문제 😕
데이터는 새로운 석유입니다. 점점 더 많은 조직이 중요한 이유로 Azure 리소스 로그를 로그 분석 워크스페이스로 전송하기를 선택하고 있습니다:
- 로그 분석 워크스페이스의 보존 기간을 최대 12년까지 구성할 수 있습니다. 이는 감사와 같은 요구 사항을 보완합니다.
- Kusto 쿼리 언어 구문을 사용하여 강력한 쿼리를 실행할 수 있어 필요한 데이터만 좁혀 보거나 시각화하여 시가 차트 등을 사용할 수 있습니다.
로그 분석 워크스페이스로 전송되는 데이터 예시로는 Cosmos DB(NoSQL 데이터베이스)에서 활성화된 CDBDataPlaneRequests 테이블이 있습니다.
해당 테이블에서 어떤 유용한 데이터를 얻을 수 있을까요?
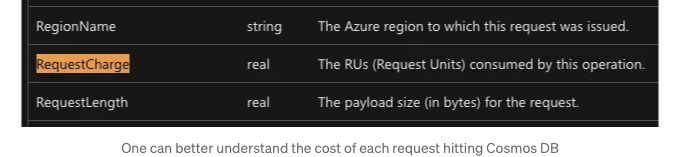
이는 전체 테이블 중 일부에 불과합니다. 실제로 Cosmos DB에서 사용할 수 있는 테이블은 더 많습니다. 더불어, 모든 Azure 리소스를 위한 가능한 모든 테이블을 상상해보세요!
일반적으로 Azure 리소스에서 로그를 전송할 수 있는 기능은 "진단 설정(diagnostic settings)"이며, 데이터는 테이블 형식으로 전송됩니다. 진단 설정에 대한 자세한 내용은 여기에서 확인해주세요.
모든 그 귀중한 데이터를 활용할 수 있게 되면 아마도 즉시 분석을 수행할 수 있어서 설레일 것입니다. 다른 말로 하면, "데이터 과학".
로그 분석 워크스페이스에 프로그래밍 방식으로 액세스하면 데이터로 수행 가능한 작업은 무궁무진합니다. Python Jupyter 노트북에서 데이터를 쉽게 분석할 수도 있고요.
이것의 제한을 궁금해하시나요? 이 설명서를 즐겨찾기에 추가해주세요.
이제 세부 사항에 대해 깊이 파고들어볼까요?
사전 준비 사항 📚

이 글을 처음부터 끝까지 따라하고 싶다면 이 사항을 준비해주세요:
- Visual Studio Code (VS Code)를 사용하는 IDE (VS Code에 특화된 확장 프로그램을 사용할 것입니다)
- Python의 기본 지식
- azure-identity, azure-monitor-query, pandas 등의 비기본 라이브러리가 설치된 Python 환경
- 로그를 보내는 기존의 Log Analytics 워크스페이스
- [선택 사항] 가능하다면 진단 설정 로그를 Log Analytics 워크스페이스로 보내기 위한 Cosmos DB 계정이 있어야 합니다. 저의 스크립트는 이에 기반합니다.
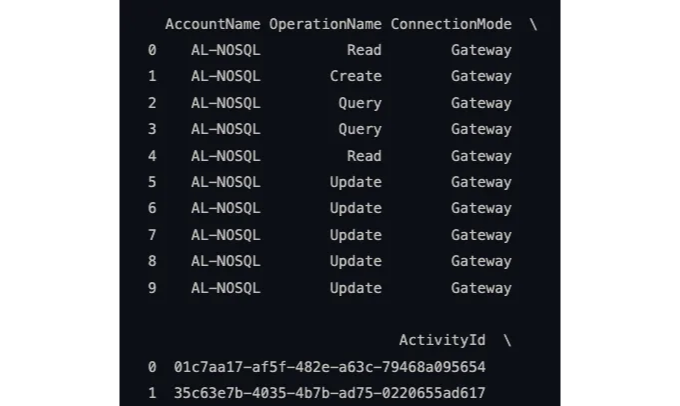
지금은 로그 분석 워크스페이스에서 데이터를 검색하는 Python 스크립트를 확인해 봅시다.
솔루션 💯

이 섹션에서는 샘플 Python 스크립트를 부분별로 분해합니다. 모든 부분을 이해한 후에 모두 조합해도 괜찮습니다(부분은 위에서 아래로 순서대로 나열되어 있습니다)!
[1] 필요한 라이브러리 가져오기
이미 해당 Python 라이브러리들이 없는 경우에는 설치해야 할 수도 있습니다: azure-identity, azure-monitor-query, pandas
import os
import pandas as pd
from datetime import datetime, timezone
from azure.monitor.query import LogsQueryClient, LogsQueryStatus
from azure.identity import DefaultAzureCredential
from azure.core.exceptions import HttpResponseError
[2] 스크립트에 필요한 클라이언트 초기화하기
우리는이 스크립트를위한 두 개의 별개의 클라이언트를 시작해야합니다. 간단함을 위해 동기 클라이언트를 선택하겠습니다:
# 필요한 클라이언트 생성 (동기, 공용 클라우드)
credential = DefaultAzureCredential()
client = LogsQueryClient(credential)
DefaultAzureCredential() 클래스를 이해하는 데 어려움이 있는 경우 이 설명서를 읽어보십시오.
[3] Log Analytics 워크스페이스 ID 정의
Log Analytics 워크 스페이스 ID를 얻으려면 Azure Portal로 이동하여 'Log Analytics 워크 스페이스 - 개요'로 이동하면 됩니다. 예시:
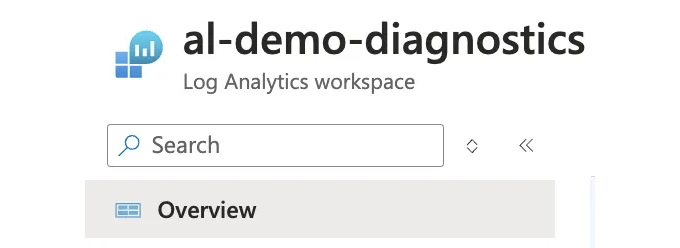

# 로그 분석 워크 스페이스 ID를 정의합니다
LA_WORKSPACE_ID = "<당신의-로그-분석-워크 스페이스-ID>"
[4] 쿼리 정의
로그 분석 워크스페이스에서 데이터를 가져오는 쿼리는 Kusto Query Language (KQL) 형식으로 작성됩니다. 특정 예시에서는 Cosmos DB와 관련된 로그를 확인하고 있습니다:
# 쿼리 정의 (Kusto Query Language)
query = """
CDBDataPlaneRequests
| where AccountName == toupper('al-nosql')
| where TimeGenerated > ago(2h)
| take 10
"""
Azure 자원이 전송한 로그에 적합한 쿼리로 위의 쿼리를 자유롭게 수정해보세요. 대부분의 Azure 자원에 대해 동작하는 매우 일반적인 쿼리는 다음과 유사합니다:
"""
AzureDiagnostics
| take 1
"""
[5] 쿼리의 시간 범위를 정의하세요 (선택 사항)
쿼리의 시간 범위를 KQL 쿼리 내에서도 정의할 수 있는 옵션이 있음을 유의해주세요 (3단계에서 설명됨).
본 문서를 위해, 사용자의 쿼리가 너무 비싼 비용이 들지 않도록 고려하여 클라이언트를 초기화할 때 상대적으로 작은 시간 범위를 강제로 적용하도록 해둡니다.
# 쿼리를 위한 시간 범위 정의 (위의 쿼리에서도 이를 정의할 수 있음)
start_time=datetime(2024,2,25, tzinfo=timezone.utc)
end_time=datetime(2024, 2, 26, tzinfo=timezone.utc)
[6] Log Analytics 작업 영역에서 쿼리하세요!
이제 Log Analytics 작업 영역에서 모든 흥미로운 데이터를 가져오는 시간입니다.
아래 코드에 오류 처리가 추가되었음을 주목하고 Pandas 데이터프레임을 표시할 것임을 확인하세요.
try:
response = client.query_workspace(
workspace_id=LA_WORKSPACE_ID,
query=query,
timespan=(start_time, end_time)
)
if response.status == LogsQueryStatus.PARTIAL:
error = response.partial_error
data = response.partial_data
print(data)
elif response.status == LogsQueryStatus.SUCCESS:
data = response.tables
for table in data:
df = pd.DataFrame(data=table.rows, columns=table.columns)
print(df)
except HttpResponseError as err:
print(f"Encountered error: {err}")
하지만 많은 열이 있는 경우 인쇄된 데이터 프레임이 모든 내용을 표시하지 않을 수 있음을 알 수 있습니다. 더 나쁜 점은 즉각적인 분석을 위해 예쁘고 조직적으로 보이지 않는다는 것입니다.
아마도 CSV로 데이터 프레임을 보내보는 게 좋을 수 있습니다. : )
[7] 데이터를 CSV 파일로 전송
CSV 파일을 사용하면 적어도 Microsoft Excel/Google Sheets 스프레드시트로 가져올 수 있는 등 재미있는 일을 할 수 있어요.
아래 코드 조각에서 CSV 파일 경로를 정의해주세요:
# 데이터프레임을 csv로 내보내기
csv_filename = "<원하는-경로>/output.csv"
df.to_csv(csv_filename)
[보너스] VS Code 확장 기능을 사용하여 멋진 형식의 테이블을 볼 수도 있어요!
좋은 소식은 몇 가지 변경만으로 Jupyter 노트북을 활용할 수 있다는 것입니다.
- 우선, 스크립트 확장자를 ".ipynb"로 변경하세요:

- VS Code에서 Jupyter 노트북을 실행할 수 있도록 필요한 확장 프로그램/패키지를 설치하세요. 처음으로 노트북을 실행하려고 시도하면 아래 항목을 설치하라는 메시지가 자동으로 표시됩니다:
-
파이썬 확장
-
주피터 확장
-
ipykernel 패키지
VS Code를 설치한 후에는 VS Code를 다시 로드해주세요.
[3] 위의 모든 것들을 설치한 후에는 VS Code에서 Jupyter Notebook을 실행할 수 있어야 합니다! 그러나 실행하면 출력물이 잘못 서식이 지정된 것을 볼 수 있습니다 (아래 스크린샷이 잘린 상태로 표시됨):
[4] Jupyter 노트북의 오른쪽 상단 어딘가에서 "Variables" 탭을 클릭하세요:
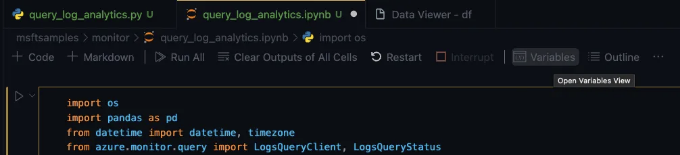
[5] 터미널에 새 탭이 생성됩니다. "JUPYTER: VARIABLES"라고 표시된 탭을 찾아 "df" 변수를 찾은 다음, 사각형 기호 위로 커서를 가져가면 "데이터 뷰어에 변수 표시"라는 메시지가 표시됩니다. 이것을 클릭하세요.
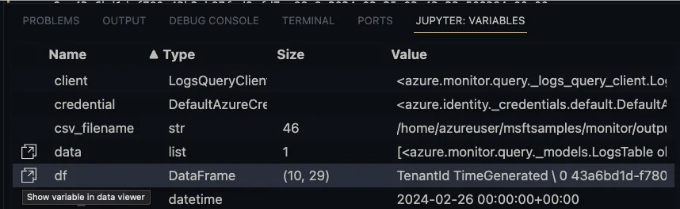
[6] 그러면 이전에 찾고 있던 완벽하게 표시된 결과를 보여주는 새 탭이 열립니다:
배운 점 👊

만약 지금까지 이 글을 주의 깊게 따라오셨다면 다음 개념들을 배우셨을 것입니다:
- Log Analytics 워크스페이스를 쿼리하는 데 필요한 필수 Python 라이브러리 파악
- 필요한 Python 클라이언트 파악
- KQL 및 효율적인 쿼리를 작성하는 데 최선의 방법에 대한 고수준 이해
- 무엇보다 중요한 것은 Python을 사용하여 Log Analytics 워크스페이스를 쿼리하고 VS Code에서 멋지게 표 형식으로 결과를 표시하는 방법
다음 스텝 🤔

이 글에 대한 궁금한 점이나 피드백이 있다면 댓글로 남겨주세요 (네, 댓글을 확인해요). 또한 쓸 주제에 대한 제안도 환영합니다.
제가 하는 일이 궁금하다면 아래 링크를 확인해보세요:
- 내 개인 웹사이트
- LinkedIn에서 연락하세요
- 내 Fiverr 서비스를 확인하세요
- 커피 한 잔 사주세요
다음에 또 뵙겠습니다!
간단한 영어로 🚀
In Plain English 커뮤니티의 일원이 되어 주셔서 감사합니다! 떠나시기 전에:
- 작가를 칭찬하고 팔로우하는 것 잊지 마세요! 👏️️
- 저희를 팔로우하세요: X | LinkedIn | YouTube | Discord | 뉴스레터
- 다른 플랫폼에서 더 많은 콘텐츠를 즐길 수 있어요: Stackademic | CoFeed | Venture | Cubed
- 더 많은 콘텐츠: PlainEnglish.io