이 게시물은 Rafael Guedes와 공저한 것입니다.
소개
예측은 학술 연구 및 산업 응용 분야에서 인공지능(AI)의 핵심 영역 중 하나입니다. 실제로, 이는 모든 산업에 걸쳐 찾아볼 수 있는 가장 보편적인 도전 중 하나일 것입니다. 미래 매출량 및 시장 동향을 정확하게 예측하는 것은 기업이 계획 프로세스를 최적화하기 위해 꼭 필요합니다. 이는 이윤 기여를 향상시키고 낭비를 최소화하며 충분한 재고 수준을 보장하고 공급망 최적화 및 전체 의사 결정을 개선하는 것을 포함합니다.
예측 모델을 개발하는 것은 복잡하고 다면적인 도전입니다. 이는 최첨단(STATE-OF-THE-ART, SOTA) 예측 방법론과 적용 대상인 특정 비즈니스 분야에 대한 깊은 이해를 요구합니다. 또한, 예측 엔진은 기관 내에서 폭넓은 프로세스를 지원하는 중요한 인프라 역할을 할 것입니다. 예를 들어:
- 마케팅 팀은 모델을 활용하여 다가오는 기간에 대한 투자 할당에 관한 전략적 의사 결정을 진행합니다. 예를 들어, 다음 달이나 분기에 대한 투자 배정에 대한 결정을 내립니다.
- 구매 팀은 공급 업체로부터의 매입 수량과 타이밍에 관한 정보에 기초하여 재고 수준을 최적화하고 낭비나 부족을 줄이기 위해 모델을 활용합니다.
- 운영 팀은 예측을 활용하여 생산 라인을 최적화합니다. 예상 수요를 충족시키기 위해 자원과 인력을 효율적으로 투입하면서 운영 비용을 최소화합니다.
- 재무 팀은 예산 및 리소스 할당을 위해 모델을 신뢰합니다. 예측 데이터를 활용하여 월별 금융 요구 사항을 예측하고 그에 맞게 자원을 할당합니다.
- 고객 서비스 팀은 예측을 활용하여 고객 조회량을 예상하며, 고품질의 고객 서비스를 유지하고 대기 시간을 최소화하면서 적정 직원 수를 조정할 수 있습니다.
최근 예측 분야의 발전은 텍스트 (예: ChatGPT), 텍스트-이미지 (예: Midjourney) 및 텍스트-음성 (예: Eleven Labs) 등 여러 도메인에서 기초 모델의 성공적인 개발에 의해 형성되었습니다. 이러한 모델들의 널리 퍼짐으로 인해 이전에 본적이 없던 데이터에 대한 예측을 생성하도록 설계된 TimeGPT [1]와 같은 모델들이 등장했습니다. 이러한 모델들은 텍스트, 이미지 및 음성 분야의 선례를 따르는 방법론과 아키텍처를 활용합니다. 일반적인 사전 훈련된 모델은 예측 작업에 대해 패러다임 변화를 가져올 것입니다. 조직에게 더 접근 가능하게 만들어줄 뿐만 아니라, 계산 복잡성을 줄이고 전반적으로 더 정확하게 만들 것입니다.
이 글에서는 TimeGPT의 가능한 아키텍처에 대해 깊이 있는 설명을 제공합니다. 또한 모델이 제로샷 추론을 수행할 수 있도록 하는 주요 구성 요소를 다룹니다. 이론적 개요를 따라 특정 사용 사례와 데이터셋에 TimeGPT를 적용합니다. 구체적인 구현 세부사항을 다루고 모델 성능을 철저히 분석합니다. 마지막으로 TimeGPT와 TiDE [2]의 성능을 비교하여, 간단한 MLP인 TiDE가 예측 사용 사례에서 Transformer를 이기는 것을 보여줍니다.

항상 코드는 저희의 GitHub에서 확인하실 수 있어요.
TimeGPT
TimeGPT [1]는 시계열 예측을 위한 최초의 기초 모델로, 다양한 도메인을 범위로 일반화할 수 있는 능력으로 특징화되어 있어요. 훈련 단계에서 사용된 데이터 이외의 데이터셋에서도 정확한 예측을 할 수 있어요. 시계열 예측을 위한 기초 모델에 대한 연구 분야는 최근에 크게 성장하고 있어요. 카네기 멜론 대학교(CMU)의 연구자들이 개발한 "MOMENT"[3], Google의 "TimesFM"[4], Morgan Stanley와 ServiceNow의 공동 연구인 "Lag-Llama"[5], 그리고 Salesforce의 "Moirai"[6]와 같은 주목할 만한 최근 작업이 있어요. 앞으로 다른 시계열 예측을 위한 기초 모델들에 대해서도 다룰 계획이에요.
TimeGPT는 제로샷 추론 설정에서 우수한 성능을 발휘하기 위해 전이 학습을 활용하고 있어요. 경제, 인구 통계, 의료, 날씨, IoT 센서 데이터, 에너지, 웹 트래픽, 판매, 운송 및 은행 업무 등 다양한 도메인의 대중적으로 제공되는 데이터셋에서 1000억 개의 데이터 포인트를 사용해 훈련되었어요.
다양한 도메인의 폭넓은 다양성 덕분에 이 모델은 여러 계절성, 다양한 길이의 주기, 그리고 변화하는 추세와 같은 복잡한 패턴을 잡을 수 있어요. 게다가 데이터셋은 다양한 노이즈 수준, 이상값, 드리프트, 그리고 기타 다양한 특징을 보여줘요. 일부는 규칙적인 패턴이 있는 깨끗한 데이터로 이루어져 있고, 다른 일부는 시간이 흐름에 따라 추세와 패턴이 변동될 수 있는 예상치 못한 사건과 행동을 포함하고 있어요. 이러한 도전들은 모델이 배울 수 있는 많은 시나리오를 제공하여 모델의 견고성과 일반화 능력을 향상시켜요.
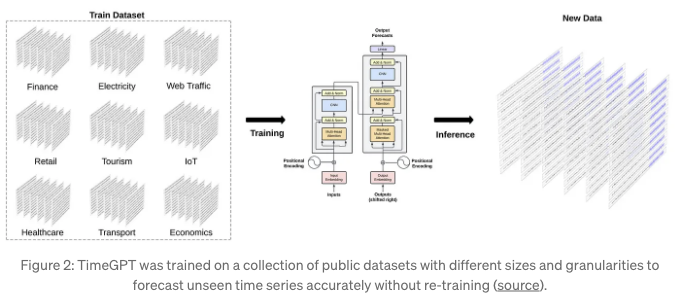
아키텍처
TimeGPT는 시계열 예측을 위해 특별히 설계된 Transformer 기반 모델로, 인코더-디코더 아키텍처 내부에 self-attention 메커니즘을 통합하고 있어요. self-attention 메커니즘을 활용하여 시계열 내에서 서로 다른 지점의 중요성을 동적으로 가중할 수 있어요.
모델은 입력으로 과거 값(y)과 외생 공변럇(x)의 창을 받습니다. 공변럇에는 추가 시계열 데이터 및/또는 특정 이벤트를 나타내는 이진 변수가 포함될 수 있습니다. 이러한 입력은 지역 위치 임베딩을 통해 순차 정보로 보강됩니다. 이를 통해 모델은 시간 의존성을 인식할 수 있습니다. 저자들이 명시적으로 언급하지는 않았지만, 모든 입력이 위치 인코딩 후 연결된다고 가정하며, 이는 인코더에 공급되는 최종 입력을 생성합니다.
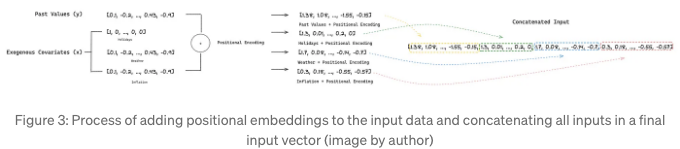
위치 인코딩은 또한 저자들에 의해 정의되지 않았습니다. 우리는 이들이 기초 변환자 아키텍처 논문의 삼각 함수를 사용한다고 가정합니다. 이러한 함수는 다양한 주파수로 특징 지어지지만 입력 데이터와 동일한 차원을 유지합니다.
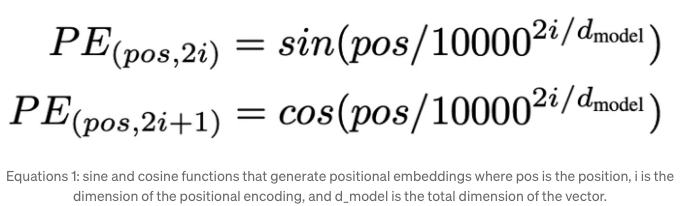
위치 인코딩과 함께 보강된 입력 벡터는 인코더에 소개됩니다. 인코더 내에서 다중 헤드 어텐션 레이어는 입력 시퀀스 내의 다양한 요소에 가중치를 평가하고 할당하여 그들의 상대적 중요성을 반영합니다. 이 representatino은 이후 완전 연결된 피드 포워드 네트워크에 의해 처리됩니다. 이것은 시퀀스 내 요소들 간의 더 복잡한 관계를 포착하는 representatino을 생성하는 것을 가능하게 합니다. 그런 다음 출력은 아키텍처의 디코더 부분으로 전달됩니다.
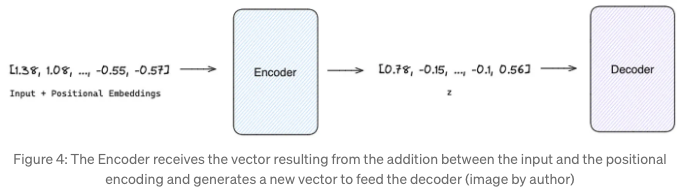
인코더의 출력을 처리하는 것 외에도 디코더는 자기 회귀적인 프로세스에서 작동합니다. 이전에 생성된 출력을 통합하여 다음 시간 단계(i+1)의 예측을 생성하기 전에 작동합니다. 이것은 인코더에 의해 생성된 숨겨진 상태들과 이전에 생성된 출력 간의 복잡한 관계를 포착하기 위해 주의 메커니즘을 활용합니다. 이 접근 방식은 디코더가 인코더의 representatino에 포착된 문맥적 및 순차적 정보를 자체 반복적인 예측과 함께 효과적으로 종합할 수 있도록 합니다.
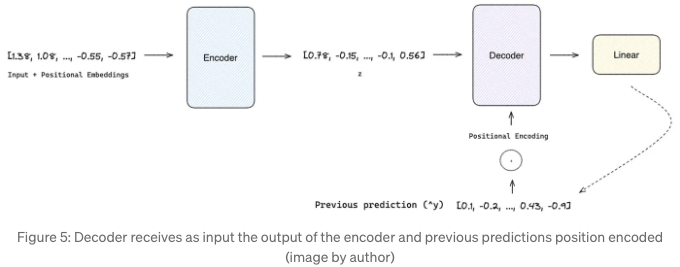
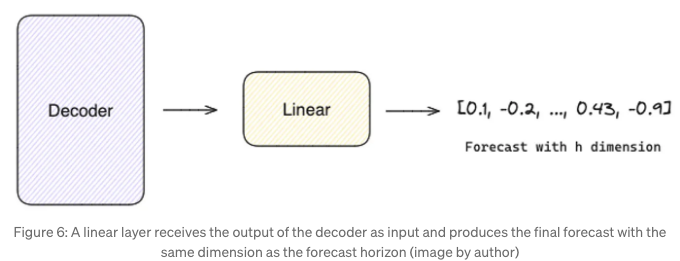
마지막으로, 선형 레이어는 디코더의 출력을 예측 지향의 길이와 동일한 값 벡터로 매핑하는 역할을 합니다.
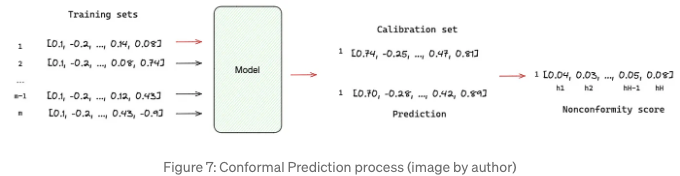
TimeGPT는 잠재적 결과물의 확률 분포를 생성할 수 있습니다. 다시 말해, 예측 간격의 추정입니다. 저자들은 기존 오류를 기반으로 하는 조화 예측을 사용하여 예측 간격을 추정했습니다. 전통적인 방법과 달리, 조화 예측은 분포 가정이 필요하지 않으며 다음과 같은 방법으로 수행할 수 있습니다:
- M개의 교육 및 보정 세트 생성;
- 각 보정 세트를 모델로 예측;
- 각 예측 시점 h에 대해 모델의 예측 값과 보정 세트 내 실제 결과 간의 절대 잔차 값이 계산됩니다. 이러한 계산된 잔차는 비준수 점수라고 불립니다.
- 각 예측 시점 h의 비준수 점수의 분포에서 특정 백분위수를 선택합니다. 선택한 백분위수는 예측 간격의 커버리지 수준을 결정하며, 더 높은 백분위수는 더 넓은 간격을 의미합니다.
예측 간격은 예측 값 ± 최종 비준수 점수로 제공됩니다.
TimeGPT 대 TiDE: 실제 사용 사례에서의 비교
이 섹션에서는 고객 중 한 명의 실제 데이터셋을 사용하여 시간 GPT를 사용하여 매출을 예측하겠습니다. 이후 동일한 분석을 위해 TiDE와 TimeGPT의 예측 성능을 비교합니다.
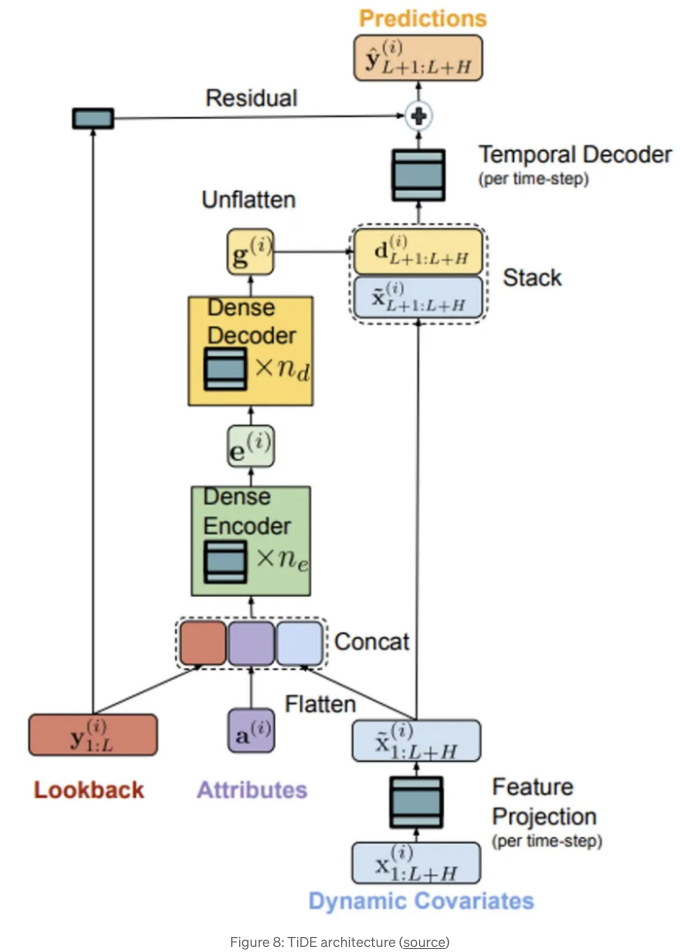
TiDE [2]은 새로운 다변량 시계열 모델로, 정적 공변럇수(예: 제품 브랜드) 및 예측 기간 동안(예: 제품 가격) 알려진 또는 알려지지 않은 동적 공변럇수를 사용하여 정확한 예측을 생성할 수 있습니다. 복잡한 Transformer 아키텍처와는 달리, TiDE는 간단한 인코더-디코더 아키텍처와 잔차 연결을 기반으로 합니다:
- 인코더는 과거 타겟 값 및 시계열의 공변럇수를 특성의 밀집 표현으로 매핑하는 역할을 합니다. 먼저 특성 프로젝션을 통해 동적 공변럇수의 차원을 줄입니다. 그런 다음, 밀집 인코더는 특성 프로젝션의 출력과 정적 공변럇수 및 과거 값이 연결된 것을 받아 하나의 임베딩 표현으로 매핑합니다.
- 디코더는 임베딩 표현을 받아 미래 예측으로 변환합니다. 밀집 디코더는 임베딩 표현을 시간당 하나의 벡터로 매핑합니다. 그 후, 시계열 디코더는 밀집 디코더의 출력을 해당 시간 단계의 특성 프로젝션과 결합하여 예측을 생성합니다.
- 마지막으로, 잔차 연결은 과거 값을 예측 기간 크기의 벡터로 선형 매핑하여 이를 시간적 디코더의 출력에 추가하여 최종 예측을 생성합니다.
데이터셋에는 미국 시장을 위한 주간 매출 데이터를 상세히 설명하는 195가지 고유한 시계열이 포함되어 있습니다. 역사적인 매출 데이터 외에도, 데이터셋에는 미국 법정 공휴일 및 이진 계절 특성 정보도 있습니다. 우리는 이 데이터셋을 보강하기 위해 이벤트 주(week)와 달(month) 식별자를 사용했습니다. 예측 기간은 16주로, 즉 미래 16주를 예측하고자 합니다.
친구야, 아래와 같이 라이브러리를 가져오는 것으로 시작해요:
import matplotlib.pyplot as plt
import os
import pandas as pd
import utils
from nixtlats import TimeGPT
from nixtlats.date_features import CountryHolidays
from dotenv import load_dotenv
from sklearn.preprocessing import MinMaxScaler, OrdinalEncoder
load_dotenv()
다음으로, TimeGPT 클래스를 초기화해요. TimeGPT 토큰을 제공하여 시작해요. Nixtla 웹사이트에서 요청하실 수 있어요.
timegpt = TimeGPT(token=os.environ.get("TIMEGPT_KEY"))
timegpt.validate_token()
데이터셋을 로드하기 전에 인증 토큰을 확인한 후 다음을 확인해 주세요:
- 대상 변수는 숫자이어야 하며 결측값이 없어야 합니다.
- 시작일부터 종료일까지의 날짜 순서에 빈 공간이 없는지 확인하세요.
- 날짜 열은 Pandas에서 인식할 수 있는 형식이어야 합니다.
- 문서에 따르면 데이터 정규화는 내부에서 처리되므로 해당 단계를 건너뛰어도 됩니다.
- 여러 시계열을 예측하는 경우 각 시리즈를 고유하게 식별할 수 있는 열을 포함해야 하며, 이는 예측 함수에서 인수로 사용됩니다.
- 외생적 특성이 필요한 경우 예측 기간을 위한 별도의 데이터셋이 필요합니다.
# 데이터 프레임 읽고 날짜를 datetime으로 파싱
df = pd.read_csv('data/data.csv', parse_dates=['delivery_week'])
토론한 바와 같이 데이터셋을 보강하기 위해 주간과 월간의 이진 계절성 특성을 추가합니다:
# df에 주차(week)와 달(month)을 추가합니다.
df['week'] = df['delivery_week'].dt.isocalendar().week
df['month'] = df['delivery_week'].dt.month
# 주차(week)와 달(month)을 원핫인코딩합니다.
df = pd.get_dummies(df, columns=['week', 'month'], dtype=int)
이제 TimeGPT가 예측에 사용할 데이터셋을 만들 준비가 되었습니다. 추가로, 예측 기간 내의 실제 매출 데이터와 해당 기간에 대한 외생 변수 특성을 포함하는 홀드아웃(holdout) 세트를 만들 것입니다.
# 데이터 프레임을 자릅니다.
forecast_df = df[df['delivery_week'] < "2023-10-16"]
# 홀드아웃(holdout) 세트를 위해 실제 매출 데이터 중 마지막 x 주를 사용합니다.
holdout_df = df[(df['delivery_week'] >= "2023-10-16") & (df['delivery_week'] <= "2024-02-05")]
데이터를 분리한 후, 훈련 및 홀드아웃 데이터셋을 forecast() 함수로 넘겨 예측할 수 있습니다. 다음 매개변수를 설정해야합니다:
- df - 과거 데이터가 포함된 데이터 프레임입니다.
- time_col - 시간 정보가 들어 있는 열입니다.
- target_col - 과거 데이터가 들어 있는 열입니다.
- X_df - 예측 기간을 위한 외생특징이 포함된 데이터 프레임입니다.
- date_features - 미국의 공휴일과 같은 새로운 외생 특징의 지정을 허용합니다.
- h - 예측 기간을 정의합니다.
- level - 예측 간격 (80% 신뢰 구간)입니다.
- freq - 데이터의 주기입니다. 우리의 경우 매주 월요일마다 발생합니다.
- id_col - 다변량 시나리오에서 각 시계열을 식별하는 열입니다.
- model - TimeGPT에는 단기용과 장기용으로 두 가지 모델이 있습니다. 예측 기간에 계절 주기가 하나 이상인 경우 장기용을 사용해야 합니다.
- add_history - 과거 데이터의 적합 값이 반환됩니다.
# 계절적 외부 요인이 포함된 목록 생성
EXOGENOUS_FAETURES = [x for x in df.columns if ('week_' in x) | ('month_' in x)]
timegpt_fcst_ex_vars_df = timegpt.forecast(
df=forecast_df[['unique_id', 'delivery_week', 'target', 'marketing_events_1', 'marketing_events_2']+EXOGENOUS_FAETURES],
time_col='delivery_week',
target_col='target',
X_df=holdout_df[['unique_id', 'delivery_week', 'marketing_events_1', 'marketing_events_2']+EXOGENOUS_FAETURES],
date_features=[CountryHolidays(['US'])],
h=17,
level=[80],
freq='W-MON',
id_col='unique_id',
model='timegpt-1',
add_history=True,
)
예측은 몇 분 안에 실행됩니다. 그런 다음, 과거 데이터에 대한 적합 값과 예측 값을 포함하는 데이터 프레임이 반환됩니다. 또한 예측에서 외생 교란 변수의 중요성도 반환됩니다.
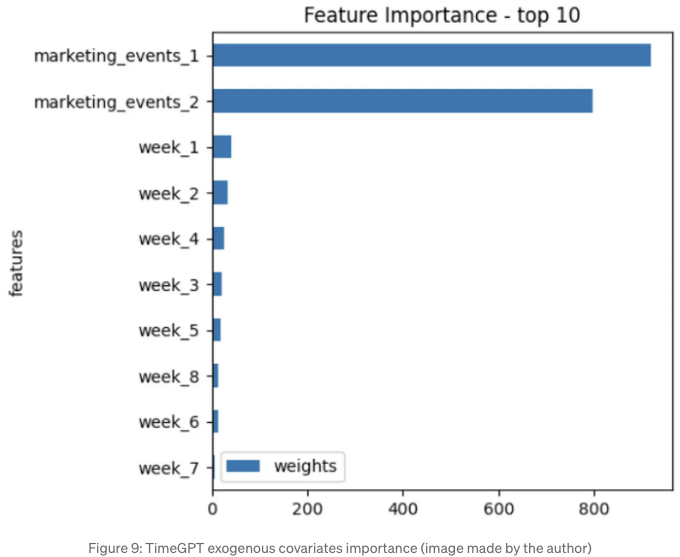
timegpt.weights_x.head(10).sort_values(by='weights').plot.barh(x='features', y='weights')
plt.title('특징 중요도 - 상위 10개')
plt.show()
우리는 경우에 가장 중요한 10가지 공변럇값을 추출했는데, 그 중에서 마케팅 이벤트가 가장 중요함을 나타냅니다. 반대로, 계절별 및 휴일 공변랇값은 잔여적인 중요성을 가지고 있습니다.
add_history=True로 설정했기 때문에 적합값과 예측을 플롯할 수 있습니다. 홀드아웃 세트에서 볼륨이 가장 높은 6개의 시리즈를 선택했습니다. 이들은 비즈니스에 더 관련이 있고 더 안정적인 패턴으로 예측하기가 더 쉬울 것입니다.
# 볼륨에 따라 정렬된 시리즈 가져오기
series = holdout_df.groupby('unique_id')['target'].sum().reset_index().sort_values(by='target', ascending=False)['unique_id'].tolist()
timegpt.plot(
forecast_df[['unique_id', 'delivery_week', 'target']],
timegpt_fcst_ex_vars_df,
time_col='delivery_week',
target_col='target',
unique_ids=series[:6],
level=[80],
)
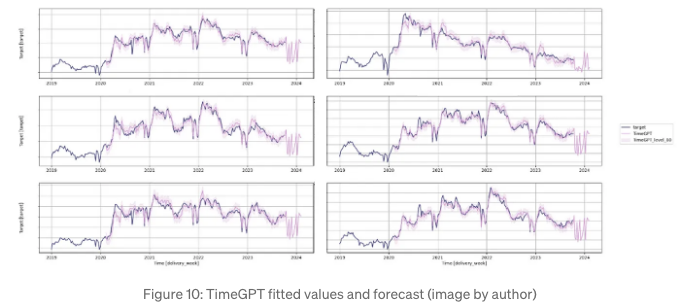
Figure 10을 보면 적합 값이 실제 값과 잘 일치하지만 예측은 일관성이 없습니다. 하나의 경우를 제외하고 대부분의 시계열에서 균일한 패턴을 보여줍니다 (우측 상단에서 확인할 수 있습니다). 또한, 모든 예측에는 우리가 기대하지 않았던 연이은 예상치 이상의 증가가 있습니다.
TimeGPT에서 예측을 얻은 후 TiDE에서 생성된 예측을 로드하고 비교를 위해 예측 성능 지표를 계산할 수 있습니다. 비교 메트릭으로 실제 판매량을 유지하기 위해 평균 절대 백분율 오차(MAPE)를 사용했습니다.
# TiDE와 TimeGPT에서 예측 로드
tide_model_df = pd.read_csv('data/tide.csv', parse_dates=['delivery_week'])
timegpt_fcst_ex_vars_df = pd.read_csv('data/timegpt.csv', parse_dates=['delivery_week'])
# TiDE 예측 및 실제 값을 병합하는 데이터 프레임
model_eval_df = pd.merge(holdout_df[['unique_id', 'delivery_week', 'target']], tide_model_df[['unique_id', 'delivery_week', 'forecast']], on=['unique_id', 'delivery_week'], how='inner')
# TimeGPT 예측 및 실제 값을 병합하는 데이터 프레임
model_eval_df = pd.merge(model_eval_df, timegpt_fcst_ex_vars_df[['unique_id', 'delivery_week', 'TimeGPT']], on=['unique_id', 'delivery_week'], how='inner')
utils.plot_model_comparison(model_eval_df)
다음은 Figure 11에 표시된 것과 같습니다. TiDE는 16주 중 15주에 대해 195개의 시계열을 비교할 때 TimeGPT에 비해 평균 MAPE가 낮습니다. 두 모델 모두 동일한 정보에 액세스할 수 있지만, TimeGPT의 제로-숏 추론은 저희가 세밀하게 조정한 모델을 이기지 못했습니다.
결론
오늘날의 경쟁적인 환경에서 예측의 중요성은 과대평가될 수 없습니다. 효과적인 예측 방법은 운영 우수성을 추구하는 조직에게 중요하며, 이를 통해 운영을 더 효율적으로 계획하고 관리할 수 있습니다.
이 기사에서는 시계열 예측의 최신 혁신 중 하나 인 foundation models의 발전을 탐구했습니다. 이러한 모델은 전문 지식이 부족한 기관들이 내부에서 SOTA 모델을 개발하는 데 필요한 특수 지식을 갖추지 못한 경우에도 정교한 알고리즘에 대한 접근을 민주화하기 위해 노력하고 있습니다. 이러한 노력은 유망해 보이지만, 우리의 분석에서는 여전히 정확한 예측을 제공하는 데 실패하는 것으로 나타났습니다. 구체적으로, TiDE가 zero-shot 추론 시나리오에서 TimeGPT를 크게 능가했습니다.
그럼에도 불구하고, AI 기업들이 예측의 경계를 넓히기 위해 노력하는 것을 보는 것은 격려되는 일입니다. 컴퓨터 비전 및 NLP와 같은 다른 도메인이 더 많은 관심을 받고 있지만, 기관들에게 있어서 예측의 중요성을 간과해서는 안 됩니다.
나에 대해
AI 분야의 시리얼 창업가이자 리더. 기업을 위한 AI 제품을 개발하고 AI 중심 스타트업에 투자합니다.
창업자 @ ZAAI | LinkedIn | X/Twitter
참고 자료
[1] Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. arXiv:2310.03589에서 검색됨.
[2] Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan Mathur, Rajat Sen, Rose Yu. (2023) TiDE를 활용한 장기 예측: Time-series Dense Encoder. arXiv:2304.08424.
[3] 고스와미, M., 살페르, K., 쵸우드리, A., 카이, Y., 리, S., & 더브라우스키, A. (2024). MOMENT: 개방형 시계열 기반 모델 패밀리. arXiv:2402.03885 (cs.LG)에서 가져옴.
[4] 다스, A., 콩, W., 센, R., & 조우, Y. (2024). 시계열 예측을 위한 디코더 전용 기반 모델. arXiv:2310.10688 (cs.CL)에서 가져옴.
[5] 라술, K., 아쇼크, A., 윌리엄스, A. R., 고니아, H., 바그와트카르, R., 코라사니, A., 다르비시 바이아지, M. J., 아다모푸로스, G., 리아치, R., 하센, N., 비로스, M., 가르그, S., 슈나이더, A., 채파도스, N., 드루앵, A., 잔테데케시, V., 네우미바카, Y., & 리시, I. (2024). Lag-Llama: 확률적 시계열 예측을 위한 기반 모델로. arXiv:2310.08278 (cs.LG)에서 가져옴.
[6] 우, G., 리우, C., 쿠마르, A., 씨옹, C., 사바레세, S., & 사후, D. (2024). 통합된 유니버설 시계열 예측 트랜스포머의 훈련. arXiv:2402.02592 (cs.LG)에서 가져옴.
[7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv:1706.03762에서 가져옴.
[8] Stankeviciute, K., Alaa, A. M., & van der Schaar, M. (2021). Conformal time-series forecasting. Advances in Neural Information Processing Systems (Vol. 34, pp. 6216–6228)에 소개됨.