
이 글에서는 제너레이티브 인공지능(GenAI) 최첨단 기술인 에이전트를 로컬에서 구축하는 방법을 소개하겠습니다. 일반 LLM과의 차이를 설명하면서요.

일반적으로, 지능형 에이전트는 환경을 인식할 수 있는 충분한 이해력으로 행동하는 존재로, 특정 목표를 달성하기 위해 자율적으로 행동하고 지식을 습득하며(사람과 같이) 개선합니다.
기술 분야에서 AI 에이전트는 작업을 수행하고 결정을 내리며 다른 개체와 통신하는 자율 프로그램입니다. 보통, 에이전트에게는 작업을 완료하는 동안 사용할 수 있는 도구 세트가 제공됩니다. 이 개념은 보상을 극대화하기 위해 정의된 일련의 작업 중에서 선택하는 강화 학습을 확장한 것입니다.
대형 언어 모델(LLM)은 에이전트가 아닙니다. LLM은 단어 임베딩과 트랜스포머 아키텍처를 활용하여 고급 자연어 처리를 수행하는 신경망입니다. 인간 언어에 대한 막대한 이해력을 갖고 있지만, 지식 범위를 넘어서는 행동은 수행하지 않습니다.
GenAI에서 에이전트는 순차적 추론을 처리하기 위해 설계된 AI 시스템으로, LLM의 일반 지식이 충분하지 않은 경우 외부 도구(예: 데이터베이스 쿼리, 웹 검색)를 실행할 수 있습니다. 간단히 말해, 일반적인 AI 챗봇은 답변할 수 없는 경우 무작위 텍스트를 생성하지만, 에이전트는 공백을 채우고 구체적인 응답을 제공하기 위해 도구를 활성화합니다.
에이전트가 수행할 수 있는 가장 일반적인 작업은:
- 대화 - 일반적인 지식 베이스와 대화하는 것을 의미합니다
- RAG - 문서와 대화하는 것을 의미합니다
- 쿼리(즉, SQL 생성) - 데이터베이스와 대화하는 것을 의미합니다
- 웹 검색 - 인터넷 전체와 대화하는 것을 의미합니다
그러나 가장 매혹적인 측면은 코딩이 가능하다면 어떤 것이든 도구가 될 수 있다는 것입니다. 따라서 에이전트의 기능과 응용 프로그램은 무한합니다.
이 튜토리얼에서는 여러 개의 에이전트를 만들 것입니다. 다른 유사한 경우에 쉽게 적용할 수 있는 유용한 Python 코드를 제시하고 각 코드 라인에 대해 설명이 담긴 주석을 달아 이 예시를 복제할 수 있도록 안내하겠습니다(아래의 전체 코드 링크 참조).
특히 다음을 다룰 것입니다:
- 설정: LangChain + CrewAI + DuckDuckGo.
- LLM: LLM을 사용하여 데이터를 읽고 시각 작업을 수행합니다.
- Agent: 단일 Agent으로 동일한 작업 수행.
- 여러 에이전트: 여럿이 팀을 이루어 동일한 작업 수행.
설정
현재, 가장 똑똑한 클로즈드 소스 인공지능(AI) Agents로는 OpenAI의 ChatGPT, Anthropic의 Claude, 그리고 Google의 Gemini가 있습니다. 오픈 소스 쪽에는 많은 초기 단계 라이브러리가 있지만, 시장 리더는 아직 없는 것으로 보입니다(이 주제는 정말 정선 기술이기 때문입니다). 주요 라이브러리는 다음과 같습니다:
- LangChain — 거의 모든 LLM 기능을 포함하는 매쉬업 프레임워크입니다. Agent가 낮은 수준에서 코딩되어야 하는 경우(즉, 어떻게 메모리를 사용할지 결정해야 하는 경우), LangGraph 모듈을 추천드립니다.
- CrewAI — "크루"로 함께 작업할 수 있는 여러 에이전트를 만들기 위해 특별히 설계된 라이브러리입니다.
- AutoGen — Microsoft에서 개발한 로우코드(거의 노코드) 인터페이스 AutoGen Studio가 함께 제공되는 라이브러리입니다.
- AnythingLLM — 가장 일반적인 작업을 수행할 수 있는 전혀 노코드 플랫폼입니다.
- HuggingFace — 첫 번째 LLM 라이브러리이자 모델 저장소입니다.
- LlamaIndex — Meta의 LLM 라이브러리와 새로운 에이전트 모듈 LLamaAgents가 포함되어 있습니다.
LangChain (LLM을 위한)과 CrewAI (에이전트를 위한)의 조합이 매우 사용자 친화적이고 효과적이라고 생각해요.
우선, LLM과 에이전트 사이의 차이를 이해해야 해요. 좋은 예를 보여드릴게요. LLM이 "간단"하지만 구체적인 질문에 어떻게 답변하는지 보여줄게요. 언어 모델 실행에 대해선 Ollama 모듈과 Phi3 모델을 사용하는 것을 선호해요. 설정 방법은 이 글을 참고할 수 있어요.
!pip install langchain #0.1.20
!pip install langchain-community #0.0.38
from langchain_community.llms import Ollama
llm = Ollama(model="phi3")
res = llm.invoke(input=["What day is today?"]).split("\n")[0]
print(res)

당연히 언어 모델은 오늘의 날짜를 알 수 없습니다. 답을 얻는 한 가지 방법은 인터넷에서 검색하는 것입니다. Python에서는 유명한 비공개 브라우저 DuckDuckGo를 사용하여 쉽게 할 수 있습니다.
!pip install duckduckgo-search #6.1.7
from langchain.tools import DuckDuckGoSearchResults
DuckDuckGoSearchResults().run("오늘은 무슨 요일인가요?")

... 또는 메타데이터 없이 텍스트만 원하면요.
from langchain_community.tools import DuckDuckGoSearchRun
DuckDuckGoSearchRun().run("What day is today?")

이제 첫 번째 에이전트를 만들어봅시다. LLM에게 우리가 방금 한 것처럼 웹을 탐색할 수 있는 기능을 제공하여. 그러면 인공지능은:
- LLM 지식으로는 해당 질문에 대답할 수 없다는 것을 이해해야 합니다.
- 추가 정보를 얻기 위해 도구를 사용해야 합니다.
- 결과를 LLM을 통해 처리하고 답변을 생성해야 합니다.
말씀드렸듯이, 어떤 것이든 Tool 객체가 될 수 있으며 CrewAI 라이브러리를 사용하여 함수에 데코레이터를 간단히 추가할 수 있습니다.
!pip install "crewai[tools]" #0.4.0
from crewai_tools import tool
@tool
def tool_browser(q: str) -> str:
"""DuckDuckGo 브라우저"""
return DuckDuckGoSearchRun().run(q)
에이전트 객체를 만들기 위해서는 목표(작업의 간단한 설명)와 배경 이야기(작업에 대한 자세한 설명)를 정의하여 일부 프롬프트 엔지니어링을 해야 합니다. 도구 및 LLM도 지정해야 합니다.
!pip install crewai #0.35.0
import crewai
agent = crewai.Agent(
role="Calendar",
goal="오늘의 요일을 확인하세요",
backstory="당신은 달력 도우미입니다. 날짜에 관한 정보를 알려줍니다.",
tools=[tool_browser],
llm=llm,
allow_delegation=False, verbose=False)
그럼, 다시 한 번 목표를 지정하여 Task 객체를 생성해야 합니다.
task = crewai.Task(description="오늘은 무슨 요일인지 알아내기",
agent=agent,
expected_output="오늘 날짜")
마지막으로, 이 경우에는 Agent가 한 명뿐인 Crew를 실행해야 합니다.
crew = crewai.Crew(agents=[agent], tasks=[task], verbose=False)
res = crew.kickoff()
print(res)

보시다시피, 에이전트는 LLM이 대답하지 못한 질문에 대답할 수 있어요. 개요를 파악하셨으니, 다음 단계로 넘어가볼까요?
LLM
이 수영복 브랜드(White Water Atelier)에서는 AI를 활용한 소셜 미디어 전략을 만들어 달라고 했어요... 에이전트에게 딱 맞는 사례죠. 특히, 인스타그램 포스트 작성 프로세스를 자동화할 거에요.
먼저, 데이터(이미지)를 읽어봅시다:
from matplotlib import image, pyplot
import os
path = 'data/'
folder = [x for x in os.listdir(path) if x.endswith(('.png','.jpg','.jpeg'))]
fig, ax = pyplot.subplots(nrows=1, ncols=len(folder), sharex=False, sharey=False, figsize=(4*len(folder),10))
for n,file in enumerate(folder):
ax[n].imshow(image.imread(path+file))
ax[n].set(title=file)
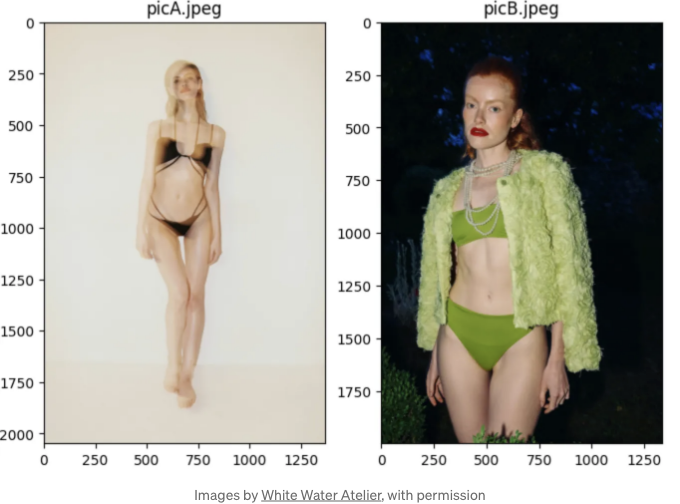
LLM에게 게시물을 생성하도록 요청하려면(사진 하나를 선택하고 캡션을 작성하도록 하기 위해서), 이미지는 모델이 처리할 수 있도록 문자열로 인코딩되어야 합니다.
import base64
def encode_image(path):
with open(path, "rb") as file:
return base64.b64encode(file.read()).decode('utf-8')
lst_imgs = [encode_image(path+i) for i in folder]
적절한 비전 LLM을 사용할 것입니다. Microsoft의 LLaVa는 GPU 없이도 작동할 수 있는 효율적인 선택입니다 (여기에서 시도해보세요).
prompt = '''먼저 인스타그램에서 어떤 사진이 좋아요를 더 많이 받을지 결정해야 합니다. 그리고 선택한 이미지에 기반하여 변환율을 극대화할 캡션을 작성해야 합니다.'''
vision_llm = Ollama(model="llava")
res = vision_llm.invoke(input=[prompt], images=lst_imgs)
print(res)

꽤 잘했어요. LLM이 두 가지 작업을 완료했고 좋은 설명도 추가했어요. 하지만 캡션이 해시태그가 빠져있어 조금 오래된 것 같아요.
에이전트
이전 예제와 마찬가지로, 특정 검색 도구가 제공된 에이전트에게 동일한 작업을 넘길 거에요.
@tool("instagram")
def tool_instagram(q: str) -> str:
'''Instagram 검색'''
return DuckDuckGoSearchRun().run(f"site:instagram.com {q}")
과거 에이전트와의 윯 한 가붕, 이번에는 입력 데아터를 전달할 때입니다. 특히, 이미지를 설명하기 위해 비전 LLM을 활용하고 텍스트를 입력으로 사용할 것입네다.
vision_llm = Ollama(model="llava")
des = ""
for n,img in enumerate(lst_imgs):
res = vision_llm.invoke(input=["이미지를 정확하게 설명하세요"], images=[img])
des = des.strip() + "\n\n" + f"이미지{n+1}: "+res.replace('\n',' ')
print(des)

CrewAI에서는 에이전트 실행 시 입력을 제공해야 하며, 'inputs'를 이용하여 프롬프트에서 참조할 수 있습니다.
prompt = '''먼저 {images}에서 어떤 이미지가 인스타그램에서 좋아요를 더 많이 받을지 결정해야 합니다. 해당 이미지를 선택한 이유를 설명한 후, 해당 이미지를 기반으로 전환율을 극대화할 캡션을 작성해야 합니다. 현재 계절, 오늘의 날짜, 이번 달의 특별한 이벤트, 트렌드 있는 해시태그 및 이모티콘을 고려하여 완벽한 캡션을 만들어보세요.'''
## Agent
agent = crewai.Agent(
role="인플루언서",
goal=prompt,
backstory="모든 게시물의 전환율을 극대화하는 인플루언서입니다.",
tools=[tool_instagram],
llm=llm,
allow_delegation=False, verbose=True)
## Task
task = crewai.Task(description=prompt, agent=agent,
expected_output='''인스타그램 게시물을 위한 최고의 사진과 캡션''')
## Crew
crew = crewai.Crew(agents=[agent], tasks=[task], verbose=True)
res = crew.kickoff(inputs={"images":des})
print("Res:", res)
로그를 분석하기 위해 verbose=True로 설정했습니다. 에이전트는 요청을 처리하면서 필요한 도구인…

…을 사용해 작업을 시작합니다. 요청 결과를 검토하는 것으로 계속됩니다.

... 그러고 나면 최종 답변이 나옵니다.

그래서 Agents는 LLM과 같은 이미지를 선택하고 더 나은 캡션을 생성했습니다.
다중 에이전트
성능을 극대화하기 위해 각 에이전트에게 단일 작업을 할당하는 것이 일반적입니다. 따라서 작업을 두 부분(이미지 선택 및 캡션 생성)으로 분할하고 전체 프로세스를 자동화하기 위해 여러 에이전트로 구성된 팀을 만들겠습니다:
- 사진작가 — 입력 설명을 기반으로 최적의 이미지를 선택하는 작업을 맡습니다 (웹에서 검색 가능)
- 소셜 미디어 매니저 — 사진작가의 결과를 기반으로 최적의 캡션을 작성하는 작업을 맡습니다 (웹에서 검색 가능)
- 매니저 — 전체 프로세스를 담당하는 작업을 맡습니다. 요청을 이해하고 다른 에이전트에 일을 할당하며 최종 결과가 올바른지 확인해야 합니다 (최종 검증을 위해 사람에게 요청 가능).
각 작업이 실행되는 동안 출력을 확인하기 위해 콜백 함수를 추가하는 것이 유용할 수 있습니다 (이를 Task 객체에 추가해야 함).
def callback_function(output):
print(f"작업 완료: {output.raw_output}")
처음 두 명의 에이전트는 이전에 코딩한 것과 유사합니다. 그러나 이번에는 각 에이전트가 특정한 하나의 작업만 수행하므로 프롬프트 지침에 더 자세히 설명하겠습니다.
######################## 1-사진작가 #########################
prompt = '''{images} 중에서 인스타그램에서 더 많은 좋아요를 받을 사진을 선택하세요.'''
## 에이전트
에이전트_사진작가 = crewai.Agent(
role="사진작가",
goal=prompt,
backstory='''사진작가로써, 인스타그램에서 더 많은 좋아요를 받을 사진을 이해해야 합니다.
게시물로 더 많은 사람들이 상호작용하도록 하고, 전환율을 극대화해야 합니다.
현재 계절, 오늘 날짜, 이번 달의 특별한 이벤트에 대해 조사해보세요.
''',
tools=[tool_browser, tool_instagram],
llm=llm,
allow_delegation=False, verbose=False)
## 작업
작업_사진작가 = crewai.Task(
description=prompt,
agent=에이전트_사진작가,
callback=callback_function,
expected_output='''선택한 이미지 및 왜 그것이 가장 좋다고 생각하는지 설명''')
######################## 2-소셜 미디어 매니저 ##################
prompt = '''이미지를 기반으로 인스타그램 게시물의 전환율을 극대화할 캡션을 작성하세요.'''
## 에이전트
에이전트_소셜 = crewai.Agent(
role="소셜 미디어 매니저",
goal=prompt,
backstory='''소셜 미디어 매니저로서, 사진작가의 결과물을 기반으로 짧은 캡션을 생성해야 합니다.
인스타그램에서 더 많은 좋아요를 받고, 게시물로 더 많은 사람들이 상호작용하며 전환율을 극대화해야 합니다.
트렌디한 주제, 해시태그 및 이모지 등에 대해 조사해보세요.
''',
tools=[tool_browser, tool_instagram],
llm=llm,
allow_delegation=False,
verbose=False)
## 작업
작업_소셜 = crewai.Task(
description=prompt,
agent=에이전트_소셜,
expected_output='''인스타그램 게시물을 위한 짧은 캡션''')
다음 에이전트는 최종 출력물을 감시하고 인간의 검증을 요청해야 합니다. 따라서 프롬프트 설명에서 매우 정확해야 하며 에이전트 객체에서 allow_delegation=True 및 작업 객체에서 human_input=True 매개변수를 사용해야 합니다.
######################## 3-다른 에이전트들의 매니저 #############
prompt = '''게시물 생성 프로세스를 감독하고, 게시물 좋아요를 극대화하는 최고의 사진을 선택하고, 게시물의 전환율을 극대화하는 최고의 캡션을 작성합니다.'''
## Agent
agent_manager = crewai.Agent(
role="다른 에이전트들의 매니저",
goal=prompt,
backstory='''프로세스의 매니저로서, 완벽한 인스타그램 게시물을 만들기 위해 모든 단계를 따릅니다:
1- 사진작가와 함께 더 많은 인스타그램 좋아요를 받을 사진을 선택합니다.
2- 이미지를 기반으로 인스타그램에서 전환율을 극대화할 게시물 캡션을 작성합니다.
프로세스의 끝에는 반드시 인간의 최종 승인을 요청해야 합니다. 인간 입력 도구를 사용하세요.
''',
llm=llm,
allow_delegation=True, verbose=True)
## Task
task_manager = crewai.Task(
description=prompt, agent=agent_manager,
human_input=True,
expected_output='''최상의 이미지와 짧은 캡션, 기본적으로 전체 인스타그램 게시물''')
마지막으로, 모든 것을 Crew 객체에 넣을 수 있습니다. 이번에는 하나의 에이전트만 프로젝트 전체를 담당해야 한다는 것을 지정할 수 있습니다. 순차 프로세스는 작업이 선형적으로 진행되어 한 작업이 다음 작업을 따르는 것을 보장하며, 계층적 프로세스는 효율적인 작업 위임 및 실행을 위해 전통적인 조직적 계층 구조를 모방합니다.
crew = crewai.Crew(agents=[agent_photograper, agent_social],
tasks=[task_photograper, task_social, task_manager],
process=crewai.Process.hierarchical,
manager_agent=agent_manager,
verbose=True)
res = crew.kickoff(inputs={"images":des})
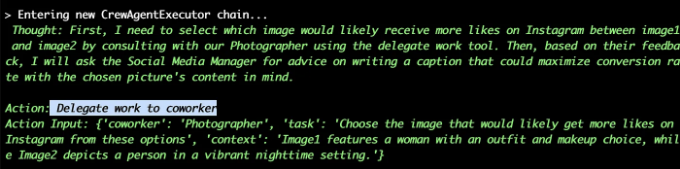
로그에서 확인할 수 있듯이, 매니저가 요청을 처리하고 첫 번째 작업을 첫 번째 에이전트에게 위임했습니다. 첫 번째 결과는 완벽합니다. AI가 최근 소셜 미디어 트렌드와 인스타그램 알고리즘 논리를 분석했습니다.

그러나 두 번째 결과는 약간 납득하기 어렵습니다. 에이전트가 제품에 대한 "할인"을 언급했습니다. 요금 및 판매와 같은 주제는 지시에 포함되어 있지 않으며 인간 감독자가 승인해야 합니다 (human_input 매개변수 덕분에).

GitHub에서 전체 코드를 확인할 수 있어요.
결론
본 글은 다양한 작업을 수행할 수 있는 에이전트를 구축하는 방법을 보여주는 튜토리얼이었습니다. LLM, LangChain 및 CrewAI를 사용하여 다양한 유형의 데이터를 처리할 수 있는 AI 팀을 만들었습니다. 에이전트는 매우 유연하므로 어떤 용도에도 사용자 정의할 수 있도록 프로세스를 가능한 일반적으로 설명했어요.
즐겁게 읽으셨기를 바랍니다! 궁금한 점이나 피드백이 있으시다면 언제든지 연락해 주시거나 흥미로운 프로젝트를 공유해 주세요.