
온디맨드 강좌| 추천
몇몇 독자들이 데이터 엔지니어가 되는 데 도움이 되는 온디맨드 강좌를 요청했습니다. 이 중에서 제가 추천하는 3가지 좋은 자료들은 다음과 같습니다:
- 데이터 엔지니어링 나노디그리 (UDACITY)
- 아파치 카프카 및 아파치 스파크를 이용한 데이터 스트리밍 나노디그리 (UDACITY)
- PySpark를 이용한 스파크 및 파이썬을 활용한 빅데이터 (UDEMY)
아직 Medium 회원이 아니신가요? 매달 $5로 Medium의 모든 콘텐츠에 액세스할 수 있는 제 추천 링크로 가입해보세요!
소개
Apache Iceberg은 데이터 레이크 내에서 매우 큰 데이터 세트를 효율적으로 저장하는 데 산업의 기준이 되어가고 있습니다.
이 오픈 테이블 형식은 Parquet 또는 ORC 파일로 저장된 데이터 세트에 대해 작동할 수 있도록 해주며, 관계형 데이터베이스의 테이블과 정확히 같은 방식으로 작동합니다.
아이스버그 데이터 웨어하우스를 올바르게 생성하는 것은 해당 형식의 모든 데이터를 저장하고 조회할 수 있는 기본적인 첫 번째 단계입니다. 그러나 아이스버그 문서는 종종 기술적인 내용이 부족하거나 관련 사용 사례를 다루지 않는 경우가 있습니다.
현재 Spark가 아이스버그 테이블과 작업하기 위해 가장 잘 지원되는 컴퓨팅 엔진 중 하나이므로 이번 튜토리얼에서는 다음 질문에 대답할 것입니다:
대규모 데이터 보관 솔루션을 개발하면서 얻은 실무 경험을 바탕으로, 본 튜토리얼은 데이터 엔지니어들에게 아이스버그 API를 PySpark에서 활용하기 위한 기본 단계를 보여주며, 연구하는 데 소요되는 시간(및 시행착오)을 감소시키는 등 지식 간극을 메우고자 합니다.
방법론
아이스버그 아키텍처는 세 개의 주요 레이어로 구성되어 있습니다:
- 아이스버그 카탈로그 레이어: 각 테이블의 현재 메타데이터 파일의 정확한 위치를 저장합니다. 이 포인터는 Spark, Trino, Flink 등의 쿼리 엔진이 데이터를 읽거나 쓸 위치를 정확히 지정합니다.
- 메타데이터 레이어: 아이스버그 테이블과 관련된 메타데이터를 저장합니다. 테이블 스키마, 파티셔닝 스키마 및 특정 시점의 테이블 스냅샷과 같은 정보를 포함합니다.
- 데이터 레이어: 행 데이터를 컬럼 형식으로 저장하며, 파티션화된 디렉토리에 구성합니다.
환경 및 특정 요구에 따라, 이러한 레이어는 동일한 저장소 내에 있거나 다른 기술을 활용할 수 있습니다.
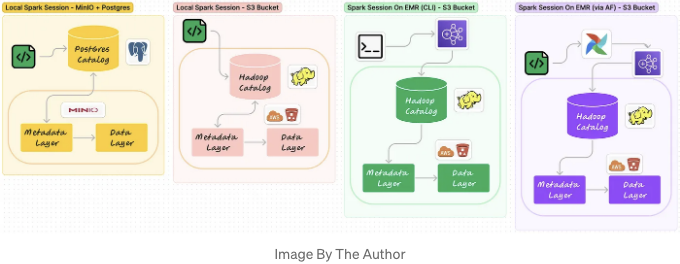
본 튜토리얼에서는 데이터 엔지니어가 로컬 환경에서 개발하는 동안 아이스버그 데이터 웨어하우스를 설정하는 세 가지 간단한 방법을 소개할 것입니다:
- 방법 #1: 로컬에서 실행되는 Spark 세션으로, 메타데이터와 데이터 레이어는 MinIO 버킷에, 카탈로그 레이어는 PostGres DB에 저장되어 있습니다.
- 방법 #2: 로컬에서 실행되는 Spark 세션으로, 모든 세 가지 레이어가 스테이징 AWS S3 버킷에 저장되어 있습니다(하둡 카탈로그 사용).
- 방법 #3: EMR 클러스터에서 실행되는 Spark 세션으로, 수동 CLI 배포를 통해, 모든 세 가지 레이어가 스테이징 AWS S3 버킷에 저장되어 있습니다(하둡 카탈로그 사용).
또한 상용 환경에서 동일한 결과를 얻는 데 일반적으로 사용되는 추가적인 방법을 설명할 것입니다:
- 방법 #4: EMR 클러스터에서 실행되는 Spark 세션으로, 자동화된 Apache Airflow 배포를 통해, 모든 세 가지 레이어가 프로덕션 AWS S3 버킷에 저장되어 있습니다(하둡 카탈로그 사용).
아래에 위에서 설명한 방법들의 시각적 표현을 찾을 수 있습니다:
환경 설정하기
이 자습서에서 사용하는 자료는 GitHub에서 이용할 수 있습니다.
따라서 따라하기 위해 단순히 원격 프로젝트 저장소를 로컬로 클론하고 spark_icb_warehouse 디렉터리로 이동한 후 docker compose up -d를 실행하면 됩니다.
이 명령은 다음 서비스를 실행합니다:
spark_icb_warehouse % docker compose up -d
[+] Running 6/6
⠿ Network spark_icb_warehouse_shared-network 생성됨 0.0초
⠿ Container postgres-db 시작함 1.0초
⠿ Container minio 시작함 1.0초
⠿ Container mc 시작함 1.8초
⠿ Container airflow_webserver 시작함 1.9초
⠿ Container airflow_scheduler 시작함
- Postgres DB = 메소드 #1의 일환으로 사용되며 Iceberg 카탈로그를 저장하고, 메소드 #4의 일환으로 Airflow 메타데이터를 저장하기 위해 사용됩니다. 동일한 Postgres 서비스가 두 개의 데이터베이스를 호스트하는 효율적인 전략입니다. 즉, docker-compose.yml이 실행되면 생성된 airflow_metadata_db와 postgres-init 폴더의 init_dbs.sh 스크립트를 실행하여 생성된 iceberg_warehouse_pg 데이터베이스가 사용됩니다.
- MinIO = 메소드 #1의 일환으로 Iceberg 데이터와 메타데이터 레이어를 저장하기 위해 사용됩니다. Docker를 통해 실행될 때 MinIO는 크라우드 스토리지 (예: S3 Bucket)의 기능을 무료로 제공하고 주요 설치나 유지 관리가 필요하지 않습니다. 따라서 PySpark 어플리케이션을 로컬로 테스트하는 동안 훌륭한 선택지입니다.
- Apache Airflow (WebServer + Scheduler) = 메소드 #4의 일환으로 PySpark 어플리케이션을 EMR에 자동으로 배포하고, 프로덕션 환경에서의 일반적인 전략을 시뮬레이션하기 위해 사용됩니다. 이 튜토리얼에서는 Airflow 버전 2.5.2를 사용하고 UI를 8085 포트에서 사용할 수 있도록 설정했습니다.
이 세 가지 서비스 외에도 동일한 지역(예: eu-central-1) 내에서 생성된 S3 Bucket과 기본 EMR 클러스터를 기다리는 상태로 설정한 AWS 계정이 있다고 가정합니다.
하지만 PySpark은 어떻게 될까요? Iceberg 퀵스타트 가이드는 인기 있는 tabulario/spark-iceberg 이미지를 가져와 Docker에서 독립적으로 Spark를 실행하는 것을 권장합니다 – 온라인 가이드의 대부분과 마찬가지로 – 그러나 이 튜토리얼의 목표 중 하나는 실제로 이것이 필요하지 않다는 것을 보여주는 것입니다:
- 메소드 #1 및 #2의 경우, 우리는 단순히 로컬로 pyspark (버전 3.3.1)을 설치할 수 있으며, 가상 환경의 일부로 코드를 Jupyter 노트북을 통해 컴파일할 수 있습니다.
- 메소드 #3 및 #4의 경우, EMR 클러스터를 설정하는 동안 pyspark=3.3.1이 사전 설치되어 있으며 추가 단계가 필요하지 않습니다.
Iceberg Warehouse 생성하기
이 섹션의 코드 조각은 GitHub 레포지토리의 Spark_Iceberg_WH Jupyter 노트북의 일부로 제공됩니다.
아이스버그 프레임워크가 Pyspark 위에서 작동하도록 하려면 스파크 세션을 생성할 때 구성값의 일부로 전달될 다음 패키지를 명시해야 합니다.
# 종속성 정의 (Maven에서 다운로드할 패키지)
# 1. Spark가 Iceberg 웨어하우스와 상호 작용하기 위해 필요
DEPENDENCIES = "org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.3.1"
DEPENDENCIES += ",software.amazon.awssdk:bundle:2.20.18"
DEPENDENCIES += ",com.amazonaws:aws-java-sdk-bundle:1.11.901"
DEPENDENCIES += ",org.apache.hadoop:hadoop-aws:3.3.4"
# 2. 카탈로그가 포스트그레스 DB에 저장된 경우에만 필요
DEPENDENCIES += ",org.postgresql:postgresql:42.6.0"
다음 사항을 유의해야 합니다:
- 우리는 iceberg-spark 패키지 버전 1.3.1을 사용할 것입니다. 이 버전을 사용할 때 구성 오류를 피하기 위해 꼭 필요한 패키지는 awssdk-bundle, aws-sdk-bundle, hadoop-aws 세 개 뿐입니다.
- Python에서 문자열을 연결하는 더 좋은 방법이 있지만, 위의 코드는 더 필요하지 않을 때 패키지에 주석을 달기 쉽게 만들어줍니다 (예를 들어 postgresql은 메소드 #1에만 필요합니다).
방법 #1 = 로컬 스파크 세션 + MinIO에 메타데이터/데이터 레이어 + 포스트그레스 DB에 카탈로그 레이어
파이스파크를 사용하여 아이스버그 데이터 웨어하우스를 만드는 첫 번째 방법은, 로컬 SparkSession을 실행하고 JDBC 카탈로그(포스트그레스 DB)를 사용하도록 구성하고 메타데이터 및 데이터 레이어를 MinIO 버킷에 저장하는 것입니다.
이를 수행하는 코드는 아래에 제시되어 있습니다:
from pyspark import SparkConf
from pyspark.sql import SparkSession
def spark_local_to_minio(icb_catalog_name,
iceberg_warehouse,
storage_type,
pg_user,
pg_password,
minio_bucket,
minio_access_key,
minio_secret_key,
minio_end_point):
conf = (
SparkConf()
.setAppName('spark_local_to_minio')
#Dependencies
.set('spark.jars.packages', DEPENDENCIES)
#SQL Extensions
.set('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
#Catalog Configuration
.set(f'spark.sql.catalog.{icb_catalog_name}', 'org.apache.iceberg.spark.SparkCatalog')
.set(f'spark.sql.catalog.{icb_catalog_name}.catalog-impl', 'org.apache.iceberg.jdbc.JdbcCatalog')
.set(f'spark.sql.catalog.{icb_catalog_name}.uri', f'jdbc:postgresql://localhost:5439/{pg_db}')
.set(f'spark.sql.catalog.{icb_catalog_name}.jdbc.user', pg_user)
.set(f'spark.sql.catalog.{icb_catalog_name}.jdbc.password', pg_password)
.set(f'spark.sql.catalog.{icb_catalog_name}.jdbc.verifyServerCertificate', 'true')
.set(f'spark.sql.catalog.{icb_catalog_name}.jdbc.useSSL', 'true')
.set(f'spark.sql.defaultCatalog', icb_catalog_name)
.set(f'spark.sql.catalog.{icb_catalog_name}.warehouse', f's3a://{minio_bucket}/{iceberg_warehouse}/{storage_type}/')
# MinIO Configuration
.set('spark.hadoop.fs.s3a.access.key', minio_access_key)
.set('spark.hadoop.fs.s3a.secret.key', minio_secret_key)
.set("spark.hadoop.fs.s3a.endpoint", minio_end_point)
)
## Start Spark Session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
print("Spark Session Running")
return spark
############################################
icb_catalog_name = 'pg_catalog'
iceberg_warehouse = 'iceberg-warehouse-pg'
storage_type = 'data-archives'
pg_db = 'iceberg_warehouse_pg'
pg_user = 'postgres'
pg_password = 'postgres'
minio_bucket = 'iceberg-bucket'
minio_access_key = 'admin'
minio_secret_key = 'password'
minio_end_point = 'http://127.0.0.1:9000'
spark = spark_local_to_minio(icb_catalog_name,
iceberg_warehouse,
storage_type,
pg_user,
pg_password,
minio_bucket,
minio_access_key,
minio_secret_key,
minio_end_point)
spark_local_to_minio() 함수를 실행하면 SparkSession이 생성되어 iceberg_warehouse_pg(로컬에서 포트 5439로 사용 가능)와 MinIO의 iceberg-bucket을 가리키게 됩니다(docker-compose.yml을 실행하면서 생성됨, 로컬에서 127.0.0.1:9000으로 사용 가능).
그러나 iceberg 웨어하우스는 SQL 명령을 실행하지 않으면 MinIO에 실질적으로 표시되지 않습니다(테스트 테이블처럼 객체를 생성하는 명령). 예를 들어:
# iceberg-warehouse-pg 웨어하우스에 테스트 테이블(Within MinIO) 생성
# *참고*: 이 작업을 실행하기 전에 UI에서 ICB WH를 볼 수 없습니다.
spark.sql(f"""CREATE OR REPLACE TABLE {icb_catalog_name}.TEST_SCHEMA.TEST_TABLE_MINIO_PG (
FIELD_1 BIGINT,
FIELD_2 varchar(50),
FIELD_3 DATE,
FIELD_4 DOUBLE,
FIELD_5 TIMESTAMP
)
USING iceberg
""")
# PG 카탈로그에 생성된 테이블 표시(TEST_SCHEMA)
spark.sql(f'SHOW TABLES IN {icb_catalog_name}.TEST_SCHEMA').show(truncate=False)pyt
위와 같은 결과가 나타납니다:
| namespace | tableName | isTemporary |
|---|---|---|
| TEST_SCHEMA | TEST_TABLE_MINIO_PG | false |
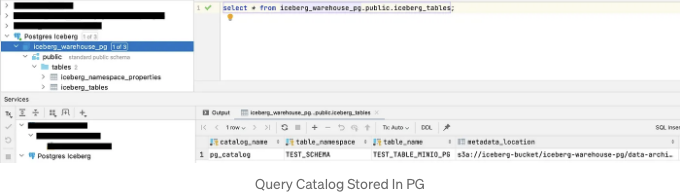
위의 표는 TEST_SCHEMA.TEST_TABLE_MINIO_PG가 카탈로그에 등록되었음을 의미합니다. 이 카탈로그는 iceberg_warehouse_pg 데이터베이스 위에 구축되었으며 MinIO 버킷에 메타데이터 파일이 저장되었습니다.
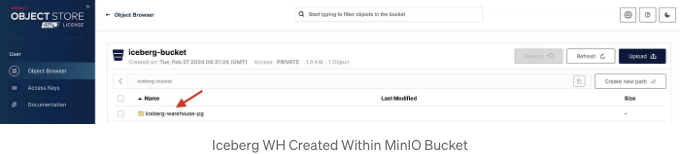
위에 설명한 것이 실제로 발생했는지 확인하기 위해 두 가지 확인을 수행할 수 있습니다:
- MinIO UI에 액세스하여(사용자: admin, 비밀번호: password) 메타데이터 파일로 이동합니다:
[Markdown 형식으로 변경한 텍스트]

- 선호하는 DBMS를 통해 Postgres DB에 연결하고 iceberg_tables를 쿼리하세요:
Method #2 - 로컬 Spark 세션 + S3 버킷의 모든 레이어
일명 #Method 1과 마찬가지로, 데이터 엔지니어들은 로컬 개발 및 테스트를 지원하도록 정확히 설정된 스테이징 S3 버킷(프로덕션 버킷을 반영)에 액세스할 수 있습니다.
만약 그렇다면, SparkSession은 로컬에서 실행되지만, 이번에는 모든 레이어가 S3 버킷 내에 저장될 수 있습니다. 특히, S3 저장소는 하둡 카탈로그(반면에 MinIO에는 누락된)를 내장하고 있어, Iceberg 데이터 웨어하우스를 생성하면서 설정할 수 있는 아마도 가장 쉬운 [외부] 카탈로그입니다.
위에서 설명한 내용을 달성하는 코드는 다음과 같습니다:
import os
from pyspark import SparkConf
from pyspark.sql import SparkSession
def spark_local_to_s3(icb_catalog_name,
iceberg_warehouse,
storage_type,
s3_bucket,
s3_access_key,
s3_secret_key):
os.environ.update({'AWS_ACCESS_KEY_ID': s3_access_key,
'AWS_SECRET_ACCESS_KEY': s3_secret_key
#'AWS_SESSION_TOKEN': s3_session_token
})
conf = (
SparkConf()
.setAppName('spark_local_to_s3')
#packages
.set('spark.jars.packages', DEPENDENCIES)
#SQL Extensions
.set('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
#Configuring Catalog
.set(f'spark.sql.catalog.{icb_catalog_name}', 'org.apache.iceberg.spark.SparkCatalog')
.set(f'spark.sql.catalog.{icb_catalog_name}.type', 'hadoop')
.set(f'spark.sql.catalog.{icb_catalog_name}.warehouse', f's3a://{s3_bucket}/{iceberg_warehouse}/{storage_type}/')
.set(f'spark.sql.catalog.{icb_catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO')
)
# Start Spark Session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
print("Spark 세션 실행 중")
return spark
icb_catalog_name = 'hadoop_catalog'
iceberg_warehouse = 'iceberg-warehouse-dev-hdp'
storage_type = 'data-archives'
s3_bucket = 'iceberg-bucket-9004'
s3_access_key='XXXXX'
s3_secret_key='XXXXX'
spark = spark_local_to_s3(icb_catalog_name,
iceberg_warehouse,
storage_type,
s3_bucket,
s3_access_key,
s3_secret_key)
한눈에 보기에 이 메서드는 #method 1보다 설정이 상당히 적게 필요함을 알 수 있습니다:
- JDBC Catalog 구현이
spark.sql.catalog.'icb_catalog_name'.type,hadoop로 대체되었습니다. - MinIO 구성이
spark.sql.catalog.'icb_catalog_name'.io-impl,org.apache.iceberg.aws.s3.S3FileIO로 대체되었습니다. - 또한 S3 버킷의 access_key와 secret_key (가끔은 session_token이 필요할 수도 있음)이 환경 변수로 사용 가능하도록 만들었습니다. 환경 변수 사용으로 연결 오류가 발생하는 경우, 대안적으로 비밀을 default 프로필 아래 ~/.aws/credentials에 저장하는 방법이 있습니다.
이번에는 spark_local_to_s3() 함수를 실행할 때, SparkSession을 생성하여 iceberg-bucket-9004를 가리키고 백그라운드에서 hadoop 카탈로그가 구성되었습니다.
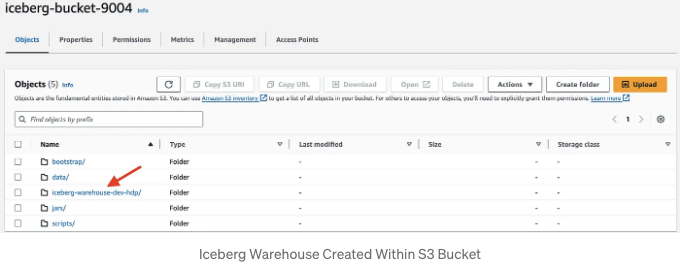
아마도 iceberg-warehouse-dev-hdp가 S3 계정 UI에 표시되지 않을 것입니다. 올바른 iceberg object를 생성하는 pyspark.sql 명령을 실행하지 않는 이상:
# 메소드 1과 같이, 이 명령을 실행하지 않으면 ICB WH가 S3 Bucket 내부에 표시되지 않음
spark.sql(f"""CREATE OR REPLACE TABLE {icb_catalog_name}.TEST_SCHEMA.TEST_TABLE_S3_HDP (
FIELD_1 BIGINT,
FIELD_2 varchar(50),
FIELD_3 DATE,
FIELD_4 DOUBLE,
FIELD_5 TIMESTAMP
)
USING iceberg
""")
실제로, 위의 명령은 데이터 웨어하우스와 TEST_TABLE_S3_HDP 테이블을 위한 전용 폴더를 생성합니다:
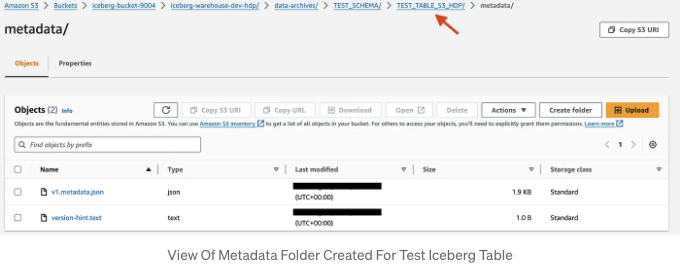
Method #3 - Spark Session On EMR (via CLI) + All Layers On S3 Bucket
If AWS EMR is your go-to production framework for deploying PySpark applications, you probably have a staging cluster for development paired with a staging S3 bucket (similar to #method 2).
In this scenario, data engineers can submit PySpark applications to the EMR cluster through AWS CLI.
EMR 단계를 추가하는 명령어를 작성할 때는 클러스터 드라이버에서 SparkSession이 자동으로 실행될 것이므로 올바른 종속성, 구성 및 PySpark 스크립트를 제출하는 데 주의해야 합니다.
이 방법을 사용하면 종속성이 Maven에서 자동으로 다운로드되는 대신 별도의 jars/ 폴더 내의 jar 파일로 S3에 사용 가능하게 만들어졌으며 PySpark 애플리케이션 자체도 scripts/ 폴더에 저장되었습니다.
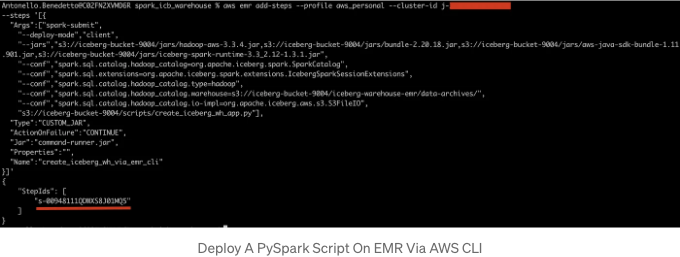
아래는 EMR에 create_iceberg_wh_app.py 애플리케이션을 제출하는 명령어의 예시입니다. 이 명령어는 실제로 해둡 카탈로그에 iceberg 웨어하우스를 설정하는 필요한 구성을 가지고 있습니다:
# CLI를 통해 AWS EMR 클러스터에 단계 추가
# 실제 클러스터 ID로 j-xxxxxxxxxxx를 대체하세요
aws emr add-steps --profile aws_personal --cluster-id j-xxxxxxxxxxx \
--steps '[{
"Args":["spark-submit",
"--deploy-mode","client",
"--jars","s3://iceberg-bucket-9004/jars/hadoop-aws-3.3.4.jar,s3://iceberg-bucket-9004/jars/bundle-2.20.18.jar,s3://iceberg-bucket-9004/jars/aws-java-sdk-bundle-1.11.901.jar,s3://iceberg-bucket-9004/jars/iceberg-spark-runtime-3.3_2.12-1.3.1.jar",
"--conf","spark.sql.catalog.hadoop_catalog=org.apache.iceberg.spark.SparkCatalog",
"--conf","spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"--conf","spark.sql.catalog.hadoop_catalog.type=hadoop",
"--conf","spark.sql.catalog.hadoop_catalog.warehouse=s3://iceberg-bucket-9004/iceberg-warehouse-emr/data-archives/",
"--conf","spark.sql.catalog.hadoop_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO",
"s3://iceberg-bucket-9004/scripts/create_iceberg_wh_app.py"],
"Type":"CUSTOM_JAR",
"ActionOnFailure":"CONTINUE",
"Jar":"command-runner.jar",
"Properties":"",
"Name":"create_iceberg_wh_via_emr_cli"
}]'
만약 명령이 성공적으로 실행되면, stepID가 반환됩니다:
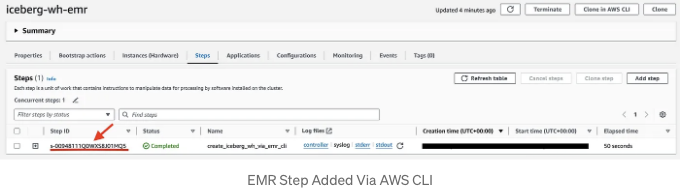
EMR 클러스터 UI에서도 동일한 stepID가 나타나며, 이는 PySpark 스크립트가 실행 준비가 된 것을 나타냅니다:
작업이 완료되면 클러스터에서 로그가 생성됩니다. 이 경우, 로그에서 TEST_TABLE_EMR_S3_HDP가 카탈로그에 실제로 생성되었음을 확인했습니다:
INFO:root:Creating SPARK SESSION...
INFO:root:SPARK SESSION created!
+-----------+---------------------+-----------+
|namespace |tableName |isTemporary|
+-----------+---------------------+-----------+
|TEST_SCHEMA|TEST_TABLE_EMR_S3_HDP|false |
+-----------+---------------------+-----------+
INFO:root:Main APPLICATION was executed!
결과적으로, iceberg-bucket-9004 S3 버킷 내에서 add-steps 명령어의 일부로 지정된 이름인 iceberg-warehouse-emr가 생성되었습니다:
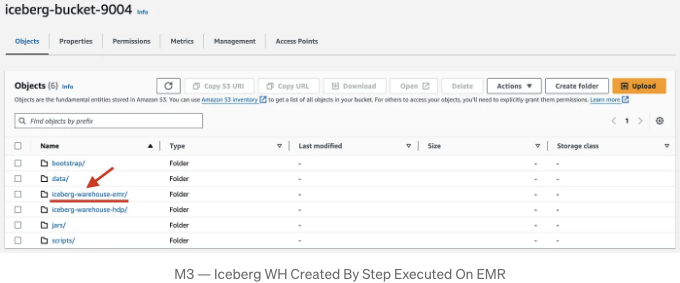
Method #4: Spark Session On EMR (Via Airflow) + All Layers On S3 Bucket
일반적으로, 실제 환경에서는 Apache Airflow를 사용하여 작업을 조율하며 PySpark 응용 프로그램을 배포하기 위해 EMR에 단계를 자동으로 추가합니다.
AWS EMR에서 Airflow를 사용하여 PySpark 파이프라인을 자동화하는 방법에 대해 자세히 알고 싶다면 이 문서를 참조하십시오.
요약하면, 이 방법은 다음 네 가지 작업을 수행하는 전용 DAG(spark_create_iceberg_wh_dag.py)를 설정하는 것을 포함합니다:
- create_iceberg_wh_app.py 파일을 iceberg-bucket-9004의 scripts/ 폴더에 업로드합니다 (EMR이 배포할 수 있도록 함).
- dag_params.json 파일에서 필요한 Spark 작업 구성을 구문 분석하고 EMR에 제출할 명령을 자동으로 빌드하는 데 사용합니다:
{
"local_conf":{
"local_sub_folder":"/assets/",
"files_to_upload":["create_iceberg_wh_app.py"]
},
"s3_conf":{
"bucket_name":"iceberg-bucket-9004",
"s3_scripts_path":"scripts/"
},
"spark_submit_cmd":{
"cmd":"[\"spark-submit\", \"--deploy-mode\", \"client\"]",
"pyspark_exec":"scripts/create_iceberg_wh_app.py"
},
"spark_conf":{
"spark.sql.catalog.hadoop_catalog": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"spark.sql.catalog.hadoop_catalog.type": "hadoop",
"spark.sql.catalog.hadoop_catalog.warehouse": "s3a://iceberg-bucket-9004/iceberg-warehouse-prod-hdp/data-archives/",
"spark.sql.catalog.hadoop_catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO"
},
"spark_jars_conf":{
"bucket_prefix":"s3://iceberg-bucket-9004/",
"bucket_subfolder":"jars/"
},
"spark_jars_conf_value":[
"hadoop-aws-3.3.4.jar",
"bundle-2.20.18.jar",
"aws-java-sdk-bundle-1.11.901.jar",
"iceberg-spark-runtime-3.3_2.12-1.3.1.jar"
]
}
- EmrAddStepsOperator를 통해 PySpark 스크립트를 배포하고 실행할 단계를 EMR에 추가하도록 지시합니다.
- EMRStepSensor를 통해 EMR 단계 상태를 지속적으로 모니터링합니다.
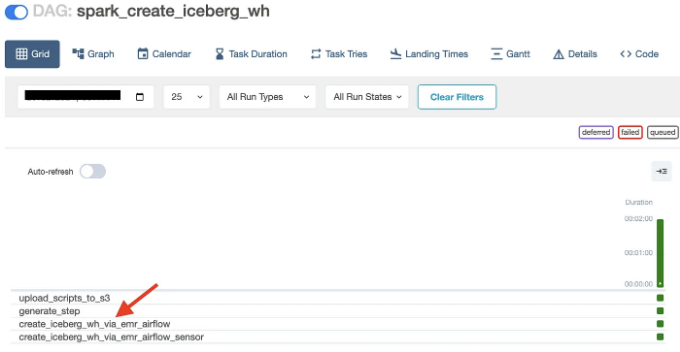
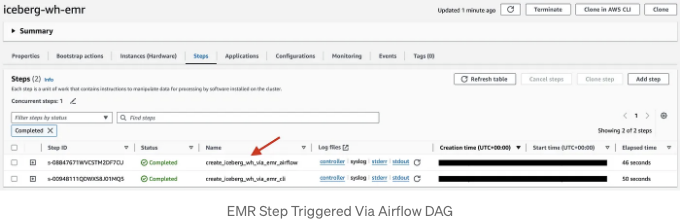
#method3에 대해 이야기해보겠습니다. DAG가 트리거된 직후에 PySpark 스크립트를 실행하는 단계가 EMR UI의 Steps 섹션 아래에 나타납니다.
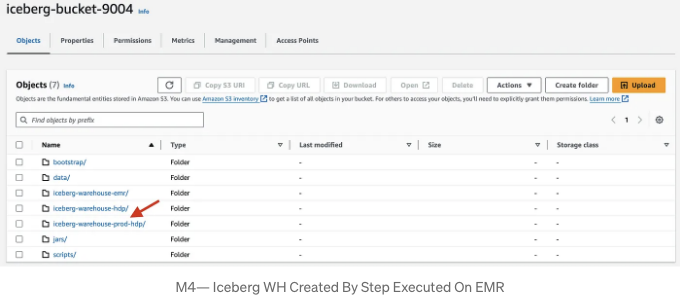
해당 단계가 완료 상태가 되면 S3 버킷 내에 새 Iceberg 웨어하우스인 "iceberg-warehouse-prod-hdp"가 생성된 것을 확인할 수 있습니다.
결론
이 튜토리얼에서는 PySpark를 사용하여 Apache Iceberg 데이터 웨어하우스를 로컬 또는 프로덕션 환경에서 생성하는 네 가지 방법을 소개했습니다.
각 방법은 특정 사용 사례를 다루며 다른 기술 (Docker, MinIo, S3, EMR, Airflow) 및 다른 전략 (로컬에서 실행되는 SparkSession 대 EMR 클러스터에서 실행되는 SparkSession, 데이터베이스에 저장된 카탈로그 레이어 대 S3 버킷 등)을 사용합니다.
현재 문서에 다양한 조합을 제시함으로써 데이터 엔지니어가 Iceberg 오픈 테이블 형식을 기반으로하는 PySpark 애플리케이션을 구축하면서 테스트하는 데 소요되는 시간을 절약하도록 돕는 것이 목표입니다.
출처
- Apache Iceberg 소개
- Spark 및 Iceberg 빠른 시작
- MinIO를 사용한 Apache Iceberg 개발자를 위한 소개
- Iceberg 및 MinIO를 사용한 Lakehouse 아키텍처 완벽 가이드
- Apache Iceberg 학습 — 카탈로그를 Postgres에 저장하기
- Iceberg 항해: Pyspark로 iceberg 테이블 단위 테스트하기