
과학 논문, 데이터 집합 및 학술 논문의 거대한 양은 오늘날 연구원, 학자 및 전문가들에게 그들의 분야에서 최신 개발 동향을 따라가기 위한 어려움을 제기합니다.
이러한 도전은 과학적 지식 검색 프로세스를 효율적이고 효과적으로 만드는 혁신적인 접근 방식의 필요성을 강조합니다.
AI 및 의미 검색은 정보 접근 및 상호 작용 방식을 변혁하는 데 놀라운 가능성을 보여 주었습니다. 이러한 혁신의 선두에서는 OpenAI 함수의 응용이 있으며, 자연어 입력을 구조화된 출력이나 함수 호출로 변환합니다.
예를 들어, 최신 재생 에너지 기술에 대한 질문을 처리해야 할 때 OpenAI의 모델은 최근 논문을 살펴보고 주요 논문과 결과물을 식별하여 연구 트렌드를 요약할 수 있습니다. 특정 키워드에 국한되지 않고 작동할 수 있어요.
이 능력은 연구 과정을 가속화할 뿐만 아니라, 전통적인 검색 방법으로는 즉시 발견하기 어렵거나 연결점과 통찰을 발견하는 데 도움이 됩니다.
이 기사의 목적은 OpenAI 기능과 arXiv API를 활용하여 학술 연구 결과물의 검색, 요약 및 제시를 간소화하는 데 사용할 수 있는 Python 코드를 제공하는 것입니다.
이 안내서의 구성은 다음과 같습니다:
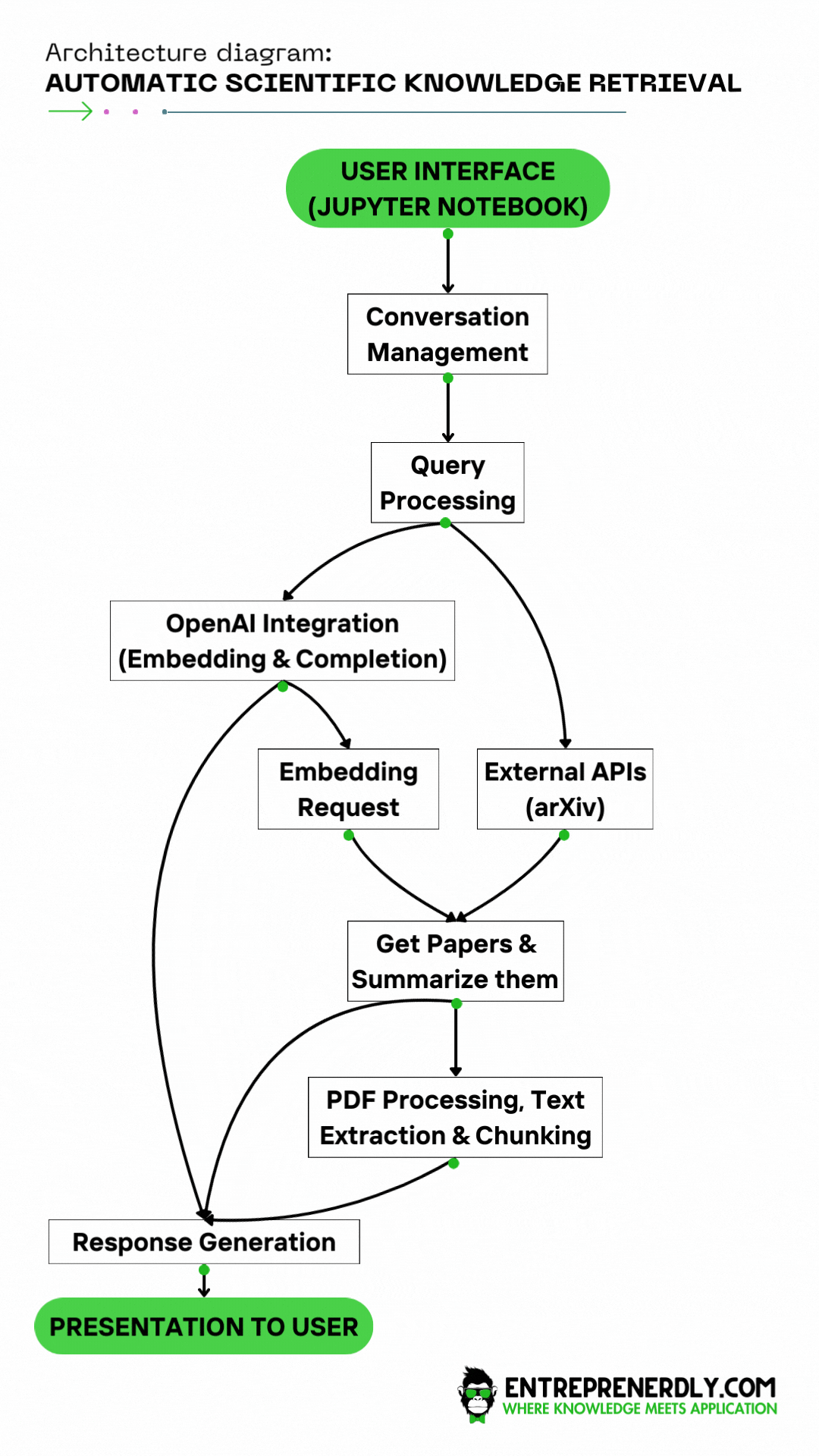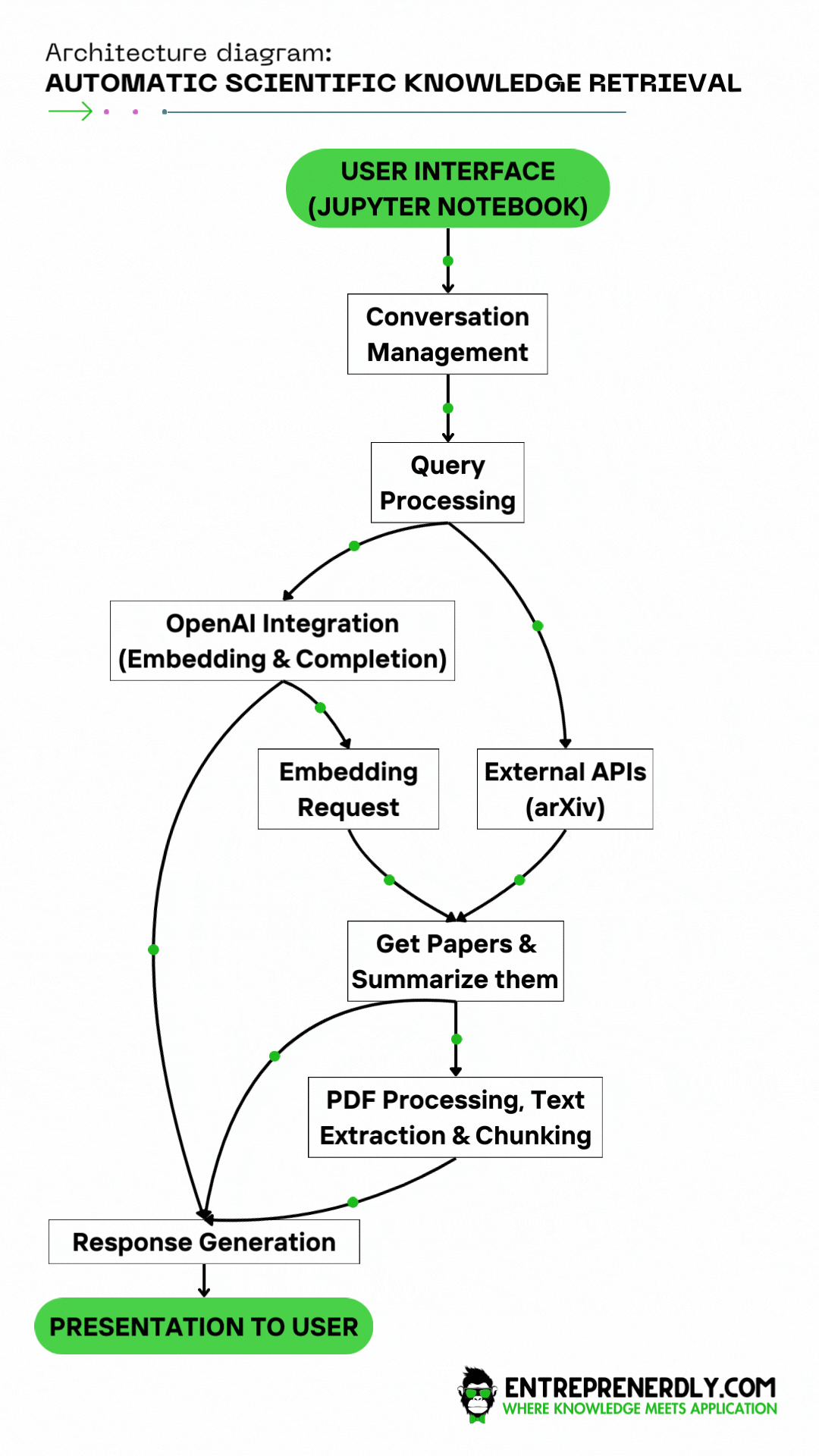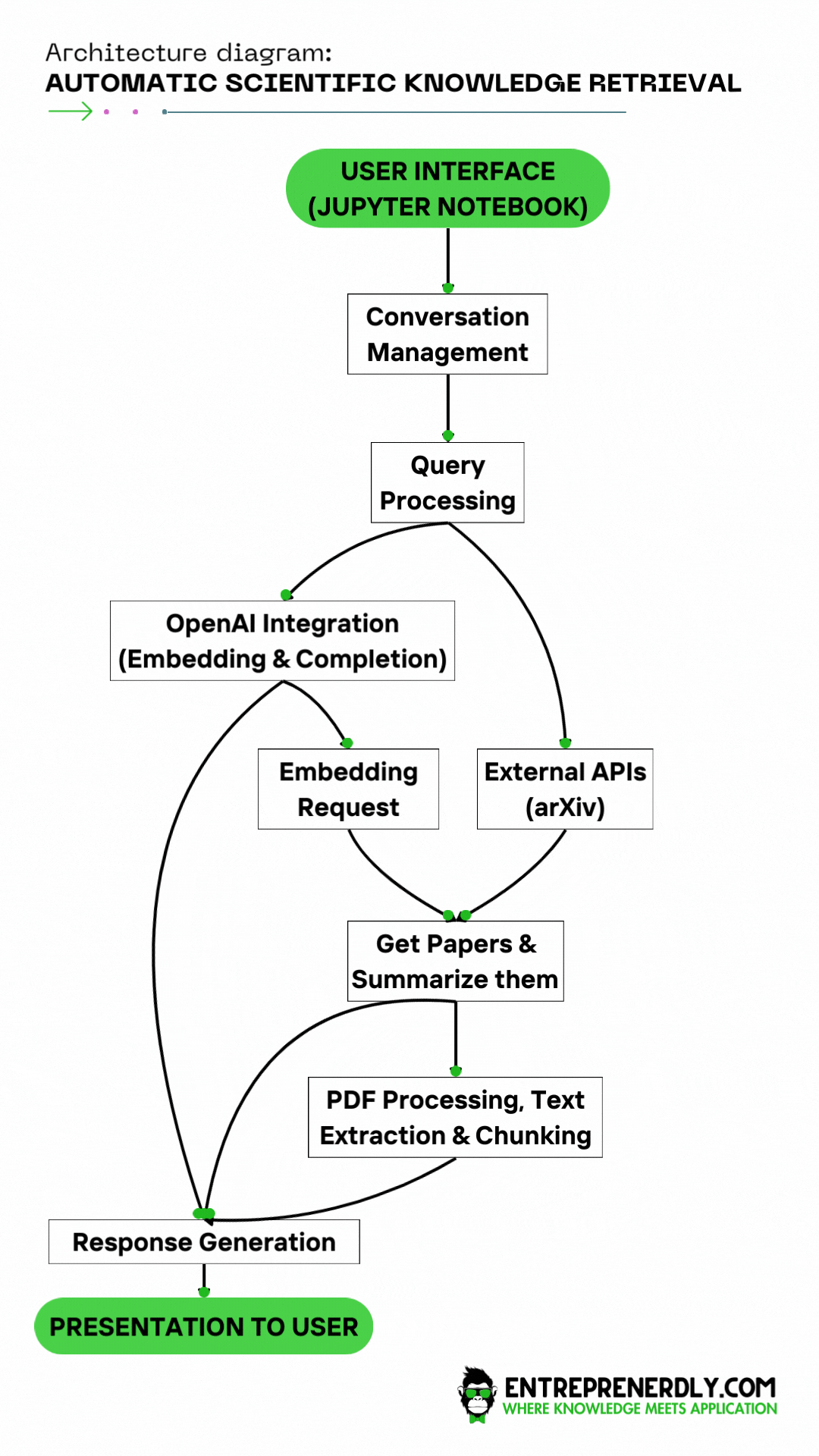
1. 솔루션 아키텍처
연구 챗봇을 위한 솔루션 아키텍처는 사용자에게 과학적 지식을 처리하고 전달하기 위한 다층 접근 방식을 구체화합니다.
워크플로우는 복잡한 사용자 쿼리를 처리하고 외부 API와 상호작용하여 정보를 제공하는 데 설계되었습니다.
이 아키텍처는 초기 사용자 입력부터 최종 응답 전달까지의 정보 흐름을 용이하게 하는 다양한 구성 요소를 통합합니다.
-
사용자 인터페이스 (UI): 사용자는 이 인터페이스를 통해 쿼리를 제출합니다. 이 경우 주피터 노트북에서 제출됩니다.
-
대화 관리: 이 모듈은 대화를 처리하여 사용자 상호작용 중에 문맥이 유지되도록 합니다.
-
쿼리 처리: 사용자의 쿼리는 이곳에서 해석되며, 의도를 이해하고 후속 조치를 위해 준비됩니다.
- OpenAI API 통합 (임베딩 및 완성):
- 완성 부분은 일부 쿼리에 대해 즉시 응답을 생성하는 쿼리를 직접 처리합니다.
- 임베딩 요청은 학술 논문 검색이 필요한 쿼리에 사용되며 관련 문서를 찾기 위한 벡터를 생성합니다.
-
외부 API (arXiv): 이 부분은 챗봇이 쿼리를 기반으로 arXiv와 같은 외부 데이터베이스와 상호작용하여 과학 논문을 가져오는 곳입니다.
-
기사 가져오기 & 요약: 이 기능은 기사를 검색한 후 쿼리의 맥락에 따라 요약할 기사를 우선순위로 설정하기 위해 임베딩을 사용합니다.
-
PDF 처리, 텍스트 추출 및 청킹: 자세한 정보가 필요한 경우, 시스템은 PDF를 처리하고 텍스트를 추출하여 작은 조각으로 나누어 요약 작업을 준비합니다.
-
응답 생성:
- OpenAI API Completion 서비스에서 응답을 통합합니다.
- arXiv API에서 검색하고 처리된 논문 요약을 포함하며, 이는 이전에 생성된 임베딩을 기반으로 합니다.
-
사용자에게 제공: AI가 생성한 답변과 논문 요약을 결합한 응집된 응답이 사용자에게 제공되는 마지막 단계입니다.
2. Python 시작하기
2.1 필수 라이브러리 설치
우리는 다양한 Python 라이브러리를 활용하며, 각각이 특정 기능을 제공하여 과학적 지식의 검색 및 처리를 용이하게 합니다. 각 라이브러리와 역할에 대한 개요는 다음과 같습니다:
- scipy: 과학 계산에 필수적이며, 최적화, 선형 대수, 적분 등을 위한 모듈을 제공합니다.
- tenacity: 실패한 작업을 다시 시도하는 기능을 제공하며, 외부 API 또는 데이터베이스에 안정적으로 요청을 보내는 데 유용합니다.
- token: OpenAI 모델과 함께 사용하기 위해 설계된 빠른 BPE 토크나이저로, GPT-4와 같은 AI 모델을 처리하기 위한 텍스트의 효율적인 토큰화를 용이하게 합니다.
- termcolor: 컬러링된 터미널 출력을 가능하게 하여, 로그 메시지나 디버깅을 편하게 구분할 수 있습니다.
- openai: GPT-3와 같은 OpenAI API와 상호 작용하기 위한 공식 라이브러리로, AI 모델 응답을 쿼리하고 수신하는 데 중요합니다.
- requests: 웹 서비스 또는 API에 HTTP 요청을 보내기 위한 라이브러리로, 데이터 검색이나 과학 자원과의 상호 작용에 활용될 수 있습니다.
- arxiv: arXiv.org의 과학 논문을 검색, 가져오기 및 관리를 간소화합니다.
- pandas: 대용량 데이터 처리 및 분석에 중요한 역할을 하며, 대규모 데이터 세트를 처리하는 데 사용되는 구조 및 기능을 제공합니다.
- PyPDF2: PDF 파일로부터 텍스트를 추출할 수 있도록 하며, PDF 형식의 과학 논문을 처리하는 데 필수적입니다.
- tqdm: 루프나 장기 실행 프로세스에 대한 진행 표시 막대를 생성하여 사용자 경험을 향상시킵니다.
2.2 환경 설정하기
먼저 OpenAI 플랫폼에 계정을 만들고 계정 설정의 API 섹션에서 API 키를 얻어야 합니다.
openai.api_key = "API_KEY"
GPT_MODEL = "gpt-3.5-turbo-0613"
EMBEDDING_MODEL = "text-embedding-ada-002"
2.3 프로젝트 설정
다운로드한 논문이나 데이터를 관리하기 위한 구조화된 디렉토리를 만드는 것은 조직화와 쉬운 접근성을 위해 매우 중요합니다. 필요한 디렉토리를 설정하는 방법을 알려드리겠습니다:
- 디렉토리 구조 생성: 프로젝트의 필요에 맞는 구조를 결정하세요. 다운로드한 논문을 관리하기 위해 ./data/papers 디렉토리가 제안됩니다.
- 구현: Python의 os 라이브러리를 사용하여 이러한 디렉토리의 존재 여부를 확인하고 없는 경우 생성하세요:
import os
directory = './data/papers'
if not os.path.exists(directory):
os.makedirs(directory)
이 코드 조각을 통해 스크립트가 수동 디렉토리 설정 없이 모든 시스템에서 실행될 수 있도록 보장하여 프로젝트의 이식성과 사용자 친화성을 높일 수 있습니다.
3. 핵심 기능
과학 지식 검색을 용이하게 하는 것을 목적으로 설계된 연구 챗봇은 여러 가지 핵심 기능을 통합하고 있습니다.
자연어 쿼리 처리, 학술 콘텐츠 검색 및 요약, 그리고 고급 NLP 기법을 활용하여 사용자 상호작용을 향상하는 것이 중심입니다.
아래에서는 이러한 기능들을 자세히 설명하며, 그 구현을 보여주는 구체적인 코드 조각을 강조하겠습니다.
3.1 임베딩 생성
사용자 쿼리를 효과적으로 이해하고 처리하기 위해 챗봇은 임베딩을 활용합니다. 임베딩은 텍스트의 의미를 포착하는 수치적인 표현으로, 이는 과학 논문과 쿼리 간의 관련성을 결정하는 작업에 중요합니다.
@retry(wait=wait_random_exponential(min=1, max=40), stop=stop_after_attempt(3))
def embedding_request(text):
response = openai.Embedding.create(input=text, model=EMBEDDING_MODEL)
return response['data']['embeddings']
이 함수는 재시도 메커니즘으로 OpenAI API에서 임베딩을 요청하며, 잠재적인 API 오류나 요청 한도에 대응하여 견고성을 보장합니다.
3.2 학술 논문 검색
쿼리를 이해한 후, 챗봇은 arXiv와 같은 외부 데이터베이스와 직접 통신하는 능력을 보여주며 관련 학술 논문을 가져옵니다.
# arXiv에서 기사 가져오는 함수
def get_articles(query, library=paper_dir_filepath, top_k=5):
"""
사용자 쿼리와 관련 있는 상위 'k'개의 학술 논문을 arXiv 데이터베이스에서 검색하고 가져옵니다.
이 함수는 arXiv API를 사용하여 논문을 검색하는데, 검색 기준은 사용자 쿼리이고 결과 수는 'top_k'로 제한됩니다.
찾은 각 논문에는 제목, 요약, URL과 같은 관련 정보를 리스트에 저장합니다.
또한 각 논문의 PDF를 다운로드하고, 제목, 다운로드 경로, 논문 제목의 임베딩을 포함한 참조를 'library'로 지정된 CSV 파일에 저장합니다.
나중에 검색 및 분석을 위해 논문과 임베딩을 기록하는 데 유용합니다.
이 함수는 read_article_and_summarize에서 사용됩니다.
"""
search = arxiv.Search(
query=query, max_results=top_k, sort_by=arxiv.SortCriterion.Relevance
)
result_list = []
for result in search.results():
result_dict = {}
result_dict.update({"title": result.title})
result_dict.update({"summary": result.summary})
# 첫 번째로 제공된 URL 사용
result_dict.update({"article_url": [x.href for x in result.links][0]})
result_dict.update({"pdf_url": [x.href for x in result.links][1]})
result_list.append(result_dict)
# 참조를 라이브러리 파일에 저장
response = embedding_request(text=result.title)
file_reference = [
result.title,
result.download_pdf(data_dir),
response["data"][0]["embedding"],
]
# 파일에 기록
with open(library, "a") as f_object:
writer_object = writer(f_object)
writer_object.writerow(file_reference)
f_object.close()
return result_list
3.3 순위 매기기 및 요약하기
해당 논문을 손에 쥐고 있으면 시스템은 쿼리와 관련성에 따라 그들을 순위를 매기고 내용을 요약하여 사용자에게 간결하고 통찰력 있는 정보를 제공합니다.
# 쿼리 문자열과 관련성을 기준으로 문자열을 순위 매기는 함수
def strings_ranked_by_relatedness(
query: str,
df: pd.DataFrame,
relatedness_fn=lambda x, y: 1 - spatial.distance.cosine(x, y),
top_n: int = 100,
) -> list[str]:
"""
함수는 주어진 쿼리 문자열과 관련성을 기준으로 DataFrame에서 문자열 목록을 순위 매기고 반환합니다.
함수는 먼저 쿼리 문자열에 대한 임베딩을 얻습니다. 그런 다음 DataFrame의 각 문자열과의 관련성을 계산합니다.
여기서 제공된 'relatedness_fn'을 사용하여 쿼리와의 관련성을 계산하며, 기본값은 임베딩 간의 코사인 유사도를 계산합니다.
이러한 문자열을 관련성에 따라 내림차순으로 정렬하여 상위 'n'개의 문자열을 반환합니다.
"""
query_embedding_response = embedding_request(query)
query_embedding = query_embedding_response["data"][0]["embedding"]
strings_and_relatednesses = [
(row["filepath"], relatedness_fn(query_embedding, row["embedding"]))
for i, row in df.iterrows()
]
strings_and_relatednesses.sort(key=lambda x: x[1], reverse=True)
strings, relatednesses = zip(*strings_and_relatednesses)
return strings[:top_n]
3.4 학술 논문 요약
관련 논문을 식별한 후, 챗봇은 과학 문서의 본질을 요약하는 과정을 사용합니다.
# 청크를 요약하고 종합 요약을 반환하는 함수
def summarize_text(query):
"""
사용자 쿼리와 관련된 학술 논문을 요약하는 프로세스를 자동화합니다. 다음을 포함합니다:
1. 데이터 읽기: 논문 및 임베딩 정보가 포함된 'arxiv_library.csv'를 읽습니다.
2. 관련 논문 식별: 쿼리의 임베딩을 CSV 파일의 임베딩과 비교하여 가장 유사한 항목을 찾습니다.
3. 텍스트 추출: 식별된 논문의 PDF를 읽어 내용을 문자열로 변환합니다.
4. 텍스트 청킹: 효율적인 처리를 위해 추출된 텍스트를 관리 가능한 청크로 나눕니다.
5. 청킹 요약: 각 텍스트 청크는 'extract_chunk' 함수를 사용하여 병렬로 요약됩니다.
6. 요약 병합: 개별 요약을 최종 종합 요약으로 결합합니다.
7. 요약 제공: 사용자 쿼리와 관련된 주요 통찰을 중점으로 한 논문의 간략한 개요를 제공합니다.
"""
# 입력된 논문을 재귀적으로 요약하는 방법을 지시하는 메시지
summary_prompt = """학술 논문의 텍스트를 요약하세요. 이유와 함께 중요한 요점을 추출하세요.\n\n내용:"""
# 라이브러리가 비어 있는 경우(아직 검색된 항목이 없는 경우) 한 번 수행하고 결과를 다운로드합니다.
library_df = pd.read_csv(paper_dir_filepath).reset_index()
if len(library_df) == 0:
print("아직 검색된 논문이 없습니다. 처음으로 다운로드합니다.")
get_articles(query)
print("논문 다운로드 완료, 계속 진행합니다.")
library_df = pd.read_csv(paper_dir_filepath).reset_index()
library_df.columns = ["title", "filepath", "embedding"]
library_df["embedding"] = library_df["embedding"].apply(ast.literal_eval)
strings = strings_ranked_by_relatedness(query, library_df, top_n=1)
print("논문에서 텍스트 청킹")
pdf_text = read_pdf(strings[0])
# 토크나이저 초기화
tokenizer = tiktoken.get_encoding("cl100k_base")
results = ""
# 문서를 1500 토큰 청크로 분할
chunks = create_chunks(pdf_text, 1500, tokenizer)
text_chunks = [tokenizer.decode(chunk) for chunk in chunks]
print("각 텍스트 청크를 요약합니다.")
# 요약을 병렬 처리합니다.
with concurrent.futures.ThreadPoolExecutor(
max_workers=len(text_chunks)
) as executor:
futures = [
executor.submit(extract_chunk, chunk, summary_prompt)
for chunk in text_chunks
]
with tqdm(total=len(text_chunks)) as pbar:
for _ in concurrent.futures.as_completed(futures):
pbar.update(1)
for future in futures:
data = future.result()
results += data
# 최종 요약
print("전체 요약으로 요약합니다.")
response = openai.ChatCompletion.create(
model=GPT_MODEL,
messages=[
{
"role": "user",
"content": f"""학술 논문에서 추출한 주요 요점을 바탕으로 종합된 요약을 작성합니다.
요약은 핵심 주장, 결론 및 증거를 강조하고 사용자 쿼리에 답변해야 합니다.
사용자 쿼리: {query}
요약은 Core Argument, Evidence, 그리고 Conclusions의 제목을 따라 목록으로 구성되어야 합니다.
주요 요점:\n{results}\nSummary:\n""",
}
],
temperature=0,
)
return response
3.5 OpenAI 함수의 통합과 사용
연구용 챗봇은 OpenAI 함수를 활용하여 복잡한 쿼리를 처리하고 응답하기 위한 능력을 향상시킵니다.
이러한 함수들은 챗봇과 다양한 외부 데이터 소스 및 도구 간의 원활한 상호작용을 허용하여 사용자에게 자세하고 정확하며 맥락에 맞는 정보를 제공하여 사용자 경험을 크게 향상시킵니다.
OpenAI 함수들은 외부 계산 또는 데이터 검색을 모델의 처리 과정에 직접 통합하여 OpenAI 모델의 기능을 확장하는 데 사용됩니다.
3.5.1 사용자 정의 OpenAI 함수
- get_articles 함수: 사용자의 쿼리와 관련된 학술 논문을 arXiv 데이터베이스에서 검색하여, 챗봇이 외부 소스에서 실시간 데이터에 접근하는 능력을 보여줍니다.
- read_article_and_summarize 함수: 사용자의 쿼리와 관련된 학술 논문을 arXiv 데이터베이스에서 검색하여, 챗봇이 외부 소스에서 실시간 데이터에 접근하는 능력을 보여줍니다.
구현:
# Function to initiate our get_articles and read_article_and_summarize functions
arxiv_functions = [
{
"name": "get_articles",
"description": """Use this function to get academic papers from arXiv to answer user questions.""",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
User query in JSON. Responses should be summarized and should include the article URL reference
""",
}
},
"required": ["query"],
},
},
{
"name": "read_article_and_summarize",
"description": """Use this function to read whole papers and provide a summary for users.
You should NEVER call this function before get_articles has been called in the conversation.""",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
Description of the article in plain text based on the user's query
""",
}
},
"required": ["query"],
},
}
]
이러한 기능을 챗봇의 작업 흐름에 통합하면 OpenAI의 API의 고급 사용 사례를 보여줍니다. 여기서는 대화 컨텍스트에 따라 특정 작업(예: 학술 조사)에 맞게 맞춤형 함수가 실행됩니다.
3.6 완전한 코드
필요한 함수 및 대화형 챗봇 상호작용이 포함된 전체 코드를 참조하세요.
이 프로젝트 유형뿐만 아니라 AI, 데이터 과학 및 기술 분야의 다양한 혁신적인 데이터 기반 이니셔티브에 대해 www.entreprenerdly.com의 다양한 자원을 살펴보기를 권장합니다.

4. 연구 챗봇과 상호작용하기
이 섹션에서는 사용자-시스템 상호작용 흐름을 설명하는 예제들과 함께 연구 챗봇의 구현과 기능에 대해 깊이 파고들어 논의합니다.
4.1 구현 개요
챗봇은 OpenAI API를 기반으로 구축되었으며, GPT-3 또는 GPT-4와 같은 모델을 활용하여 복잡한 쿼리를 이해하고 사람과 유사한 답변을 생성할 수 있습니다.
구현은 사용자가 쿼리를 입력할 수 있는 인터페이스(명령줄 인터페이스 또는 웹 기반 UI)를 설정하는 것을 포함합니다. 그런 다음 시스템은 이러한 쿼리를 처리하고 OpenAI API와 상호 작용하여 사용자에게 다시 응답을 제시합니다.
4.2 기능
연구 챗봇의 핵심 기능은 다음과 같습니다:
- 질의 이해: 챗봇은 먼저 사용자의 질문을 해석하여 OpenAI 모델의 이해 능력을 활용하여 질문 뒤에 숨은 맥락과 의도를 파악합니다.
- 정보 검색: 챗봇은 질의에 따라 교육된 지식베이스를 활용하여 직접 답변을 생성하거나 관련 과학 논문과 문서를 가져와 응답을 작성할 수 있습니다.
- 응답 생성: 챗봇은 검색하거나 생성한 정보를 일관되고 간결한 답변으로 종합하여 사용자에게 제시합니다.
4.3 사용자-시스템 상호작용 흐름
- 사용자 질의 예시: 사용자가 “양자 컴퓨팅의 최신 발전은 무엇인가요?”라고 묻습니다. 질의 처리:
response = openai.Completion.create(
engine="davinci",
prompt="양자 컴퓨팅의 최신 발전 사항은 무엇입니까?",
max_tokens=100
)
- 답변 생성: 시스템은 답변을 구성하여 양자 컴퓨팅의 최근의 폭발적인 발전을 요약할 수 있습니다.
- 답변 제시: 챗봇은 사용자의 이해를 돕기 위해 합성된 정보를 출력합니다.
4.3.1 관련 논문 검색
이 단계는 사용자가 챗봇에게 특정 주제에 대한 논문을 식별하고 검색하는 것을 포함합니다.
# 시스템 메시지로 시작합니다
paper_system_message = """안녕하세요, 저는 arXivGPT입니다. 사용자의 질문에 답변하기 위해 학술 논문을 가져오는 유용한 도우미입니다.
논문을 명확하게 요약하여 고객이 질문에 대한 답변을 얻기 위해 어떤 논문을 읽어야 하는지 결정할 수 있도록 도와드립니다.
사용자가 논문의 이름을 이해하고 액세스하려면 항상 article_url과 title을 제공합니다.
시작하세요!"""
paper_conversation = Conversation()
paper_conversation.add_message("system", paper_system_message)
# 사용자 메시지 추가
paper_conversation.add_message("user", "시장 효율성에 대한 최신 정보는 무엇인가요?") # PPO 강화 학습은 어떻게 작동하나요?
chat_response = chat_completion_with_function_execution(
paper_conversation.conversation_history, functions=arxiv_functions
)
assistant_message = chat_response["choices"][0]["message"]["content"]
paper_conversation.add_message("assistant", assistant_message)
display(Markdown(assistant_message))
4.3.2 논문 요약하기
적절한 논문을 가져온 후, 챗봇은 사용자의 요청을 더 처리하여 특정 논문의 내용을 요약하여 제공함으로써 간결하고 통찰에 풍부한 요약을 제공하며 상호작용을 개선합니다.
# 두 번째 도구를 사용하도록 시스템을 유도하기 위해 다른 사용자 메시지 추가
paper_conversation.add_message(
"user",
"시장 효율적 교차 시장 추천을 위한 시장-인식 모델 논문을 읽고 요약을 제공해줄 수 있나요?",
)
updated_response = chat_completion_with_function_execution(
paper_conversation.conversation_history, functions=arxiv_functions
)
display(Markdown(updated_response["choices"][0]["message"]["content"]))
5. 도전과 솔루션
5.1 다양한 데이터 소스 통합
- 도전: 과학적 지식은 학술 저널부터 프리프린트 서버 및 기관 저장소까지 다양한 플랫폼과 형식으로 분산되어 있습니다.
- 솔루션: 여러 소스에서 데이터를 가져와 정규화하기 위해 다양한 API 및 웹 스크래핑 기술과 연결할 수 있는 모듈식 데이터 수집 프레임워크를 개발해야 합니다.
5.2 사용자-시스템 상호 작용 흐름
- 도전: 특히 다단계 정보 검색 및 처리가 필요한 복잡한 쿼리에 대해 대화 플로우를 자연스럽고 매력적으로 유지하는 것이 도전입니다.
- 해결책: 사용자 경험을 향상시키기 위해, 챗봇이 사용자와 상호 작용하는 동안 정보 검색을 백그라운드에서 처리하면서 상호 작용적인 세션을 유지할 수 있는 멀티 스레드 요청 처리 시스템을 구현할 수 있습니다.
5.3 연속적인 학습과 개선 보장
- 도전: 챗봇이 사용자 상호작용에서 지속적으로 학습하고 개선하여 시간이 지남에 따라 정확도와 효과성을 향상시키는 것입니다.
- 해결책: 사용자가 챗봇의 응답의 relevance 및 정확도를 평가할 수 있는 피드백 루프 메커니즘을 구현합니다. 이 피드백은 모델을 세밀하게 조정하고 응답 품질을 향상시키는 데 사용됩니다.
5.4 실시간 데이터 동기화
- 도전 과제: 챗봇의 데이터베이스를 실시간으로 최신 과학 논문과 동기화하는 것. 새로운 연구가 계속 발표되고 있기 때문에, 챗봇이 가장 최신 정보를 제공하는 것은 상당한 도전입니다.
- 해결책: 대형 과학 논문 데이터베이스의 웹훅과 RSS 피드를 사용하여 실시간 데이터 동기화 매커니즘을 구현할 수 있습니다. 이를 통해 새로운 논문이 제공되는 즉시 시스템이 자동으로 레포지토리를 업데이트할 수 있습니다.
6. 실용적 응용
6.1 학술 연구
다양한 학문 분야의 연구자들은 이 시스템을 활용하여 문헌 검토 과정을 간소화하고 효율적으로 관련 연구를 찾을 수 있습니다. 연구 주제와 관련된 구체적인 쿼리를 입력함으로써, 시스템은 과학 논문을 신속히 검색하여 주요 결과, 방법론 및 결과를 식별하고 요약할 수 있습니다.
6.2 산업 연구 및 개발
제약, 공학 및 기술 연구개발 부서의 빠른 환경에서는 최신 과학적 발견에 대한 최신 정보를 충분히 파악하는 것이 혁신과 경쟁 우위를 유지하는 데 중요합니다. 시스템은 이러한 산업에 최신 연구, 실험 결과 및 기술 발전을 신속하게 접근할 수 있는 강력한 도구를 제공합니다.
6.3 교육
교육자와 학생 모두 시스템을 활용하여 학습 경험을 풍부하게 하고 학업 연구를 지원할 수 있습니다. 교사들은 강의를 준비하기 위한 최신 정보를 찾아 수업 내용을 현재와 관련성 있게 전달할 수 있습니다. 마찬가지로 학생들은 에세이, 프로젝트 또는 논문을 위한 소스, 참고 자료 및 사례 연구를 찾기 위해 시스템을 활용할 수 있습니다.
6.4 데이터 과학 및 AI
데이터 과학가와 AI 연구원들에게는 시스템이 데이터 세트를 확보하고 복잡한 알고리즘을 이해하며 기존 연구에 대한 벤치마킹을 제공하는 중요한 자원으로 작용합니다. 사용자들은 시스템에서 특정 프로젝트에 가장 최근이고 관련성 있는 데이터 세트를 쿼리할 수 있으며, 데이터 세트의 크기, 다양성 및 응용에 대한 자세한 정보를 얻을 수 있습니다.
결론과 향후 작업
이 연구 및 과학적 지식 검색 시스템의 개발과 구현은 인공지능의 변혁적 잠재력을 강조하며, 과학적 조사의 접근성과 효율성을 향상시키는 데 중요한 역할을 합니다.
미래 작업은 AI 및 기계 학습의 최신 발전을 활용하여 식별된 과제에 대응하며, 시스템이 최첨단 기술 선두에 머무르고 다양한 사용자들의 요구를 계속 충족할 수 있도록 보장하는 데 초점을 맞추게 될 것입니다.
읽어 주셔서 감사합니다. 만약 이 글이 유익했다면 앞으로의 콘텐츠 지원을 위해 박수를 부탁드립니다. 👏
Entreprenerdly.com에는 행동 가능한 지식을 제공하기 위해 설계된 전체 자습서, 코드 및 전략이 제공됩니다.
