| Library | Purpose |
|---|---|
| Requests | For sending HTTP requests |
| BeautifulSoup | For parsing HTML and XML |
| Tkinter | For building the GUI |
- Pandas: 추출된 데이터를 위한 데이터베이스를 생성하는 데 사용됩니다.
- Requests: 웹사이트에 접근 권한을 요청하는 데 사용됩니다.
- BeautifulSoup: 웹상에서 데이터를 찾는 데 사용됩니다.
작업: 이메일 목록 추출 및 CSV로 변환하기
여러 주제에서 많은 이메일을 가져와야 했습니다.
"수동으로는 절대 할 수 없어" 라고 생각했습니다. 그렇게 하면 시간이 많이 걸리고 지루할 것이라고 생. 따라서 나는 파이썬 기술을 사용하기로 결정했습니다.
웹 사이트에는 다음과 같은 데이터가 있습니다:
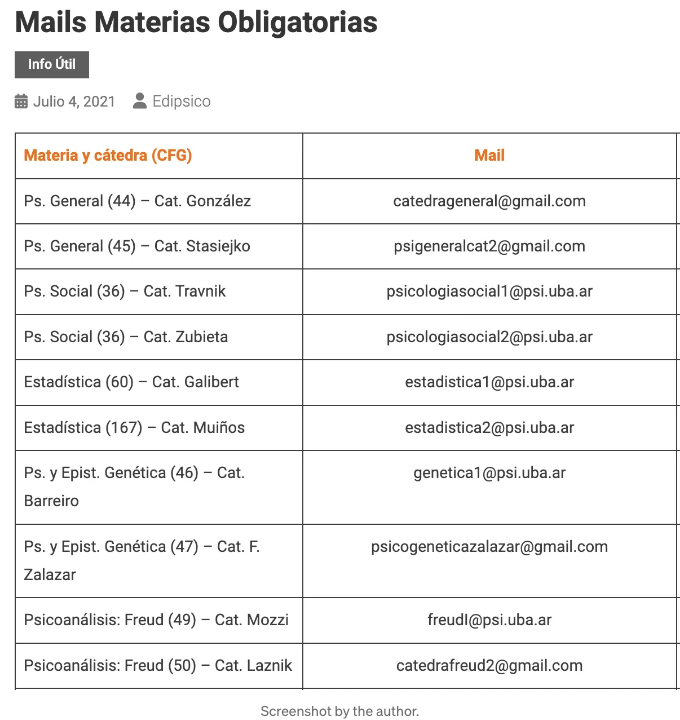
네, 과목 이름과 이메일이 포함된 표가 있습니다.
이 프로젝트의 목표는 이 데이터를 사용하여 CSV 파일을 생성하는 것입니다.
단계 1. 모듈 가져오기
먼저 사용할 Python 라이브러리를 가져와 봅시다:
- pandas.
- requests.
- BeautifulSoup.
import pandas as pd
import requests
from bs4 import BeautifulSoup
단계 2. 데이터 찾기
2.1. 웹 스크래핑은 어떻게 작동되나요?
웹에서 데이터를 추출하는 것이 가능한 이유는 무엇인가요?
답은 HTML(HyperText Markup Language)에 달려 있습니다. HTML은 웹 브라우저에서 표시할 문서의 표준 마크업 언어입니다.
웹사이트 어디에서든 마우스 오른쪽 버튼을 클릭하고 Inspect를 선택하면 웹의 코드가 오른쪽에 표시됩니다:
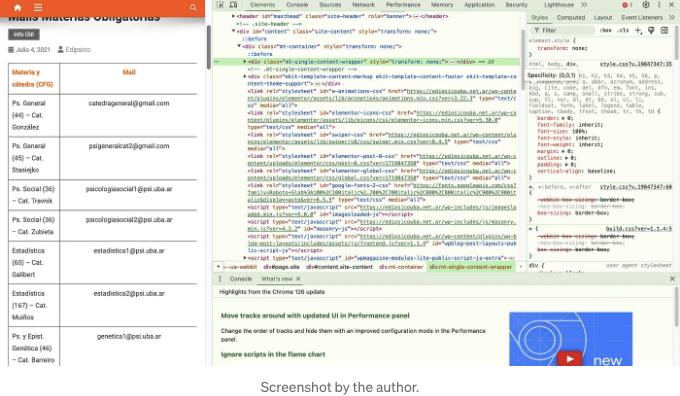
파이썬은 (일부 라이브러리와 함께) 이 HTML 코드를 "읽고" 원하는 데이터를 찾는 것입니다.
더 자세한 내용은 향후 기사에서 확인해보세요.
2.2. HTML 가져오기 함수
우선, 웹 사이트에서 HTML 코드를 가져와야 합니다.
URL을 매개변수로 하는 get_html 함수를 생성하는 방법은 다음과 같습니다:
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_html(url):
try:
response = requests.get(url) # 웹 사이트에서 HTML을 요청합니다
return response.text
except Exception as e: # 가능한 오류를 처리하기 위한 예외 처리
print(f"웹 페이지를 가져오는 데 실패했습니다: {e}")
return ""emails = set() # 중복을 피하기 위한 코드입니다
단계 3. 데이터 추출
다음 단계는 우리가 원하는 데이터를 추출하는 것입니다.
우리는 이전 함수에서 HTML 코드를 가져오는 extract_data 함수를 만들 수 있습니다. 이는 다음 단계를 포함합니다:
- BeautifulSoup 클래스 초기화.
- 테이블을 찾는 변수 설정.
- 데이터를 수집할 빈 리스트.
- 데이터를 검색하는 for 루프.
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_html(url):
try:
response = requests.get(url) # 웹사이트로부터 HTML을 요청합니다.
return response.text
except Exception as e: # 가능한 오류를 처리하기 위한 부분
print(f"웹 페이지를 가져오는 데 실패했습니다: {e}")
return "" # 중복을 피하기 위해 이메일 집합으로 설정
def extract_data(html):
soup = BeautifulSoup(html, 'html.parser') # BeautifulSoup 클래스를 초기화
table = soup.find('table') # 테이블을 찾습니다.
data = [] # 데이터를 수집할 빈 리스트
if table:
rows = table.find_all('tr') # 모든 테이블을 찾습니다.
for row in rows[1:]: # 헤더 행을 건너 뜁니다.
cols = row.find_all('td') # 테이블에서 셀을 찾습니다.
if len(cols) == 4: # 항상 4개의 열이 있다고 가정
catedra_name = cols[0].text.strip() # 과목 이름
email = cols[1].text.strip() # 이메일
data.append({'catedra': catedra_name, 'email': email}) # 데이터 리스트에 추가
return data
단계 4. 함수 호출 및 데이터 CSV로 저장
이제 모든 준비가 되었으므로 함수를 호출해야 합니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_html(url):
try:
response = requests.get(url) # 웹사이트에서 HTML 가져오기
return response.text
except Exception as e: # 가능한 오류 처리
print(f"웹 페이지를 가져오는 데 실패했습니다: {e}")
return "" # 중복을 피하기 위해 이메일 집합
def extract_data(html):
soup = BeautifulSoup(html, 'html.parser') # BeautifulSoup 클래스를 초기화
table = soup.find('table') # 테이블 찾기
data = [] # 데이터 수집을 위한 빈 리스트
if table:
rows = table.find_all('tr') # 모든 테이블 찾기
for row in rows[1:]: # 헤더 행 건너 띄기
cols = row.find_all('td')
if len(cols) == 4: # 항상 4개의 열
catedra_name = cols[0].text.strip() # 과목 이름
email = cols[1].text.strip() # 이메일
data.append({'catedra': catedra_name, 'email': email})
return data
url = "https://edipsicouba.net.ar/uncategorized/listado-mails-materias-electivas/" # 여러분의 링크 설정
html = get_html(url) # get_html() 함수 호출하여 내용을 변수에 저장
data = extract_data(html) # extract_data() 함수 호출하여 결과를 변수에 저장
df = pd.DataFrame(data) # 데이터를 데이터프레임으로 변환
df.to_csv('mail_info.csv', index=False) # 데이터프레임을 CSV 파일로 저장
print("데이터가 성공적으로 추출되어 mail_info.csv로 저장되었습니다")
그게 다에요!
이렇게 하면 웹사이트의 테이블 안에서 데이터를 수집할 수 있어요.
또한, 이렇게 하면 Python을 사용하여 지루한 작업을 자동화할 수 있어요 😉
다음 글에서는 데이터 분석 프로젝트를 위해 슈퍼마켓에서 데이터를 수집하는 방법을 보여드릴게요.
도와드릴 수 있는 방법:
- 새로운 무료 뉴스레터 'The Super Learning Lab'를 구독하세요.
- 곧 무료 학습 이북과 이메일 코스가 출시될 예정입니다!

내 최고의 학습 기사들:
안녕하세요!
가져와주셔서 감사합니다! 아래는 이번 주 발간물 내용입니다:
- Ultralearning으로 무엇이든 배우기
- 초안 속 9가지 Ultra-learning 원칙
- Ultralearning을 활용하여 2개월 만에 무료로 독일어 배우기
- 학습을 슈퍼파워로 만들기
- 이것을 하지 않고 책을 읽는 것을 그만두세요
만날 날을 기대하며,
Axel
간단하고 쉬운 용어로 🚀
In Plain English 커뮤니티에 참여해 주셔서 감사합니다! 떠나시기 전에:
- 작가에게 박수를 보내고 팔로우해주세요 👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | Newsletter
- 다른 플랫폼 방문하기: CoFeed | Differ
- PlainEnglish.io에서 더 많은 콘텐츠 확인하기