
프랑스 스타트업인 Mistral이 공개한 오픈 소스 언어 모델 Mistral 7B를 소개하면서 ChatGPT나 claude.ai와 같은 전용 모델이 보여준 놀라운 성능이 오픈 소스 커뮤니티에서도 이용 가능해졌습니다. 이 모델을 리소스가 제한된 시스템에서 사용할 수 있는 가능성을 탐색하기 위해 양자화된 버전은 훌륭한 성능을 유지했습니다.
이전 연구에서 2비트 양자화된 Mistral 7B 모델이 정확성 테스트를 훌륭히 통과했지만, 맥에서 질문에 대한 평균 응답 시간이 약 2분이 걸리는 문제가 있었습니다. 그래서 Llama 2와 동일한 아키텍처와 토크나이저를 사용한 3조 토큰으로 사전학습된 1.1B 언어 모델인 TinyLlama[1]이 출시되었습니다. 이 모델은 더 많은 리소스가 제한된 환경을 위해 고안되었습니다.
이 기사에서는 양자화된 Mistral 7B와 양자화된 TinyLlama 1.1B의 질문-응답 능력의 정확성과 응답 시간 성능을 앙상블 검색 증강 생성 (RAG) 설정에서 비교할 것입니다.
목차
- 활성화 기술
- 시스템 아키텍처
- 환경 설정
- 구현
- 결과 및 토론
- 최종 생각
활성화 기술
이 테스트는 8GB RAM을 장착한 MacBook Air M1에서 수행됩니다. 계산 및 메모리 자원이 제한되어 있기 때문에 우리는 이 LLM들의 양자화된 버전들을 채택하고 있습니다. 본질적으로 양자화란 모델의 매개변수를 더 적은 비트로 표현하는 것을 의미하며, 이는 모델을 압축하는 효과를 냅니다. 이 압축은 메모리 사용량을 줄이고 더 빠른 실행 시간 및 증가된 에너지 효율성을 가져오지만 정확도를 희생해야 합니다. 이 연구에서는 2비트 양자화된 Mistral 7B Instruct 및 5비트 양자화된 TinyLlama 1.1B Chat 모델을 GGUF 형식으로 사용할 것입니다. GGUF는 모델의 빠른 로딩과 저장을 위해 설계된 이진 형식입니다. 이러한 GGUF 모델을 로드하기 위해 llama-cpp-python 라이브러리를 사용할 것입니다. llama-cpp-python은 llama.cpp 라이브러리에 대한 Python 바인딩입니다.
검색 증가 생성 (RAG)은 LLM의 출력을 향상시키는 과정으로, 응답 생성 이전에 교육 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하는 것입니다. RAG 응용 프로그램은 문헌에서 관련 문서 조각을 검색하기 위한 검색기 시스템과, 검색된 조각을 컨텍스트로 사용하여 응답을 생성하는 LLM으로 구성됩니다. 검색기는 RAG의 주요 요소이며, 전체 질문-답변 (QA) 시스템의 성능에 상당한 영향을 미칩니다. LLM과 함께 작업할 수 있는 강력한 프레임워크 라이브러리인 LangChain은 재견러(EnsembleRetriever)를 포함하고 있습니다. 재견러는 입력으로 검색기 목록을 받아 상호 순위 조합 알고리즘을 기반으로 결과를 조합하고 재정렬합니다. 서로 다른 알고리즘의 장점을 활용함으로써, 과거에 더 높은 정확도를 달성했다는 것을 보여주었습니다. 본 문서에서 우리는 앙상블을 위해 BM25 검색기와 FAISS 검색기를 0.3:0.7 비율로 결합할 것입니다.
이러한 지원 요소를 모두 함께 가져오기 위해 시스템 아키텍처를 살펴보겠습니다.
시스템 아키텍처
이전 글에서 소개한 모듈식 아키텍처를 재사용할 것입니다. 아래와 같이:
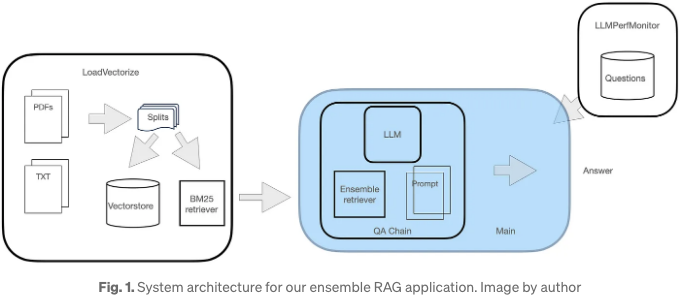
이 QA 시스템에는 세 가지 모듈이 있습니다:
- 첫 번째 모듈은 온라인 PDF 문서를 로드하고 벡터화하는 작업을 포함합니다.
- 두 번째 모듈은 양자화된 LLM을 로드하고 FAISS 리트리버를 인스턴스화하며 FAISS와 BM25 리트리버로 구성된 앙상블 리트리버 인스턴스를 만드는 작업을 포함합니다. 이후 LLM, 앙상블 및 사용자 정의 프롬프트를 포함하는 리트리버 체인을 생성합니다.
- 세 번째 모듈은 이 RAG를 위한 도우미 모듈로 작동합니다. 이 모듈은 코사인 유사도 및 모델 응답 시간을 계산하여 질문 세트 전체에서 LLM 성능을客客하게하게 합니다.
구현을 살펴보기 전에, 환경 설정을 먼저 해보겠습니다.
환경 설정
여기서 사용하는 Python 버전은 3.10.5입니다. 이 프로젝트를 관리하기 위해 가상 환경을 생성할 거에요. 환경을 생성하고 활성화하기 위해 다음 단계를 따라봐요:
python3.10 -m venv mychat
source mychat/bin/activate
이제 모든 필요한 라이브러리를 설치하러 가볼까요? (의존 라이브러리도 함께 설치됩니다):
pip install langchain==0.0.259
pip install faiss-cpu
pip install rank_bm25
pip install sentence_transformers
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
최근에 langchain이 리팩토링되었기 때문에 코드에 사용된 특정 버전이 위에 표시되어 있습니다. M1 프로세서에서 하드웨어 가속화를 사용하여 llama-cpp-python 라이브러리를 사용하려면 위의 마지막 설치 명령어는 Metal 지원을 활성화합니다. Metal을 사용하면 연산이 GPU에서 실행됩니다.
faiss-cpu는 GPU가 아닌 CPU를 사용하여 밀도가 높은 벡터의 유사성 검색 및 클러스터링을 위한 효율적인 라이브러리입니다. Okapi BM25로도 알려진 rank_bm25는 문서가 주어진 검색 쿼리와 얼마나 관련되는지를 추정하는 랭킹 함수입니다. sentence-transformers는 문장 및 기타 것들의 임베딩을 계산하는 간단한 방법을 제공합니다.
이제 코드를 살펴볼 준비가 되었습니다.
구현
저희 시스템 아키텍처에 따르면 LoadVectorize, LLMPerfMonitor 및 주요 모듈이 총 3개의 모듈이 있습니다. 처음 두 모듈은 수정 없이 이전 연구에서 재사용되었습니다. 첫 번째 모듈에서 로드된 샘플 문서는 최근 출시된 600페이지 이상의 가속화 장치 가이드인 SteelHead입니다.
LLM을 로드하기 위해 LlamaCpp 인스턴스를 일반적인 모델 매개변수로 인스턴스화할 것입니다. 모델 GGUF 파일은 이미 미리 다운로드되어 특정 디렉토리에 저장되어 있습니다. Mistral 7B Instruct 또는 TinyLlama Chat 모델을 로드하려면 LlamaCpp 인스턴스의 model_path 속성에 다른 값이 지정되어야 합니다. 그런 다음 FAISS와 BM25 리트리버가 함께 하는 EnsembleRetriever 인스턴스를 생성할 것입니다. 마지막으로 LLamaCpp 인스턴스, EnsembleRetriever 및 프롬프트로 RetrievalQA 체인을 생성할 것입니다.
Mistral 프롬프트는 다음 템플릿을 따릅니다:
s[INST] 'context' [/INST]/s'question'
TinyLlama 프롬프트는 다음과 같습니다:
|system| 'context' |user| 'question' |assistant|
따라서, 아래 코드 목록은 TinyLlama 애플리케이션의 메인 모듈을 나타냅니다.
# main.py
from langchain.retrievers import EnsembleRetriever
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.llms import LlamaCpp
import LoadVectorize
import LLMPerfMonitor
import timeit
# Prompt template
qa_template = """<|system|>
You are a friendly chatbot who always responds in a precise manner. If answer is
unknown to you, you will politely say so.
Use the following context to answer the question below:
{context}</s>
<|user|>
{question}</s>
<|assistant|>
"""
# Create a prompt instance
QA_PROMPT = PromptTemplate.from_template(qa_template)
llm = LlamaCpp(
model_path="../models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# load doc, vectorize and create retrievers
db,bm25_r = LoadVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
r = 0.3 # ensemble ratio
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_r,faiss_retriever],weights=[r,1-r])
# Custom QA Chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=ensemble_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
# List of questions
qa_list = LLMPerfMonitor_EN.get_questions_answers()
print('model;question;cosine;resp_time')
for i,query in enumerate(qa_list[::2]):
start = timeit.default_timer()
result = qa_chain({"query": query})
cos_sim = LLMPerfMonitor_EN.calc_similarity(qa_list[i*2+1],result["result"])
time = timeit.default_timer() - start # seconds
print(f'bm25-{r:.1f}_f-{1-r:.1f};Q{i+1};{cos_sim:.5};{time:.2f}')
결과 및 토의
응답의 정확성을 이해하기 위해 모델 응답과 전문가의 샘플 답변 사이의 코사인 유사도를 계산했습니다. 예를 들어, 다음은 두 모델에 대해 질문을 제시한 것입니다:
이 질문에 대한 답변은 SteelHead RiOS v9.7입니다. 각 모델의 응답은 아래와 같습니다.
두 LLM이 올바른 코드 버전을 식별할 수 있었습니다. 그러나 둘 다 추가 세부 정보를 포함한 응답이 완전히 정확하지는 않습니다. 특히 TinyLlama에 대해서는 좋은 결과입니다. 10개의 질문에 대한 정확도는 도형 2에 트리맵 차트로 나타냈습니다. Treemap은 내재적 분류 체계를 사용하여 데이터를 효과적으로 표현할 수 있으며 선택한 측정 항목의 크기와 색상 음영을 사용하여 구분할 수 있습니다.
아래 표는 마크다운 형식으로 변환해 주세요.
이미지는 래이블을 명시해 볼 수는 있지만, Markdown은 이미 HTML인 요소보다 더 적합하고, 깨끗한 마크업을 보여주는 방법입니다. 역할에 따라 Markdown의 사용은 더 효과적일 수 있습니다.
선택한 질문에 대한 결과를 기반으로 보면, TinyLlama는 정확성 측면에서 꽤 잘 수행했습니다. 더 중요한 점은 더 정확한 Mistral 7B 모델보다 훨씬 더 빠르게 응답할 수 있었습니다. 주장대로라면, TinyLlama는 자원이 제한된 시스템에서 좋은 성능을 보이는 모델로 보입니다.
#최종 생각
몇 달 전 Mistral 7B 모델이 소개된 이후, 오픈 소스 LLM은 정확도에서 큰 발전을 이루었습니다. 내부 문서에서 이 모델이 훈련되지 않았더라도, 우리는 검색 보감 생성(RAG) 설정에서 이 능력을 활용할 수 있습니다. 그러나 이러한 대형 모델을 자원이 제한된 환경에서 실행하는 것은 완전히 현실적이지는 않습니다. 이 곳에서 양자화는 모델의 매개변수에 사용된 비트 수를 줄이는 데 도움이 됩니다. 게다가, 자원 풋프린트가 작은 모델들이 이러한 제한된 환경을 위해 소개되었고, TinyLlama가 그러한 모델 중 하나입니다.
이 기사에서 우리는 정량화된 Mistral 7B Instruct와 TinyLlama 1.1B Chat의 정확성과 질문 응답 시간을 비교했습니다. 정확성 측면에서 큰 모델 Mistral 7B가 TinyLlama보다 여전히 우수하지만, 응답 시간 측면에서 TinyLlama의 응답이 Mistral 7B보다 훨씬 빨랐습니다. 한 예에서 TinyLlama의 응답 시간이 Mistral 7B보다 17배 빨랐습니다. 따라서 정확도에 약간의 하락이 허용되는 애플리케이션의 경우, TinyLlama는 자원이 제한된 시스템에 완벽하게 적합합니다.
안녕하세요!
참고 자료
[1] https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0 [2] https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble [3] Mistral 7B를 사용하여 앙상블 리트리버의 컨텍스트와 함께 내부 문서 조사하기