안녕하세요! 이 기사에서는 머신러닝 모델을 평가하는데 있어서 혼동 행렬의 중요성에 대해 살펴보겠습니다. 혼동 행렬이 무엇이며, 어떻게 작동하는지, 그리고 분류 모델의 성능을 평가하는 데 왜 중요한지에 대한 자세한 설명을 제공할 것입니다. 게다가, 우리는 혼동 행렬을 그리는 Python 함수를 살펴보고, 결과를 효과적으로 해석하는 방법에 대한 통찰을 제공할 것입니다.
혼동 행렬 소개
혼동 행렬은 분류 알고리즘의 성능을 평가하는 데 사용되는 표입니다. 예측된 레이블을 실제 레이블과 비교하여 모델이 얼마나 잘 수행되고 있는지 명확하게 보여줍니다. 이 행렬은 모델이 어떤 종류의 오류를 범하고 있는지 이해하는 데 특히 유용하며, 개선할 부분을 식별하는 데 도움이 됩니다.
혼동 행렬의 구조
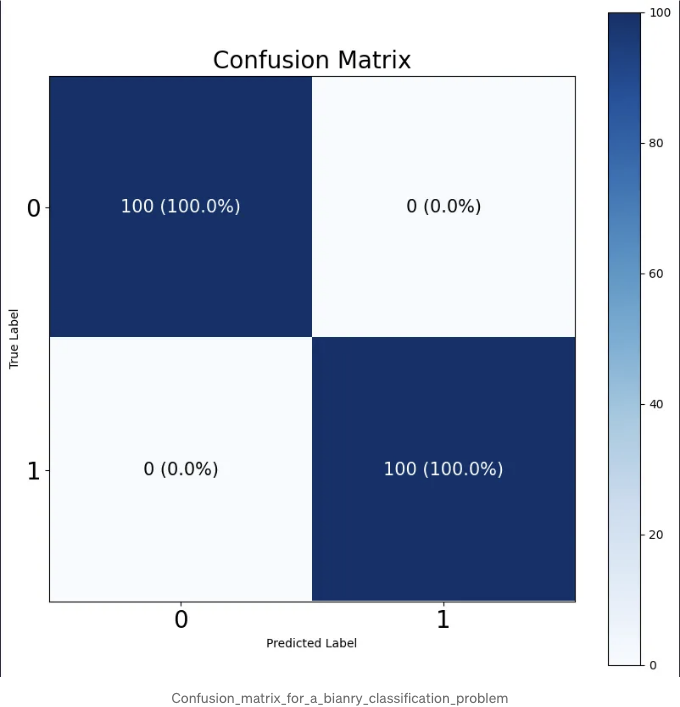
이진 분류 문제의 혼동 행렬은 일반적으로 다음과 같은 모습을 갖습니다:

다중 클래스 분류 문제의 경우, 행렬은 더 많은 클래스를 수용하도록 확장됩니다.
- 정확도: 정확도 점수 이상의 자세한 정확도 정보를 제공합니다.
- 오류 분석: 오류 유형(거짓 양성 및 거짓 음성)을 식별하는 데 도움이 됩니다.
- 모델 개선: 오분류를 이해함으로써 모델을 개선하는 데 유용한 통찰을 제공합니다.
Python으로 혼동 행렬 플로팅
import itertools
import matplotlib.pyplot as plt
import numpy as np
def plot_confusion_matrix(cm, class_labels=None, normalize=False, figsize=(10, 10)):
"""
레이블 및 백분율로 혼동 행렬을 플로팅합니다.
Args:
cm (numpy.ndarray): 혼동 행렬.
class_labels (list, optional): 클래스에 대한 사용자 정의 레이블. 기본값은 None입니다.
normalize (bool, optional): 백분율을 위해 혼동 행렬을 정규화할지 여부. 기본값은 False입니다.
figsize (tuple, optional): 도표의 크기. 기본값은 (10, 10)입니다.
Returns:
None
"""
n_classes = cm.shape[0]
# 플로팅을 위한 도표 및 축 생성
fig, ax = plt.subplots(figsize=figsize)
# 혼동 행렬 시각화를 위한 컬러맵 생성
cax = ax.matshow(cm, cmap=plt.cm.Blues) # 다른 컬러맵을 사용할 수 있습니다
# 플롯에 컬러바 추가
fig.colorbar(cax)
# 축 레이블 (선택사항)
if class_labels is not None:
labels = class_labels
else:
labels = np.arange(cm.shape[0])
# 축 레이블 및 제목 설정
ax.set(
title="혼동 행렬",
xlabel="예측된 레이블",
ylabel="실제 레이블",
xticks=np.arange(n_classes),
yticks=np.arange(n_classes),
xticklabels=labels,
yticklabels=labels,
)
# 가독성을 높이기 위해 x축 레이블 회전
ax.xaxis.set_label_position("bottom")
ax.xaxis.tick_bottom()
# 레이블 크기 조정
plt.setp(ax.xaxis.get_majorticklabels(), size=20)
plt.setp(ax.yaxis.get_majorticklabels(), size=20)
ax.title.set_size(20)
# 텍스트 색상 임계값 계산
threshold = (cm.max() + cm.min()) / 2.
# 필요한 경우 혼동 행렬 정규화
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
# 혼동 행렬의 각 요소를 순회하고 텍스트 주석 추가
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
# 값 및 백분율 표시 (선택사항)
text = f"{cm[i, j]:.2f}" if normalize else f"{cm[i, j]}"
# 임계값에 기반한 텍스트 색상 설정
color = "white" if cm[i, j] > threshold else "black"
# 중앙 정렬 및 적절한 크기로 텍스트 주석 추가
ax.text(
j,
i,
text,
ha="center",
va="center",
color=color,
fontsize=15,
)
# 혼동 행렬 플롯 표시
plt.show()
Plot Confusion Matrix 함수 사용 방법
- 혼동 행렬 생성: 플로팅하기 전에 모델의 예측과 실제 레이블을 이용해 혼동 행렬을 생성해야 합니다. 이를 위해 sklearn.metrics.confusion_matrix를 사용할 수 있습니다.
from sklearn.metrics import confusion_matrix
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
- 혼동 행렬 플로팅: 생성된 행렬로 plot_confusion_matrix 함수를 호출하세요.
plot_confusion_matrix(cm, (class_labels = ["Class 0", "Class 1"]), (normalize = True));
혼동 행렬은 분류 모델의 성능을 평가하는 강력한 도구입니다. 이들은 모델이 얼마나 잘 수행되고 있는지에 대한 포괄적인 관점을 제공하며 개선이 필요한 부분을 강조합니다. 혼동 행렬을 시각화함으로써, 모델의 동작에 대한 더 깊은 통찰력을 얻고 미래 개선을 위한 정보를 파악할 수 있습니다.
본 문서에서는 혼동 행렬을 플로팅하는 Python 함수를 제공하고 사용 방법을 설명했습니다. 이 함수를 워크플로에 통합함으로써, 모델의 예측을 효과적으로 분석하고 해석할 수 있어 더 나은 정확도의 머신 러닝 모델에 이르게 될 것입니다.