
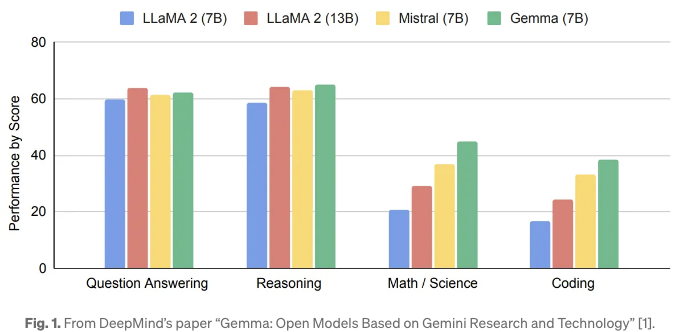
몇 주 전에 Google은 Gemma 언어 모델을 소개했습니다. 두 가지 크기의 경량 모델, Gemma 2B와 7B가 있습니다. 이러한 모델들은 다른 오픈 소스 모델과 비교했을 때 해당 크기에 대해 최고 수준의 성능을 달성한다고 주장됩니다. 이 모델들은 주로 소비자급 장치를 대상으로 하고 있습니다. Google의 테스트에서도, 특정 주요 성능 기준에서 Gemma가 일부 더 큰 모델들을 크게 능가했음이 확인되었습니다. 그 결과는 그림 1에서 확인할 수 있습니다.
이 기사에서는 Gemma 2B를 검색 보강 생성(RAG) 설정에서 사용하여, 모델이 훈련 중에 본 적이 없는 문서에 대한 질문-응답에 활용할 것입니다. RAG는 모델의 응답을 향상시키는 프로세스로, 훈련 데이터 외부의 권위 있는 지식 소스를 활용합니다. 검색 시스템은 관련 문서 스니펫을 검색하여 Gemma가 생성에 영향을 미치기 위한 컨텍스트로 사용할 것입니다. 우리는 어떻게 Gemma가 기본 검색기와 고급 검색기로부터 컨텍스트를 활용하는지 다양한 성능 각도에서 평가할 것입니다. 또한, 해당 성능은 제한된 자원 시스템을 위한 또 다른 LLM로, TinyLlama 1.1B와 비교될 것입니다.
목차
1.0 환경 설정 2.0 디자인 및 구현 2.1 모듈 LoadVectorize 2.2 모듈 LLMPerfMonitor 2.3 주요 모듈 3.0 초기 테스트 3.1 젬마 2B 대 TinyLlama 1.1B의 응답 정확도 4.0 앙상블 리트리버 구동된 RAG 4.1 고급 리트리버와 함께 젬마 vs TinyLlama의 성능 비교 5.0 최종 생각
1.0 환경 설정
이 실험은 MacBook Air M1(8GB RAM)에서 진행됩니다. 여기서 사용되는 Python 버전은 3.10.5입니다. 먼저 이 프로젝트를 관리하기 위해 가상 환경을 생성해 보겠습니다. 환경을 생성하고 활성화하려면 다음을 실행하세요:
python3.10 -m venv mychat
source mychat/bin/activate
이제 필요한 모든 라이브러리를 설치할 수 있습니다:
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
위의 두 번째 줄은 Metal 지원이 포함된 llama-cpp-python 라이브러리를 설치하는 것입니다. 이 라이브러리는 M1 프로세서에서 하드웨어 가속을 이용하여 LLM을 불러오는 데 사용될 것입니다. Metal을 사용하면 계산이 GPU에서 실행됩니다.
환경이 준비되었으니 우리의 RAG 시스템 설계 및 구현을 살펴보겠습니다.
2.0 디자인 및 구현
이 QA 시스템에는 그림 2에 설명된 세 가지 모듈이 있습니다.
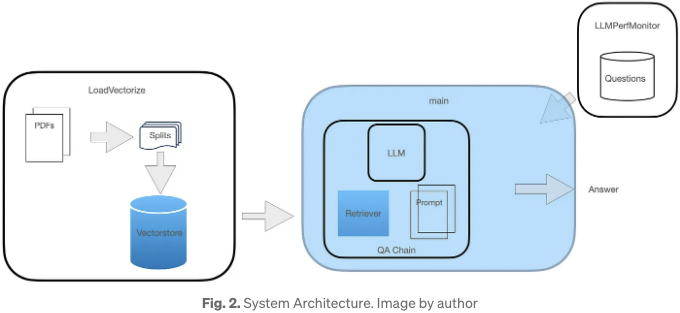
이 다이어그램에서 강조된 두 구성 요소는 이 기사의 후반에서 성능 향상을 위해 다시 다룰 예정입니다. 각 모듈의 역할은 다음과 같습니다:
- 왼쪽에 있는 첫 번째 모듈은 온라인 PDF 문서를 로드하고 벡터화하는 과정을 포함합니다.
- 오른쪽에 있는 더 작은 모듈은 보조 모듈 역할을 합니다. 이 모듈은 코사인 유사도를 계산하고 모델 응답 시간을 평가함으로써 일련의 질문을 통해 시스템 성능을 객관적으로 측정할 수 있도록 도와줍니다. 또한 시스템 메모리 사용량도 측정합니다.
- 중앙에 있는 주요 모듈은 LLM을 로드하고 FAISS 리트리버를 인스턴스화한 뒤, LLM, 리트리버 및 사용자 정의 프롬프트를 포함하는 리트리버 체인을 생성하는 것을 포함합니다.
이제 주요 구현 결정 사항과 코드를 자세히 살펴보겠습니다.
2.1 모듈 LoadVectorize
이 모듈은 다음과 같이 3가지 함수로 구성됩니다:
- load_doc 함수는 온라인 PDF 문서를 로드하는 데 사용되며, 처음에는 100자씩 청크로 분할하고 20자의 오버랩이 있는 문서 목록을 반환합니다.
- vectorize 함수는 위 load_doc 함수를 호출하여 문서의 청크 목록을 가져와 임베딩을 생성하고 opdf_index라는 로컬 디렉토리에 커밋하며 FAISS 객체를 반환합니다.
- load_db 함수는 opdf_index 디렉토리 내에 FAISS vectorstore가 있는지 확인하고 로드를 시도합니다. 그렇지 않은 경우 이전 함수 vectorize를 호출하여 문서를 로드하고 벡터화합니다. 마지막으로 FAISS 객체를 반환합니다.
이 모듈은 이전 작업 [2]에서 소개되었으며 초기에 여기서 그대로 사용되었습니다.
2.2 Module LLMPerfMonitor
이 모듈은 또한 3개의 함수로 구성됩니다:
- 함수 get_questions_answers은 디스크에있는 파일에서 질문 목록과 예상 답변을 읽습니다. 이러한 답변은 모델의 반환된 응답과 함께 사용되어 코사인 유사성을 계산하는 데 사용됩니다.
- 함수 calc_similarity은 두 개의 문자열 인수를 허용합니다. 두 문자열은 초기에 텐서 임베딩으로 변환됩니다. 그런 다음 sentence_transformers의 util.pytorch_cos_sim 함수가 모든 i와 j에 대해 코사인 유사성 cos_sim(a[i], b[j])을 계산합니다. 문장이 의미적으로 매우 유사하면 코사인 유사성은 1에 가까울 것입니다. 그들이 정반대라면, 이 값은 이상적으로 0에 가까워야 합니다.
- 함수 get_mem_cpu_util은 부모 프로세스 ID(ppid)를 인자로 사용하여 psutil을 사용하여 해당 메모리 사용량 (물리적 RAM 사용량을 나타냄)을 구합니다.
이 모듈의 전체 코드 목록은 아래에 표시되어 있습니다.
# LLMPermMonitor.py
from sentence_transformers import SentenceTransformer, util
import os, psutil
import nltk
from nltk.translate import meteor
from nltk import word_tokenize
def get_questions_answers() -> list[str]:
# 질문과 답변이 교차된 목록을 반환합니다.
with open("sh_qa_list.txt") as qfile:
lines = [line.rstrip()[3:] for line in qfile]
return lines
def calc_similarity(sent1, sent2) -> float:
# 임베딩을 생성하고 코사인 유사성을 계산하여 값을 반환합니다.
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 두 문자열에 대한 임베딩 계산
embedding_1 = model.encode(sent1, convert_to_tensor=True)
embedding_2 = model.encode(sent2, convert_to_tensor=True)
return util.pytorch_cos_sim(embedding_1, embedding_2).item()
def get_mem_cpu_util(ppid) -> tuple[float, float]:
# RSS를 GB로 수집하고 총 CPU 이용률을 반환합니다.
process = psutil.Process(ppid) # 부모 프로세스 반환
mem_usage = process.memory_info().rss / 1024 ** 3 # GB 단위로
cpu_usage = sum(psutil.cpu_percent(percpu=True))
return mem_usage, cpu_usage
2.3 주요 모듈
주요 모듈은 주로 QA 파이프라인을 정의하는 데 관여합니다. 또한 이 앱의 리소스 사용 추적을 용이하게하기 위해 별도의 스레드에서 수행될 때에만 가능합니다. 따라서 본 모듈은 메인 스레드가 전체 LangChain 파이프라인을 수행하고, 단일 자식 스레드가 일정 간격으로 부모의 통계를 수집하고 공유 데이터 구조에 저장하는 간단한 멀티 스레드 시스템을 가능하게 합니다. 이러한 병렬 처리 설계를 캡처한 스레드 다이어그램은 Figure 3에 나와 있습니다.
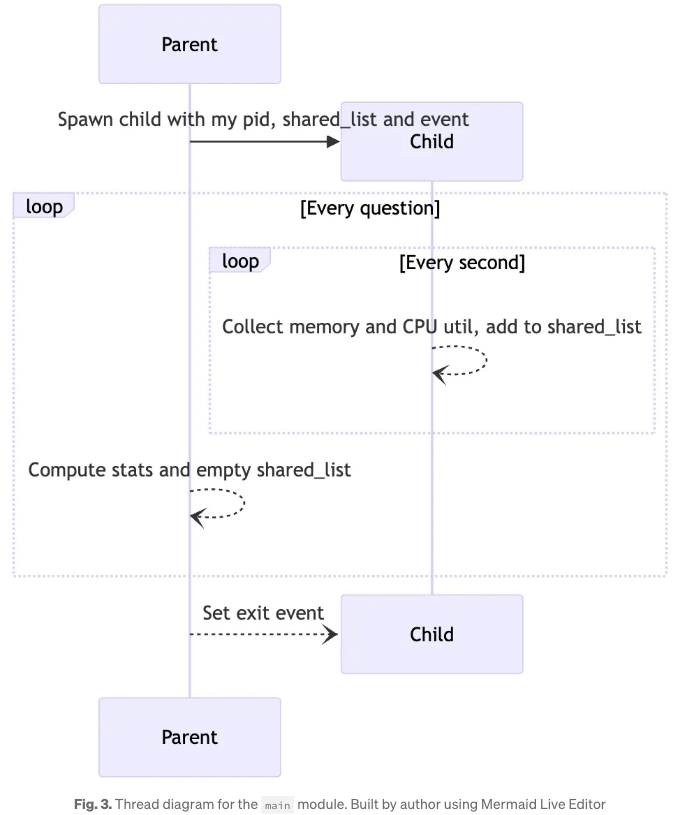
부모는 자신의 pid, 리스트 객체인 공유 데이터 구조 및 스레딩 이벤트 객체를 사용하여 자식을 생성합니다. 이벤트 객체는 자식이 종료할 때를 결정하는 데 사용됩니다. 자식이 작동 중일 때, 1초 간격으로 메모리 및 CPU 사용량을 수집하고 이를 리스트인 shared_list에 저장합니다. 부모는 각 쿼리에 대해 QA 체인을 실행하고, 자식이 수집한 데이터를 사용하여 통계를 계산합니다. 부모가 모든 질문을 실행한 후, 이벤트 객체를 설정하고 자식이 종료될 때까지 기다립니다. 자식이 이벤트가 설정된 것을 확인하면, 1초 내에 가장 길게 while 루프를 종료하고 부모도 종료됩니다.
QA 파이프라인의 경우, 이 모듈은 우선 Gemma에 대한 프롬프트 템플릿을 다음 템플릿으로 정의합니다:
bos``start_of_turnuser
'context'
'question'end_of_turn
start_of_turnmodel
LLM 메모리 풋프린트를 더 줄이기 위해 lmstudio-ai의 HuggingFace repo [3]의 Gemma의 양자화된 버전을 채택할 예정입니다. 양자화된 모델은 모델 파라미터에 더 적은 비트를 사용합니다. 양자화된 LLM을 GGUF 형식으로 로드하기 위해서는 LlamaCpp가 사용됩니다. LoadVectorize 모듈에서 반환된 FAISS 객체를 사용하여 FAISS 검색기가 초기 테스트를 위한 기본 검색기로 생성됩니다. 위의 객체를 사용하여 RetrievalQA 체인이 인스턴스화되며, 질의에 사용됩니다.
주요 모듈의 전체 목록은 다음과 같습니다.
# main.py
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.llms import LlamaCpp
from langchain_community.embeddings import HuggingFaceEmbeddings
import LoadVectorize
import LLMPerfMonitor
import threading
import os
import time
import timeit
# 자식 작업
def monitor_thread(event, ppid, shared_list):
while not event.is_set():
mem,cpu = LLMPerfMonitor.get_mem_cpu_util(ppid) # 스레드의 이벤트 루프에서 비동기 작업 실행
shared_list += [mem,cpu]
time.sleep(1)
def main():
event = threading.Event() # 이벤트 개체 생성
shared_list = [] # 공유 큐 객체 생성
child = threading.Thread(target=monitor_thread, args=(event,os.getpid(),shared_list))
child.start()
# 검색기 생성
db = LoadVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
# 질문과 답변 목록
qa_list = LLMPerfMonitor.get_questions_answers()
# 프롬프트 템플릿
qa_template = """
<bos><start_of_turn>user
{context}
{question}<end_of_turn>
<start_of_turn>model
"""
# 프롬프트 인스턴스 생성
QA_PROMPT = PromptTemplate.from_template(qa_template)
llm = LlamaCpp(
model_path="./models/gemma_2b/gemma-2b-it-q4_k_m.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# 사용자 정의 QA 체인
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=faiss_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
print('model;question;cosine;resp_time;memory_util;cpu_util')
# 질문, 통계 계산 루프
for i,query in enumerate(qa_list[::2]):
start = timeit.default_timer()
result = qa_chain({"query": query})
time = timeit.default_timer() - start # 초
avg_mem = sum(shared_list[::2])/len(shared_list[::2])
#avg_cpu = sum(shared_list[1::2])/len(shared_list[1::2])
shared_list.clear()
cos_sim = LLMPerfMonitor.calc_similarity(qa_list[i*2+1],result["result"])
print(f'gemma_2b;Q{i+1};{cos_sim:.5};{time:.2f};{avg_mem:.2f};{avg_cpu:.2f}')
event.set() # 자식 스레드가 종료되도록 이벤트를 설정합니다
child.join() # 자식 스레드가 종료될 때까지 대기
if __name__ == "__main__":
main()
TinyLlama에 대해서는 동일한 시스템 아키텍처가 채택될 것입니다. 또한, 소수의 코드 변경이 필요한 유일한 모듈은 주 모듈이며, 여기서 LlamaCpp의 인스턴스 속성인 module_path와 변수 qa_template이 유일한 차이점입니다.
3.0 초기 테스트
우리의 초기 테스트에서는 청크 크기와 중첩 매개변수를 변경하여 테스트 머신에서 최상의 정확도를 제공하는 최적의 구성을 결정합니다. 텍스트 분할기가 벡터화 단계의 일부로 사용하는 청크 크기는 100, 250, 500, 750부터 1,000 자까지 다양하게 변경되었습니다. 중첩 매개변수는 항상 청크 크기의 20%로 유지되었습니다. 각 청크 크기에 대해 RAG 시스템은 10가지 다른 질문에 대해 테스트되었습니다. 응답 정확도 측면에서, 청크 크기 500이 가장 우수한 결과를 반환했습니다.
예를 들어, 다음은 8번째 질문이었습니다:
다음은 LLM이 청크 크기 100에서의 응답이었으나, 이는 올바르지 않습니다:
그리고 청크 크기 500에서, 이 LLM의 응답은 아래와 같았습니다:
이것이 올바른 답입니다! 이는 지난 시간 여러 다른 모델들에게 (현재 연구의 일부가 아님) 동일한 질문이 제기되었을 때 그들이 전혀 성공하지 못한 반면, 젬마에게 큰 승리로 이어집니다.
게다가, 이 시스템은 벡터화 구성에서 평균 응답 시간도 가장 낮았습니다. 그림 4에서 보이는 바와 같이, 이 그래프는 95% 신뢰 구간과 함께 표시되었습니다.
이 실험 결과를 바탕으로, 청크 크기 500과 해당하는 겹침 크기 100이 이후 모든 테스트에 채택되었습니다.
이러한 매개변수가 변할 때 벡터 공간 속성의 변경을 표시하기 위해, 그림 5는 라이브러리 renumics-spotlight를 사용하여 임베딩 시각화를 보여줍니다. 이 시각화에 관심 있는 분들이나 이를 작성하는 방법을 알아보고 싶은 분들은 우리의 이전 작업을 확인해보세요. [2].
위의 내용을 변경하면 벡터 공간에 상당한 영향을 미친다는 것이 분명하다. 왼쪽에서는 100자의 청크 크기를 사용하면, 임베딩이 몇 개의 이상치를 가진 단일 밀집 클러스터처럼 보입니다. 반면에 다른 끝에서 1,000자의 청크 크기를 사용하면, 여전히 단일 클러스터로 보이지만 지역 밀도가 다양하고 각 벡터마다 다른 가장 가까운 이웃들이 있을 것으로 예상됩니다.
3.1 젬마 2B 대화모델 대 티니람마 1.1B 대화모델 응답 정확도
이 첫 번째 성능 비교에서, 우리는 그들의 응답 정확도를 살펴볼 것입니다. 다음은 사용된 질문 중 하나와 해당하는 기대되는 답변입니다:
젬마 LLM은 다음과 같이 응답했습니다:
작은라마 LLM은 다음과 같이 응답했습니다:
두 모델 모두 정확한 응답을 내놨습니다! 다음으로 제시된 또 다른 질문은 다음과 같습니다:
이 경우, Gemma는 주어진 맥락으로 대답할 수 없다고 응답했으며 아래와 같이 나와 있습니다:
반면에, TinyLlama는 동일한 맥락으로 응답을 제공할 수 있었지만 응답은 부분적으로 부정확했습니다. 아래에서 확인할 수 있습니다 (일부 추출; 포인트 2가 잘못됨):
더 넓은 성능 비교를 진행하기 전에, 먼저 검색 성능을 향상시키는 것을 살펴보겠습니다.
4.0 RAG 앙상블 리트리버로 구성된
LangChain은 EnsembleRetriever라는 고급 리트리버를 보유하고 있습니다. 이 리트리버는 리트리버 목록을 입력으로 받아 앙상블하고 결과를 재정렬하여 RAG 성능을 향상시킵니다. FAISS와 BM25 리트리버의 장점을 3:7 비율로 이용하여 이전 작업[4]에서 최상의 응답 정확도를 달성했습니다.
그림 2에 나와 있는 동일한 시스템 아키텍처를 사용하면, 이 고급 리트리버에 맞추기 위해 LoadVectorize 모듈과 메인 모듈을 약간 수정해야 합니다. LoadVectorize 모듈의 vectorize 함수에는 BM25 리트리버를 인스턴스화하는 새로운 단계가 포함될 것입니다:
def vectorize(embeddings) -> tuple[FAISS, BM25Retriever]:
docs = load_doc()
db = FAISS.from_documents(docs, embeddings)
db.save_local("./opdf_index")
bm25_retriever = BM25Retriever.from_documents(docs) <<<<<
bm25_retriever.k = 5 <<<<<
return db, bm25_retriever
주요 모듈 내에서 EnsembleRetriever를 인스턴스화하는 라인은 아래와 같이 추가됩니다:
db, bm25_r = LoadVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
r = 0.3
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_r, faiss_retriever], weights=[r, 1-r])
이 앙상블 검색기는 이후 QA 체인에서 사용될 것입니다. 이 QA 시스템이 EnsembleRetriever를 사용하도록 변경하는 데 필요한 변경점은 여기까지입니다.
해당 시스템의 모든 코드에는 GitHub의 다음 저장소에서 확인할 수 있습니다:
이제 Gemma와 TinyLlama 간의 보다 포괄적인 성능 비교를 살펴보려고 합니다.
4.1 Gemma 대 TinyLlama 성능 비교 (고급 리트리버 사용)
본 비교 실험에서는 같은 10가지 질문을 고급 리트리버를 이용하여 동일하게 Gemma 2B와 TinyLlama 1.1B에 제시하고, 성능 비교를 위해 이들의 응답 정확도, 응답 시간, 메모리 사용 및 CPU 이용률을 기록할 것입니다.
Gemma가 FAISS 리트리버에서의 컨텍스트로 급유되었을 때, 제6번 질문에 대한 응답을 제공하지 못했습니다. 하지만 앙상블 리트리버로 구동된 Gemma가 다음과 같이 응답했습니다:
정확한 답변입니다! 이 모델이 향상된 유일한 질문은 아닙니다. Gemma의 응답 정확도가 4개에서 8개로 두 배로 증가했습니다. 반면에 TinyLlama의 정확한 응답률은 3개에서 5개로 증가했습니다.
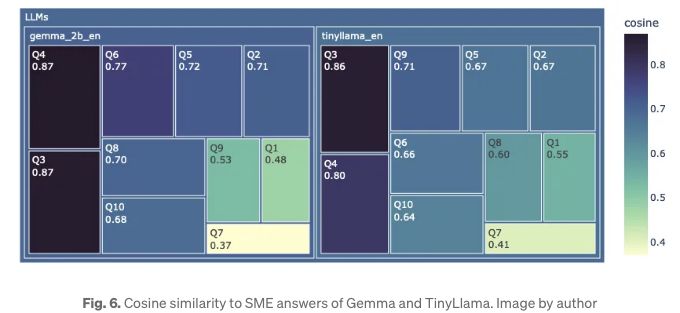
간접적으로 응답 정확도를 파악하기 위해, 그림 6은 모든 질문에 대한 LLMs 간의 코사인 유사도를 사용하여 샘플 답변에 대한 트리맵 차트를 보여줍니다. 답변이 잘못되었더라도 선택된 단어 때문에 높은 유사도 값이 있을 수 있으니 주의해야 합니다. 이 결과를 나타내기 위해 트리맵을 채택했습니다. 이 데이터에는 내재된 계층 구조가 있으며, 차트에서 직사각형의 면적과 색상 음영을 사용하여 선택한 측정 항목의 크기를 구별할 수 있습니다. 이 차트에서 Gemma는 더 어두운 음영의 사각형이 많고, 심지어 LLM 수준에서도 더 짙은 파란색 음영을 갖고 있습니다. 이는 Gemma가 TinyLlama보다 더 높은 응답 정확도를 자랑한다는 것을 의미합니다.
LLM의 응답 시간을 비교하기 위해 Treemap이 그림 7에 표시되어 있습니다. 거의 모든 TinyLlama 질문 사각형이 연하게 그려져 있어요. 평균적으로 Gemma는 TinyLlama에 비해 질문에 대한 응답이 1.5배 더 오래 걸렸어요. TinyLlama가 크기적으로 더 작은 모델이기 때문에 빠르게 응답할 것으로 예상됩니다.
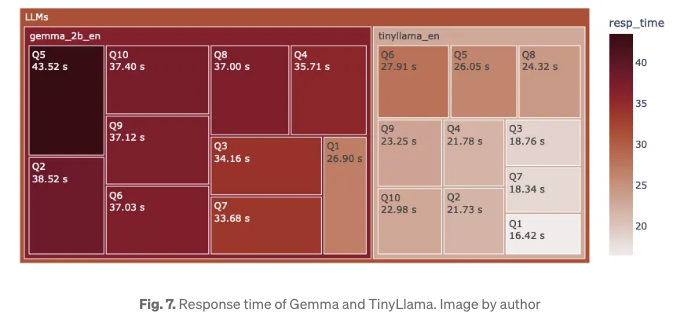
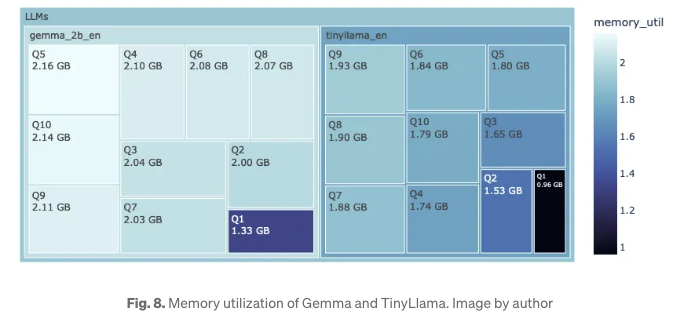
그림 8에서 Gemma와 TinyLlama의 메모리 사용량이 나타나 있어요. 여기서 더 짙은 색이 낮은 메모리 사용을 나타내요. 앞과 마찬가지로, TinyLlama가 1.1B 모델인 반면 Gemma 2B와 비교했을 때, 전자가 더 낮은 메모리 사용량을 갖고 있어요.
요약하자면, Gemma 2B는 뛰어난 응답 정확도를 자랑하며, EnsembleRetriever와 같은 고급 retriever를 사용함으로써 더욱 향상되었습니다. TinyLlama와 비교했을 때, Gemma는 메모리 풋프린트가 16% 크고, 평균 14초 추가 지연이 있지만, 합리적으로 보입니다.
5.0 최종 결론
작년 후반부터 오픈소스 대형 언어 모델은 정확도에서 거대한 발전을 이루었습니다. 이러한 모델이 내부 문서에 훈련되어 있지 않더라도, Retrieval-Augmented Generation (RAG) 설정에서 그들의 능력을 활용할 수 있습니다. 그러나 자원이 제한된 환경에서 대형 모델을 실행하는 것은 불가능합니다. TinyLlama 1.1B는 이 분야에서 유망한 모델 중 하나입니다.
이 기사에서는 Gemma 2B에 대해 포괄적으로 살펴보았습니다. RAG 설정에서 ensemble retriever와 결합되었을 때, 이 모델은 최근 문서에 대한 질문에 대해 80% 이상의 정확한 답변을 제공하는 것으로 입증되었으며, 이는 TinyLlama보다 33% 우수한 성과를 보여주었습니다. 이 개선은 메모리 풋프린트가 16% 크고 응답 지연이 1.5배 길어진 비용이 들지만, 합리적인 대가로 보입니다.
위 내용을 읽어 주셔서 감사합니다!
참고 자료
- Gemma: Google DeepMind의 Gemini 연구 및 기술에 기반한 개방 모델
- RAG 성능에 미치는 FAISS 벡터 공간의 영향을 이해하기 위한 시각화
- https://huggingface.co/lmstudio-ai/gemma-2b-it-GGUF
- Ensembled Retriever에서 Context를 사용하여 Mistral 7B를 이용한 내부 문서 쿼리하기