
#1 로컬 LLM을 사용해야 하는 이유
ChatGPT은 정말 멋지죠. 그런데 한 가지 치명적인 단점이 있습니다: 작성하거나 업로드하는 모든 것이 OpenAI의 서버에 저장됩니다. 이는 많은 경우에는 문제가 되지 않을 수 있지만, 민감한 데이터를 다룰 때 문제가 될 수 있습니다.
그래서 저는 개인 컴퓨터에서 로컬로 실행할 수 있는 오픈소스 LLM을 탐구하기 시작했습니다. 실제로 그것들이 왜 훌륭한지에 대해 많은 이유가 있다는 것을 발견했습니다.
-
데이터 개인 정보 보호: 귀하의 정보는 귀하의 기기에 유지됩니다.
-
비용 효율적: 가입비나 API 비용이 없으며 무료로 사용할 수 있습니다.
-
맞춤화: 모델은 귀하의 특정 시스템 프롬프트나 데이터 세트로 세밀하게 조정할 수 있습니다.
-
오프라인 기능: 인터넷 연결이 필요하지 않습니다.
- 제약 사항이 없는 사용: 외부 API에서 부과된 제한이 없습니다.
시작해 봅시다!
2. Ollama 설치 및 Llama 3 실행하기
Ollama는 개인 컴퓨터에서 쉽게 대형 언어 모델(LLM)을 로컬에서 실행할 수 있게 해주는 오픈 소스 프로젝트입니다. 사용자 친화적이고 매우 가벼우며 Meta(럼마 3)와 구글(젬마 2)의 최신 및 최고의 사전 학습 모델을 포함한 다양한 모델을 제공하는 것으로 알려져 있습니다. 이러한 회사들이 이러한 모델을 교육하는 데 수백만 달러를 투자하여 우리가 자신의 기기에서 재미있게 사용할 수 있도록 했습니다. 대단하지 않나요?
Ollama는 그 자체로는 빈 껍데기에 불과하며 작동하려면 LLM이 필요합니다.
설치 프로세스에 들어가기 전에 사용 가능한 모델들을 살펴보겠습니다:
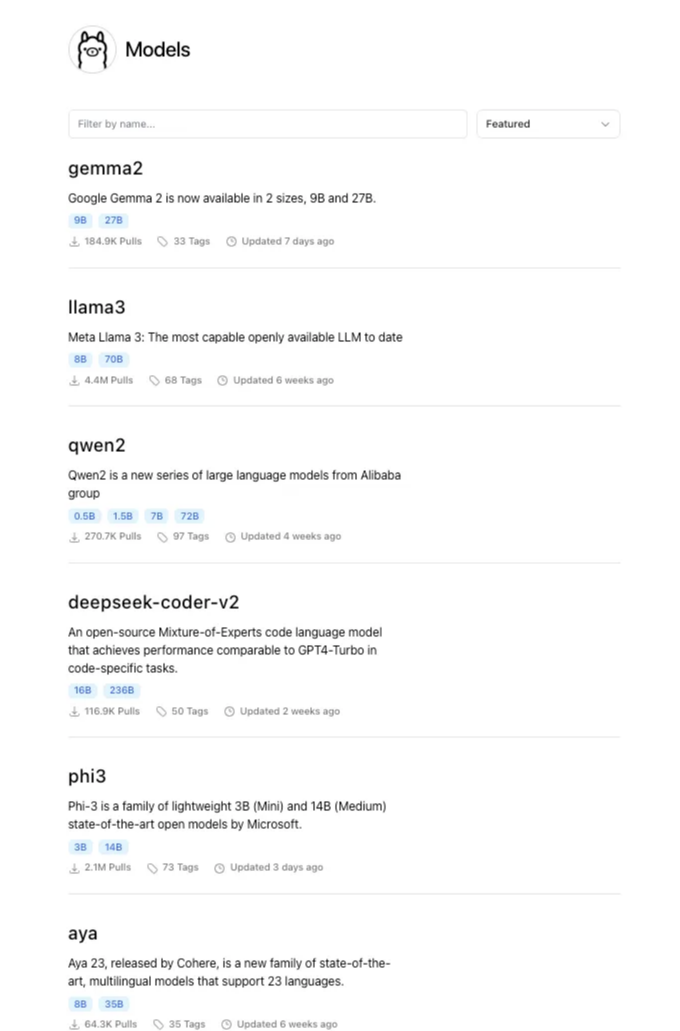
그리고 더 많은 모델이 있습니다!
이 글에서는 Meta사의 최신 모델인 Llama 3에 초점을 맞추어 놀라운 성능을 약속하는 이 모델이 이 플랫폼에서 가장 인기 있는 모델이라고 합니다. 이 글을 작성하는 시점에 이 모델은 440만 회 이상의 다운로드를 기록하고 있습니다.
다음 단계에서는 컴퓨터에 Ollama를 설치하고 Llama3로 공급하여 마침내 그 모델을 ChatGPT처럼 사용하는 방법을 보여줍니다.
단계 1/2:
- ollama.com에 가서 "다운로드"를 클릭합니다. 저는 macOS를 사용하고 있으므로 이후 튜토리얼에서 이 옵션에 초점을 맞출 것이지만, Linux나 Windows에서 할 때도 크게 다르지 않을 것입니다.
- "macOS용 다운로드"를 클릭합니다.
마크다운 형식의 표를 사용해보세요.
STEP 3/4/5: 다른 앱들과 마찬가지로 매우 간단한 설치 단계를 따르기만 하면 됩니다.
- "설치"를 클릭합니다.
- "다음"을 클릭합니다.
- 터미널에서 "ollama run llama3"을 실행합니다.
마지막 단계에서는 먼저 llama3의 8B 버전(약 4.7GB)을 컴퓨터에 다운로드한 다음 실행됩니다. 이렇게 간단합니다!

And this article could stop right here. A few clicks and a line of code later, here we are running an LLM locally!
You can ask it anything, like explaining the differences between the 8 billion and 70 billion parameters versions of Llama 3.
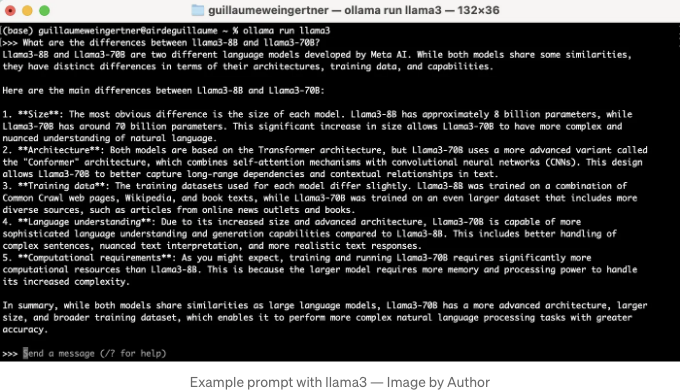
해당 모델의 응답 시간은 일반적으로 컴퓨터의 GPU / RAM에 의존합니다.
#3 몇 가지 유용한 명령어
터미널 내에서 계속 LLMs를 사용하고 싶다면 몇 가지 기본 명령어가 필요하다고 생각됩니다:
- ollama run llama3 이 경우 llama3 모델을 실행합니다.
- ollama list 로컬로 이미 설치된 모든 모델을 나열합니다.
- ollama pull mistral 플랫폼에서 다른 사용 가능한 모델을 가져옵니다. 이 경우 mistral 모델을 가져옵니다.
- /clear (모델이 실행 중일 때) 세션의 컨텍스트를 지워 처음부터 시작합니다.
- /bye (모델이 실행 중일 때) ollama를 종료합니다.
- /? (모델이 실행 중일 때) 사용 가능한 모든 명령어를 나열합니다.
더 복잡한 사용 사례를 위해 더 많은 명령이 존재합니다. 새로운 미세 조정 모델을 생성하는 것과 같은 경우가 있습니다.
Ollama의 Github 저장소에는 매우 완벽한 설명서가 있습니다.
기본 사용 사례에 대해서는 CLI가 충분할 수도 있지만 더 많은 기능이 있습니다...
#4 Jupyter Notebook에서 Llama 3
터미널을 통해 LLMs를 사용하는 것도 좋지만 파이썬 코드를 통해 모델과 상호 작용하면 더 많은 가능성이 열립니다.
이를 위해 langchain_community 라이브러리를 pip으로 설치해야 합니다 (pip install langchain_community) 그리고 Ollama 패키지를 가져와야 합니다.
예를 들어, 어떤 사람의 이름, 나이, 직업을 제공하여 짧은 자기소개를 만들고 싶다고 가정해봅시다. 이 예제에서는 다음과 같이 코드가 작성됩니다:
# !pip install langchain_community
# 필요한 패키지 가져오기
from langchain_community.llms import Ollama
# 모델 인스턴스 생성
llm = Ollama(model="llama3")
# 프롬프트와 함께 모델 사용
llm.invoke("Alice의 나이가 25세이고 엔지니어로 일하는 짧은 2문장 자기소개 생성")
친근한 톤으로 번역해 드릴게요.
조금 더 다듬어보면 더 완벽해질거에요.
단일 인물을 위한 소개를 터미널에서 쉽게 만들 수 있지만, 많은 사람들의 경우엔 파이썬 없이 같은 작업을 반복해야 할 수도 있어요. 파이썬을 사용하면 프롬프트를 매개변수화시키고, 많은 사람들에 대해 자동화된 프로세스를 실행할 수 있어요.
예를 들어:
import pandas as pd
# 샘플 DataFrame 생성
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'occupation': ['Engineer', 'Teacher', 'Artist']
})
# DataFrame에 적용할 수 있는 함수 생성
def generate_bio(name, age, occupation):
prompt = f"{name}님에 대한 간단한 2문장 소개 생성, {age}세이고 {occupation}로 근무 중"
return llm.invoke(prompt)
# DataFrame에 함수 적용
df['bio'] = df.apply(lambda row: generate_bio(row['name'], row['age'], row['occupation']), axis=1)
df.head()
이제 DataFrame의 각 행에 대해 모델이 바이오를 생성합니다!
5번째 단계 최종 소견
이 기사의 목적은 Ollama 덕분에 로컬에서 완전히 기능적인 LLM(Large Language Model)을 구현하는 간편함을 강조하는 것이었습니다.
간단한 요청을 위해 터미널을 통해 이 모델을 사용하거나 Python을 사용하여 더 복잡하거나 자동화된 작업을 수행할 수 있습니다. 프로세스는 간단합니다.
Open WebUI와 같은 오픈 소스 프로젝트 덕분에 우리만의 ChatGPT와 같은 그래픽 인터페이스를 구현할 수도 있습니다.
저는 그저 몇 번의 클릭과 몇 줄의 코드로 이렇게 유용한 것을 얻을 수 있다는 것이 놀라워요! 여러분도 즐기셨으면 좋겠네요.
기사 끝까지 읽어 주셔서 감사합니다. 더 많은 내용을 보려면 팔로우해주세요! 질문이나 의견이 있으시면 아래에 메시지를 남겨 주시거나 LinkedIn / X를 통해 연락해 주세요!