
실무자들은 종종 모델이 데이터 집합과 얼마나 잘 맞는지를 평가하는 데 어려움을 겪습니다. 대부분의 경우 이는 여러 손실 지표를 살피는 것을 포함하거나 때로는 세분화된 지표를 살펴보는 것 또는 모델의 약점이나 편향을 식별하기 위해 예상 성능과 실제 성능을 보여주는 끝없는 차트를 살피는 것을 의미합니다.
이와 같은 작업에는 문제가 없으며, 이 모든 과정은 모델링 과정의 중요한 부분입니다. 그러나 모델 맞춤의 자연스러운 이중성인 모델 잔차를 간과하지 않는 것이 중요합니다.
모델 잔차는 모델에서 "남는 부분"으로 생각할 수 있습니다. 이론적으로 좋은 모델의 잔차는 '좋은' 모델이 모든 진짜 신호를 잡았기 때문에 무작위 잡음에 불과할 것입니다. 그러나 현실적으로 이는 항상 그렇지 않으며, 잔차는 모델 개선을 위한 통찰력을 제공할 수 있습니다. 일반적으로 인기 있는 그래디언트 부스팅 트리 모델인 XGBoost와 LightGBM은 이를 수행하여 더 나은 모델을 구축합니다.
오늘은 시계열 잔차가 어떻게 우리가 더 나은 예측 모델을 만드는 데 도움이 되는지 살펴볼 거에요.
- 먼저 실제 데이터를 활용하여 영국의 도로 교통 사고에 대한 간단한 분석을 시작할 거에요.
- 적은 양의 코딩을 통해 우리는 시계열 모델(및 잔차)을 구축하고 검토할 수 있는 기능을 얻게 될 거에요.
- 3가지 다른 모델이 어떻게 적합하게 구성되고 그들의 결점이 모델 잔차에서 강조되는지 살펴볼 거에요: 추세만을 고려한 모델은 계절적 효과를 놓치게 되고, 계절성만 고려한 모델은 추세를 놓치게 되며, 추세와 계절성을 모두 고려한 모델은 미세한 세부 사항 중 일부를 놓치게 됩니다.
시작해봐요!
추가 정보: 제가 사용하는 용어나 개념에 어색하거나 조금 녹슬었다면 아래 링크된 지원 문서들을 참고해보세요. 즐거운 독해되세요!
데이터
우리는 영국 도로 교통 사고의 월별 발생 건수를 모델링할 것입니다. 이 데이터는 사고 당 세부 정보를 제공하는 STATS19¹ 데이터입니다. 이를 월별 도로 교통 사고 발생 건수로 집계했는데, 다음과 같이 보입니다:
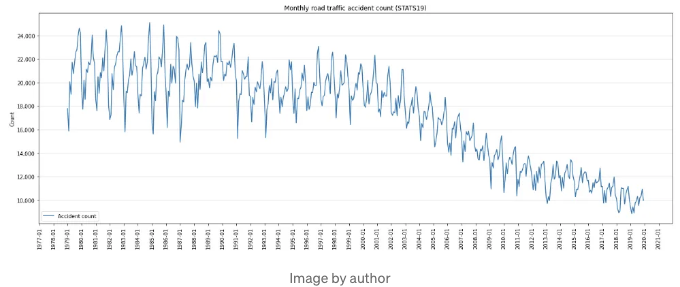
일부 중요한 점들이 있습니다:
- 데이터에서 명백한 추세가 나타나고 있습니다. 1979년부터 2000년까지는 일반적인 하향 추세가 시작되기 전에 시리즈가 상당히 안정적인 것으로 보입니다. 게다가, 2014년쯤에 하향 추세 속도 변화가 보이네요.
- 데이터에서 규칙적이고 주기적인 변동을 주목해보세요 — 강력한 계절성의 명백한 증거가 있습니다; 간단하게 말해서, 매년 1월마다 사고가 줄어드는 효과와 같이 특정 효과가 일정 주기로 반복된다는 것을 알 수 있어요.
- 계절적 변동의 크기는 추세의 크기 변화와 함께 다양해 보이며, 이 시리즈를 가장 적절하게 모델링하는 데는 곱셈 모델 구조가 맞을 수 있어요.
- 상당한 수준의 잡음 또는 무작위 변동이 보이네요. 예측할 수 없는 과정을 모델링 하고 있으며, 외부 환경 조건에 크게 영향을 받는데 이 환경 조건 자체가 변할 수 있으므로 어느 정도의 잡음이 예상된다고 합니다(예: 영국 날씨!).
이제, 간단한 코딩을 해볼게요.
산타의 작은 도우미(함수)
작은 모델을 구축하고 모델 맞춤 및 모델 잔차를 그래픽으로 표시하기 위한 함수를 만들어 보죠. 아래와 같은 형태를 가집니다:
def fit_and_visualise_model(
X, y, time_index,
title_fit='월간 도로 교통사고 건수 (STATS19)',
title_resid='상대 잔차'):
# 여기에 모델을 작성하세요
scaler = MinMaxScaler()
scaler.fit(X)
model = LassoCV(max_iter=2_500)
model.fit(scaler.transform(X), np.log(y.values))
# 예측 및 잔차
preds = np.exp(model.predict(scaler.transform(X)))
resids = y.values / preds
# 적합도 시각화
fig,ax = plt.subplots(figsize = (22,7.5))
plt.plot(
time_index, y,
label='실제값', color='lightgrey',
linewidth=2, alpha=0.45)
plt.plot(
time_index, preds,
label='예측값', color='tab:orange',
linewidth=2)
plt.gca().xaxis.set_major_locator(
mdate.MonthLocator(bymonth=[1]))
plt.xticks(rotation=90)
plt.gca().yaxis.set_major_formatter(
mtick.StrMethodFormatter('{x:,.0f}'))
plt.grid(axis='y', which='major', alpha=0.5)
plt.legend(loc = 'lower left')
plt.title(title_fit)
plt.ylabel('건수')
plt.show()
# 잔차 시각화
fig,ax = plt.subplots(figsize = (22,7.5))
plt.scatter(time_index, resids, color='lightgrey')
plt.axhline(1, color='red')
plt.gca().xaxis.set_major_locator(mdate.MonthLocator(bymonth=[1]))
plt.xticks(rotation=90)
plt.grid(axis='y', which='major', alpha=0.5)
plt.title(title_resid)
plt.ylabel('잔차')
plt.show();
너무 복잡하지 않지만 유용한 기능이에요.
트렌드를 따라가기
시계열 데이터의 추세만을 포착하는 모델을 구축해보겠어요.
아래의 차트는 우리가 원하는 것과 정확히 일치하는 것처럼 보이는데요. 하지만 시계열 데이터에는 상당한 계절성이 있고, 모델에 전혀 고려하지 않았기 때문에 실제로 그런지 알 수 없습니다. 모델 residual을 더 자세히 살펴보겠습니다. 지난 5년 동안의 정보를 확대해서 살펴보겠습니다:
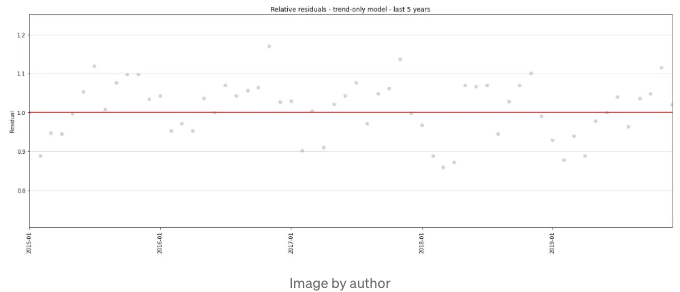
잔차에서 파도 모양 패턴을 눈치채셨나요? 패턴이 규칙적이고 주기적임을 볼 수 있으며, 무작위 변동이 몇 개 있는 것을 빼면요. 이것이 모델에서 포착되지 않는 계절성 신호입니다. 더 나은 모델은 이 계절성을 포착해 틈을 메울 것입니다.
모든 계절을 위한 모델
이제 시계열의 계절성만을 포착하는 모델을 구축해 봅시다.
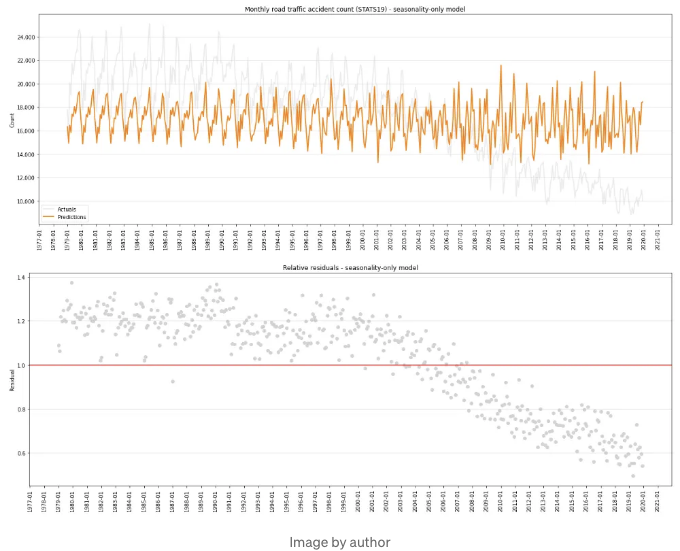
가장 강력한 계절 모델은 아니지만, 훈련 기간 끝에서 예측이 조금 엉뚱해 보이는 점을 무시한다면, 모델이 일반적으로 반복적인 계절 효과를 잘 포착한다는 것을 볼 수 있습니다.
지금쯤이면 모델이 거대한 추세 효과를 놓치고 있다는 것을 잘 알기 때문에 잔차를 살펴볼 필요가 없을 것 같지만, 아래 차트가 바로 그겁니다.
모든 중요한 점들을 고려해야 합니다.
이제 이를 마저 처리하고, 추세 및 계절성 효과를 모두 포함한 모델을 적합해 봅시다. 우리가 예상한 대로 결과 (그리고 잔차)가 훨씬 더 잘 작동하여, 이 모델이 데이터에서 진짜 신호를 더 많이 포착했다는 것을 보여줍니다.
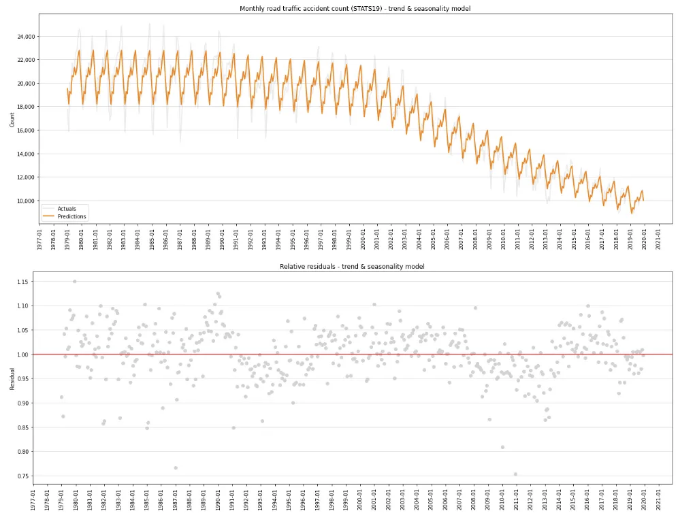
잔차에 여전히 패턴이 보이는 것을 주목하세요. 세 가지 구분 시기로 보이는 것: 1994년 이전, 1994년~2008년, 2008년부터.
완벽하지는 않지만, 모델이기 때문에 꽤 괜찮은 수준입니다.
감싸고 어슬렁어슬렁
자세한 내용을 이야기하기 전에 간단히 요약해 볼까요?
마무리
모델 잔차가 모델을 개선하는 데 어떻게 도움이 되는지 살펴봤습니다. 이번에는 월별 영국 교통사고를 예측하기 위한 간단한 모델을 만들었습니다.
시계열에서 계절성을 캡처하지 못한 경향 모델이 어떻게 실패했는지, 그리고 이 결점이 모델 잔차에서 파형 신호로 나타났는지 보았습니다. 반면에 계절성 전용 모델은 잔차에서 명확한 추세를 보여주었습니다. 그리고 추세와 계절성 모델은 성능이 좋게 향상되었지만 아직 개선할 여지가 있습니다.
"좋은" 모델의 잔차는 어떻게 보이나요?
답은 — 약간 귀찮게 — 상황에 따라 다릅니다. 일반적으로, 곱셈(가산) 모델의 경우 잔차는 1(또는 0) 주변에 무작위 노이즈와 같이 보여야 합니다. 잔차에 일관된 패턴이 없어야 하며, 모두 좁고 유한한 범위에 있어야 합니다.
우리가 앞에서 본 것처럼, 패턴은 모델의 결점을 나타낼 수 있습니다. 특히 주의해야 할 패턴 중 하나는 이분산성 또는 분산의 변동이며, 이는 통계적 유의성 검정을 무효화시키는 큰 문제입니다⁵.
시계열 모델을 위한 피처 엔지니어링
저는 위에 언급된 각 모델이 어떻게 구축되었는지 대략적으로 살펴봤어요. 이 내용은 다른 글에서 자세히 다루었지만, 비밀은 간단해요: Lasso 모델에 입력하는 피처를 변경하세요. 계절성만 고려한 모델이 필요하다면, 회귀 모델에 계절성 피처만 사용하세요. 트렌드만 고려한 모델도 동일한 방법이 적용돼요.
우리는 종종 적합하지 않은 모델이나 모델 잔차 패턴에서 벗어날 수 있어요. 트렌드와 계절성을 모두 포함했을 때 모델이 얼마나 개선되는지 확인해보세요. 가끔 모델이 필요로 하는 것이 명확하지 않을 수 있으니, 측면적 사고와 시행착오에 대비해야 해요.
이미 세 가지 주요 시기를 식별했기 때문에 최종 모델이 완벽하지는 않다는 것은 분명해요. 모델을 개선할 빠른 방법이 있을 수 있어요: 몇 개의 변곡점을 추가하거나 피처 간 상호작용을 포함하는 것이 높은 확률로 효과를 볼 수 있어요. 예를 들어, 지표 피처를 추가하면 1994년 이전의 시기의 모델 적합도가 향상될 수 있어요. 이를 통해 이 기간에 적용된 계절성을 효율적으로 조절함으로써 모델 잔차를 축소할 수 있어요.
여기까지! 이 글까지 읽어주셔서 감사합니다.
만약 이 글을 즐겼고 제 더 많은 이야기들을 보고 싶다면, 여기를 한 번 봐주세요:
다음 시간에 뵙겠습니다.
참고 자료와 유용한 자원들
- Open Government Licence을(를) 사용한 자료 (nationalarchives.gov.uk)
- 시계열(time series) 구성 요소 및 모델 구조: 시계열 분해에 대한 포괄적 가이드 | Towards AI
- 시계열 회귀 모델을 위한 특성 구축: False Prophet: Feature Engineering for Time Series | Towards Data Science
- False Prophet: 시계열 회귀 모델 | Towards Data Science는 이 글에서 사용된 모델 구조와 유사한 회귀 모델에 대한 자세한 내용을 다룹니다.
- 동분산성 및 이분산성 — 위키백과
친절한 한국어 번역 🚀
In Plain English 커뮤니티에 참여해 주셔서 감사합니다! 다음에 가시기 전에:
- 글쓴이를 칭찬하고 팔로우해 주세요 ️👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | 뉴스레터
- 다른 플랫폼 방문하기: Stackademic | CoFeed | Venture | Cubed
- PlainEnglish.io에서 더 많은 콘텐츠를 만나보세요