
Sample eBook chapters (free): https://github.com/dataman-git/modern-time-series/blob/main/20240522beauty_TOC.pdf
eBook on Teachable.com: $22.50 https://drdataman.teachable.com/p/home
The print edition on Amazon.com: $65 https://a.co/d/25FVsMx
위의 텍스트를 친근하게 번역하면 아래와 같습니다.
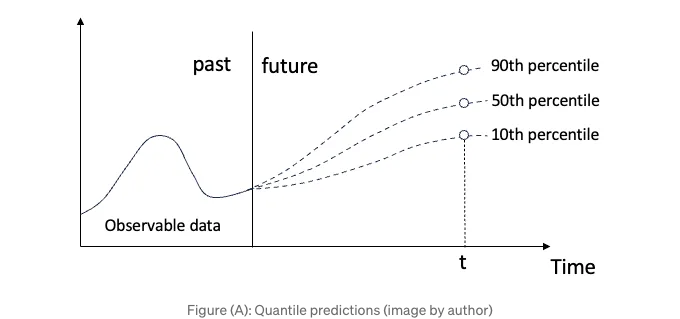
챕터 제목은 "확률 예측", "다기간", "트리 기반" 세 가지 중요한 개념을 다룹니다. 첫 번째로 "확률 예측"이 있습니다. 많은 실세계 응용 프로그램에서는 자원 계획이나 이상 징후 감지를 위해 예측 구간을 요청하며, 이는 1장에서 언급한 것과 같습니다. 이 책의 Part 2에서 언급한 네 가지 해결책 중 하나는 분위수 회귀입니다. 분위 예측은 예측 값을 매우 가능성이 높은 50 번째 백분위 값이거나 상위 90 번째 백분위 값과 같이 매우 낮은 가능성을 보여줍니다 (A) 그림에서 확인할 수 있습니다.
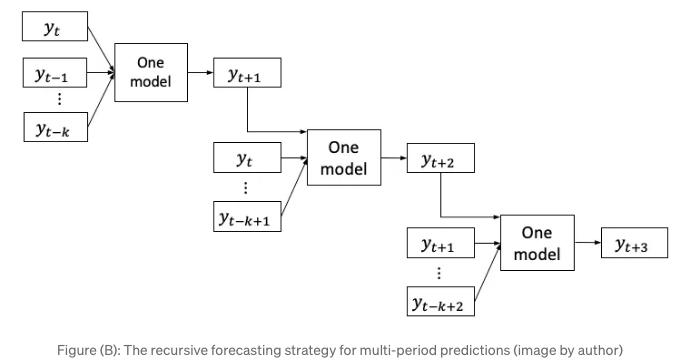
제목에서 두 번째 개념은 다기간 예측입니다. 우리는 일일 예측이 아닌 여러 기간을 위한 예측이 필요한 경우가 많습니다. 한 주간 휴가를 계획할 때, 한 날이 아닌 5일간의 날씨 예보가 필요합니다. 그러나 선형 회귀 또는 트리 기반 알고리즘은 일반적으로 점 추정만 제공합니다. 이러한 경우 어떻게 예측 프로세스를 설계하여 다기간을 제공할 수 있을까요? 직관적으로, 다음 기간을 예측하면 동일한 모델의 입력으로 사용하여 다다음 기간을 예측할 수도 있지 않을까요? 이 해결책은 인기가 있으며 (B) 그림에서 보이는 것과 같이 재귀적 예측 전략이라고 합니다. 재귀적 예측 전략은 모델의 예측을 후속 예측의 입력으로 사용합니다. 전략은 모델이 1 단계 앞으로 예측하기 위해 yt에서 yt-k까지의 과거 값을 사용합니다. 그런 다음 yt+1을 통합하고 다른 입력을 업데이트하여 yt+2를 예측합니다. 이 프로세스를 반복하여 모든 후속 시간 단계를 예측합니다. Darts 라이브러리에서도 이 전략을 할당할 수 있습니다.
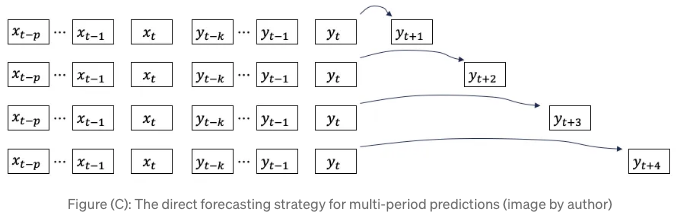
새로운 시각으로 생각해보는 건 어때요? n 기간을 예측하는 것이 목표인 경우, 왜 n 개의 모델을 따로 구축하지 않을까요? 각 모델은 각각의 다음 n 기간을 예측할 것입니다. 이는 직접 예측 전략이라고 불립니다. Darts 라이브러리의 기본 전략이며, 라이브러리에 포함된 모든 모델에 대해 적용됩니다.
마지막으로, 장 제목에 있는 "tree-based"에 대해 논의해보겠습니다. Tree-based 알고리즘들은 지도 학습 알고리즘입니다. 샘플을 행으로, 피처를 열로 갖는 데이터 프레임이 필요합니다. 단변량 시계열 데이터를 데이터 프레임으로 어떻게 변환할까요? 기본 아이디어는 단변량 시계열 데이터에서 샘플을 생성하는 것입니다. 이렇게 함으로써, 모델링을 위해 단변량 시계열 데이터를 데이터 프레임으로 재구성하고, 원하는 경우 단변량 시계열 데이터에서 피처를 생성할 수도 있습니다.
이번 장에서는 세 가지 tree-based 모델인 XGBoost (2016), LightGBM (2017), CatBoost (2018)에 대해 세 부분으로 소개하고, 각 알고리즘에 대해 간단히 설명할 것입니다. 세 모델 간의 차이점에 대해 궁금하다면, Figure (C)에 각 세 그래디언트 부스팅 기반 알고리즘의 특징을 강조한 표를 만들었습니다.

이번 장에서는 Darts 라이브러리를 사용할 것입니다. 시계열 모델링은 많은 기능과 데이터를 저장해야 하므로 Darts 라이브러리는 자체 데이터 형식을 갖추고 있습니다. 시간 순서에 풍부한 정보를 담을 수 있는 다양한 데이터 형식의 장점을 설명하기 위해 본 책은 '10장: 시계열 데이터 형식 쉽게 만들기'를 별도로 마련했습니다. 마지막으로, 이 장은 '11장: 다기간 확률 예측을 위한 자기회귀 선형 회귀'와 함께 읽을 수 있습니다. 두 장은 프로젝트에 적합한 모델을 선택하기 위해 선형 회귀 및 트리 기반 모델을 구축하는 데 도움이 됩니다.
이 장의 구조는 다음과 같습니다:
- 필요한 소프트웨어 요구 사항
- 판다스 데이터를 Darts 데이터 형식으로 변환하는 방법
- XGB
- LightGBM
- CatBoost
파이썬 노트북은 이 Github 링크를 통해 다운로드할 수 있어요.
소프트웨어 요구 사항
기본 Darts 패키지는 Prophet, CatBoost, 그리고 LightGBM 종속성을 설치하지 않습니다. 0.25.0 버전을 기준으로 해서요. 직접 Prophet, CatBoost, 그리고 LightGBM 패키지를 설치해야 해요.
- CatBoostModel: CatBoost 설치 가이드를 사용하여 catboost 패키지(버전 1.0.6 이상)를 설치합니다.
- LightGBMModel: LightGBM 설치 가이드를 사용하여 lightgbm 패키지(버전 3.2.0 이상)를 설치합니다.
!pip install pandas numpy matplotlib darts lightgbm catboost
다음으로, 동일한 Walmart 매장 판매 데이터를 로드할 것입니다.
데이터
저는 Kaggle.com에 있는 Walmart 데이터셋을 사용할 것입니다. 이 데이터셋은 2010년 2월 5일부터 2012년 11월 1일까지의 주간 매장 매출 정보를 포함하고 있습니다.
- Date - 판매 주차
- Store - 상점 번호
- 주간 매출 - 상점의 매출
- 휴일 플래그 - 주가 특별 휴일 주인지 여부 1 - 휴일 주 0 - 비 휴일 주
- 온도 - 판매일 온도
- 연료 가격 - 지역의 연료 비용
소매 판매에 영향을 미칠 수있는 두 가지 거시경제 지표 : 소비자 물가지수와 실업률. 데이터 세트는 Pandas 데이터 프레임으로로드됩니다.
%matplotlib inline
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# Google Colab
from google.colab import drive
drive.mount('/content/gdrive')
path = '/content/gdrive/My Drive/data/time_series'
# https://www.kaggle.com/datasets/yasserh/walmart-dataset
# 데이터 로드
data = pd.read_csv(path + '/walmart.csv', delimiter=",")
data['ds'] = pd.to_datetime(data['Date'], format='%d-%m-%Y')
data.index = data['ds']
data = data.drop('Date', axis=1)
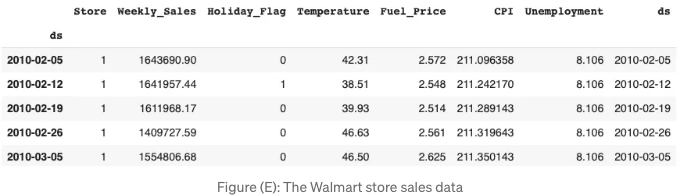
data.head()
제 10 장에서 쉽게 만들어진 Darts의 시계열 데이터 형식에 대해 배웠어요. Darts의 주요 데이터 클래스는 "TimeSeries" 클래스입니다. Darts는 값들을 다음과 같은 배열 모양으로 저장해요 (시간, 차원, 샘플):
- 시간: 위 예시에서처럼 143 주와 같은 시간 인덱스
- 차원: 다변량 시계열의 "열"
- 샘플: 기간에 대한 값들. 10 번째, 50 번째 백분위수와 90 번째 백분위수에 대한 그림 (A)에서처럼 확률론적 예측이라면 3개의 샘플이 있을 거예요.
저희는 월마트 매장 판매량을 불러오기 위해 .from_group_dataframe() 함수를 사용할 거예요. 그룹 ID는 "Store"예요. 따라서 group_cols 매개변수는 "Store"가 될 거예요. 시간 인덱스는 "ds" 열이에요.
from darts import TimeSeries
darts_group_df = TimeSeries.from_group_dataframe(data, group_cols='Store', time_col='ds')
print("그룹/매장의 수는:", len(darts_group_df))
print("시간 기간의 수는: ", len(darts_group_df[0]))
- 그룹/상점 수: 45
- 기간 수: 143
다음과 같이 컬럼을 나열할 수 있습니다. components 함수를 사용해봅시다:
darts_group_df[0].components;
Index(['Weekly_Sales', 'Holiday_Flag', 'Temperature', 'Fuel_Price', 'CPI', 'Unemployment'], dtype='object', name='component')
Store 1 매출 모델을 구축하기 위해 Store 1 데이터만 사용할 겁니다. "darts_group_df[0]"에 해당합니다. 이를 훈련 데이터와 테스트 데이터로 나눌 겁니다.
store1 = darts_group_df[0]
train = store1[:130]
test = store1[130:]
len(train), len(test) # (130, 13)
우리의 목표 시리즈는 "Weekly_Sales"입니다. 다른 공선변수를 포함할 수도 있습니다. 시계열에서는 과거 공선변수와 미래 공선변수 두 종류가 있습니다. Darts 라이브러리는 동일한 용어를 사용합니다. 과거 공선변수는 연구 현재 시간까지의 변수입니다. 미래 공선변수는 미래에 관측 가능한 변수입니다. 미래 값을 어떻게 알 수 있는지 궁금할 수도 있습니다. 첫 번째 이유는 미래 휴일과 같이 결정론적 값이기 때문입니다. 두 번째 이유는 날씨 예측과 같은 다른 소스에서 예측된 값이기 때문입니다. 우리의 경우 "Fuel_price"와 "CPI"를 과거 공선변수로, "Holiday_flag"를 미래 공선변수로 포함할 것입니다. 훈련 데이터에서의 목표와 과거 공선변수는 130개의 데이터 포인트가 있습니다. 하지만 미래 공선변수는 실제로 미래까지 확장되어 143개의 데이터 포인트를 갖습니다.
target = train['Weekly_Sales']
past_cov = train[['Fuel_Price','CPI']]
future_cov = store1['Holiday_Flag'][:143]
우니바리에이트 데이터부터 시작해보겠습니다.
XGB
XGBoost (Extreme Gradient Boosting)은 분류 및 회귀와 같은 지도 학습 작업에 널리 사용되며 효율성, 확장성 및 정확도로 알려져 있습니다. 가장 주목할 만한 기능은 오버피팅을 방지하기 위해 L1 및 L2 규제 기술이 포함되어 있다는 점입니다. 규제 패널티는 트리의 가중치, 리프 노드 값, 특성 중요도 점수에 적용되어 일반화 성능을 향상시키는 데 도움을 줍니다. 또 다른 기능으로는 병렬 및 분산 컴퓨팅을 지원하며 멀티코어 CPU 및 Apache Spark 및 Dask와 같은 분산 컴퓨팅 프레임워크에서 효율적인 학습이 가능합니다. 이 확장성은 대규모 데이터 처리에 적합하게 만듭니다. 그 외에도 이전 모델이 실수한 오류를 수정하기 위해 각 트리가 순차적으로 훈련되는 경사 부스팅 프레임워크를 계승했습니다. 전체적인 목표는 특정 손실 함수를 최소화하는 것입니다.
다음 코드는 Darts의 표준 모델링 구문입니다.
from darts.models import XGBModel
n = 12
chunk_length = n
model = XGBModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5],
output_chunk_length=12,
Multi_models = True # optional
verbose=-1
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n)
pred
fit() 함수의 "target"은 모델링을 위한 대상 시리즈입니다. 모델은 yt, yt-1, yt-2, ..., yt-12까지의 지연된 값들에 대한 "lags"를 필요로 합니다. 또한 다른 공변량을 지정할 수도 있습니다. 시계열 모델링에서 과거 공변량과 미래 공변량이라는 두 가지 넓은 유형의 공변량이 있습니다. Darts는 이 규칙을 따릅니다. lags_past_covariates는 xt, xt-1, ..., xt-12와 같이 지연된 과거 공변량을 나타냅니다. 약간 혼동스러운 lags_future_covariates 이름은 미래 공변량을 의미합니다. "미래 공변량"은 미래 시간 단계에서의 이러한 공변량의 값들을 의미하며, "지연된" 값들은 이전 시간 단계에서의 미래 공변량을 의미합니다. 이는 미래 t + n 단계에 대해 모델이 t부터 t + (n-1)까지의 공변량의 값을 고려한다는 것을 의미합니다.
multi_models 매개변수가 True로 설정된 것에 주목해주세요. 이는 모델에게 다중 기간 예측을 위한 직접 예측 전략 또는 재귀적 예측 전략을 사용할지 알려줍니다. 기본값은 True이며, 이는 직접 예측 전략을 사용한다는 것을 의미합니다.
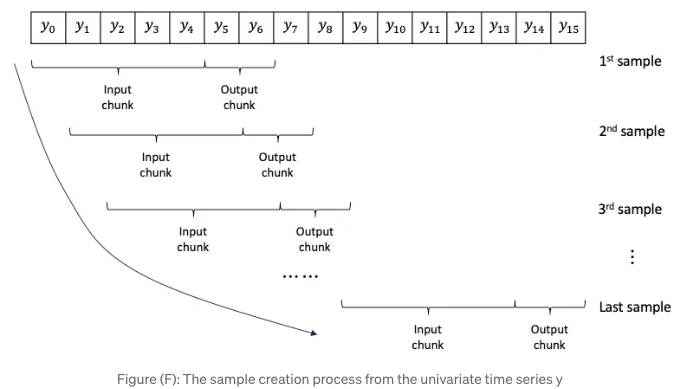
입력 청크 길이와 출력 청크 길이에 관한 한 가지 추가적인 매개변수가 있습니다. 이는 단변량 시리즈에서 샘플을 생성하는 것과 관련이 있습니다. 그림 (F)는 y0에서 y15까지의 시리즈에서 생성된 샘플을 보여줍니다. 각 샘플에는 입력 청크와 출력 청크가 포함되어 있습니다. 입력 청크 길이가 5이고 출력 청크 길이가 2인 것을 가정해보세요. 첫 번째 샘플은 입력 청크로 y0 - y4를, 출력 청크로 y5, y6를 가지고 있습니다. 창이 시리즈를 따라 이동하여 샘플을 만들며, 이를 시리즈의 끝까지 반복합니다. 출력 청크 길이는 예측할 수 있는 가장 긴 길이를 정의합니다. 이를 12로 지정했습니다. 12 이상을 예측하려고 하면 오류 메시지가 출력됩니다.
The outputs are stored in the Dart data array:
We will plot the actual and the predicted values. We make this in a function for repeating use.
def plotit():
import matplotlib.pyplot as plt
target.plot(label='train')
pred.plot(label='prediction')
test['Weekly_Sales'][:n].plot(label='actual')
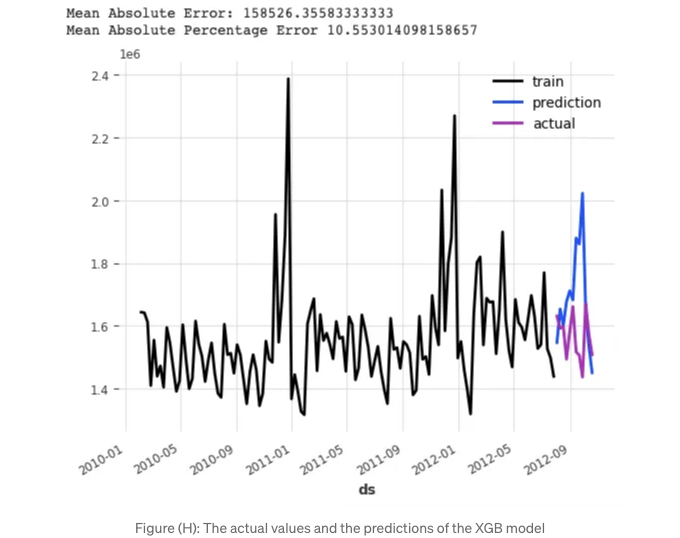
from darts.metrics.metrics import mae, mape
print("Mean Absolute Error:", mae(test['Weekly_Sales'][:n], pred))
print("Mean Absolute Percentage Error", mape(test['Weekly_Sales'][:n], pred))
plotit()
MAPE 값은 10.55% 입니다.
이제 분위수 예측을 추가해보겠습니다. 모델에게 5개의 분위수를 생성해 달라고 요청하겠습니다.
from darts.models import XGBModel
n = 12
chunk_length = n
model = XGBModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5,6,7,8,9,10,11,12],
output_chunk_length=chunk_length,
likelihood = 'quantile', # 'quantile' 또는 'poisson'으로 설정 가능합니다.
# 'quantile'로 설정하면 sklearn.linear_model.QuantileRegressor가 사용됩니다.
# 'poisson'으로 설정하면 sklearn.linear_model.PoissonRegressor가 사용됩니다.
quantiles=[0.01, 0.05, 0.50, 0.95, 0.99]
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n, num_samples=5)
pred
각 예측에는 5개의 샘플이 있습니다. 이는 5개의 분위 수치 값을 생성했기 때문입니다.

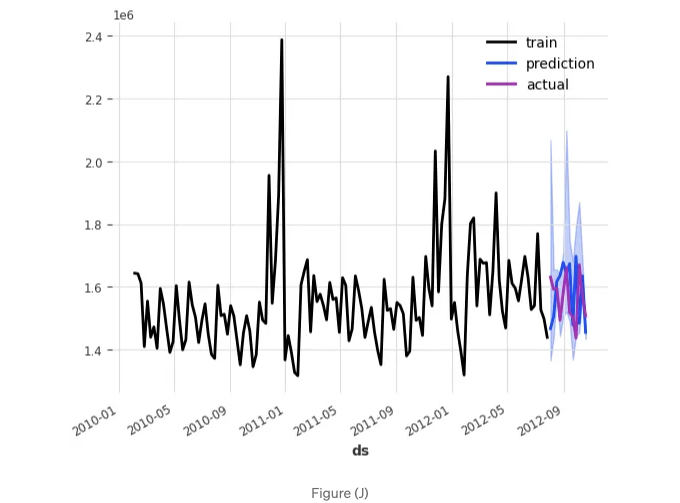
실제 값과 분위 예측을 시각화할 수 있습니다.
def plotQuantile():
import matplotlib.pyplot as plt
target.plot(label = 'train')
pred.plot(label = 'prediction')
test['Weekly_Sales'][:n].plot(label = 'actual')
plotQuantile()
양자 예측은 다음과 같습니다:
모델을 구축하고 예측을 제공하는 것이 매우 쉽다는 것을 발견할 수 있을 것 입니다. 계속해서 LightGBM 모델을 구축해 봅시다.
LightGBM
"제 12장: Tree-based Time Series Models의 Feature Engineering"에서 lightGBM 모델을 구축한 적이 있지 않았나요? 정말이죠! 다른 점은 여기서는 Darts 라이브러리를 사용하여 lightGBM 모델을 구축할 것이라는 점입니다. 이전 장에서의 데이터 형식은 Pandas 데이터 프레임이었지만, 여기서는 Darts 데이터 object입니다. 그럼에도 불구하고 LightGBM이 무엇인지 설명해보겠습니다.
LightGBM (Light Gradient Boosting Machine)은 gradient-boosting 결정 트리 모델의 효율적이고 확장 가능한 학습을 위해 설계되었습니다. LightGBM은 빠른 속도, 메모리 효율성, 정확성으로 인해 인기를 얻었습니다. 그 중요한 특징은 다른 gradient-boosting 구현에서 사용되는 전통적인 수준별 전략이 아니라 잎별 성장 전략을 채택한다는 것입니다. 이 전략은 손실을 가장 효과적으로 최소화할 잎 노드를 선택하여 더 빠른 학습 시간을 제공합니다. 그 외에도 그래디언트 부스팅 알고리즘을 여전히 구현합니다.
from darts.models import LightGBMModel
n = 12
model = LightGBMModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5],
output_chunk_length=12,
verbose=-1
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n)
pred.values()
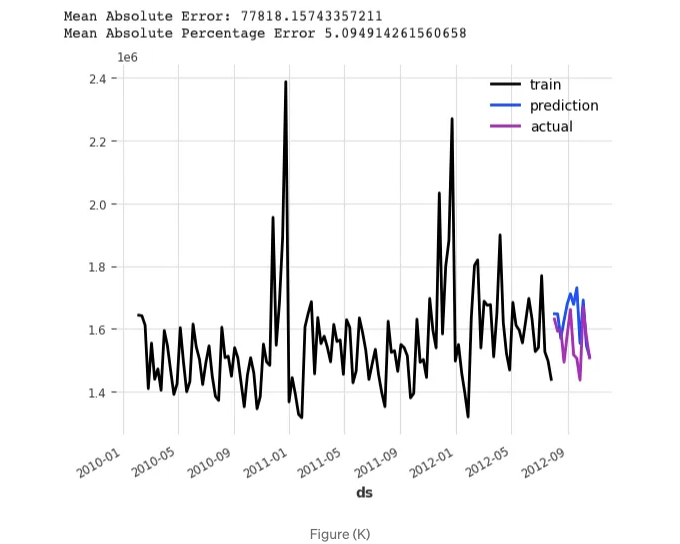
위의 코드는 XGB와 유사하여 더 이상 강조하지 않겠습니다. 그래프를 그려 성능 메트릭을 살펴봅시다:
plotit();
MAPE는 5.09%입니다.
이제 분위 예측을 포함해 봅시다.
n = 12
chunk_length = n
model = LightGBMModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5,6,7,8,9,10,11,12],
output_chunk_length=chunk_length,
likelihood = 'quantile', # quantile 또는 poisson 으로 설정할 수 있습니다.
# quantile로 설정하면 sklearn.linear_model.QuantileRegressor가 사용됩니다.
# poisson으로 설정하면 sklearn.linear_model.PoissonRegressor가 사용됩니다.
quantiles=[0.01, 0.05, 0.50, 0.95, 0.99]
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n, num_samples=5)
pred
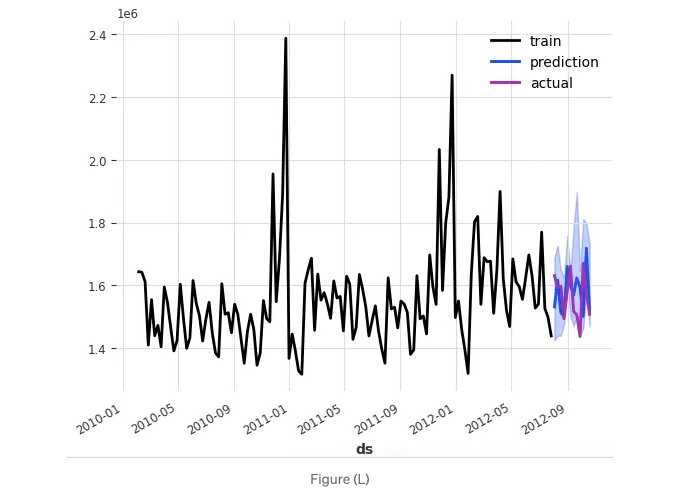
분위 예측을 그래프로 확인해볼 수 있습니다.
plotQuantile();
양자수치 예측값은:
좋아요. 이미 두 개의 모델이 구축되었습니다. 이제 CatBoost 모델을 구축해봅시다.
CatBoost
CatBoost은 "Category Boosting"의 약자입니다. 범주형 기능을 효율적으로 처리할 수 있도록 특별히 설계되었으므로 다양한 분류 및 회귀 작업에 적합합니다. 이는 원-핫 인코딩과 같은 전처리가 필요 없이 범주형 기능을 직접 처리할 수 있습니다. CatBoost는 카테고리별 통계 속성에 기초하여 최적 분할점을 찾아 효율적으로 범주형 변수를 처리하는 Ordered Boosting이라는 새로운 알고리즘을 사용합니다. 이외에도 결정 트리 앙상블을 구축하기 위해 그래디언트 부스팅의 구현을 상속받습니다. 각 트리는 이전 모델의 오류를 최소화하도록 학습됩니다. 최적 매개변수를 찾기 위해 그래디언트 강하 최적화 알고리즘을 사용합니다.
from darts.models import CatBoostModel
n = 12
chunk_length = n
model = CatBoostModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5],
output_chunk_length=12,
verbose=-1
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n)
pred
위 코드에 CatBoostModel을 삽입하여 내용을 그대로 유지하시면 됩니다.
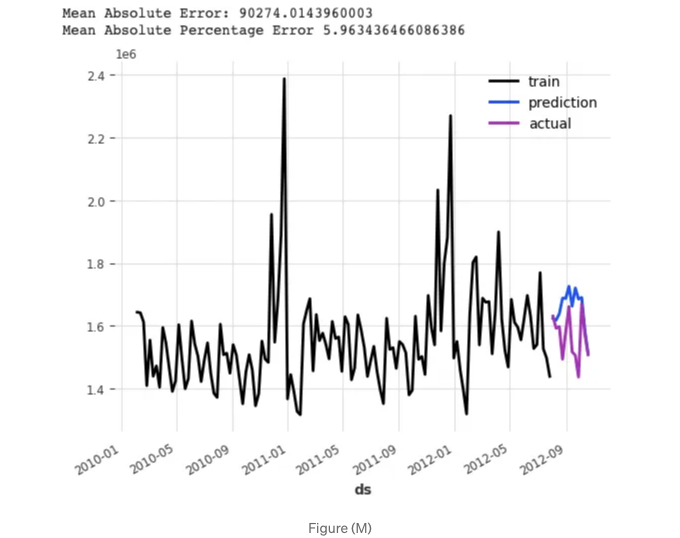
결과를 그래프로 출력해보겠습니다:
plotit();
MAPE는 5.96% 입니다.
모델에 분위 예측을 포함해 봅시다.
n = 12
chunk_length = n
model = CatBoostModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5,6,7,8,9,10,11,12],
output_chunk_length=chunk_length,
likelihood = 'quantile', # 'quantile' 또는 'poisson'으로 설정할 수 있습니다.
# 'quantile'로 설정하면 sklearn.linear_model.QuantileRegressor가 사용됩니다.
# 'poisson'으로 설정하면 sklearn.linear_model.PoissonRegressor가 사용됩니다.
quantiles=[0.01, 0.05, 0.50, 0.95,0.99]
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n, num_samples=5)
pred
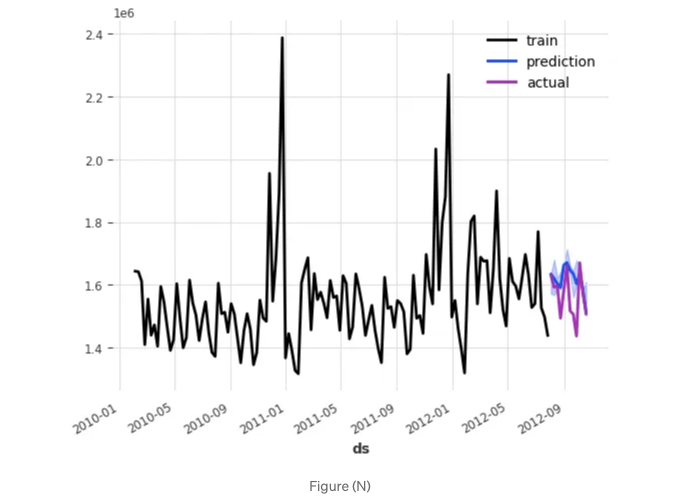
양자화 예측값을 그릴 수 있습니다.
plotQuantile();
이 차트는 다음과 같습니다.
결론
이 장에서는 Darts 라이브러리를 사용하여 세 가지 인기있는 트리 기반 시계열 모델을 구축했습니다. 우리는 다기간 예측 및 예측 불확실성의 사용 사례에 중점을 두었습니다. 다음에 시계열 모델을 구축하여 다기간 예측 및 예측 불확실성을 제공해야 할 때, 세 가지 트리 기반 모델과 다기간 확률적 예측을 위한 자동 회귀 선형 회귀 모델을 함께 생성하는 것을 권장합니다. 우승 모델을 찾기 위해 11 장에서 선형 회귀 모델과 결합하여 사용할 수 있습니다.
이 장은 트리 기반 시계열 모델에 대한 현대적 기법 시리즈를 마무리합니다. 다음 장에서는 딥러닝 기반 시계열 모델에 대한 시리즈를 시작할 것입니다.
- 시계열 모델링 기법의 진화
- RNN/LSTM용 DeepAR
- 응용 - 주식 가격에 대한 확률 예측
참고문헌
- (XGB) Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 785–794). ACM. 링크
- (LightGBM) Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., … & Li, Q. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems (pp. 3146–3154). 링크
- (CatBoost) Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: unbiased boosting with categorical features. In Advances in Neural Information Processing Systems (pp. 6638–6648). 링크
샘플 eBook 챕터 (무료): 링크
- The Innovation Press, LLC의 직원들께서 아름다운 형식으로 책을 재구성해 주어 즐거운 독서 경험을 선사했습니다. 전 세계 독자들에게 복잡한 유지보수비 없이 eBook을 배포하기 위해 Teachable 플랫폼을 선택했습니다. 신용카드 거래는 Teachable.com에 의해 기밀리에 안전하게 관리됩니다.
Teachable.com에서의 eBook: $22.50 https://drdataman.teachable.com/p/home
Amazon.com에서의 인쇄판: $65 https://a.co/d/25FVsMx
- 인쇄판은 윤광 표지, 컬러 인쇄, 아름다운 Springer 글꼴과 레이아웃을 사용하여 즐거운 독서를 위해 디자인되었습니다. 7.5 x 9.25 인치의 크기는 책장의 대부분 책들과 잘 어울립니다.
- “이 책은 과거 시계열 분석 및 예측 분석, 이상 징후 탐지 등의 응용에 대한 깊은 이해력을 갖춘 쿠오의 증명서입니다. 이 책은 독자들에게 실세계의 도전 과제에 대처하는 데 필요한 기술을 제공합니다. 데이터 과학으로의 전직을 고려하는 분들에게 특히 가치 있습니다. 쿠오는 전통적이고 최첨단 기술 모두에 대해 상세히 탐구합니다. 쿠오는 신경망 및 다른 고급 알고리즘에 대한 토론을 통합하여 최신 동향과 발전을 반영합니다. 이는 독자들이 확립된 방법뿐만 아니라 데이터 과학 분야의 가장 최신이며 혁신적인 기술과 상호작용할 수 있도록 준비되어 있다는 것을 보장합니다. 쿠오의 생동감 넘치는 글쓰기 스타일로 이 책의 명확함과 접근성이 향상되었습니다. 그는 복잡한 수학적 및 통계적 개념을 실용적으로 만들어내며 엄격함을 희생하지 않고 다가갈 수 있게 만듭니다.”
현대 시계열 예측: 예측 분석과 이상 감지
제로 장: 서문
1장: 소개
2장: 비즈니스 예측을 위한 예언자
Chapter 3: 튜토리얼 1 - 추세 + 계절성 + 휴일 및 이벤트
Chapter 4: 튜토리얼 2 - 추세 + 계절성 + 휴일 및 이벤트 + 자기회귀(AR) + 지연 회귀 변수 + 미래 회귀 변수
Chapter 5: 시계열의 변화점 탐지
Chapter 6: 시계열 확률 예측을 위한 몬테카를로 시뮬레이션
제목 7: 시계열 확률 예측을 위한 분위 회귀
제목 8: 시계열 확률 예측을 위한 적응형 예측
제목 9: 시계열 확률 예측을 위한 적응형 분위 회귀
제목 10: 자동 ARIMA!
"Chapter 11: 시계열 데이터 형식을 쉽게 만들어보기
Chapter 12: 다기간 확률 예측을 위한 선형 회귀
Chapter 13: 트리 기반 시계열 모델을 위한 피처 엔지니어링
Chapter 14: 다기간 시계열 예측을 위한 두 가지 주요 전략"