
요즘 인공지능 커뮤니티에서 멋진 소식들이 있었어요. 모두가 작은 언어 모델과 낮은 계산 자원 가용성과 관련이 있어요.
예를 들면, 1.58비트(32비트 대신) 대규모 언어 모델을 실행하는 Transformer를 상상해봐요: 이를 위해 GPU가 필요하지 않아요.
지금으로선, 이것은 아직 가능한 미래에 해당해요. 현실은 새로운 작은 언어 모델이 챗봇 어시스턴트로 놀라운 성능을 발휘할 수 있다는 거죠.
집에서 손쉽게 직접 테스트해보고 싶지 않으세요?
컴퓨터에 전용 GPU가 없는 경우에 대한 완벽한 직접 테스트 가이드를 제공해 드릴게요.
전문적인 사전 설명
H2O.ai는 Apache-2 라이센스로 출시되었고 놀라운 SML을 제공합니다: h2oai/h2o-danube-1.8b-chat라고 불린답니다.
마찬가지로, MBZUAI(모하메드 빈 자이드 인공지능 대학교 - LaMini 모델의 창조자)의 사랑받는 친구들은 새로운 람가 무리를 발표했습니다. 최고 러너는 MobiLlama-1B-Chat입니다.
이제 다양한 Small AI가 제공되어 일상적인 작업에 파트너를 선택할 수 있습니다.
이 기사에서 제공하는 방법은 로컬 컴퓨터뿐만 아니라 동일한 네트워크에 연결된 친구나 동료와 공유할 수 있습니다.
이 방법을 사용하면 Python 코드에서 변경해야 하는 유일한 부분은 페이지 제목입니다!
Home Acceptance Test
이 용어는 계측 공학에서 상속 받은 것입니다. 공장 수락 테스트는 제조업체의 공장에서 수행하는 일련의 절차와 테스트로, 제조업체가 제공할 장비를 확인하는 것입니다. FAT(공장 수락 테스트) 중에 시스템이 요청한 요구사항을 준수하는지 확인해야 합니다.
우리의 Small Language Models에 대해 우리 중 누구도 기대를 갖고 있습니다. 이를 확인할 방법은 없는 것일까요?
저는 귀하의 GitHub Repo에 3가지 예제를 만들어서 귀하가 3분 안에 설정하고 수정하며 Hugging Face Hub의 거의 모든 모델과 페어링할 수 있도록 했습니다.
홈 랩 설정 방법
이 프로젝트를 가능한 한 호환성 있게 만들기 위해 최소한의:
- 파이썬 라이브러리 수
- 가장 쉬운 GGUF 추론 방법
- 그래픽 인터페이스의 쉬운 사용자 정의를 사용했습니다.
따라서 이 프로젝트를 위한 새 폴더를 만들고 가상 환경을 생성한 다음 활성화하세요 (여기서 제시된 지침은 Windows 사용자를 위한 것입니다).
저는 아직 Python 3.10을 사용 중이지만 3.11도 괜찮습니다. Sentencepiece를 사용하려면 3.12를 사용하지 마세요 (아직 지원되지 않음).
mkdir HAT
cd HAT
python -m venv venv
venv\Scripts\activate
가상 환경이 활성화된 상태이므로 필요한 3개의 라이브러리만 설치해야 합니다:
pip install llama-cpp-python[server]==0.2.53
pip install openai
pip install streamlit
라마-cpp-python 라이브러리는 CPU 만 사용하여 양자화된 모델을 실행할 수 있을뿐만 아니라 서버로서도 작동할 수 있습니다!
처음에는 놀랐어요. 한 줄의 명령어로 이게 다 가능하다니요!
로컬 모델을 호출하기 위해 openai Python 라이브러리가 필요합니다. 여기서의 차이점은 ChatGPT를 호출할 때와 동일한 방법으로 로컬 모델을 호출할 것이지만 인터넷 연결이 필요하지 않으며 API 키나 돈을 요청하지 않을 것입니다.
그리고 웹 그래픽 인터페이스로 Streamlit을 사용할 것입니다.
마지막으로, 모델 파일을 잊지 말아야 합니다. 우리는 오직 CPU 자원을 사용할 계획이므로 모델의 양자화된 GGUF 형식을 사용하려고 합니다.
모델을 다운로드하여 모델 하위 폴더에 저장해주세요.
- https://huggingface.co/brittlewis12/h2o-danube-1.8b-chat-GGUF
- https://huggingface.co/asedmammad/gemma-2b-it-GGUF/tree/main
- https://huggingface.co/tsunemoto/cosmo-1b-GGUF/tree/main
여기 3개의 모델 링크를 제공해드리겠습니다 (danube-1.8B-chat Q5_K_M, Gemma-2B-it Q4_K_M, 그리고 Cosmo-1b Q4_K_M): 하지만 이 외에도 그 이상의 모델들을 사용할 수 있다는 것을 기억해 주세요.
이제 모든 설정이 완료되었습니다.
cosmo-1b.Q4_K_M.gguf, gemma-2b-it.q4_K_M.gguf, 그리고 h2o-danube-1.8b-chat.Q5_K_M.gguf의 모델 파일들은 model이라는 하위 폴더에 있어야 합니다.

H2O Danube-1.8b-chat 테스트 벤치에서
파이썬 파일을 여기 리포지토리에서 다운로드할 수 있어요. 여기서 모델을 실행하고 사용자 정의하는 과정에 대해 설명할 거예요.
코드 워크스루를 원하신다면 아래 기사를 참고하세요:
모델을 API로 실행한 다음 streamlit을 실행하려면 두 개의 터미널 창이 필요해요: 하나는 FastAPI 서버를 시작하고, 또 다른 하나는 Streamlit GUI 서버 역할을 할 걘이에요. 두 터미널은 모두 venv를 활성화해야 해요.
왼쪽 터미널에서 다음 명령으로 llama-cpp-server를 실행하십시오:
python -m llama_cpp.server --host 0.0.0.0 --model model/h2o-danube-1.8b-chat.Q5_K_M.gguf --n_ctx 16384
오른쪽 터미널에서 다음 명령으로 Streamlit 서버를 시작하십시오:
streamlit run .\Danube1.8-stChat_API.py
기본 브라우저를 열어 기본 챗봇 그래픽 인터페이스를 확인하세요.
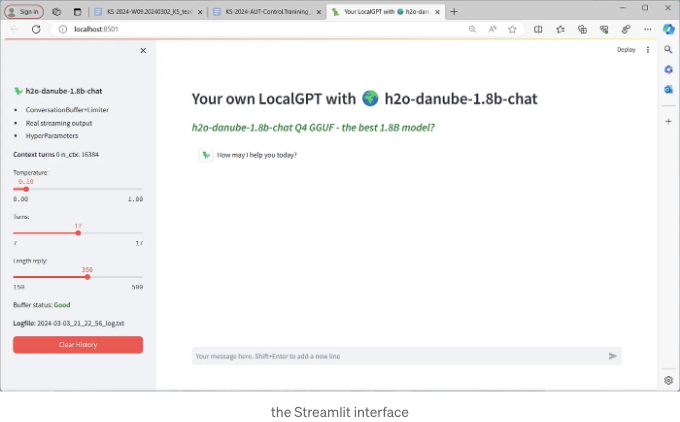
바로 채팅을 시작할 수 있어요. 몇 가지 매개변수를 변경할 수 있어요 (예를 들어
- 온도
- 출력의 최대 토큰 수
- 어시스턴트와 사용자의 턴 수와 관련된 다른 유용한 매개변수는 버퍼 메모리에 유지할 대화의 수입니 12개의 작은 모델인 Cosmo-1B이 좋은 숫자입니다.
- 대화 전체가 txt 로그 파일에 저장됩니다. (매우 유용함)
- '이전 대화 모두 삭제' 버튼을 클릭하면 이전 대화 내용이 모두 지워지고 처음부터 시작하게 됩니다.

모든 마법이 일어나는 곳은 어디인가요?
실제로 동일한 Streamlit 파일을 다른 챗봇 모델과 함께 사용할 수 있는 사실은 llama-cpp-python의 힘 덕분입니다.
호환되는 openai-webserver는 기본적으로 우리에게 모델과 상호작용하는 표준 방식을 제공해줍니다(API의 힘입니다...).
서버에서 사용 가능한 옵션 전체 목록을 보려면 명령줄에 다음과 같이 입력하면 됩니다.
python3 -m llama_cpp.server --help # 리눅스/맥 용
python -m llama_cpp.server --help # 윈도우 용
서버를 로드하는 명령줄에서 이전에 우리가 chat-format을 지정했다는 것을 알았을 것입니다. 편의를 위해, 명령줄에 전달되는 각 인수에 대해 새 줄을 추가할 것입니다.
python -m llama_cpp.server
--host 0.0.0.0
--model model/gemma-2b-it.q4_K_M.gguf
--chat_format gemma
--n_ctx 8192
-
--host 0.0.0.0: 이 argument는 서버의 노출된 IP 주소를 지정하는 데 사용됩니다. 0.0.0.0으로 설정하면 컴퓨터가 네트워크에 할당한 IP를 사용하도록 지정하는 것입니다.
-
--model model/gemma-2b-it.q4_K_M.gguf: 이는 GGUF 파일의 위치를 제공하는 데 사용됩니다.
-
--chat-format gemma: 이 argument는 채팅 템플릿에 책임이 있습니다. 각 LLM이 특정 형식의 스타일로 프롬프트를 받는 것을 기억해야 합니다. 여기서 llama-cpp가 이미 구축한 기존 채팅 템플릿을 지정합니다.
-
--n_ctx 8192: 이는 모델이 계산할 수 있는 컨텍스트 창입니다. Gemma-2b는 8,192토큰, Danube-1.8b는 16,384토큰의 창을 가지고 있습니다.
놀라운 엔지니어링 작업이 여기 정확히 있습니다. Andrei aka abetlen은 채팅을 처리하는 매우 똑똑한 방법을 만들었습니다 (소스는 여기에 있습니다):
모델은 다음 우선 순위 순서로 메시지를 단일 프롬프트로 포맷팅합니다:
- 제공된 경우 chat_handler 사용
- 제공된 경우 chat_format 사용
- gguf 모델의 메타데이터에서 tokenizer.chat_template 사용 (대부분의 새로운 모델에 작동해야 함, 오래된 모델에는 없을 수 있음)
- 그렇지 않으면, llama-2 채팅 형식으로 대체
의미를 보여드리기 위해 다누브-1.8b-채팅 모델의 llama-cpp-server의 로딩 시퀀스를 살펴보겠습니다:
GGUF 파일에는 모델 토크나이저가 포함되어 있습니다. 모델을 로드하는 동안 llama-cpp-python은 토크나이저.template을 구문 분석하여 우리가 사용할 수 있는 chat.template으로 변환합니다!
이는 터미널 창에서 추출한 내용입니다.
이제 다른 Streamlit 앱을 실행하지 않아도 채팅을 할 수 있습니다. Danube를 읽고 Gemma와 대화하는 것은 상당히 이상할 수 있지만 중요한 것은 챗봇이 임무를 제대로 수행하고 있다는 것입니다.
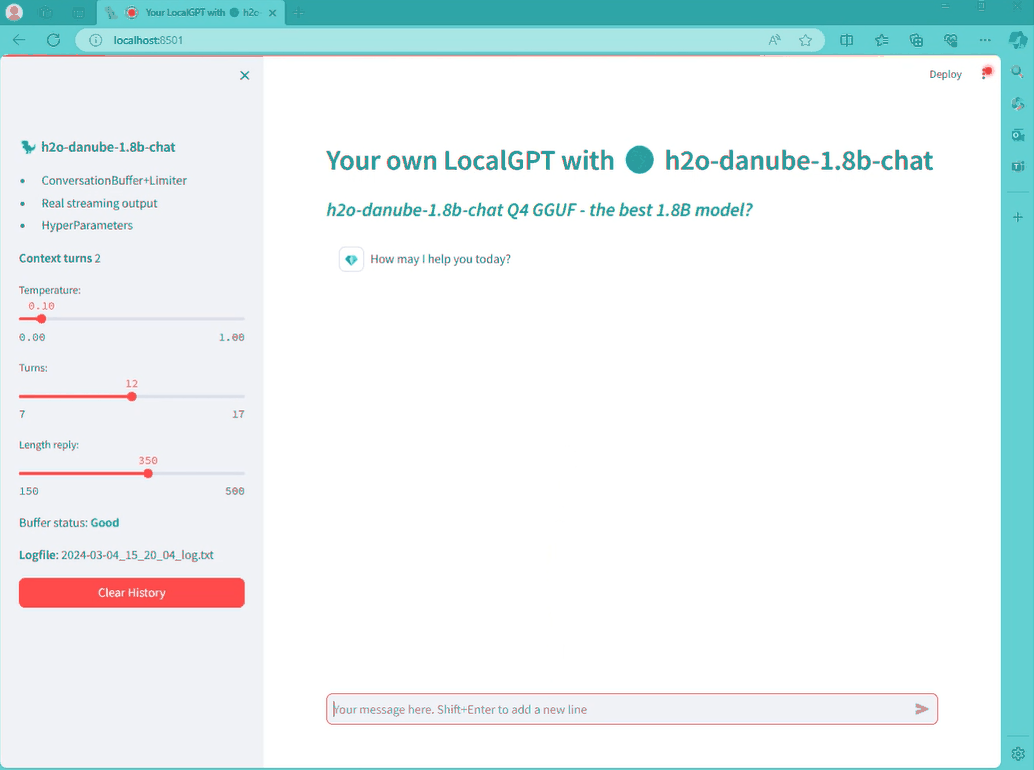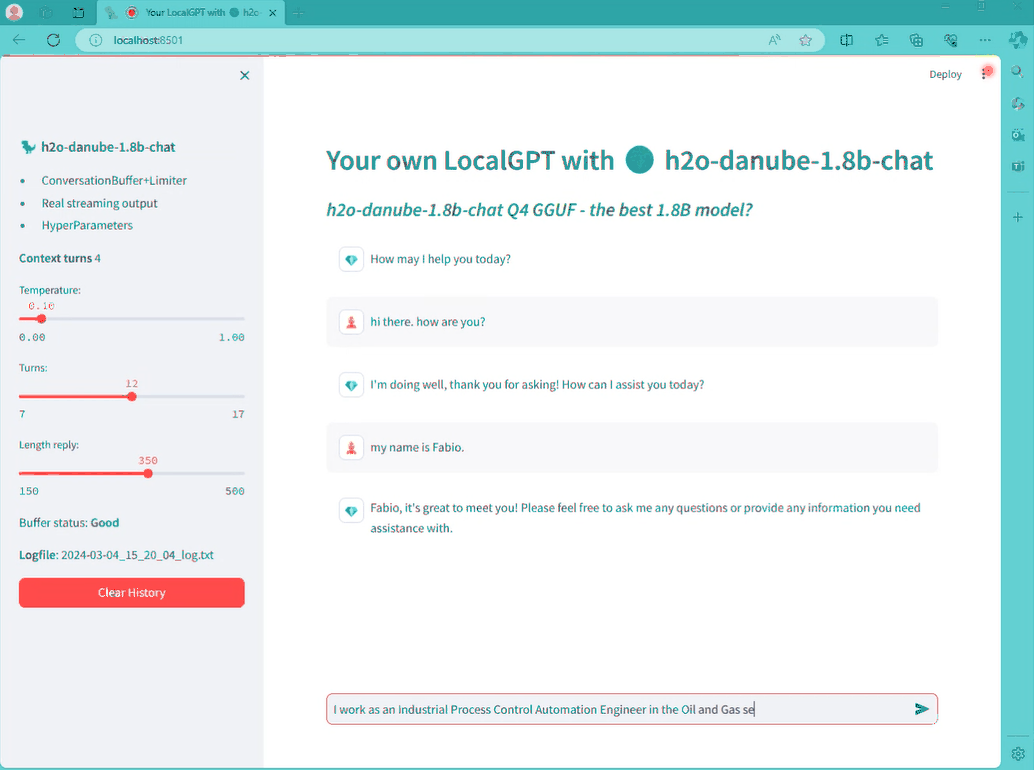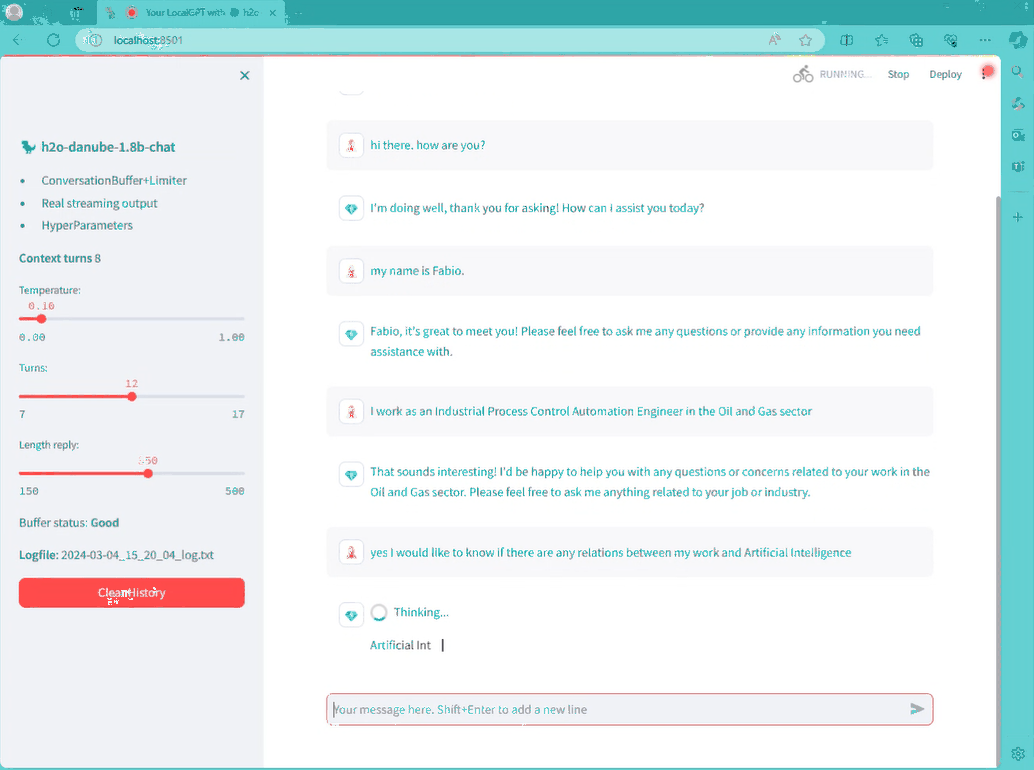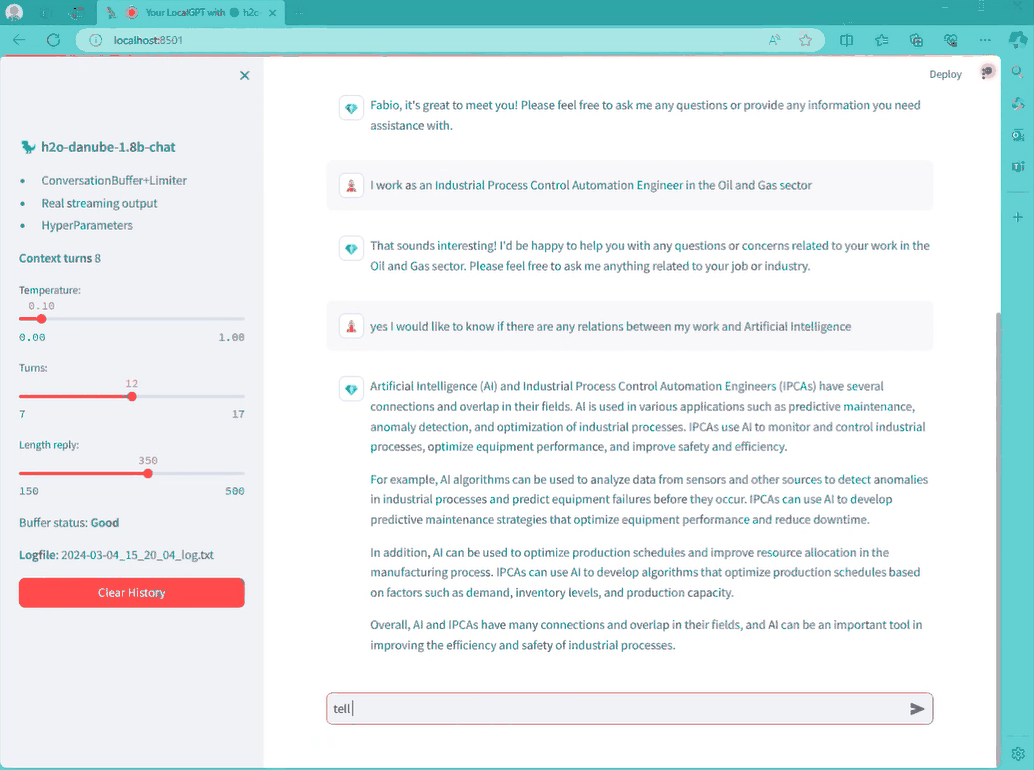
그래서, Chat-formats이 뭔가요?
만약 명령줄에서 챗형식을 지정하려면, llama-cpp-python이 내장된 해결책으로 제공하는 옵션들은 다음과 같습니다:
llama_cpp.llama_chat_format(valid formats: [
'llama-2', 'alpaca', 'qwen', 'vicuna', 'oasst_llama',
'baichuan-2', 'baichuan', 'openbuddy', 'redpajama-incite',
'snoozy', 'phind', 'intel', 'open-orca', 'mistrallite',
'zephyr', 'pygmalion', 'chatml', 'mistral-instruct',
'chatglm3', 'openchat', 'saiga', 'gemma', 'functionary',
'functionary-v2', 'functionary-v1', 'chatml-function-calling'])
결론
이미 언급했듯이, 그리고 멈추지 않고 계속 말할 테니 매주 새로운 모델이 나오고 있습니다. 많은 사람들이 그 중 하나를 쫓아가느라 시간을 낭비하지 말라고 말할지도 모릅니다.
하지만 저는 그것에 반대합니다! 다른 사람들의 판단에 항상 의지해서는 안 됩니다. 게다가, 작은 언어 모델(30억 파라미터 미만)은 매우 유망하며 매우 적은 추론 시간으로 CPU에서 실행할 수 있습니다.
이러한 작은 모델들의 파라미터 조정은 결과를 극적으로 바꿀 수 있으며, 모든 주요 지표에서 높은 벤치마크 점수를 가질 수는 없지만 이는 전혀 좋지 않거나 특정 목적에 완벽하지 않다는 것을 의미하지 않습니다.
자신을 판단하는 최선의 방법은 당신 자신입니다. 홈 수용 테스트는 정말 좋은 해결책이죠!
만약 놓치셨다면, 다시 한번 GitHub Repo를 확인해보세요:
이 기사를 즐기셨기를 바랍니다. 이 이야기가 가치를 제공했고 조금이라도 지원을 표현하고 싶다면:
- 이 이야기에 대해 많이 박수를 보내세요.
- 기억해야 할 중요한 부분을 강조하세요(나중에 찾을 때 더 쉽고 더 나은 기사를 작성하는 데 도움이 됩니다).
- 자신만의 AI를 만드는 방법을 배우려면 이 무료 eBook을 다운로드하세요.
- 제 링크를 사용하여 Medium 멤버십 가입하기 ($5/월로 무제한 Medium 기사 읽기).
- Medium에서 제 팔로우하기.
- 제 최신 기사는 https://medium.com/@fabio.matricardi에서 읽을 수 있습니다.
다음은 몇 가지 더 자료입니다:
챗봇 구축을 위한 자원 및 참고 자료:
출력을 스트리밍하는 방법을 배우려면:
채팅 템플릿 유도
Stackademic 🎓
내용을 끝까지 읽어주셔서 감사합니다. 떠나기 전에:
- 작가를 클립하고 팔로우해주시면 감사하겠습니다! 👏
- 저희를 팔로우해 주세요: X | LinkedIn | YouTube | Discord
- 다른 플랫폼에서도 저희를 만나보세요: In Plain English | CoFeed | Venture | Cubed
- 더 많은 콘텐츠는 Stackademic.com에서 확인하세요.