
소개
다양한 통계에 따르면 모델들을 개발하는데 50%와 90% 사이의 모델들이 제품화되지 못하는 경우가 많습니다. 이는 작업을 구조화하는 데 실패한 결과입니다. 학계나 Kaggle에서 습득한 기술이 수천 명의 사용자가 사용하는 머신러닝 기반 시스템을 구축할 수 있을 정도로 충분하지 않은 경우가 종종 있습니다.
산업계에서 머신러닝 업무를 찾을 때 가장 필수적인 기술 중 하나는 MLflow와 같이 복잡한 파이프라인을 조정하는 도구를 사용하는 능력입니다.
이 글에서는 프로젝트를 여러 단계로 구조화하고 모든 단계를 체계적으로 관리하는 방법을 알아볼 것입니다.
이 글의 스크립트를 실행하려면 Deepnote를 사용합니다: 협업 데이터 과학 프로젝트 및 프로토타입에 적합한 클라우드 기반 노트북입니다.
Mlflow이란?
MLflow는 Databricks가 개발한 기계 학습의 완전한 라이프사이클 관리를 위한 오픈 소스 플랫폼입니다.
MLflow은 훈련 중인 모델을 모니터링하고 아티팩트 스토어를 사용하며 모델을 제공하는 등 여러 가지 기능을 제공합니다. 오늘은 MLflow를 머신러닝 파이프라인의 오케스트레이터로 사용하는 방법을 살펴볼 것입니다. 왜냐하면 특히 인공지능 세계에서는 다양한 단계와 실험이 있기 때문에 깔끔하고 이해하기 쉽고 쉽게 재현할 수 있는 코드를 갖추는 것이 중요합니다.
그런데 정확히 MLflow를 사용하여 관리해야 하는 단계는 무엇일까요? 이는 우리 작업의 문맥에 따라 달라집니다. 머신러닝 파이프라인은 우리가 일하는 환경과 최종 목표가 무엇인지에 따라 달라질 수 있습니다. 예를 들어, 캐글 과제를 해결하기 위한 파이프라인은 대부분 모델링에 시간을 소비하므로 간단합니다. 반면 산업에서는 데이터 및 코드 품질을 확인하는 단계가 여러 개일 수 있습니다.
여기서는 매우 기본적인 파이프라인을 가정합니다.
우리는 가능한 한 각 단계를 독립적으로 개발하길 원합니다. 모델링을 맡은 사람들은 데이터 수집, 데이터 다운로드, 정리 등과 무관하게 그 구성요소만 개발하면 됩니다.
우리는 (과장해서) 각 파이프라인 구성요소에 대한 팀이 있는 상황을 더 가정해 봅시다. 우리는 각 팀이 가장 잘 아는 도구와 언어로 작업할 수 있도록 하여 각 팀의 작업을 용이하게 하길 원합니다. 그래서 각 단계마다 독립적인 개발 환경을 원합니다. 예를 들어, 데이터 다운로드는 C++로 개발하고, 데이터 정리는 Julia로, 모델링은 Python으로, 그리고 추론은 Java로 개발할 수 있습니다. MLflow를 통해 가능합니다!
MLflow를 설치하려면 pip를 사용할 수 있습니다.
MLflow 프로젝트 정의
MLflow 프로젝트는 3가지 주요 부분으로 구성되어 있습니다:
- 코드: 작업 중인 작업을 해결하기 위해 작성하는 코드
- 환경: 환경을 정의해야 합니다. 코드 실행에 필요한 종속성은 무엇인가요?
- MLflow 프로젝트 정의: 각 MLflow 프로젝트에는 사용자가 프로젝트와 상호 작용하는 방법과 무엇을 실행해야 하는지를 정의하는 MLproject라는 파일이 있습니다.
이 글에서 각 파이프라인 구성 요소의 코드는 간편함을 위해 Python으로 작성할 것입니다. 그러나 이전에 언급했듯이 이것이 반드시 그렇다는 것은 아닙니다.
환경을 어떻게 관리할까요? 재현 가능하고 격리된 개발 환경을 정의하려면 여러 도구를 사용할 수 있습니다. 주요 도구로는 docker와 conda가 있습니다. 이 예에서는 conda를 사용할 것인데, conda를 사용하면 의존성을 빠르고 쉽게 지정할 수 있지만, docker는 다소 어려운 학습 곡선을 가지고 있습니다. conda를 다운로드해야 한다면, 가벼운 버전인 miniconda를 추천합니다.
개발 환경을 정의하는 conda.yml 파일을 만들어 가상 환경을 생성할 수 있습니다.
우리가 할 일은 conda.yml에서 pip 사용을 정의하고 나중에 wandb와 같은 추가 설치를 위해 pip를 사용하는 것입니다. (참고로 이 경우에는 wandb가 실제로 필요하지 않습니다.)
conda.yml
name: download_data channels:
- conda-forge
- defaults dependencies:
- requests
- pip
- mlflow
- hydra-core
- pip:
- wandb
이제 conda.yml에 정의된 환경을 생성하기 위해 다음 명령을 CLI에서 실행할 수 있습니다.
conda env create --file=conda.yaml
이제 활성화해 봅시다.
conda activate download_data
이제 MLproject 파일을 정의해야 합니다. 이 파일에 유의해 주세요. yaml로 작성되어 있지만 확장자가 필요하지 않습니다.
이 파일에서는 먼저 단계의 이름과 사용할 콘다 환경을 정의합니다. 그런 다음 계산을 시작할 주요 Python 파일인 entry point를 지정해야 합니다. 그 후에는 파일을 시작하는 데 필요한 매개변수도 정의해야 합니다. 예를 들어, 다운로드 단계에서는 데이터를 다운로드할 URL을 전달할 것으로 예상합니다.
마지막으로 mlflow가 실제로 시작해야 하는 명령을 표시합니다.
name: download_data conda_env: conda.yml
entry_points: main: parameters: data_url: description: 데이터 다운로드 URL type: uri
command: >-
python main.py --data_url {data_url} #중괄호에 입력 변수를 넣으세요
이제 본격적으로 주 Python 코드 main.py를 작성할 준비가 됐습니다.
파이썬 코드에서는 MLproject로부터 예상되는 인수 "data_url"을 입력으로 받아야 합니다. 그런 다음 사용자가 이 인수를 cli에서 전달할 수 있도록 argparser를 사용할 수 있습니다.
그런 다음 run() 함수를 실행하는데, 이 함수는 URL에서 CSV 파일을 읽어 로컬로 저장하는 일을 하는데, 이는 이 구성요소에서 기대되는 데이터의 간단한 다운로드를 수행합니다.
여기에는 MIT 라이선스의 오픈 소스 데이터가 사용되었습니다. 구체적으로, GitHub의 다음 URL에서 찾을 수 있는 클래식 Titanic 데이터셋입니다: https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
이렇게 main.py 파일을 작성할 수 있습니다.
우리는 mlflow를 사용하여 전체 구성 요소를 실행할 수 있습니다. mlflow에서 매개변수를 지정하려면 -P 플래그를 사용합니다.
mlflow run . -P data_url="https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
터미널 로그에서 처음에 Mlflow가 conda.yml을 사용하여 개발 환경을 재생성하려고 시도하고(첫 번째 시도에 시간이 걸릴 수 있음) 그런 다음 코드를 실행합니다. 결과적으로 데이터셋이 다운로드되는 것을 볼 수 있어야 합니다!

구성 요소에서 파이프라인으로
좋아요, 이제 한 구성 요소로 구성된 MLflow 프로젝트를 만드는 기초가 마련되었습니다. 하지만 전체 파이프라인을 어떻게 개발할까요? MLflow에서 파이프라인이란 다른 MLflow 프로젝트로 이뤄진 것으로 구성됩니다!
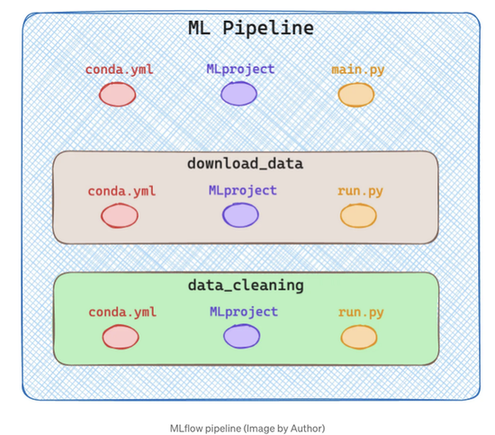
루트 디렉토리에서 여러 구성 요소로 파이프라인을 생성하고 싶으므로 각 구성 요소용 서브디렉토리를 두 개 만들겠습니다. 다음 이미지에서 확인할 수 있습니다.

간단하게 말하자면, 데이터 다운로드 및 데이터 정리 두 단계만 실행합니다. 물론, 실제 파이프라인은 훈련, 추론 등 훨씬 많은 단계로 구성됩니다.
위 다이어그램에서 각 구성 요소/단계는 자체적으로 3개의 파일로 설명된 MLflow 프로젝트입니다. 전체 구조는 다음 이미지에서 확인할 수 있습니다.
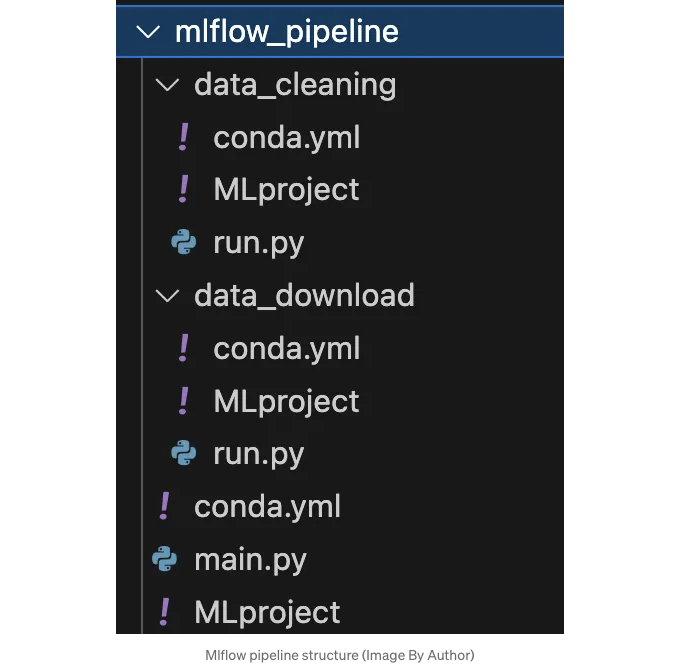
이제 이 디렉토리에 있는 모든 파일을 어떻게 정의했는지 살펴봅시다.
🟢 mlflow_pipeline/conda.yml
이 파일은 이전과 다르지 않습니다. 개발 환경을 정의합니다.
#conda.yaml
name: mlflow_pipeline
channels:
- conda-forge
- defaults
dependencies:
- pandas
- mlflow
- requests
- pip
- mlflow
🟢 mlflow_pipeline/MLproject
파이프라인의 모든 단계를 항상 실행할 필요는 없을 수도 있지만 때로는 일부 단계만 실행하고 싶을 때가 있습니다. 따라서 쉼표로 구분된 실행하려는 모든 단계를 정의하는 문자열을 입력으로 받습니다.
MLflow를 실행할 때 다음과 같은 명령을 사용할 것입니다:
mlflow run . P steps=”download,cleaning,training”
name: mlflow_pipeline conda_env: conda.yml
entry_points: main: parameters: steps: description: 쉼표로 구분된 수행할 단계 type: str
data_url:
descripton: 데이터의 URL
type: uri
command: >-
python main.py --steps {steps} --data_url {data_url}
🟢 mlflow_pipeline/main.py
이 파일에서는 이제 단계를 처리할 것입니다. 입력을 파싱하면 문자열을 쉼표로 분할하여 모든 단계가 배열에 포함됩니다.
각 단계에 대해 mlflow.run을 실행하며, 이번에는 cli를 사용하지 않고 직접 Python에서 실행합니다. 명령어는 매우 유사하지만 각 실행에는 구성 요소 경로와 entry point(항상 main)를 지정하고 필요한 경우 매개변수를 전달합니다.
여기서부터 다른 구성 요소를 정의하는 방법은 이전에 했던 것과 매우 유사합니다. 다운로드 및 정리 단계를 계속 설명하겠습니다. ⚠️ 모든 conda.yml은 동일하므로 여러 번 반복하는 것을 피하겠습니다.
🟢 mlflow_pipeline/data_download/MLproject
이전과 마찬가지로 data_download은 데이터를 다운로드하기 위한 input 매개변수, 즉 데이터의 URL을 예상하며, 나머지는 표준입니다.
name: download_data
conda_env: conda.yml
entry_points:
main:
parameters:
data_url:
description: 데이터 다운로드 URL
type: str
command: >-
python run.py --data_url {data_url}
🟢 mlflow_pipeline/data_download/run.py
run.py 파일에서는 MLproject에 정의된 URL 파일을 가져와 pandas 데이터프레임을 열고 .csv 확장자로 데이터셋을 로컬에 저장합니다.
🟢 mlflow_pipeline/data_cleaning/MLproject
이 경우, 데이터 클리닝은 매우 간단합니다. 파이프라인 구조화에 초점을 맞추고 복잡한 단계 생성에 대해서는 다루지 않습니다. 입력 매개변수를 예상하지 않으므로 run.py만 실행하면 됩니다.
name: data_cleaning
conda_env: conda.yml
entry_points:
main:
command: >-
python run.py
🟢 mlflow_pipeline/data_cleaning/run.py
실제 데이터 클리닝에서는 null 값이 포함된 모든 행을 삭제하고 새로운 데이터프레임을 CSV로 로컬 루트 폴더에 저장합니다.
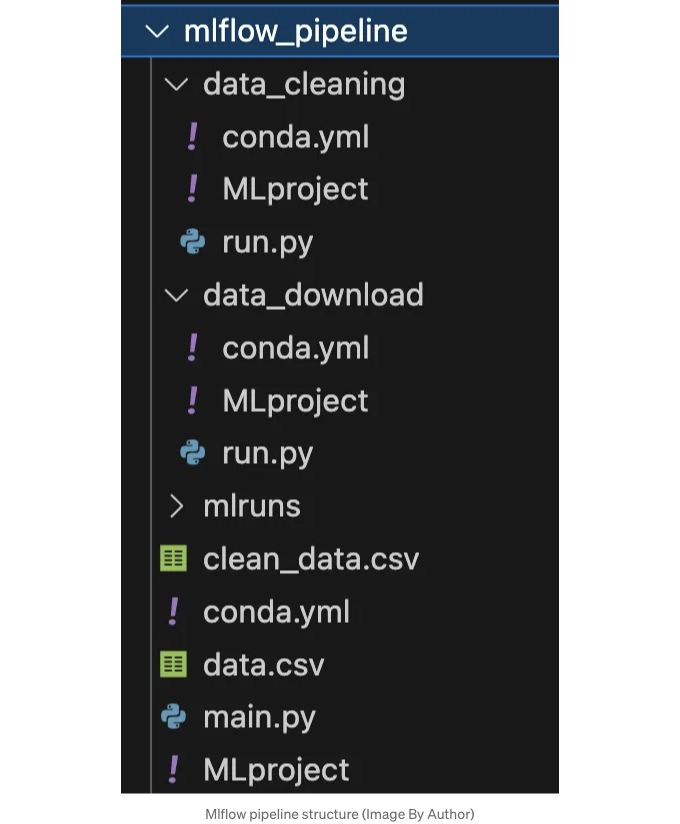
이제 우리가 실수를 하지 않았다면 적절한 매개변수를 지정하여 단일 mlflow 명령어로 전체 파이프라인을 실행할 수 있습니다. 그럼 단계와 데이터셋의 URL을 지정하세요.
mlflow run . -P steps="data_download,data_cleaning" -P data_url="https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
모든 단계가 올바르게 수행될 것이며, 여러분의 디렉토리에 두 개의 새 CSV 파일이 생길 것입니다! 🚀
결론
이 기사에서는 MLflow에서 프로젝트가 구성되는 방식과 파이프라인이 프로젝트 시퀀스에 의해 정의되는 방법을 살펴 보았습니다.
파이프라인의 각 단계는 자체 환경에 의해 정의되기 때문에 독립적으로 개발할 수 있습니다. 각 단계의 개발에는 다른 언어와 도구를 사용할 수 있으며, MLflow는 오로지 Orchestration 역할만을 합니다. 이 기사가 여러분께 MLflow의 사용 방법에 대한 아이디어를 제공해 드렸기를 바랍니다.
MLFlow는 머신러닝 실험을 추적하는 데 매우 유용하지만, 복잡성과 가파른 학습 곡선 때문에 MLOps에 새로운 작은 프로젝트나 팀들을 망설이게 할 수 있습니다. 그러나 실험 추적, 데이터 및 모델 버전 관리, 협업이 중요한 경우에는 매우 편리하며 중대규모 프로젝트에 이상적입니다.
MLflow가 제공하는 기능들은 매우 다양합니다. 예를 들어, 모델의 성능을 모니터링하거나 생성한 아티팩트를 저장하는 데 사용할 수 있습니다. 앞으로 다른 도구들을 MLflow에 통합하여 그 잠재력을 최대한 활용하는 방법을 소개할 예정이니 기대해 주세요!
만약 이 기사에 관심이 있다면 제 Medium 팔로우해주세요! 😁
💼 Linkedin ️| 🐦 Twitter | 💻 Website