이 게시물은 Rafael Guedes와 공동 저자로 작성되었습니다.
소개
세계는 모두가 원하는 것을 거의 한 번 클릭으로 모두 얻을 수 있는 디지턈 시대로 발전해 왔습니다. 접근성, 편의성 및 다양한 제공 효과는 소비자에게 새로운 도전과 함께 제공됩니다. 소비자가 옵션의 바다 속에서 검색하는 대신 맞춤 선택을 받을 수 있는 방법은 무엇일까요? 바로 추천 시스템이 여기에서 나타납니다.
추천 시스템은 조직이 교차 판매와 장꼬 아이템의 판매를 증가시키고, 고객들이 가장 좋아하는 것을 분석하여 의사 결정을 개선하는 데 유용합니다. 뿐만 아니라, 고객의 과거 행동을 학습하여 특정한 고객 선호도에 따라 제품 집합을 순위 매길 수 있습니다. 추천 시스템을 사용하는 조직은 향상된 고객 경험을 제공함으로써 경쟁사보다 한 발 앞서 있습니다.
이 기사에서는 온라인 광고 및 추천 시스템에서의 클릭 수 예측을 향상시키기 위해 설계된 새로운 모델인 FinalMLP에 초점을 맞춥니다. Advanced features like gating and interaction aggregation layers를 갖춘 두 개의 다층 퍼셉트론(MLP) 네트워크를 통합하여, FinalMLP은 기존의 단일 스트림 MLP 모델과 고급 두 개의 스트림 CTR 모델보다 우수한 성능을 보입니다. 저자들은 FinalMLP의 효과를 벤치마크 데이터셋 및 실제 온라인 A/B 테스트를 통해 확인했습니다.
FinalMLP의 상세한 내용과 작동 방식에 초점을 맞추면서, 공개 데이터셋에 적용하고 구현하는 방법에 대한 안내도 제공합니다. 우리는 책 추천 설정에서 FinalMLP의 정확도를 테스트하고, 저자들이 제안한 두 개의 스트림 아키텍처를 활용하여 예측을 설명하는 능력을 평가합니다.
항상 그렇듯이, 코드는 저희의 GitHub에서 이용 가능합니다.
FinalMLP: 두 개의 MLP 위에 (F)eature gating 및 (IN)teraction (A)ggregation (L)ayers가 추가된 모델
FinalMLP [1]은 DualMLP [2] 위에 구축된 두 개의 스트림 Multi-Layer Perceptron (MLP) 모델로, 다음과 같은 2가지 새로운 개념을 도입하여 향상시킵니다:
- Gating 기반의 특징 선택은 두 스트림 간의 차이를 증가시켜, 각 스트림이 서로 다른 특징 세트로부터 서로 다른 패턴을 학습하도록 만듭니다. 예를 들어, 하나의 스트림은 사용자 특징을 처리하고, 다른 하나는 항목 특징에 중점을 둡니다.
- Multi-Head Bilinear Fusion은 두 스트림에서 나온 출력을 결합하는 방법을 개선하여 특징 상호작용을 모델링합니다. 이는 덧셈 또는 연결과 같은 선형 연산에 의존하는 전통적인 방식을 사용할 때 발생하지 않을 수 있습니다.
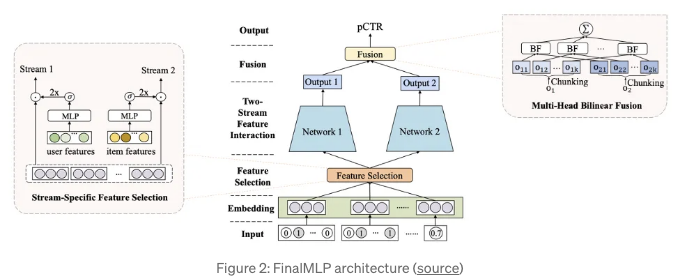
작동 방법은 무엇인가요?
이전에 언급한 대로, FinalMLP는 서로 다른 관점에서 특징 상호 작용을 학습하는 두 개의 간단하고 병렬 MLP 네트워크로 구성된 Two-Stream CTR 모델입니다. 다음과 같은 주요 구성 요소로 구성되어 있습니다:
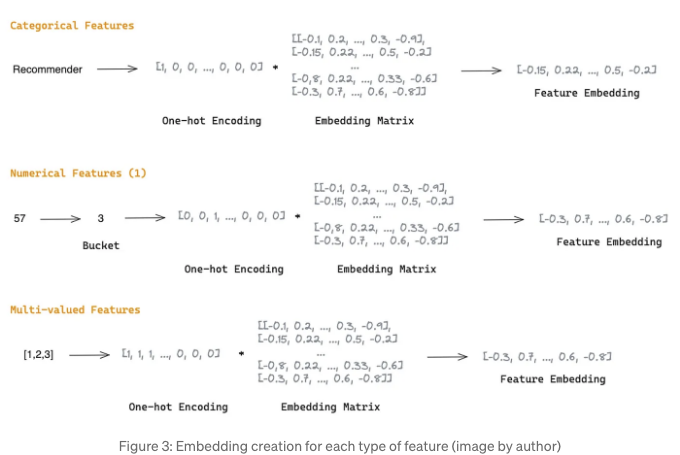
특징 임베딩 레이어는 고차원 및 희소한 원시 특징을 밀집 숫자 표현으로 매핑하는 일반적인 방법입니다. 범주형, 숫자, 또는 다중 값이어도 각 특징은 임베딩 벡터로 변환되고 Feature Selection 모듈에 입력하기 전에 연결됩니다.
범주형 특징은 원-핫 특징 벡터로 변환되며, 학습 가능한 임베딩 행렬에 의해 곱해져 어휘 크기 n과 임베딩 차원 d를 가진 임베딩을 생성합니다[3].
숫자형 특성은 1) 숫자 값을 이산형 특성으로 버킷팅하고 이를 범주형 특성으로 다루거나 2) 정규화된 스칼라 값 xj가 주어지면, 임베딩은 xj를 field j의 모든 특성에 대한 공유 임베딩 벡터 vj와 곱한 것으로 주어질 수 있습니다 [3].
다중값 특성은 값 시퀀스를 하나의 길이가 k인 원-핫 인코딩 벡터로 변환한 다음 학습 가능한 임베딩 행렬과 곱하여 임베딩을 생성할 수 있습니다 [3].
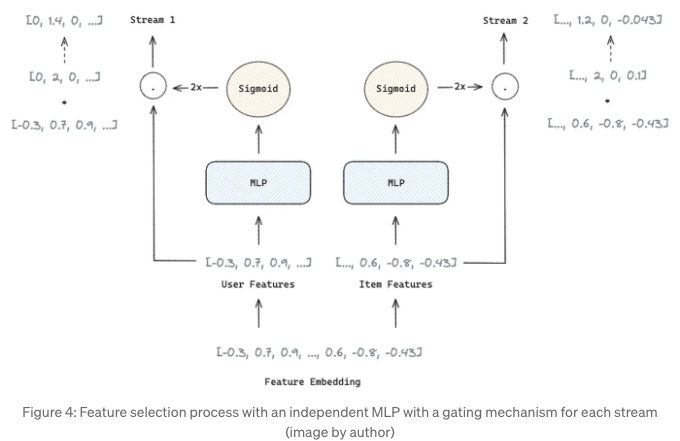
특성 선택 레이어는 모델 예측에 중요한 영향을 미치도록 중요한 특성에 더 높은 영향을 미치도록 잡음이 많은 특성을 억제하기 위한 특성 중요도 가중치를 얻기 위해 사용됩니다.
언급한 대로, FinalMLP는 게이팅 기반 특성 선택, 그리고 게이트 메커니즘을 갖춘 MLP를 사용합니다. 이 MLP는 임베딩을 입력으로 받아들이고, 입력과 동일한 차원의 가중치 벡터를 생성합니다. 특성 중요도 가중치는 시그모이드 함수를 가중치 벡터에 적용하여 [0, 2] 범위의 벡터를 생성하는 방식으로 얻어집니다. 가중된 특성은 특성 임베딩과 특성 중요도 가중치 사이의 요소별 곱셈을 통해 얻어집니다.
이 과정을 통해 두 스트림 간 균질한 학습이 감소되어 특성 상호작용의 보다 보완적인 학습이 가능해집니다. 유저나 아이템 차원에 집중하도록 각 스트림에 독립적으로 적용되어 특성 입력을 구분합니다.
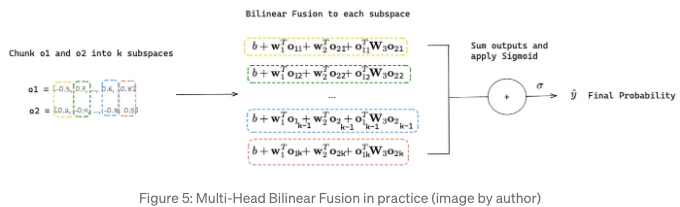
양 스트림의 출력을 결합하여 최종 예측 확률을 얻기 위해 스트림 수준 융합 계층이 필요합니다. 일반적으로 두 출력을 결합하는 것은 합산 또는 연결 작업을 기반으로 합니다. 그러나 FinalMLP의 저자들은 선형 조합이 실패할 수 있는 특성 상호작용 정보를 얻기 위해 두 출력을 결합하는 데에 양선형 상호작용 집계 계층을 제안합니다.
저자들은 어텐션 레이어에서 영감을 받아 멀티 헤드 바이리니어 퓨전 레이어로 발전시킨 바이리니어 퓨전을 소개했습니다. 이는 계산 복잡성을 줄이고 모델의 확장성을 향상시키는 데 사용됩니다.
바이리니어 퓨전 방정식은 다음과 같이 구성됩니다:

여기서 σ는 시그모이드 함수, b는 편향 항목이며, o1은 한 스트림의 출력입니다. w1은 o1에 적용되는 학습 가능한 가중치이고, o2는 다른 스트림의 출력이며, w2는 o2에 적용되는 학습 가능한 가중치입니다. 마지막으로, w3는 특성 상호작용 정보를 추출하는 바이리니어 항목의 학습 가능한 매트릭스입니다. w3가 제로 매트릭스로 설정되면 전통적인 연결 퓨전으로 약화됩니다.
Bilinear Fusion과 Multi-Head Bilinear Fusion의 차이점은, 두 스트림에서 전체 벡터를 사용하는 대신 출력 o1과 o2를 k 개의 하위 공간으로 나눈다는 것입니다. 각 하위 공간에서 이루어진 bilinear 퓨전은 sigmoid 함수에 공급하여 최종 확률을 생성합니다.
FinalMLP로 도서 추천 모델 만들기
이 섹션에서는 FinalMLP를 Kaggle의 Public Domain 라이선스(CC0)로 공개된 데이터셋에 구현할 것입니다. 이 데이터셋에는 사용자, 책, 그리고 사용자가 책에 부여한 등급에 관한 정보가 포함되어 있습니다.
데이터셋은 다음과 같이 구성되어 있습니다:
- 사용자 ID — 사용자를 식별하는 ID
- 위치 — 사용자의 도시, 주, 국가가 콤마로 구분된 문자열
- 나이 — 사용자의 나이
- ISBN — 책 식별자
- 책 평점 — 특정 책에 대한 사용자의 평점
- 책 제목 — 책의 제목
- 책 저자 — 책의 저자
- 출판 연도 — 책이 출판된 연도
- 출판사 — 책을 출판한 편집자
우리는 각 사용자에 대한 관련성을 기반으로 책을 순위 지정할 것입니다. 그 후에는 우리의 순위 지정과 실제 순위(사용자가 지정한 평점에 따라 책을 정렬함)를 비교하기 위해 정규화 된 할인 누적 이익 (nDCG)를 사용할 것입니다.
nDCG는 결과의 순위를 측정하여 추천 시스템의 품질을 평가하는 메트릭스입니다. 각 항목의 관련성과 결과 목록에서의 위치를 고려하여 상위 순위에 더 많은 중요성을 부여합니다. nDCG는 낮은 순위 항목의 이익을 할인하는 할인 누적 이익(DCG)과 완벽한 순위를 감안한 이상적인 DCG (iDCG)를 비교하여 계산됩니다. 이 정규화된 점수는 0에서 1 사이의 범위를 가지며, 1은 이상적인 순위를 나타냅니다. 따라서 nDCG는 어떻게 시스템이 사용자에게 관련 정보를 효과적으로 제공하는지 이해하는 데 도움이 됩니다.
우리는 먼저 라이브러리를 가져와요:
%matplotlib inline
%load_ext autoreload
%autoreload 2
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import random
from sklearn.metrics import ndcg_score
from sklearn.decomposition import PCA
from sentence_transformers import SentenceTransformer
import os
import logging
from fuxictr.utils import load_config, set_logger, print_to_json
from fuxictr.features import FeatureMap
from fuxictr.pytorch.torch_utils import seed_everything
from fuxictr.pytorch.dataloaders import H5DataLoader
from fuxictr.preprocess import FeatureProcessor, build_dataset
import src
import gc
import os
그런 다음, 세 개의 데이터 세트를로드하고 단일 데이터 세트로 병합합니다:
books_df = pd.read_csv('data/book/Books.csv')
users_df = pd.read_csv('data/book/Users.csv')
ratings_df = pd.read_csv('data/book/Ratings.csv')
df = pd.merge(users_df, ratings_df, on='User-ID', how='left')
df = pd.merge(df, books_df, on='ISBN', how='left')
그 후, 데이터에 문제점을 식별하기 위해 탐색적 데이터 분석을 수행합니다:
- 사용자가 책에 평가를 내리지 않은 관측치를 제거합니다.
df = df[df['Book-Rating'].notnull()]
- 누락된 값 확인 및 누락된 Book-Author 및 Publisher를 알 수 없는 카테고리로 대체합니다.
print(df.columns[df.isna().any()].tolist())
df['Book-Author'] = df['Book-Author'].fillna('unknown')
df['Publisher'] = df['Publisher'].fillna('unknown')
- Remove observations with missing information about the book.
df = df[df['Book-Title'].notnull()]
- Replace non-integer Year-of-Publication with null values.
df['Year-Of-Publication'] = pd.to_numeric(df['Year-Of-Publication'], errors='coerce')
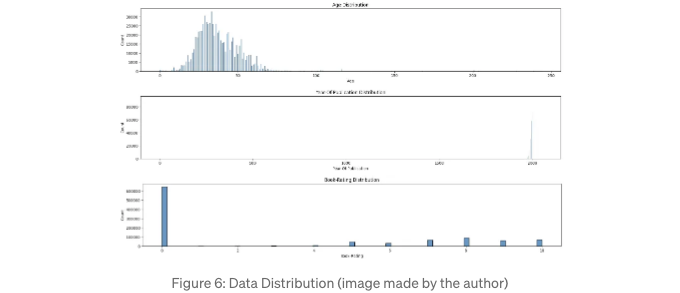
- 이상을 식별하려면 나이, 출판 연도 및 도서 평점 분포를 확인해보세요.
plt.rcParams["figure.figsize"] = (20, 3)
sns.histplot(data=df, x='Age')
plt.title('나이 분포')
plt.show()
sns.histplot(data=df, x='Year-Of-Publication')
plt.title('출판 연도 분포')
plt.show()
sns.histplot(data=df, x='Book-Rating')
plt.title('도서 평점 분포')
plt.show()
마침내, 데이터 정리를 다음과 같이 진행합니다:
- 나이가 100 (오기로 보이는 값)인 경우, 나중에 처리할 결측값으로 대체합니다.
- 데이터셋이 Kaggle에 발행된 시점인 2021년을 상한으로 제한하고, 발행년도가 0인 경우에는 나중에 처리할 결측값으로 대체합니다.
- 사용자가 독서는 했지만 평점은 남기지 않은 경우 평점이 0인 관측치를 제거합니다.
- 위치 정보에서 3가지 새로운 특성(도시, 주, 국가)를 생성합니다. 너무 노이즈가 많은 도시 정보는 사용하지 않습니다.
- FinalMLP를 위한 이진 레이블을 생성합니다. 평점이 7보다 높은 책을 사용자에게 관련성 있는 것으로 간주합니다.
df['Age'] = np.where(df['Age'] > 100, None, df['Age'])
df['Year-Of-Publication'] = np.where(df['Year-Of-Publication'].clip(0, 2021) <= 0, None, df['Year-Of-Publication'])
df = df[df['Book-Rating'] > 0]
df['city'] = df['Location'].apply(lambda x: x.split(',')[0].strip()) # too noisy, we will not use
df['state'] = df['Location'].apply(lambda x: x.split(',')[1].strip())
df['country'] = df['Location'].apply(lambda x: x.split(',')[2].strip())
df['label'] = (df['Book-Rating'] > 7)*1
데이터셋을 정리하면, 랜덤으로 사용자의 70%를 훈련용, 10%를 검증용, 20%를 테스트용으로 나눠서 데이터를 분할합니다.
# 고유 사용자 목록 생성
users = df['User-ID'].unique()
# 목록 섞기
random.shuffle(users)
# 학습용, 검증용 및 테스트용 사용자 목록 생성
train_users = users[:int(0.7*len(users))]
val_users = users[int(0.7*len(users)):int(0.8*len(users))]
test_users = users[int(0.8*len(users)):]
# 학습, 검증 및 테스트 데이터프레임
train_df = df[df['User-ID'].isin(train_users)]
val_df = df[df['User-ID'].isin(val_users)]
test_df = df[df['User-ID'].isin(test_users)]
모델에 데이터를 제공하기 전에 데이터에 일부 전처리를 적용할 것입니다:
텍스트 특성인 Book-Title에 대한 다국어 인코더를 사용하여 임베딩을 생성하고, 80%의 분산이 설명되도록 PCA를 사용하여 차원을 축소합니다.
다국어 인코더를 사용하는 이유는 제목이 서로 다른 언어로 작성되기 때문입니다. 또한, 책이 다른 책보다 더 많은 사용자에 의해 읽혔을 경우 차원 축소에 편향이 주입되지 않도록 먼저 고유한 Book-Title을 추출합니다.
# 임베딩 생성
train_embeddings = utils.create_embeddings(train_df.copy(), "Book-Title")
val_embeddings = utils.create_embeddings(val_df.copy(), "Book-Title")
test_embeddings = utils.create_embeddings(test_df.copy(), "Book-Title")
# PCA를 사용하여 차원 축소
train_embeddings, pca = utils.reduce_dimensionality(train_embeddings, 0.8)
val_embeddings = pca.transform(val_embeddings)
test_embeddings = pca.transform(test_embeddings)
# 데이터프레임에 임베딩 추가
train_df = utils.add_embeddings_to_df(train_df, train_embeddings, "Book-Title")
val_df = utils.add_embeddings_to_df(val_df, val_embeddings, "Book-Title")
test_df = utils.add_embeddings_to_df(test_df, test_embeddings, "Book-Title")
숫자형 특성의 결측값은 중앙값으로 채우고 MinMaxScaler를 사용하여 데이터를 정규화합니다.
# 숫자형 열 설정
NUMERICAL_COLUMNS = [i for i in train_df.columns if "Book-Title_" in i] + ['Age', 'Year-Of-Publication']
# 전처리 파이프라인 정의 및 데이터 변환
pipe = utils.define_pipeline(NUMERICAL_COLUMNS)
train_df[NUMERICAL_COLUMNS] = pipe.fit_transform(train_df[NUMERICAL_COLUMNS])
val_df[NUMERICAL_COLUMNS] = pipe.transform(val_df[NUMERICAL_COLUMNS])
test_df[NUMERICAL_COLUMNS] = pipe.transform(test_df[NUMERICAL_COLUMNS])
FinalMLP에 제공할 준비가 된 모든 데이터로 dataset_config.yaml 및 model_config.yaml 두 개의 yaml 구성 파일을 만들어야 합니다.
dataset_config.yaml 파일은 모델에서 사용할 feature들을 정의하는 역할을 합니다. 또한 이들의 데이터 유형을 정의하고(Embedding 레이어에서 다르게 처리됨) 훈련, 검증, 테스트 세트의 경로를 정의합니다. 아래는 구성 파일의 주요 부분을 확인할 수 있습니다:
FinalMLP_book: data_root: ./data/book/ feature_cols: - active: true dtype: float name: [Age, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3, Book-Title_4, Book-Title_5, Book-Title_6, Book-Title_7, Book-Title_8, ...] type: numeric - active: true dtype: str name: [Book-Author, Year-Of-Publication, Publisher, state, country] type: categorical fill_na: unknown label_col: {dtype: float, name: label} min_categr_count: 1 test_data: ./data/book/test.csv train_data: ./data/book/train.csv valid_data: ./data/book/valid.csv
model_config.yaml 파일은 모델의 하이퍼파라미터를 설정하는 역할을 합니다. 사용자 feature를 처리할 스트림과 아이템 feature를 처리할 스트림을 정의해야 합니다. 파일은 다음과 같이 정의되어야 합니다:
FinalMLP_book: dataset_id: FinalMLP_book fs1_context: [Age, state, country] fs2_context: [Book-Author, Year-Of-Publication, Publisher, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3, Book-Title_4, Book-Title_5, ...] model_root: ./checkpoints/FinalMLP_book/
파이썬으로 돌아가서 최근에 생성된 설정 파일을 로드합니다. 그런 다음, 특성 매핑을 만듭니다 (즉, 각 범주형 특성에 몇 가지 카테고리가 있는지, 다른 특성에서 누락된 값이 있을 경우 어떻게 대체해야 하는지 등). CSV 파일을 h5 파일로 변환합니다.
# 모델 및 데이터셋 구성 가져오기
experiment_id = 'FinalMLP_book'
params = load_config(f"config/{experiment_id}/", experiment_id)
params['gpu'] = -1 # CPU
set_logger(params)
logging.info("Params: " + print_to_json(params))
seed_everything(seed=params['seed'])
# 특성 매핑 생성 및 데이터를 h5 형식으로 변환
data_dir = os.path.join(params['data_root'], params['dataset_id'])
feature_map_json = os.path.join(data_dir, "feature_map.json")
if params["data_format"] == "csv":
# 특성 매핑 빌드 및 h5 데이터 변환
feature_encoder = FeatureProcessor(**params)
params["train_data"], params["valid_data"], params["test_data"] = \\
build_dataset(feature_encoder, **params)
feature_map = FeatureMap(params['dataset_id'], data_dir)
feature_map.load(feature_map_json, params)
logging.info("Feature specs: " + print_to_json(feature_map.features))
이후에 모델의 훈련 프로세스를 시작할 수 있습니다.
model_class = getattr(src, params['model'])
model = model_class(feature_map, **params)
model.count_parameters() # 모델에서 사용하는 매개변수 수를 출력
train_gen, valid_gen = H5DataLoader(feature_map, stage='train', **params).make_iterator()
model.fit(train_gen, validation_data=valid_gen, **params)
마침내 보이지 않는 데이터를 예측할 수 있게 되었습니다. 관측치들의 점수를 얻기 위해 배치 크기를 1로 변경하기만 하면 됩니다.
# 관측치들의 점수를 얻기
params['batch_size'] = 1
test_gen = H5DataLoader(feature_map, stage='test', **params).make_iterator()
test_df['score'] = model.predict(test_gen)
우리는 한 명의 고객을 선택했는데, 이 고객은 여러 권의 책을 평가하고 각 책에 대해 다른 평점을 매겨서 맞춤 순위를 설정할 수 있도록 했습니다. nDCG 점수는 0.986362로 나타났는데, 2권의 책을 1위에서 잘못 배치했기 때문입니다.
우리는 FinalMLP를 평가하기 위해 Recall을 사용했습니다. Recall은 시스템이 전체 중에서 모든 관련 항목을 식별하는 능력을 측정하는 지표로, 전체 관련 항목 중 검색된 관련 항목의 비율로 나타냅니다. Recall@K와 같이 Recall@3을 지정하면 시스템이 상위 K개의 추천 내에서 관련 항목을 식별하는 능력에 초점을 맞춥니다. 이것은 사용자들이 주로 상위 추천에 주목하는 추천 시스템을 평가하는 데 중요합니다. K(예: 3)의 선택은 일반적인 사용자 행동과 애플리케이션 맥락에 따라 달라집니다.
이 고객의 Recall@3을 살펴보면, 상위 3위 안에 가장 관련성 있는 책이 세 권 모두 들어있기 때문에 100%입니다.
true_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['Book-Rating'].tolist()])
y_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['score'].tolist()])
ndcg_score(true_relevance, y_relevance)
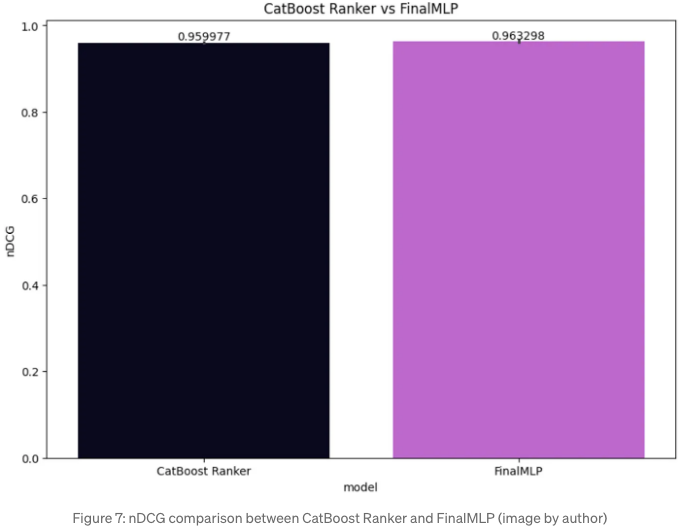
남은 테스트 세트에 대한 nDCG 점수를 계산하고, Figure 7에서 FinalMLP 성능을 CatBoost Ranker와 비교했습니다. 두 모델 모두 잘 수행했지만, 이 테스트 세트에서 FinalMLP가 조금 더 우수한 성능을 보였습니다. 사용자 당 평균 nDCG가 0.963298인 반면 CatBoost Ranker는 0.959977에 그쳤습니다.
해석 가능성 측면에서 이 모델은 특성 선택을 수행하여 가중치 벡터를 추출할 수 있게 합니다. 그러나 각 특성의 중요성을 해석하고 이해하는 것은 간단하지 않습니다. 임베딩 레이어 이후에는 930차원 벡터가 생성되어 원래 특성으로 재매핑하기가 어려워집니다. 그럼에도 불구하고, 이전에 언급된 선형 항으로 주어진 선형 처리 후 각 스트림의 출력의 절대값을 추출함으로써 각 스트림의 중요성을 이해해 볼 수 있습니다.
이를 위해 InteractionAggregation 모듈을 변경하고 각 단계 후에 선형 변환된 값 추출을 위해 다음 코드 라인을 추가해야 합니다:
...
self.x_importance = []
self.y_importance = []
def forward(self, x, y):
self.x_importance.append(torch.sum(torch.abs(self.w_x(x))))
self.y_importance.append(torch.sum(torch.abs(self.w_y(y))))
...
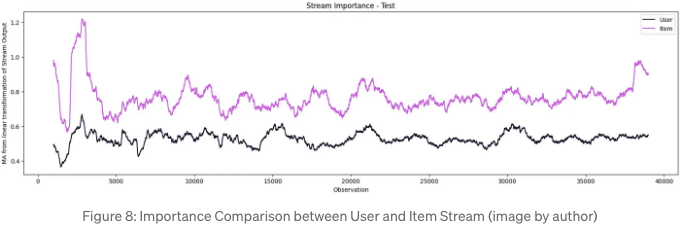
한 번 훈련을 받으면, 각 스트림의 선형 변환 결과에서 절대 값을 예측하고 플롯할 수 있습니다. 그림 8에 보여진 것처럼, 상품 스트림이 사용자 스트림보다 중요성이 높습니다. 이는 상품에 대한 기능이 훨씬 많기 때문이지만 사용자 특성이 상당히 일반적이기 때문에 발생합니다.
결론
추천 시스템은 사용자 경험을 향상시켜 맞춤형 추천을 제공하며, 성장과 혁신을 이끄는 데이터 기반 의사 결정을 기관에 제공하여 사용자 경험을 향상시킵니다.
이 기사에서는 추천 시스템용으로 개발된 가장 최근 모델 중 하나를 소개했습니다. FinalMLP는 두 개의 독립 네트워크를 가진 딥 러닝 모델입니다. 각 네트워크는 사용자와 항목 이 두 가지 다른 관점 중 하나에 중점을 둡니다. 각 네트워크로부터 학습된 다른 패턴은 그 다음 각 네트워크의 학습 내용을 결합하는 책합층에 공급됩니다. 사용자-항목 쌍 상호 작용의 단일 뷰를 생성하여 최종 점수를 생성합니다. 이 모델은 CatBoost Ranker를 이겼으며 우리의 사용 사례에서 잘 수행했습니다.
알고리즘 선택은 해결하려는 문제와 데이터셋에 따라 다를 수 있음을 유의해 주세요. 항상 여러 방법을 상호 비교하는 것이 좋은 실천 방법입니다. 또한 xDeepFM, AutoInt, DHEN 또는 DLRM을 테스트하는 것도 고려할 수 있습니다.
내 소개
인공지능 분야의 시리얼 기업가 및 리더입니다. 비즈니스를 위한 인공지능 제품을 개발하고 인공지능에 초점을 맞춘 스타트업에 투자합니다.
창립자 @ ZAAI | LinkedIn | X/Twitter
참고 문헌
[1] Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. FinalMLP: CTR 예측을 위한 향상된 이차원 MLP 모델. arXiv:2304.00902, 2023.
[2] Jiajun Fei, Ziyu Zhu, Wenlei Liu, Zhidong Deng, Mingyang Li, Huanjun Deng, Shuo Zhang. DuMLP-Pin: 집합 특성 추출을 위한 이중-MLP-내적 불변 네트워크. arXiv:2203.04007, 2022.
[3] Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, Xiuqiang He. BARS-CTR: Open Benchmarking for Click-Through Rate Prediction. arXiv:2009.05794, 2020.