
파이토치는 현재 딥 러닝 분야에서 가장 핫한 라이브러리 중 하나입니다. ChatGPT가 출시된 이후 데이터 과학가와 머신 러닝 엔지니어들 사이에서 딥 러닝 라이브러리가 아마도 가장 많은 관심을 받고 있다고 볼 수 있습니다. 특히 이러한 라이브러리는 매우 빠르게 복잡한 다차원 계산을 수행하는 능력이 뛰어나며, 이러한 라이브러리는 우리가 신경망 모델을 훈련하는 방식을 바꾸었습니다. 특히 이러한 모델이 저장하고 최적화하는 많은 수의 가중치를 관리하는 데 매우 도움이 됩니다. TensorFlow(구글의 프레임워크)와 경쟁하며, PyTorch는 Meta의 오픈 소스 프레임워크로, 아주 멋지고 실용적인 문법을 사용하여 딥 러닝 모델을 훈련할 수 있는 기회를 제공합니다.
지금까지 이 PyTorch 시리즈에서 이 라이브러리를 사용하는 기본 개념을 배워왔습니다. 예를 들어:
- 텐서에 대한 기본 사항을 배우기
- PyTorch를 사용하여 처음 선형 모델(회귀)을 만드는 방법 이해하기
- 비선형 활성화 함수 및 비선형 문제 해결하는 방법 배우기
저희는 예제와 이전 블로그 게시물에서 몇 가지 사용자 정의 데이터셋을 사용했습니다. 이 시리즈에서 딥 러닝 모델을 교육하는 방향으로 진행하면서, PyTorch의 맥락에서 다양한 데이터셋을 통합하는 방법을 이해하는 데 매우 도움이 됩니다. 이 블로그 게시물에서는 라이브러리에서 사용자 정의 데이터셋을 다루는 방법을 배우고, 특히 세 가지 다른 유형의 데이터를 통합하는 방법을 다룰 것입니다:
- CSV 파일
- 이미지 데이터
- 텍스트 데이터
또한 데이터 배치의 개념에 대해 살펴보고, 이를 위해 PyTorch 사용자 정의 DataLoader를 사용하는 방법도 알아볼 것입니다. 이 블로그 게시물의 일부 영감은 Zero to Mastery Pytorch 무료 강좌에서 온 것입니다 — 많은 흥미로운 학습 예제가 있는 이 멋진 자료를 확인해보세요.
시작해 봅시다!
랜덤 데이터셋 생성
먼저, Pytorch에서 랜덤 데이터셋을 생성하여 DataLoader를 어떻게 사용할 수 있는지 이해해 봅시다:
import torch
from torch.utils.data import Dataset, DataLoader
class RandomIntDataset(Dataset):
def __init__(self, start, stop, x, y):
self.data = torch.randint(start, stop, (x,y))
self.labels = torch.randint(0, 10, (x,))
def __len__(self):
return len(self.labels)
def __str__(self):
return str(torch.cat((self.data, self.labels.unsqueeze(1)), 1))
def __getitem__(self, i):
return self.data[i], self.labels[i]
저희 RandomIntDataset은 랜덤한 torch 객체와 레이블을 생성합니다. 클래스에 던더 메서드를 도입하고 torch.utils.data.Dataset을 상속했음을 주목해주세요. (특히 데이터셋을 DataLoader와 결합할 때 유용하게 사용될 것입니다).
이전 클래스를 기반으로 첫 번째 데이터셋 객체를 생성해봅시다!
dataset = RandomIntDataset(100, 1000, 500, 10)
다시 말씀드리지만, Pytorch의 기본 클래스를 상속받았기 때문에 DataLoader를 사용하여 좋은 이터러블을 생성할 수 있습니다:
dataset_loader = DataLoader(dataset, batch_size=10, shuffle=True)
신경망 내에서 데이터를 배치로 전달하는 것은 매우 흔한 일이며 DataLoader 생성자가 깔끔한 batch_size 인자를 통해 이를 처리합니다! dataset_loader는 반복 가능하므로 순차적인 데이터 배치를 얻기 위해 next 및 iter를 사용할 수 있습니다.
data, labels = next(iter(dataset_loader))
data

새로운 iteration을 실행하고 data_loader의 다음 배치가 어떻게 이동하는지 확인해보세요! 이를 통해 데이터 및 레이블 객체 내부의 다른 데이터가 표시됩니다.
물론, 이 무작위 데이터 세트는 실제로 "사용자 지정 데이터 세트"로 간주하기 어렵습니다. 무작위 생성된 데이터와 작업하려고 할 가능성은 매우 낮습니다. 그러나 배치 처리에 익숙해지는 데 도움이 되는 이 소개 후에 첫 번째 CSV 파일을 PyTorch 파이프라인에 포함하여 계속 진행할 준비가 되었습니다!
DataLoader와 사용자 지정 데이터 세트 결합
우리가 보았듯이, 무작위 데이터 세트 사용은 단순한 연습일 뿐입니다. 그러나 이제 DataLoader와 데이터 배치가 어떻게 작동하는지 알기 때문에 이 지식을 사용하여 새로운 클래스를 만들어 PyTorch 데이터 세트를 사용할 수 있습니다:
import pandas as pd
class TaxiSample(Dataset):
def __init__(self):
super().__init__()
df = pd.read_csv('data/taxi_data_sample.csv')
features = ['passenger_count',
'pickup_longitude',
'pickup_latitude',
'dropoff_longitude',
'dropoff_latitude']
target = 'trip_duration'
self.features = torch.tensor(df[features].values,
dtype=torch.float32)
self.labels = torch.tensor(df[target].values,
dtype=torch.float32)
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
참고: 라이브러리를 게시물에서 지날 때까지 가져오고 있지만 모든 라이브러리는 스크립트의 처음에 가져와야 합니다!
우리가 사용하는 데이터셋은 Kaggle의 택시 여행 소요 시간 경쟁의 샘플 버전입니다. 여기서 csv를 init에 전달하고 있습니다 (이 기능을 더 다룰 수 있도록 인수로도 전달할 수 있습니다). DataLoader와 잘 어울리는지 확인해봅시다:
data_taxi = TaxiSample()
dataset_loader = DataLoader(data_taxi, batch_size=20, shuffle=True)
우리의 배치 크기가 20인 경우, 이 데이터셋에서 이터레이터를 만들 수 있습니다:
data_iterator = iter(dataset_loader)
data, labels = next(data_iterator)

멋져요! 이것들은 데이터셋에서 무작위로 선택한 처음 20개의 예시입니다. 위 이미지에서는 피처와 해당 레이블을 확인할 수 있어요.
있는 이미지 데이터를 사용 해보세요.
이 블로그 게시물의 이 섹션에서는 이미지 데이터 처리 능력을 보여주기 위해 Microsoft Research Cats. vs Dogs. 데이터셋과 함께 Pytorch를 사용할 것입니다. 먼저 pathlib를 사용하여 경로를 정의해 보겠습니다:
from pathlib import Path
data_path = Path(“data/dogs_cats”)
폴더 안에는 강아지 이미지와 고양이 이미지가 있는 두 개의 폴더가 있습니다. 각 폴더에서 이미지 경로를 추출해 봅시다:

이 섹션에서는 일반적인 컴퓨터 비전 변환 및 아키텍처를 제공하는 pytorch의 멋진 확장인 torchvision이 필요합니다.
from torchvision import datasets, transforms
다음으로 jpg 파일 이름을 읽어보겠습니다.
image_dogs_list = list((data_path/'dogs').glob("*.jpg"))
image_cats_list = list((data_path/'cats').glob("*.jpg"))
.. and combining our lists into a single object:
image_paths = image_cats_list + image_dogs_list
Let’s see if everything is working fine by extracting a random image from our list:
import random
from PIL import Image
random.seed(20)
random_image_path = random.choice(image_paths)
image_class = random_image_path.parent.stem
img = Image.open(random_image_path)
print(f"Random image path: {random_image_path}")
print(f"Image class: {image_class}")
print(f"Image height: {img.height}")
print(f"Image width: {img.width}")
img

귀여운 강아지!
이미지를 텐서로 변환할 때 일반적인 단계 중 하나는 이미지를 일반적인 포맷으로 조정하는 것입니다. transforms 라이브러리를 사용하여 이미지 크기를 조정하고 첫 번째 비전 파이프라인을 설정할 수 있습니다!
data_transform = transforms.Compose([
# 이미지 크기를 조정합니다
transforms.Resize(size=(64, 64)),
# 이미지를 수평으로 무작위로 뒤집습니다 — 이는 데이터 증가를 위한 단계입니다
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()])
위 transforms 파이프라인에서 우리는 다음을 수행합니다:
- 이미지를 64x64 픽셀 크기로 크기 조정합니다.
- 무작위로 수평으로 이미지를 뒤집습니다 — 이는 데이터 증가를 위한 일반적인 단계입니다.
- 이미지를 텐서로 변환합니다.
한 이미지와 해당 변환된 버전을 나란히 그래플로 표시합니다:
import matplotlib.pyplot as plt
def plot_transformed_images(image_paths: list,
transform: transforms.Compose,
n=3,
seed=100):
random.seed(seed)
random_image_paths = random.sample(image_paths, k=n)
for image_path in random_image_paths:
with Image.open(image_path) as f:
fig, ax = plt.subplots(1, 2)
ax[0].imshow(f)
ax[0].set_title(f"Original Image \nSize: {f.size}")
ax[0].axis("off")
transformed_image = transform(f).permute(1, 2, 0)
ax[1].imshow(transformed_image)
ax[1].set_title(f"Transformed Image \nSize: {transformed_image.shape}")
ax[1].axis("off")
fig.suptitle(f"Class: {image_path.parent.stem}", fontsize=16)
plot_transformed_images(image_paths,
transform=data_transform,
n=1)

저런! 변환을 통해 기본 텐서에 액세스하는 방법을 살펴보겠습니다. 예를 들어, 첫 번째 이미지의 경우:
image_path = image_paths[0]
data_transform(Image.open(image_path))

데이터 변환은 RGB 채널이 3개이고 64x64 텐서를 생성했습니다!
우리가 넘어가기 전에 더해야 할 마지막 단계 하나가 있습니다. 빠르게 텐서와 레이블을 생성하는 대안이 있습니다. 우리는 ImageFolder를 사용하여 편리하게 훈련 데이터를 생성할 수 있습니다.
train_data = datasets.ImageFolder(root=data_path, transform=data_transform, target_transform=None)
datasets.ImageFolder을 사용해요
class_names = train_data.classes
class_names

class_names에는 현재 태그(폴더 이름에서 읽음)가 컴퓨터 비전 모델에 포함되어 있습니다. train_data에는 컴퓨터 비전 프로세스에 대한 중요한 메타데이터가 포함되어 있습니다:

그리고 이제 데이터 세트 ImageFolders를 DataLoaders로 변환하는 것은 매우 간단합니다:
train_dataloader = DataLoader(dataset=train_data,
batch_size=5,
num_workers=1,
shuffle=True)
train_dataloader
보면 이터러블이 있네요:
img, label = next(iter(train_dataloader))
print(f"이미지 형태: {img.shape} -> [배치 크기, 색상 채널, 높이, 너비]")
print(f"레이블 형태: {label.shape}")

멋져요! 이 배치 크기가 5인 경우, 3채널(RGB)의 64x64 픽셀 이미지를 나타내는 3x64x64 텐서를 얻을 수 있습니다.
이제 이 데이터 배치를 사용하여 강아지와 고양이 이미지를 인식하는 머신러닝 모델을 훈련할 수 있어요! (사실, 이 시리즈의 다음 블로그 게시물에서 이를 진행할 예정이에요!)
텍스트 데이터 사용
이 글의 마지막 부분에서는 sklearn.datasets의 fetch_20newsgroups를 사용하여 문자열과 정수 간 매핑을 생성할 거에요:
from sklearn.datasets import fetch_20newsgroups
다음의 내용을 newsgroups에서 로드해 보겠습니다:
from sklearn.datasets import fetch_20newsgroups
categories = [
'comp.os.ms-windows.misc',
'rec.sport.baseball',
'rec.sport.hockey',
]
dataset = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=('headers', 'footers', 'quotes'))
corpus = [item for item in dataset['data']]
다음 함수는 텍스트를 전처리할 것입니다:
import nltk
import re
def preprocess_text(text: str) -> str:
'''
입력 데이터에서 텍스트를 전처리하여 특수 문자와 숫자를 제거합니다.
토큰 목록을 반환합니다.
'''
# 특수 문자 및 숫자 제거
text = re.sub("[^A-Za-z]+", " ", text)
tokens = nltk.word_tokenize(text.lower())
return tokens
아래는 우리 어휘를 생성하는 함수입니다:
def get_vocab(training_corpus):
# 특수 문자 추가
# 패딩, 라인 끝, 알 수 없는 용어
vocab = {'__PAD__': 0, '__</e>__': 1, '__UNK__': 2}
for item in training_corpus:
processed_text = preprocess_text(item)
processed_text.sort()
for word in processed_text:
if word not in vocab:
vocab[word] = len(vocab)
return vocab
전체 어휘 사이즈는 얼마인가요?
vocab = get_vocab(corpus)
len(vocab)
이미지 파일:
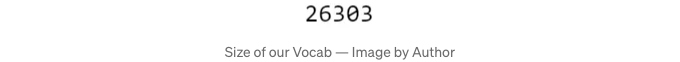
단어장은 2만 6천 개가 조금 넘는 단어를 포함하고 있으며, 각 단어는 정수로 매핑되어 있습니다:
이미지 파일:

이렇게 설정을 했으면, 문자를 정수로 변환하여 텐서로 변환하는 함수를 사용할 수 있습니다.
def text_to_tensor(text: str, vocab_dict: dict) -> torch.tensor:
'''
텍스트를 전처리하고 텐서 형식의 정수 매핑을 생성합니다.
'''
word_l = preprocess_text(text)
# 빈 텐서 초기화
tensor_l = []
# 단어 목록에서 __UNK__ 값을 가져옴
unk_ID = vocab_dict['__UNK__']
# 각 단어에 대해:
for word in word_l:
# 인덱스 가져옴
# 단어가 vocab_dict에 없으면 UNK로 할당
word_ID = vocab_dict.get(word, unk_ID)
# 텐서 목록에 추가
tensor_l.append(word_ID)
return torch.tensor(tensor_l)
이 함수가 텍스트를 텐서로 어떻게 변환하는지에 대한 예시는 아래와 같습니다. 첫 번째 텍스트의 처음 200 단어를 사용하여 검사합니다:
snippet = corpus[0][0:200]
print('텍스트 "{}"는 다음과 같이 텐서로 표현됩니다: {}'.format(snippet, text_to_tensor(snippet, vocab)))

테이블 태그를 마크다운 형식으로 변경해주세요.
이 PyTorch 시리즈의 더 많은 포스트를 알아보려면 다음 링크를 확인해보세요:
- Tensor 소개;
- 선형 모델 만들기;
- 활성화 함수 및 비선형 문제;
이 게시물의 자료:
- 택시 여행 기간 — https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- 고양이와 개 이미지 인용: @Inproceedings (컨퍼런스)'asirra-a-captcha-that-exploits-interest-aligned-manual-image-categorization, 저자 = 'Elson, Jeremy 및 Douceur, John (JD) 및 Howell, Jon 및 Saul, Jared', 제목 = 'Asirra: A CAPTCHA that Exploits Interest-Aligned Manual Image Categorization', 책 제목 = 'Proceedings of 14th ACM Conference on Computer and Communications Security (CCS)', 연도 = '2007', 월 = '10월', 발행사 = 'Association for Computing Machinery, Inc.', url = 'https://www.microsoft.com/en-us/research/publication/asirra-a-captcha-that-exploits-interest-aligned-manual-image-categorization/', 판본 = 'Proceedings of 14th ACM Conference on Computer and Communications Security (CCS)', '