기계 학습에서 쌓기의 힘을 발견해보세요. 이 기술은 여러 모델을 하나로 결합하여 강력한 예측기로 만드는 기법입니다. 이 기사에서는 쌓기의 기초부터 고급 기술까지 살펴보고, 다양한 모델의 장점을 결합하여 정확성을 향상시키는 방법을 소개합니다. 쌓기에 익숙하지 않은 분들이나 최적화 전략을 찾고 계신 분들을 위해, scikit-learn을 활용하여 예측 모델링을 높이는 실용적인 통찰과 팁을 제공합니다.
이 기사는 scikit-learn을 바탕으로 작성되었지만, scikit-learn의 쌓기 모델을 구현하고 모방하는 순수한 Python 클래스를 제공합니다. 이 순수한 Python 구현을 검토하는 것은 여러분의 이해도를 확인하고 테스트하는 데 훌륭한 방법입니다.
이 게시물에서는 다음을 확인하게 됩니다:
- 쌓기가 머신러닝의 앙상블 기법 중 일부인지
- 쌓기가 예측을 제공하기 위해 내부적으로 어떻게 작동하는지
- 쌓기가 어떻게 fitting되는지
- “리스택”이 무엇인지
- 다층 쌓기를 어떻게 생성할 수 있는지
- 왜 기본 모델의 성능을 검사해야 하는지
- 스택 모델의 사용을 조정하고 최적화하는 방법
"테이블" 태그를 마크다운 형식으로 변경해주세요.
"’베이스 모델’이라 함은 만날 수 있는 모든 전통적인 모델을 의미합니다 - scikit-learn에서 직접 가져와 학습하고 예측할 수 있는 모델입니다. 이러한 베이스 모델은 예를 들어 다음과 같습니다:
- 선형 회귀나 로지스틱 회귀 (및 이들의 변형인 LASSO 또는 리지)
- 서포트 벡터 회귀 또는 분류기
- 의사결정 트리 회귀 또는 분류기
- K-최근접 이웃 회귀 또는 분류기
각각의 이 모델들은 장단점이 있고, 하이퍼파라미터들이 있으며, ‘편안한’ 영역이 있습니다. 따라서, 이 모델들은 여러분의 머신러닝 문제에서 서로 다르게 수행할 수 있습니다: 데이터셋 전체에서 다른 점수를 가질 뿐만 아니라, 데이터셋의 일부 샘플/영역에서는 더 나은 성능을 발휘할 수도 있고, 다른 곳에서는 더 나쁠 수도 있습니다.
앙상블 방법의 일반적인 아이디어는 여러 이러한 베이스 모델을 하나의 더 나은 모델로 결합하는 것입니다. 스태킹 기술에서는 이러한 모델들을 건물의 벽돌로 사용하고 예측을 결합하는 수단으로 사용할 것입니다."
일반적인 앙상블 모델 기술 중 몇 가지를 빠르게 살펴봅시다:
- 투표: 투표 앙상블은 일련의 기본 모델에서 생성되며, 최종 예측은 기본 모델의 예측을 평균 (회귀의 경우)하거나 가장 예측 클래스 (분류의 경우)로 간단히 계산하여 얻습니다. 이것은 가장 간단한 앙상블 기술 중 하나이며 이해하고 설명하기 가장 쉽습니다.
- 부스팅: 일련의 약한 학습자들의 (거의 더미 모델) 예측이 순환적으로 가중치를 사용하여 조정됩니다. 이 기술은 Adaboost 알고리즘과 GradientBoosting으로 이어지며 성능이 우수한 모델 중 하나입니다.
- 배깅: 부트스트랩 집계라고도 하는 병렬 앙상블 기술로, 여러 개별 모델이 전체 데이터 세트의 다른 하위 집합에 적합됩니다. 이러한 모델의 예측은 그런 다음 (투표/평균 사용) 결합됩니다. 개별 모델이 결정 트리인 경우, 이 기술은 랜덤 포레스트 알고리즘으로 이어집니다.
- 스태킹: 이 게시물이 설명하는 앙상블 기술입니다. 계속 읽어 보세요!
그래서 스태킹은 앙상블 기술 중 하나일 뿐입니다. 스태킹은 위의 앙상블 기술들과 많은 면에서 다릅니다:
- 기본 모델을 순차적으로 결합하지 않습니다.
- 모델의 가중치를 순환적으로 업데이트하지 않습니다.
- 기본 모델의 예측을 단순히 평균화하지 않습니다.
- 다양한 종류의 모델 (LinReg, KNN, SVM 등) 모음과 함께 작동합니다. 반면에 배깅과 부스팅은 일반적으로 동일한 기본 모델 (보통 결정 트리)의 모음을 사용합니다.
스태킹 작동 방식
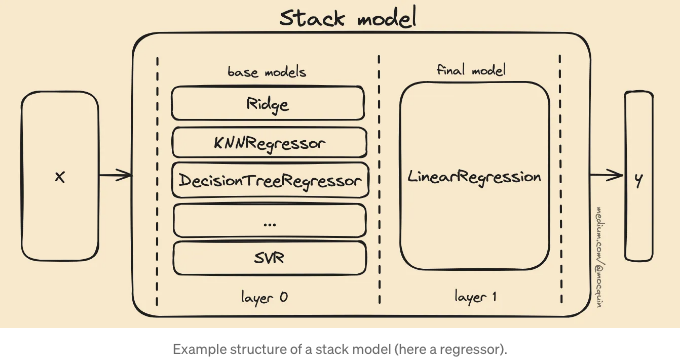
스태킹 방법의 가장 큰 차이점과 특징 중 하나는 기본 모델의 구조와 최종 예측을 계산하는 방식입니다. 스태킹 앙상블의 구조는 다음과 같습니다:
- 일련의 기본 모델이 앙상블을 이룸: 이들은 독립적으로 훈련되고 예측합니다. 이러한 모델은 "기본 레이어" 또는 스택 구조의 "0층"이라고도 불립니다. 이러한 기본 모델은 부스팅/배깅 컨텍스트에서와 같이 "약 학습기(weak learners)"로 불릴 수도 있지만, 엄격히 말하면 약 학습기는 아닙니다.
- 또 다른 단일 모델이 기본 모델의 예측을 감싸 최종 예측을 계산합니다. 이 모델은 "최종 레이어" 또는 "1층"이라고도 불립니다.
다음과 같이 도식화됩니다 (우리는 지금 예측 과정에 초점을 맞춥니다):
스태킹의 특징 중요한 것은 다음과 같습니다: 내부적으로 스택의 최종 모델은 일반적인 입력 데이터 집합 X와 함께 작동하지 않고, 대신에 베이스 모델의 예측값에서 학습/예측합니다. 아이디어는 모델을 사용하여 기초 모델이 출력 y를 예측하는 방법을 학습하고, 이러한 예측을 실제 참값 y_true와 비교하는 것입니다.
모델이 적합화된 후, 예측 프로세스는 간단히 다음과 같이 이루어집니다: 새로운 X 데이터 집합(또는 단일 샘플 x)에 대해
- 모든 베이스 모델 예측이 독립적으로 계산됩니다: 모델로 기초 모델에 대해 y_pred=model.predict(X)를 수행합니다.
- 이러한 y_pred 벡터들은 가로로 연결(concatenated)되어 새로운 2D 데이터 집합을 만들게 되는데, 이 과정에 각 열은 특정 기초 모델에 대한 예측을 나타내고 이 행렬을 X_final이라고 부릅니다. 이것은 최종 추정기의 2D 입력 데이터 집합을 나타냅니다.
- 이 X_final 2D 데이터 집합은 최종 추정기에 의해 실제 최종 예측을 예측하는 데 사용됩니다: final.predict(X_final)
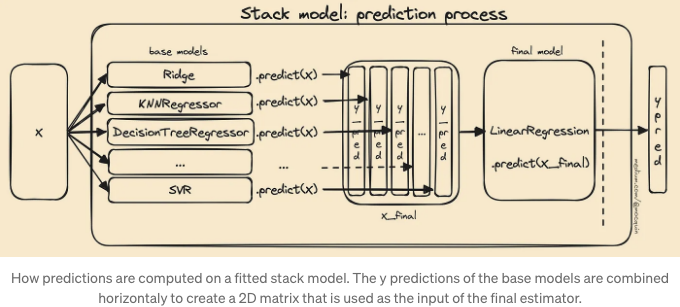
다시 말해, 스태킹은 기본 모델의 y-예측으로 구성된 내부 2D 데이터셋 행렬이 생성되고, 이 행렬이 최종 모델의 입력으로 사용된다는 것을 의미합니다. 따라서 최종 모델은 y-공간 값의 2D 행렬을 입력으로 받아 실제 1D 예측인 y-공간 값의 출력을 생성합니다.
스태킹을 보는 다른 방법은 간단히 투표 모델로 볼 수 있지만, 평균값/가장 많이 투표된 예측을 가져오는 것이 아니라 이러한 예측값을 다른 모델에 공급하는 것입니다. 다시 말해, 스태킹을 사용하여 투표를 흉내 내기 위해 최종 모델로 평균화/argmax 모델을 사용할 수 있습니다.
일반적으로 회귀 문제의 경우 최종 모델로는 간단한 LinearRegression을, 분류 문제의 경우 LogisticRegression을 사용하며, 이러한 모델은 scikit-learn의 StackingClassifier 및 StackingRegressor의 기본값입니다. 최종 추정기에 의해 기본 모델의 예측을 결합하는 단계는 종종 "블렌딩"이라고 불리며, 모든 모델의 예측이 단일 예측으로 혼합됩니다.
스택 모델을 적절하게 적합시키는 방법
스택 모델이 작동하는 구체적인 방식 때문에 특정한 적합 절차를 사용해야 합니다.
scikit-learn에서는 어떤 추정기든 자동으로 이 작업이 처리됩니다. 따라서 스택 모델을 사용하기 위해 이 적합 절차를 이해할 필요는 절대적으로 없습니다. 한편, 모델이 어떻게 작동하는지 이해하는 것은 항상 좋은 일이죠. 또한 새로운 것을 배우는 것은 굉장히 재밌고 만족스러운 경험입니다!
스택을 적합시키는 알고리즘은 2단계로 나눌 수 있습니다. 첫 번째는 매우 간단한데, 두 번째는 조금 더 설명이 필요합니다.
- 단계 1: 모든 기본 모델(레이어 0에서 온 모델)은 완전히 독립적으로 피팅되며 전체 X/y 데이터셋을 사용합니다. 다시 말해, 첫 번째 단계는 아래와 같습니다: base_models의 각 모델에 대해 model.fit(X, y)를 실행하는 것과 동일합니다.
- 단계 2: 최종 추정기는 피팅되지 않은 기본 모델을 사용하여 교차 검증 체계를 활용하여 피팅됩니다.
첫 번째 단계는 상당히 명확합니다: 스택 모델인 stack.fit(X, y)에 대해 fit 메서드가 호출되면, X와 y가 각기의 기본 모델로 전달되어 서로 독립적으로 피팅이 진행됩니다. 이 단계는 base_models의 각 모델에 대해 model.fit(X, y)를 실행하는 것과 동일합니다. 이러한 피팅된 추정기는 stack 모델의 stack.estimators_ 속성에 저장됩니다.
그런 다음 최종 추정기를 훈련시키기 위해 다른 방법이 사용됩니다. 이미 해당 피팅을 위한 대상 출력 y가 있지만, 여전히 기본 모델들의 예측으로 생성된 중간 X_final 데이터셋을 생성해야 합니다. 이미 피팅된 추정기들에 .predict 메서드를 사용하는 것은 입력 X가 이미 기본 추정기에 의해 보고되고 훈련되었기 때문에 어떤 종류의 오버피팅을 초래할 수 있습니다.
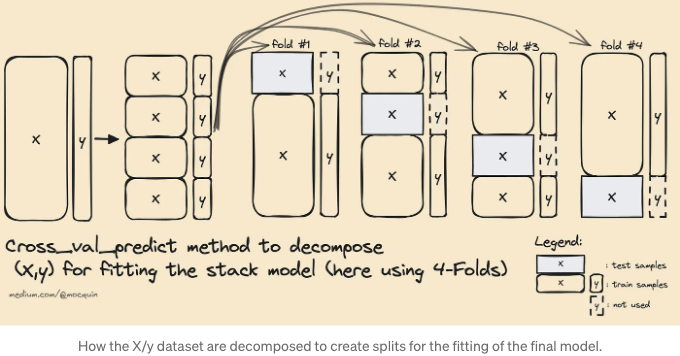
다시 말해 이미 학습된 기본 추정기를 사용하여 입력 데이터 세트를 최종 추정기에 맞출 수 없습니다. 대신, 각 추정기는 동일한 교차 검증 폴드로 cross_val_predict 함수에 공급되어 모든 기본 추정기에 대한 y_pred를 생성합니다. 이러한 기본 예측값은 X_final 훈련 데이터 세트에 수평으로 연결되어 최종 추정기가 X_final, y로 적합하게 됩니다.
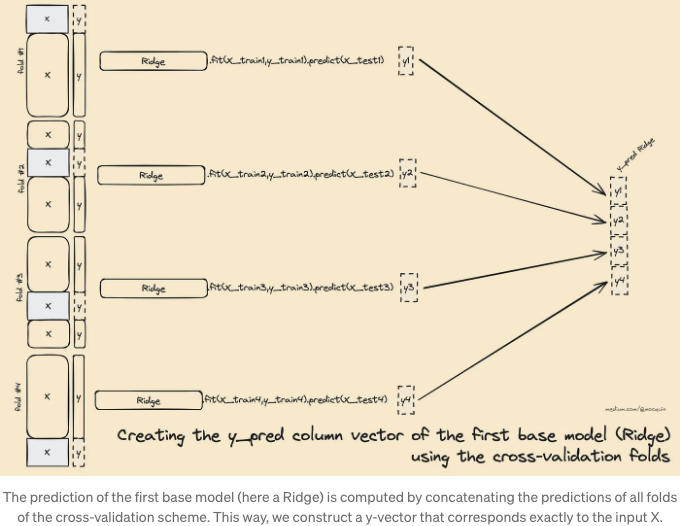
이제 문제를 아래와 같이 분해하는 방법을 알게 되었습니다: "최종 추정기가 대상 y에 적합하도록 사용하는 X 데이터 세트는 모든 추정기에 의해 제공된 예측 값들을 연결하여 생성됩니다. (모든 추정기에 대해 동일한 cv 전략을 사용하여, 모든 기본 추정기가 항상 동일한 입력/출력을 보는 사실을 고려하기 위함). 이는 첫 번째 단계에서 적합된 기본 모델들(전체 X 데이터 세트로 적합된 모델들)이 최종 추정기를 적합하기 위해 사용되지 않는다는 것을 의미합니다. 대신, 각 폴드에 대해 적합되지 않은 기본 모델의 사본이 사용되며, 각 폴드에 대한 예측값이 연결되어 X_final을 생성합니다. (각 모델에 대해 수직으로, 그리고 수평으로 X_final을 만들기 위해)
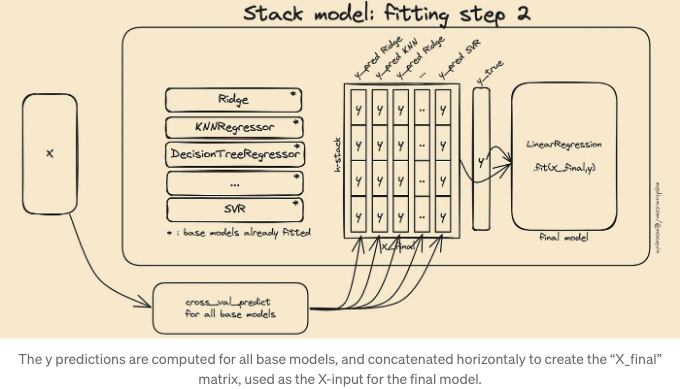
이 방법을 통해 최종 추정기는 베이스 모델의 예측값이 이미 확인되지 않은 샘플에 적합됩니다.
이 적합 절차를 보는 또 다른 방법은 교차 검증 데이터 폴드 분해에서 중간 2D 데이터 세트 X_final을 표현하는 것입니다: X 데이터 세트는 N 개의 폴드(X_train, X_test, y_train, y_test)로 분할됩니다. 폴드는 각 개별 샘플이 테스트 세트로 한 번만 사용되는 "분할" 기준을 준수해야 합니다. 이 분할의 각각에 대해 미적합 기본 모델의 복사본이 .fit(X_train, y_train)을 사용하여 적합되고, 해당 예측값이 .predict(X_test)을 사용하여 계산됩니다. 이렇게 하면 모든 베이스 모델에 대한 모든 분할에 대해 y_pred를 얻을 수 있습니다. 최종 X_train은 모든 분할의 예측값을 수직으로 연결한 것입니다.
리스태킹
스태킹 아키텍처는 모델의 추가적인 사용자 정의를 가능하게 합니다. 이는 모델이 작동하는 방식을 조정할 수 있는 하이퍼파라미터로 생각할 수 있습니다. 아이디어는 정말 간단합니다: 베이스 모델의 수평으로 쌓인 예측뿐만 아니라 원본 입력 X 데이터 집합도 마지막 추정기의 입력에 추가됩니다. 이렇게 하면 최종 추정기가 베이스 모델의 예측과 원본 데이터를 모두 포함하여 데이터에서 더 많은 정보를 찾을 수 있습니다. 다시 말해, 스태킹 모델의 복잡성은 마지막 모델의 입력 특성의 수를 늘림으로써 증가됩니다.
사이킷런에서는 이를 스택 모델의 passthrough=True 매개변수를 통해 수행합니다.
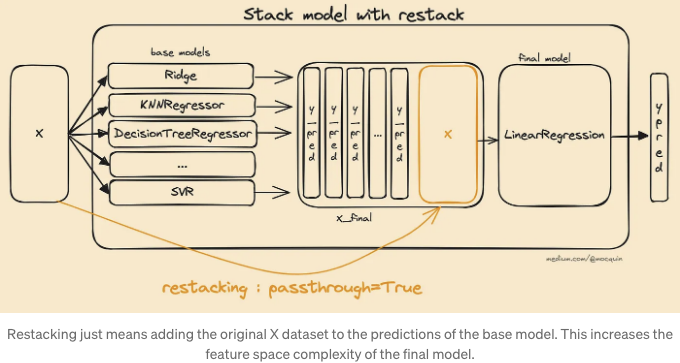
물론 X 행렬은 학습 시간과 예측 시간 모두 X_final에 추가됩니다.
다층
스태킹 모델의 디자인 방식을 통해 추가적인 스택을 간단히 만들 수 있어 더 복잡한 모델을 만들 수 있습니다. 이는 새로운 스택을 중첩하여 수행될 수 있는데, 새로운 스택은 이전 스택의 최종 에스티메이터로 설정됩니다. 이 작업은 모델의 복잡성을 높이지만, 학습/예측 시간과 과적합 가능성이 증가할 수 있다는 점을 유의해야 합니다.
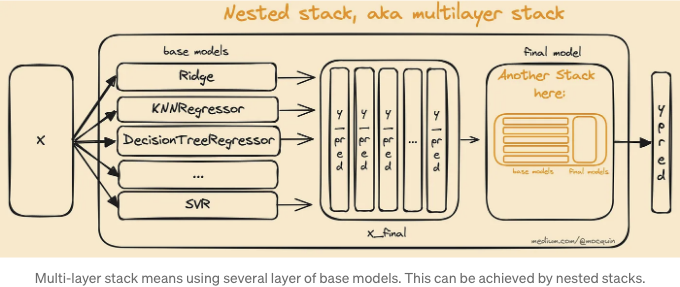
스택 모델 튜닝
이미 언급한 대로, 스태킹은 각 베이스 모델의 최상의 부분을 유지하려는 목적으로, 서로의 약점을 보완할 수 있도록 하는 것을 목표로 합니다. 즉, 모든 모델이 동일한 샘플에서 동일한 성능을 발휘한다면, 스택 모델은 어떤 개선도 이루어지지 않을 것입니다. 따라서 다양한 데이터셋의 위상 영역에서 이상적으로 성능을 발휘하는 서로 다르게 작용하는 베이스 모델을 사용하여 스택 모델을 최적화할 수 있습니다.
따라서 베이스 모델이 어떻게 성능을 발휘하고, 그들의 예측 오류가 서로 상관 관계가 있는지 여부를 검토하는 것이 좋은 아이디어일 수 있습니다. 두 모델이 거의 동일한 오류를 공유한다면, 한 모델은 아마 버릴 수 있을 것입니다 - 전반적인 성능을 유지하면서 연산 복잡성을 줄일 수 있습니다.
스택은 모든 베이스 모델과 최종 모델을 포함하므로, 모든 하이퍼파라미터를 상속합니다. 스택의 성능에 관심을 가지기 때문에 베이스 모델의 성능에 엄격하게 초점을 맞추는 것이 아니라, 그들의 하이퍼파라미터는 스택에서 튜닝되어야 합니다. 다시 말해, 베이스 모델은 하이퍼파라미터 A로 혼자서 더 나은 성능을 발휘할 수 있지만, 스택의 성능은 하이퍼파라미터 B로 더 나을 수 있습니다.
마지막으로, passthrough=True 또는 False를 사용하여 스택 모델을 조정하는 또 다른 방법이 있습니다.
일반적으로, 스택이 있는지 기본 모델과 동일한 성능을 발휘하는지 항상 확인해야 합니다. 그렇다면, 스택을 버리거나 조정해야 합니다. 높은 계산 복잡성은 상당한 성능 향상과 함께 제공된다는 것을 명심해야 합니다.
스태킹은 앙상블 모델의 한 형태이므로, 개별 모델이 완벽하지 않다고 해서 항상 안 좋은 것은 아닙니다. 목표는 모델의 성능이 서로 보완될 수 있도록 하는 것입니다 — 마치 약한 학습자들이 결합되어 더 나은 모델이 만들어지는 것처럼요.
실제로, 스택 예측기는 기본 계층의 최고 예측기만큼 잘 예측하며 때로는 이러한 예측기의 서로 다른 강점을 결합함으로써 이를 앞지르기도 합니다. 그러나 스택 예측기로 훈련과 예측을 하는 것은 계산적으로 비용이 많이 드는 일입니다.
scikit-learn을 사용한 스태킹
이제 우리는 스태킹에 대해 모두 알았으니, scikit-learn과 함께 어떻게 사용하는지 살펴봅시다. 기억해야 할 유일한 것은 scikit-learn에서 스태킹이 모델/메타-모델로 구현된다는 것입니다:
- .fit 및 .predict 메서드를 가진 모델이다.
- 다른 모델을 입력으로 받는 메타-모델이다.
Scikit-learn은 앙상블 모듈에서 분류 및 회귀용 스태킹 모델을 제공합니다. 회귀용 매우 간단한 예제를 살펴보겠습니다:
%matplotlib qt
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris, make_moons, make_circles
from sklearn.model_selection import StratifiedKFold, train_test_split, cross_validate
from sklearn.svm import SVC, LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
from sklearn.ensemble import StackingClassifier
X, y = make_circles(n_samples=500, noise=0.3, factor=0.5, random_state=1, shuffle=True)
# 3개의 기본 모델을 사용합니다.
base_models = [
('knn', KNeighborsClassifier(n_neighbors=3)),
('logreg', LogisticRegression(max_iter=1000)),
('svc', SVC(C=0.05)),
]
# 기본 모델을 사용하여 스택을 만들고 최종 예측기로 LogisticRegression을 사용합니다.
stack = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegressionCV(max_iter=1000)
)
restack = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegressionCV(max_iter=1000),
passthrough=True,
)
# 그런 다음 모든 모델을 비교할 수 있는 멋진 목록을 만듭니다.
models = base_models + [('stack', stack), ('restack', restack)]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
for name, model in models:
model.fit(X_train, y_train)
# stacking classifier의 결정 경계
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.2),
np.arange(y_min, y_max, 0.2))
fig, axes = plt.subplots(1, len(models), sharex=True, sharey=True)
for ax, (name, model) in zip(axes, models):
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.8)
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, edgecolors='k')
ax.set_title(f"{name} 점수={model.score(X_test, y_test):.2f}")
ax.set_xlabel("특성 1")
ax.set_ylabel("특성 2")
fig.tight_layout()
완벽을 위해 stack의 다시 쌓은 버전을 추가했습니다. 플롯을 보면 기본 모델을 결합하면 stack의 성능이 기본 모델 중 가장 좋은 성능을 조금 능가한다는 것을 알 수 있습니다. 다시 쌓기를 사용하면 성능이 더 조금 향상됩니다.
위에서 설명한 것은 모델 스택을 만드는 방법을 보여줄 뿐, 실제 성능 추정을 위해서는 튜닝과 교차 검증이 필요합니다.
"처음부터" 스택 구성하기
이제 scikit-learn API를 사용하여 스태킹의 간단한 구현을 살펴보겠습니다. 이것은 스태킹이 그렇게 복잡하지 않다는 것을 보여주는 장난감 예제에 불과합니다. 학습/설명 목적 이외에는 scikit-learn의 구현을 사용해야 합니다!
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_validate
from sklearn.base import BaseEstimator, RegressorMixin, TransformerMixin, clone
from sklearn.model_selection import cross_val_predict
class HomeMadeStackingRegressor(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_estimators, meta_estimator):
self.base_estimators = base_estimators
self.meta_estimator = meta_estimator
def fit(self, X, y):
self.base_estimators_ = [clone(est) for est in self.base_estimators]
self.meta_estimator_ = clone(self.meta_estimator)
# Fit base estimators independently
for est in self.base_estimators_:
est.fit(X, y)
# Generate X_final feature dataset for the final estimator
# as the concatenation of the cross_val_predict results of the base estimators
X_final = np.array([cross_val_predict(est, X, y, cv=5) for est in self.base_estimators_]).T
# Fit final estimator
self.meta_estimator_.fit(X_final, y)
return self
def predict(self, X):
meta_features = np.array([est.predict(X) for est in self.base_estimators_]).T
return self.meta_estimator_.predict(meta_features)
boston = load_diabetes()
X, y = boston.data, boston.target
base_estimators = [RandomForestRegressor(n_estimators=20, max_depth=3, random_state=1), Ridge()]
meta_estimator = Ridge()
stack = HomeMadeStackingRegressor(base_estimators, meta_estimator)
models = list(zip(['rf', 'ridge'], base_estimators)) + [('stack', stack)]
results = []
for name, basemodel in models:
cv_results = cross_validate(basemodel, X, y, return_estimator=True, return_train_score=True)
df = pd.DataFrame.from_dict(cv_results)
df.reset_index(names="run", inplace=True)
df["model"] = name
results.append(df)
cv_results = pd.concat(results).reset_index(drop=True)
cv_results_melt = cv_results.melt(id_vars=["model", "run"], value_vars=["test_score", "train_score", "fit_time", "score_time"], var_name="metric", value_name='value')
sns.catplot(cv_results_melt, y="model", x="value", kind="bar", hue="model", col="metric", sharex=False)
스태킹의 테스트 점수가 기본 모델보다 우수함을 확인할 수 있습니다. 그러나 더 높은 학습 시간을 필요로 합니다.
요약
스태킹에 대해 기억해야 할 것들입니다:
- 앙상블 기법이며, 최종 모델을 사용하여 기본 모델의 예측을 결합합니다.
- 최종 모델은 기본 모델의 예측을 수평 스택으로 사용합니다.
- 기본 모델이 서로 다르고 서로의 약점을 보완할 때 가장 잘 작동합니다. 최소한 기본 모델 중 가장 우수한 것보다는 성능이 우수해야 합니다.
- 기본 및 최종 모델의 하이퍼파라미터와 통과 매개변수를 사용하여 조정할 수 있습니다. 다시 쌓을 수 있도록 하거나 아니면 그렇지 않도록 설정할 수 있습니다.
- 적합화 과정에는 기본 추정기와 동일하게 독립적으로 적합된 최종 추정기를 적합화하기 위해 교차 검증 체계를 사용합니다.
이 글이 마음에 드셨다면 다른 글도 읽어보세요: