
예측 분야에서는 Lag-LLaMA, Time-LLM, Chronos, Moirai와 같은 모델들이 2024년 초부터 제안되어 기초 모델 분야에서 많은 활동을 보이고 있습니다.
그러나 이러한 모델들의 성능은 조금 아쉬운 면이 있습니다 (재현 가능한 벤치마크를 보려면 여기를 참조하십시오) 그리고 저는 데이터 특화 모델이 여전히 현재 최적의 해결책이라고 믿습니다.
이에 따라 Transformer 아키텍처가 다양한 형태로 시계열 예측에 적용되어왔으며, PatchTST는 장기 예측에서 최고 수준의 성능을 달성하였습니다.
도전적인 PatchTST에 이어 2024년 3월에 제안된 iTransformer 모델이 등장했습니다. 논문 "iTransformer: Inverted Transformers Are Effective for Time Series Forecasting"에서 소개되었습니다.
이 기사에서는 iTransformer의 놀라운 간단한 개념을 발견하고 그 아키텍처를 탐구합니다. 그런 다음 해당 모델을 소규모 실험에 적용하고 그 성능을 TSMixer, N-HiTS 및 PatchTST와 비교합니다.
더 자세한 내용은 원본 논문을 읽어보세요.
시작해봅시다!
iTransformer 탐색
iTransformer의 아이디어는 바닐라 Transformer 모델이 시간 토큰을 사용한다는 깨달음에서 나왔어요.
이것은 모델이 단일 시간 단계에서 모든 특징을 살펴본다는 것을 의미합니다. 그래서 모델이 한 번에 한 시간 단계씩 살펴볼 때 시간 의존성을 학습하는 것이 어려울 수 있어요.
그 문제에 대한 해결책은 PatchTST 모델과 함께 제안된 패칭이에요. 패칭을 사용하면 토큰화하고 임베딩하기 전에 시간 지점을 단순히 그룹화할 수 있어요. 아래에서 보여준 것처럼요.
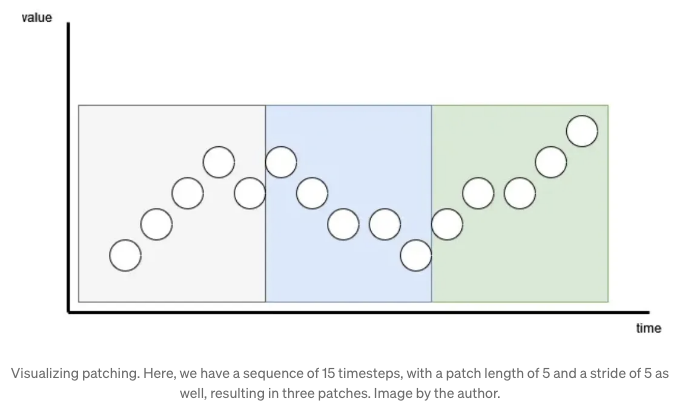
In iTransformer, we push patching to the extreme by simply applying the model on the inverted dimensions.
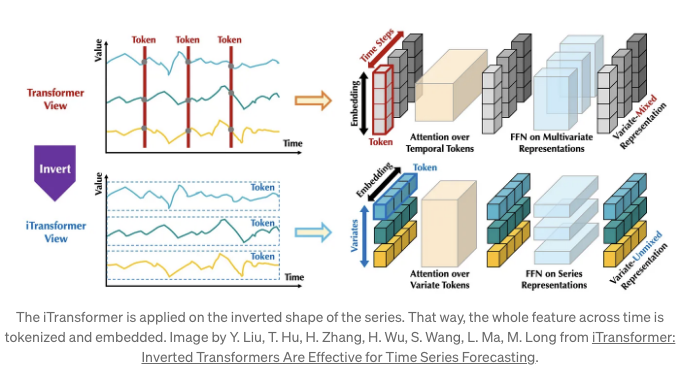
In the figure above, we can see how the iTransformer differs from the vanilla Transformer. Instead of looking at all features at one time step, it looks at one feature across many time steps. This is done simply by inverting the shape of the input.
이렇게하면 어텐션 레이어가 다변량 상관 관계를 학습하고 피드포워드 네트워크가 전체 입력 시퀀스의 표현을 인코딩합니다.
iTransformer의 일반 아이디어를 이해했으니, 이제 더 자세히 살펴보겠습니다.
iTransformer의 아키텍처
iTransformer는 2017년에 Attention Is All You Need에서 처음으로 제안된 임베딩, 프로젝션 및 트랜스포머 블록을 사용한 바닐라 인코더-디코더 아키텍처를 채택합니다.
위의 그림에서 건물 블록들은 동일하지만 기능은 완전히 다르다는 것을 볼 수 있습니다. 좀 더 자세히 살펴보겠습니다.
임베딩 레이어
먼저, 입력 시리즈는 독립적으로 토큰으로 임베딩됩니다. 다시 말해서, 이는 입력의 서브시퀀스를 토큰화하는 대신, 모델이 전체 입력 시퀀스를 토큰화하는 극단적인 경우와 같습니다.
다변량 주의력
그런 다음, 임베딩은 주의층으로 전송되어 다변량 상관 맵을 학습할 것입니다.
이는 역전 모델이 각 특징을 독립된 프로세스로 간주하기 때문에 가능합니다. 이러한 결과로 주의 메커니즘은 특징들 사이의 상관 관계를 학습하게 되며, 이로써 iTransformer는 특히 다변량 예측 작업에 적합합니다.
층 정규화
어텐션 레이어의 출력은 정규화 레이어로 전송됩니다.
전통적인 트랜스포머 아키텍처에서는 정규화가 모든 특성에 대해 고정된 타임스탬프에서 이루어집니다. 이는 모델이 쓸모없는 관계를 학습하게 될 수 있는 상호작용 소음을 도입할 수 있습니다. 또한, 지나치게 매끄러운 신호를 초래할 수 있습니다.
반면, iTransformer는 차원을 뒤집으므로 정규화가 타임스탬프를 횡단하여 이루어집니다. 이는 모델이 비정상적인 시계열에 대처하도록 도와주며, 시계열의 소음을 줄여줍니다.
피드포워드 네트워크
마지막으로, 피드 포워드 네트워크(FFN)는 들어오는 토큰의 깊은 표현을 학습합니다.
다시 말해서, 모양이 반전되어 있기 때문에 다층 퍼셉트론(MLP)은 주기성이나 진폭과 같은 다른 시계열 속성을 학습할 수 있습니다. 이는 MLP 기반 모델(N-BEATS, N-HiTS, TSMixer 등)의 능력을 모방합니다.
프로젝션
여기서 간단히 많은 블록을 쌓는 것으로 이루어진 단계입니다:
- 주의 층
- 계층 정규화
- 피드포워드 네트워크
- 계층 정규화
각 블록은 입력 시리즈의 다른 표현을 학습합니다. 그런 다음, 블록 스택의 출력은 최종 예측을 얻기 위해 선형 투사 단계를 거쳐 전송됩니다.
요약하자면, iTransformer는 새로운 아키텍처가 아니며 Transformer를 새롭게 만들어내지는 않습니다. 단순히 입력의 역된 차원에 Transformer를 적용하여 모델이 다변량 상관 관계를 학습하고 시간적 특성을 포착할 수 있도록 합니다.
이제 iTransformer 모델에 대한 깊은 이해를 갖고 작은 예측 실험에서 적용해 보겠습니다.
iTransformer를 사용한 예측
이 작은 실험에서는 Creative Commons 라이선스로 공개된 전기 변압기 데이터셋에 iTransformer 모델을 적용합니다.
중국 한 성의 두 지역에서 전기 변압기의 오일 온도를 추적하는 인기 있는 벤치마크 데이터셋입니다. 두 지역 모두 1시간마다 샘플링된 데이터셋을 가지고 있으며, 15분마다 샘플링된 데이터셋이 있어 총 네 개의 데이터셋이 있습니다.
iTransformer는 근본적으로 다변량 모델이지만, 우리는 96개의 시간 단계에 걸친 일변량 예측 능력을 테스트합니다.
이 실험에 대한 코드는 GitHub에서 확인할 수 있어요.
자, 시작해봅시다!
초기 설정
이 실험에서는 neuralforecast라는 라이브러리를 사용하는데, 이 라이브러리가 딥러닝 방법의 가장 빠르고 직관적인 사용 가능한 구현을 제공한다고 믿습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datasetsforecast.long_horizon import LongHorizon
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, PatchTST, iTransformer, TSMixer
본 글을 작성하는 시점에서 iTransformer가 아직 neuralforecast의 공개 릴리스에 포함되지 않았음을 참고하세요. 즉시 해당 모델에 액세스하려면 다음을 실행하세요:
pip install git+https://github.com/Nixtla/neuralforecast.git
이제 ETT 데이터셋을로드하고, 검증 크기, 테스트 크기, 그리고 주기를 포함하는 함수를 작성해봅시다.
def load_data(name):
if name == "ettm1":
Y_df, *_ = LongHorizon.load(directory='./', group='ETTm1')
Y_df = Y_df[Y_df['unique_id'] == 'OT']
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
val_size = 11520
test_size = 11520
freq = '15T'
elif name == "ettm2":
Y_df, *_ = LongHorizon.load(directory='./', group='ETTm2')
Y_df = Y_df[Y_df['unique_id'] == 'OT']
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
val_size = 11520
test_size = 11520
freq = '15T'
elif name == 'etth1':
Y_df, *_ = LongHorizon.load(directory='./', group='ETTh1')
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
val_size = 2880
test_size = 2880
freq = 'H'
elif name == "etth2":
Y_df, *_ = LongHorizon.load(directory='./', group='ETTh2')
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
val_size = 2880
test_size = 2880
freq = 'H'
return Y_df, val_size, test_size, freq
The above function conveniently loads the data in the required format for neuralforecast. It includes a unique_id column to identify time series, a ds column for timestamps, and a y column for series values.
Please note that the validation and test sizes align with standards in the scientific community for publishing research papers.
We are all set to start training the models.
훈련 및 예측
iTransformer 모델을 훈련시키기 위해서는 단순히 다음을 지정해주면 됩니다:
- 예측 기간
- 입력 크기
- 시리즈 수
iTransformer가 본질적으로 다변량 모델이기 때문에 모델을 적합할 때 시리즈 수를 지정해야 합니다.
단변량 시나리오이므로 n_series=1입니다.
iTransformer(
(h = horizon),
(input_size = 3 * horizon),
(n_series = 1),
(max_steps = 1000),
(early_stop_patience_steps = 3)
);
위의 코드 블록에서는 최대 학습 단계 수를 지정하고, 과적합을 방지하기 위해 조기 중지를 3번 반복으로 설정합니다.
나머지 모델들에 대해 같은 작업을 수행한 후, 리스트에 넣어줍니다.
horizon = 96;
models = [
iTransformer(
(h = horizon),
(input_size = 3 * horizon),
(n_series = 1),
(max_steps = 1000),
(early_stop_patience_steps = 3)
),
TSMixer(
(h = horizon),
(input_size = 3 * horizon),
(n_series = 1),
(max_steps = 1000),
(early_stop_patience_steps = 3)
),
NHITS((h = horizon), (input_size = 3 * horizon), (max_steps = 1000), (early_stop_patience_steps = 3)),
PatchTST((h = horizon), (input_size = 3 * horizon), (max_steps = 1000), (early_stop_patience_steps = 3)),
];
좋아요! 이제 우리는 단순히 NeuralForecast 객체를 초기화하면 되는데, 이 객체는 학습, 교차 검증 및 예측을 위한 메서드에 액세스할 수 있게 해줍니다.
nf = NeuralForecast((models = models), (freq = freq));
nf_preds = nf.cross_validation((df = Y_df), (val_size = val_size), (test_size = test_size), (n_windows = None));
마지막으로, 우리는 각 모델의 성능을 utilsforecast 라이브러리를 사용하여 평가합니다.
from utilsforecast.losses import mae, mse
from utilsforecast.evaluation import evaluate
ettm1_evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['iTransformer', 'TSMixer', 'NHITS', 'PatchTST'])
ettm1_evaluation.to_csv('ettm1_results.csv', index=False, header=True)
이 단계는 모든 데이터셋에 대해 반복됩니다. 이 실험을 실행하는 완전한 함수는 아래에 표시됩니다.
from utilsforecast.losses import mae, mse
from utilsforecast.evaluation import evaluate
datasets = ['ettm1', 'ettm2', 'etth1', 'etth2']
for dataset in datasets:
Y_df, val_size, test_size, freq = load_data(dataset)
horizon = 96
models = [
iTransformer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),
TSMixer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),
NHITS(h=horizon, input_size=3*horizon, max_steps=1000, early_stop_patience_steps=3),
PatchTST(h=horizon, input_size=3*horizon, max_steps=1000, early_stop_patience_steps=3)
]
nf = NeuralForecast(models=models, freq=freq)
nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)
nf_preds = nf_preds.reset_index()
evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['iTransformer', 'TSMixer', 'NHITS', 'PatchTST'])
evaluation.to_csv(f'{dataset}_results.csv', index=False, header=True)
이 작업을 완료하면 모든 데이터셋에 대해 모든 모델의 예측이 있게 됩니다. 그런 다음 평가로 넘어갈 수 있습니다.
성능 평가
성능 지표를 모두 CSV 파일에 저장했으므로, pandas를 사용하여 이를 읽고 각 모델의 각 데이터셋에 대한 성능을 그릴 수 있습니다.
files = ['etth1_results.csv', 'etth2_results.csv', 'ettm1_results.csv', 'ettm2_results.csv']
datasets = ['etth1', 'etth2', 'ettm1', 'ettm2']
dataframes = []
for file, dataset in zip(files, datasets):
df = pd.read_csv(file)
df['dataset'] = dataset
dataframes.append(df)
full_df = pd.concat(dataframes, ignore_index=True)
full_df = full_df.drop(['unique_id'], axis=1)
이후, 지표를 그래프로 그리려면:
import matplotlib.pyplot as plt
import numpy as np
dataset_names = full_df['dataset'].unique()
model_names = ['iTransformer', 'TSMixer', 'NHITS', 'PatchTST']
fig, axs = plt.subplots(2, 2, figsize=(15, 15))
bar_width = 0.35
axs = axs.flatten()
for i, dataset_name in enumerate(dataset_names):
df_subset = full_df[(full_df['dataset'] == dataset_name) & (full_df['metric'] == 'mae')]
mae_vals = df_subset[model_names].values.flatten()
df_subset = full_df[(full_df['dataset'] == dataset_name) & (full_df['metric'] == 'mse')]
mse_vals = df_subset[model_names].values.flatten()
indices = np.arange(len(model_names))
bars_mae = axs[i].bar(indices - bar_width / 2, mae_vals, bar_width, color='skyblue', label='MAE')
bars_mse = axs[i].bar(indices + bar_width / 2, mse_vals, bar_width, color='orange', label='MSE')
for bars in [bars_mae, bars_mse]:
for bar in bars:
height = bar.get_height()
axs[i].annotate(f'{height:.2f}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom')
axs[i].set_xticks(indices)
axs[i].set_xticklabels(model_names, rotation=45)
axs[i].set_title(dataset_name)
axs[i].legend(loc='best')
plt.tight_layout()
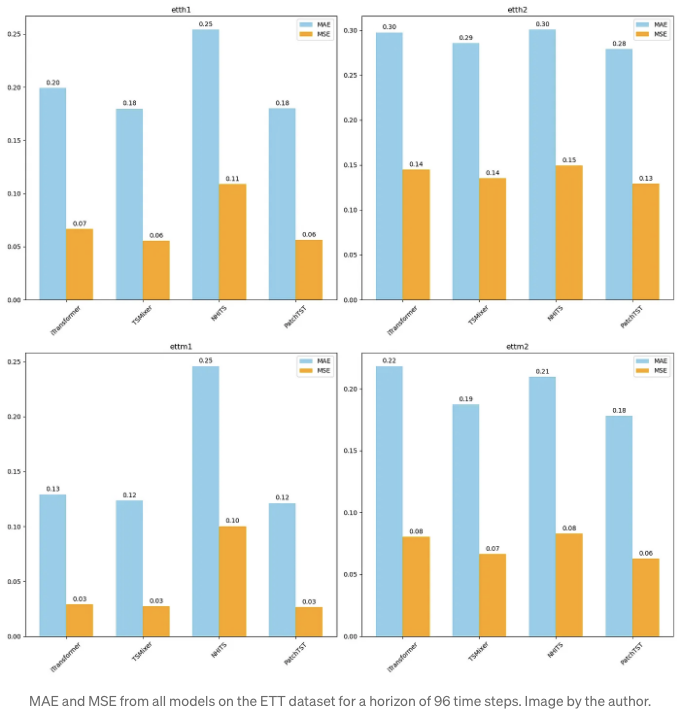
From the figure above, we can see that the iTransformer performs fairly well on all datasets, but TSMixer is overall slightly better than iTransformer, and PatchTST is the overall champion model in this experiment.
Of course, keep in mind that we did not leverage the multivariate capabilities of iTransformer, and we only tested on a single forecast horizon. Therefore, it is not a complete assessment of the iTransformer’s performance.
그럼에도 불구하고, 모델이 PatchTST와 매우 유사하게 수행되는 것을 볼 때, Transformer를 사용한 시계열 예측에서 새로운 성능에 도달하는 데 그룹화 시간 단계를 토큰화하기 전에 묶는 아이디어를 더 지원하는 점이 흥미로운 부분입니다.
결론
iTransformer는 베이닐라 Transformer 아키텍처를 적용한 뒤 입력 시리즈의 역방향 모양으로 그냥 적용합니다.
이렇게 하면 전체 시리즈가 토큰화되고 PatchTST에서 제안한 것과 같이 극단적인 케이스를 모방합니다.
모델이 주의 매커니즘을 사용하여 다변량 상관 관계를 학습하고, 피드포워드 네트워크가 시계열의 시간적 특성을 학습합니다.
iTransformer는 많은 벤치마크 데이터셋에서 장기 예측에 대한 최신 기술을 보여주었으며, 우리의 한정된 실험에서는 PatchTST가 전반적으로 가장 우수한 성과를 보였습니다.
모든 문제는 고유한 해결책이 필요하다고 단언합니다. 이제 iTransformer를 도구 상자에 추가하고 여러분의 프로젝트에 적용할 수 있습니다.
읽어 주셔서 감사합니다! 즐겁게 읽으셨기를 바라며 새로운 지식을 얻으셨기를 기대합니다!
만나서 반가워요 🌟
저를 지원해주세요
제 작업을 즐기고 계신가요? Buy me a coffee로 제게 지원을 표현해주세요. 여러분의 응원을 받으면 저는 커피 한 잔을 즐길 수 있어요! 만약 그렇게 느끼신다면, 아래 버튼을 클릭해주세요 👇

참고 자료
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting by Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, Mingsheng Long