
협업 프로그래밍을 올바르고 합리적으로 사용하면 우리 프로그램에 상당한 성능 향상을 가져다 줄 것입니다. 오늘의 글에서는 파이썬에서 동시성 프로그래밍 및 Future를 중점으로 하는 동시성 프로그래밍을 이해하고 적용하는 방법을 안내하겠습니다.
동시성과 병렬성: 차이 이해하기
동시성 프로그래밍에 대해 학습할 때 동시성과 병렬성이라는 용어를 함께 사용하는 경우가 많습니다. 이로 인해 많은 사람들이 두 용어가 동일한 것으로 생각되는 오해를 하게 됩니다. 그러나 이는 오인입니다.
먼저 일반적으로 오해되는 것을 명확하게 해 봅시다: 파이썬에서 동시성은 여러 작업(스레드 또는 태스크)이 동시에 동시에 발생한다는 것을 의미하지 않습니다. 대신, 한 번에 하나의 작업만 진행되도록 허용하고, 스레드 또는 태스크가 완료될 때까지 서로 전환됩니다. 아래 다이어그램을 살펴보겠습니다:
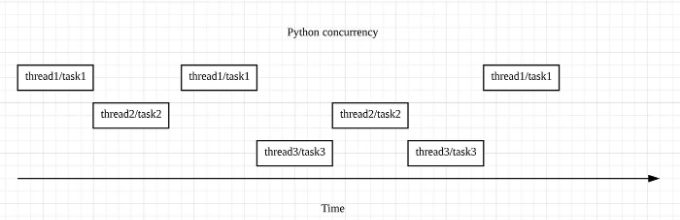
이 다이어그램은 태스크 전환을 관리하는 두 가지 다른 방법을 보여줍니다. 이는 파이썬에서 동시성의 두 형태에 대응됩니다: 스레딩과 asyncio입니다.
스레딩의 경우, 운영 체제는 각 스레드의 모든 세부 정보를 알고 있기 때문에 필요에 따라 스레드 전환을 처리합니다. 여기서의 장점은 프로그래머가 전환 프로세스를 관리할 필요가 없기 때문에 코드를 작성하기가 더 쉽다는 것입니다. 그러나 이는 레이스 컨디션과 같은 문제로 이어질 수 있습니다. 이는 스레드가 단일 명령문 실행 도중에 서로 간섭할 수 있는 상황을 말합니다(e.g., x += 1).
그러나 asyncio를 사용할 경우, 주 프로그램이 작업을 전환할 수 있다는 것을 명시적으로 알려주어야 합니다. 이러한 설계는 asyncio 이벤트 루프에 의해 제어되는 방식으로 전환되므로 실행 중에 작업이 충돌하지 않도록 보장하여 경쟁 조건을 피할 수 있도록 도와줍니다.
병렬성에 대해 이야기하면, 동시에 동시에 실행되는 작업을 가리킵니다. Python에서 이는 멀티 프로세싱을 통해 달성됩니다. 예를 들어, 컴퓨터가 6코어 프로세서를 사용한다면, 실행 속도를 높이기 위해 6개의 프로세스를 동시에 실행할 수 있습니다. 멀티 프로세싱의 기본 아이디어는 다음과 같이 나타낼 수 있습니다:

두 가지를 비교해보면:
동시성은 빈번한 I/O 작업이 발생하는 시나리오에서 자주 사용됩니다. 예를 들어, 웹 사이트에서 여러 파일을 다운로드할 때, I/O 작업에 소요되는 시간이 CPU 처리에 소요되는 시간보다 크게 늘어날 수 있습니다.
반면에 병렬성은 CPU 집중적인 시나리오에 더 적합합니다. 예를 들어, MapReduce 병렬 계산에서 여러 대의 기계와 프로세서를 사용하여 작업을 여러 코어 또는 시스템에 분산시켜 실행 속도를 높이는 데 활용됩니다.
동시성 프로그래밍의 Futures
단일 스레드 및 다중 스레드 접근 방식의 성능 비교
다음으로, 코드 관점에서 Futures를 이해하고 단일 스레드 방식과 성능을 비교하기 위한 구체적인 예제를 사용해보겠습니다.
여러 웹사이트에서 콘텐츠를 다운로드하고 결과를 출력하는 작업이 있다고 가정해봅시다. 단일 스레드 방식을 사용한다면, 코드 구현은 다음과 같이 보일 것입니다 (단순함을 위해 예외 처리는 간단히 생략했습니다):
import requests
import time
def download_one(url):
resp = requests.get(url)
print('{}에서 {}를 읽었습니다.'.format(url, len(resp.content)))
def download_all(sites):
for site in sites:
download_one(site)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('{}개 사이트를 {}초에 다운로드했습니다.'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
이 방식은 직접적이고 간단한 접근 방식입니다:
먼저 웹사이트 목록을 순회합니다. 그 후, 현재 웹사이트에 대한 다운로드 작업을 수행합니다. 현재 작업이 완료될 때까지 기다렸다가 다음 웹사이트로 넘어가며, 모든 작업이 완료될 때까지 이 과정을 계속합니다.
총 소요 시간은 약 2.4초인 것을 확인할 수 있습니다. 단일 스레드 방식의 장점은 간단함에 있지만, 대부분의 시간이 I/O 작업을 기다리며 보내므로 효율적이지 않습니다. 프로그램은 각 웹사이트의 다운로드가 끝날 때까지 기다려야 다음 작업을 시작할 수 있습니다. 웹사이트 다운로드해야 하는 수가 수천 개에 달하는 현실적인 프로덕션 환경에서는 이 방식이 실행하기에 적합하지 않습니다.
그 다음, 코드의 멀티 스레드 버전을 살펴봅시다:
import concurrent.futures
import requests
import threading
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## Output
Read 151021 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 107637 from https://en.wikipedia.org/wiki/Portal:Biography
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 157811 from https://en.wikipedia.org/wiki/Portal:Technology
Read 91533 from https://en.wikipedia.org/wiki/Portal:Science
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 468461 from https://en.wikipedia.org/wiki/PHP
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 0.19936635800002023 seconds
총 시간이 약 0.2초로 나타나는 것은 효율성이 10배 이상 향상되었다는 사실을 알 수 있어요.
다중 스레드 버전과 단일 스레드 버전 사이의 주요 차이점을 살펴보겠어요:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
여기서는 5개의 스레드를 사용할 수 있는 스레드 풀을 생성했어요. executor.map()은 파이썬 내장 map() 함수와 유사하며, 각각의 urls 요소에 download_one() 함수를 동시에 적용해요.
여담이지만, download_one() 함수에서 사용하는 requests.get() 메서드는 스레드 안전(thread-safe)하므로 경합 상태를 일으키지 않고 여러 스레드 환경에서 안전하게 사용할 수 있습니다.
또한, 스레드의 개수는 사용자가 정의할 수 있지만, 더 많은 스레드가 항상 좋은 것은 아닙니다. 그 이유는 스레드를 생성, 유지 및 소멸하는 데 일정한 오버헤드가 발생하기 때문입니다. 스레드의 개수를 지나치게 높게 설정하면 오히려 성능이 떨어질 수 있습니다. 종종 실제 요구 사항에 기반하여 최적의 스레드 개수를 찾기 위해 몇 가지 테스트를 수행해야 합니다.
물론 프로그램 효율성을 향상시키기 위해 병렬성(parallelism)을 사용할 수도 있습니다. 이를 위해 download_all() 함수에서 다음과 같이 변경할 수 있습니다:
with futures.ThreadPoolExecutor(workers) as executor
=>
with futures.ProcessPoolExecutor() as executor:
코드를 변경해야 하는 부분에서는 ProcessPoolExecutor() 함수를 사용하여 병렬로 작업을 실행할 수 있는 프로세스 풀을 생성합니다. 그러나 여기서 worker 매개변수를 종종 생략하는데, 시스템이 사용 가능한 CPU 코어 수를 자동으로 프로세스로 활용할 수 있기 때문입니다.
이전에 언급한 대로, 병렬성은 일반적으로 CPU 바운드 시나리오에서 사용됩니다. I/O 바운드 작업의 경우 대부분의 시간이 대기 상태에 소요되며, 여러 프로세스를 사용하는 것은 멀티 스레딩과 비교하여 효율성을 향상시키지 않습니다. 실제로 CPU 코어의 제한으로 인해 멀티 프로세싱의 성능이 종종 멀티 스레딩보다 나쁠 수 있습니다.
Futures란 정확히 무엇인가요?
파이썬에서 Futures 모듈은 concurrent.futures와 asyncio에 위치하며, 둘 다 지연된 작업을 나타냅니다. Futures는 대기 상태에 있는 작업을 래핑하여 큐에 배치합니다. 이러한 작업의 상태는 언제든지 쿼리할 수 있으며, 작업이 완료된 후 결과 또는 예외를 검색할 수도 있습니다.
일반적으로 사용자들은 미래(Futures)를 생성하는 방법에 대해 걱정할 필요가 없습니다. 내부 메커니즘이 대신 처리해 주기 때문이죠. 실제로 해야 할 일은 이러한 Futures를 실행할 수 있도록 예약하는 것입니다.
예를 들어, Futures 모듈에서 Executor 클래스를 사용하면 executor.submit(func) 메서드를 사용하여 작업을 제출할 수 있습니다. 이 메서드는 func() 함수를 실행할 수 있도록 예약하고 작업을 나타내는 Future 객체를 반환합니다. 그런 다음 이 Future 객체를 사용하여 작업의 상태를 조회하거나 결과를 검색할 수 있습니다.
Futures 모듈에서 자주 사용되는 몇 가지 메서드는 다음과 같습니다:
- done(): 해당 작업이 완료되었는지 확인하는 메서드입니다. True는 작업이 완료되었음을 나타내고, False는 아직 진행 중이라는 뜻입니다. done()은 비차단 방식으로 동작하며 결과를 즉시 반환합니다.
- add_done_callback(fn): 이 메서드는 Future가 완료되면 실행될 콜백 함수 fn을 등록합니다. 콜백 함수 fn은 Future가 작업을 완료한 후에 알림을 받고 호출됩니다.
- result(): 이 메서드는 Future의 결과 또는 예외를 반환합니다. Future가 완료되었을 때 호출합니다. Future가 예외를 만났다면 result()는 해당 예외를 발생시킵니다.
- as_completed(fs): 이 함수는 Futures fs의 반복자를 가져와 완료될 때마다 Futures를 생성하는 반복자를 반환합니다.
그래서, 앞서 언급한 예제는 다음과 같은 형식으로도 작성할 수 있습니다:
import concurrent.futures
import requests
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one, site)
to_do.append(future)
for future in concurrent.futures.as_completed(to_do):
future.result()
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## 결과
https://en.wikipedia.org/wiki/Portal:Arts에서 129,886을 읽음
https://en.wikipedia.org/wiki/Portal:Biography에서 107,634을 읽음
https://en.wikipedia.org/wiki/Portal:Society에서 224,118을 읽음
https://en.wikipedia.org/wiki/Portal:Mathematics에서 158,984을 읽음
https://en.wikipedia.org/wiki/Portal:History에서 184,343을 읽음
https://en.wikipedia.org/wiki/Portal:Technology에서 157,949을 읽음
https://en.wikipedia.org/wiki/Portal:Geography에서 167,923을 읽음
https://en.wikipedia.org/wiki/Portal:Science에서 94,228을 읽음
https://en.wikipedia.org/wiki/Python_(programming_language)에서 391,905을 읽음
https://en.wikipedia.org/wiki/Computer_science에서 321,352을 읽음
https://en.wikipedia.org/wiki/Node.js에서 180,298을 읽음
https://en.wikipedia.org/wiki/Java_(programming_language)에서 321,417을 읽음
https://en.wikipedia.org/wiki/PHP에서 468,421을 읽음
https://en.wikipedia.org/wiki/The_C_Programming_Language에서 56,765을 읽음
https://en.wikipedia.org/wiki/Go_(programming_language)에서 324,039을 읽음
15개 사이트를 0.21698231499976828초에 다운로드함
여기서, 우리는 먼저 executor.submit()를 호출하여 각 웹사이트에서 내용을 다운로드하는 작업을 to_do라는 미래 큐에 넣고 실행을 대기시킵니다. 그런 다음 as_completed() 함수를 사용하여 각 미래가 완료될 때마다 결과를 출력합니다.
그러나 미래가 완료되는 순서가 목록의 순서와 일치하는 것은 아님을 유의해야 합니다. 완료 순서는 시스템 스케줄링 및 각 미래의 실행 시간에 따라 달라집니다.
왜 멀티스레딩에서 한 번에 하나의 스레드만 실행될 수 있을까요?
이전에 파이썬에서 메인 프로그램에서 한 번에 하나의 스레드만 실행될 수 있다고 언급했습니다. 이게 왜 그런 걸까요?
나중에 더 자세히 배울 Global Interpreter Lock (GIL) 개념을 간단히 소개해 드리겠습니다.
사실 파이썬 인터프리터는 스레드로부터 안전하지 않습니다. 동시 스레드로 인한 레이스 컨디션과 같은 문제를 해결하기 위해 파이썬은 Global Interpreter Lock (GIL)를 도입했습니다. 이 잠금은 한 번에 한 스레드만 파이썬 바이트코드를 실행할 수 있도록 보장합니다. 그러나 스레드가 I/O 작업으로 인해 차단될 때 GIL이 해제되어 다른 스레드가 계속해서 실행될 수 있습니다.
결론
이 글에서는 파이썬에서 동시성과 병렬성의 개념과 차이점을 먼저 살펴보았습니다.
동시성은 스레드와 작업 간에 전환을 통해 달성되지만, 어떤 순간에는 한 스레드 또는 작업만 실행될 수 있습니다. 반면에 병렬성은 여러 프로세스가 동시에 실행되는 것을 의미합니다.
동시성은 일반적으로 빈번한 I/O 작업이 있는 시나리오에서 사용되고, 병렬성은 CPU 집약적인 작업에 더 적합합니다.
우리는 웹 사이트 콘텐츠를 다운로드하는 예제를 통해 단일 스레드 방식과 Futures를 사용한 멀티 스레딩 버전 사이의 성능 차이를 비교했습니다. 잘 구현된 멀티 스레딩 접근 방식이 프로그램의 효율성을 크게 향상시킬 수 있다는 것이 명백합니다.
또한 Futures의 구체적인 원리를 탐구했습니다. done(), result(), as_completed()과 같은 일반적인 함수들을 다루며, 예제를 통해 그 사용법을 설명했습니다.
기억해야 할 중요한 점은 Python이 글로벌 인터프리터 락(GIL) 때문에 한 번에 하나의 스레드만 실행되도록 한다는 것입니다. 그러나 I/O 작업에 대해서는 스레드가 차단될 때 GIL이 해제되어 다른 스레드가 계속 실행될 수 있습니다.
