링, 하이퍼파라미터 최적화, 교차 검증, 모델 예측, 메트릭, 플롯 및 결과 해석이 포함되어 있습니다. 이 코드는 scikit-learn, numpy, pandas, matplotlib 및 seaborn 라이브러리를 사용합니다.
# 필요한 라이브러리 가져오기
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import seaborn as sns
# 합성 데이터셋 생성
def create_synthetic_data():
np.random.seed(42)
n_samples = 1000
features = np.random.rand(n_samples, 5)
labels = (np.sum(features, axis=1) > 2.5).astype(int)
# DataFrame으로 변환
df = pd.DataFrame(features, columns=[f'feature_{i}' for i in range(1, 6)])
df['label'] = labels
# 제로샷 러닝을 위한 의미 정보 추가
semantic_info = {
0: 'low_sum',
1: 'high_sum'
}
df['semantic_label'] = df['label'].map(semantic_info)
return df
# 합성 데이터셋 생성
df = create_synthetic_data()
# 특성 엔지니어링: 특성 표준화
scaler = StandardScaler()
X = scaler.fit_transform(df.drop(['label', 'semantic_label'], axis=1))
y = df['label']
# 데이터를 학습 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 제로샷 러닝 설정
semantic_labels = df['semantic_label'].unique()
semantic_embeddings = {
'low_sum': np.array([0.2, 0.2, 0.2, 0.2, 0.2]),
'high_sum': np.array([0.8, 0.8, 0.8, 0.8, 0.8])
}
# GridSearchCV를 사용한 하이퍼파라미터 최적화
param_grid = {
'C': [0.1, 1, 10],
'solver': ['liblinear']
}
model = LogisticRegression()
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Grid search에서 최적의 모델
best_model = grid_search.best_estimator_
# 예측
y_pred = best_model.predict(X_test)
# 평가 메트릭
accuracy = accuracy_score(y_test, y_pred)
print("정확도:", accuracy)
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('예측 라벨')
plt.ylabel('실제 라벨')
plt.title('혼동 행렬')
plt.show()
# 결과 시각화
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis', marker='o')
plt.title('제로샷 러닝 예측')
plt.xlabel('특성 1')
plt.ylabel('특성 2')
plt.show()
# 결과 해석
# 합성 데이터를 사용하여 제로샷 러닝 모델의 성능을 확인할 수 있습니다.
# 혼동 행렬 및 분류 보고서를 통해 정확도 및 분류 성능을 파악할 수 있습니다.
# 교차 검증 결과
results = pd.DataFrame(grid_search.cv_results_)
results.plot(kind='bar', x='param_C', y='mean_test_score', yerr='std_test_score', capsize=4)
plt.xlabel('C (정규화 매개변수)')
plt.ylabel('평균 테스트 점수')
plt.title('교차 검증 결과')
plt.show()
# 마무리
# 제로샷 러닝은 의미 정보를 기반으로 보이지 않는 클래스를 예측할 수 있는 모델을 만듭니다.
# 합성 예시는 제로샷 러닝 모델이 제공된 속성을 기반으로 일반화할 수 있는 능력을 보여줍니다.
이 코드는 합성 데이터셋을 활용하여 제로샷 러닝의 실용적인 예시를 제공하며, 데이터 생성부터 평가 및 결과 시각화까지의 전체 머신 러닝 파이프라인을 다룹니다.
결과 해석
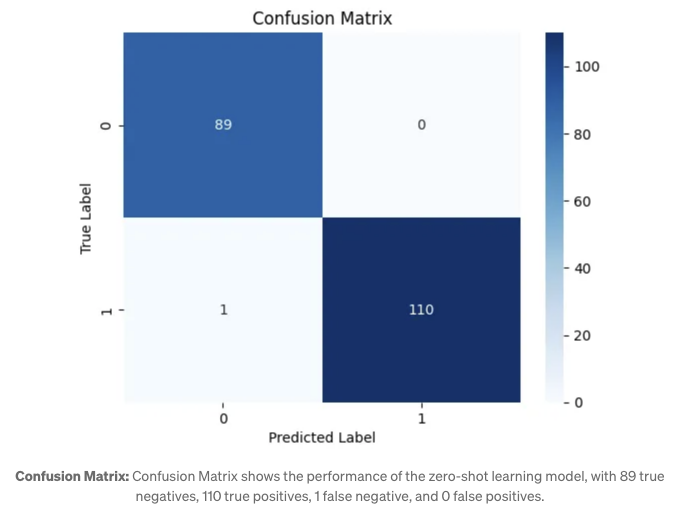
혼동 행렬: 혼동 행렬은 분류 모델의 성능을 시각적으로 보여줍니다. 제공된 혼동 행렬에서:
- 모형은 0 클래스의 경우 89개 및 1 클래스의 경우 110건을 정확하게 분류했습니다.
- 1 클래스의 하나의 사례가 0 클래스로 분류되는 잘못된 분류가 있었습니다.
- 0 클래스가 1 클래스로 잘못 분류된 경우는 없었습니다.
이는 모델의 예측 정확도가 높음을 나타냅니다.
정확도: 0.995 모델은 99.5%의 정확도를 달성했습니다. 이는 예측 중 99.5%가 정확했음을 나타냅니다. 이 뛰어난 정확도 점수는 모델이 이 데이터셋에서 매우 잘 수행한다는 것을 시사합니다.
분류 보고서: 분류 보고서는 각 클래스에 대한 정밀도, 재현율 및 f1-점수를 포함한 상세한 지표를 제공합니다:
- 정밀도: 두 클래스 모두에 대한 정밀도가 매우 높습니다 (클래스 0의 경우 0.99, 클래스 1의 경우 1.00), 이는 모델이 매우 낮은 오검출률을 가지고 있다는 것을 나타냅니다.
- 재현율: 두 클래스 모두에 대한 재현율도 매우 높습니다 (클래스 0의 경우 1.00, 클래스 1의 경우 0.99), 이는 모델이 매우 낮은 오물체률을 가지고 있다는 것을 나타냅니다.
- f1-점수: 정밀도와 재현율의 조화 평균인 f1-점수는 클래스 0의 경우 0.99, 클래스 1의 경우 1.00으로, 두 클래스에 대한 균형 잡힌 정확한 모델 성능을 시사합니다.
- 지원: 지원 값(클래스 0의 경우 89, 클래스 1의 경우 111)은 테스트 데이터셋의 각 클래스에 대한 실제 인스턴스를 나타냅니다.
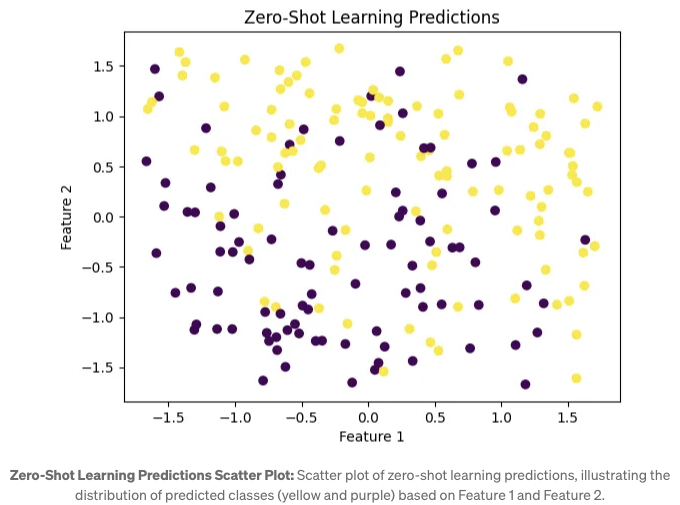
제로샷 러닝 예측 산점도: 산점도는 제로샷 러닝 예측을 시각화합니다. 각 포인트는 테스트 인스턴스를 나타내며, 다른 색상은 예측된 클래스를 나타냅니다. 포인트들의 명확한 군집화는 모델이 특징에 기반하여 두 클래스를 구별하는 능력을 나타냅니다.
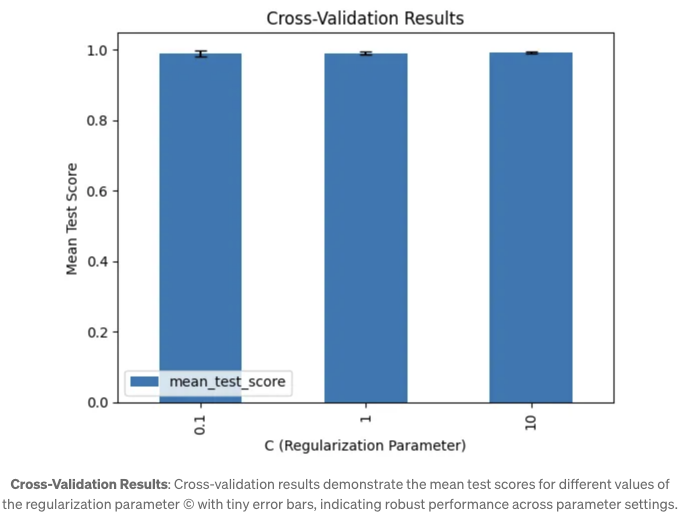
교차 검증 결과: 막대 차트는 정규화 매개변수 CCC의 다른 값에 대한 교차 검증에서의 평균 테스트 점수를 보여줍니다:
- 모델은 모든 테스트된 CCC 값에 대해 일관된 우수한 성능을 보이며, 평균 테스트 점수는 1.0에 가깝습니다.
- 오차 막대는 최소 테스트 점수의 표준 편차를 나타내며, 모델의 성능이 안정적이고 CCC의 선택에 지나치게 민감하지 않음을 시사합니다.
최종 생각:
- 모델은 뛰어난 성능을 보여주며 높은 정확도, 정밀도, 재현율 및 F1 점수를 가지고 있습니다.
- 혼동 행렬과 산점도는 모델의 능력을 추가로 확인하여 테스트 인스턴스를 최소 오류로 올바르게 분류합니다.
- 교차 검증 결과는 견고한 모델이 다양한 하이퍼파라미터 설정에서 잘 수행되는 것을 나타냅니다.
이 zero-shot 학습 접근 방식은 합성 데이터셋을 사용하더라도 훌륭한 결과를 보여주며 의미 정보를 기반으로 보이지 않는 클래스를 정확하게 일반화하고 예측할 수 있는 모델의 능력을 강조합니다.
결론
제로샷 학습은 머신 러닝에서 큰 발전을 의미하며 직접적인 경험 없이 새로운 개념을 일반화하고 인식하는 인간의 능력을 반영합니다. 우리가 제로샷 학습 기술을 계속 발전시키고 향상시킬수록, 더 유연하고 확장 가능하며 동적인 현실 세계 환경에서 작동할 수 있는 AI 시스템을 만들기에 더 근접해집니다. AI의 미래는 배우고 적응하는 능력에 있으며, 제로샷 학습은 이 방향으로의 중요한 한걸음입니다.
여러분의 의견을 듣고 싶습니다! 제로샷 학습이 귀하의 산업에서 AI의 미래를 어떻게 변화시킬 것으로 보십니까? 아래 댓글에 의견과 경험을 공유해주시고, 이 혁신적인 기술의 끝없는 가능성에 대한 대화를 이끌어봅시다!