제품 환경을 위한 데이터 파이프라인 확장을 위한 TensorFlow Transform 활용
![]()
데이터 전처리는 머신 러닝 파이프라인에서 중요한 단계 중 하나입니다. TensorFlow Transform은 거대한 데이터셋 위에서 분산 환경에서 이를 달성하는 데 도움이 됩니다.
데이터 변환에 대해 더 알아보기 전에, 제품 파이프라인 프로세스의 첫 번째 단계인 데이터 유효성 검사에 대해 다룬 제 글 "TFX 방식으로 제품 파이프라인에서 데이터 유효성 검사하기"가 있습니다. 더 나은 이해를 위해 이 글을 확인해보세요!
이 데모에서는 환경을 구성하는 것이 훨씬 쉽고 빠르기 때문에 이를 위해 Colab을 사용했습니다. 탐색 단계에 있다면 중요한 부분에 집중할 수 있도록 도와줄 Colab을 추천드립니다.
ML 파이프라인 작업은 데이터 수집 및 검증으로 시작하여 변환을 거칩니다. 변환된 데이터는 학습 및 배포됩니다. 이전 글에서 검증 부분을 다루었고, 이제는 변환 부분을 다룰 예정입니다. Tensorflow에서 파이프라인에 대한 더 나은 이해를 위해 아래 글을 확인해보세요.
이전에 말한 대로 Colab을 사용할 것입니다. 그래서 tfx 라이브러리를 설치하면 됩니다.
! pip install tfx
그 다음은 imports가 옵니다.
# 라이브러리 가져오기
import tensorflow as tf
from tfx.components import CsvExampleGen
from tfx.components import ExampleValidator
from tfx.components import SchemaGen
from tfx.v1.components import ImportSchemaGen
from tfx.components import StatisticsGen
from tfx.components import Transform
from tfx.orchestration.experimental.interactive.interactive_context import InteractiveContext
from google.protobuf.json_format import MessageToDict
import os
저희는 데이터 유효성 검사 기사에서와 같이 Kaggle에서 제공하는 타이타닉 우주선 데이터셋을 사용할 것입니다. 이 데이터셋은 상업적 및 비상업적 용도로 무료로 사용할 수 있습니다. 여기에서 데이터셋에 접근할 수 있습니다. 데이터셋에 대한 설명이 아래 그림에 표시되어 있습니다.
데이터 변환 부분을 시작하기 위해서는 파이프라인 구성 요소를 배치할 폴더를 생성하는 것이 좋습니다(그렇지 않으면 기본 디렉터리에 배치됩니다). 저는 파이프라인 구성 요소를 위한 하나와 훈련 데이터를 위한 다른 하나의 폴더를 만들었습니다.
# 파이프라인 폴더 경로
# 생성된 모든 구성 요소는 여기에 저장됩니다
_pipeline_root = '/content/tfx/pipeline/'
# 훈련 데이터 경로
# 여러 훈련 데이터 파일을 포함할 수도 있습니다
_data_root = '/content/tfx/data/'
그 다음으로, InteractiveContext를 만들고 파이프라인 디렉터리 경로를 전달합니다. 이 과정은 또한 파이프라인 프로세스의 메타데이터를 저장하기 위한 sqlite 데이터베이스를 생성합니다.
InteractiveContext은 각 단계를 탐색하는 데 사용됩니다. 각 단계에서 생성된 아티팩트를 확인할 수 있습니다. 프로덕션 환경에서는 Apache Beam과 같은 파이프라인 생성 프레임워크를 사용하면 이 전체 프로세스가 개입없이 자동으로 실행될 것입니다.
# InteractiveContext 초기화
# 이는 메타데이터를 저장하기 위해 sqlite db를 생성합니다
context = InteractiveContext(pipeline_root=_pipeline_root)
다음으로 데이터 수집부터 시작합니다. 데이터가 csv 파일로 저장되어 있다면 CsvExampleGen을 사용하여 데이터 파일이 저장된 디렉터리 경로를 전달할 수 있습니다.
# 입력 CSV 파일
example_gen = CsvExampleGen(input_base=_data_root)
TFX는 현재 csv, tf.Record, BigQuery 및 일부 사용자 정의 실행기를 지원합니다. 자세한 내용은 아래 링크에서 확인할 수 있어요.
ExampleGen 구성 요소를 실행하려면 context.run을 사용하세요.
# 구성 요소 실행하기
context.run(example_gen)
구성 요소를 실행한 후, 아래와 같은 출력이 생성됩니다. 실행 ID, 구성 요소 세부 정보 및 구성 요소의 출력이 저장된 위치가 표시됩니다.
확장하면 이 상세 정보를 볼 수 있어야 합니다.
디렉토리 구조는 아래 이미지와 같습니다. 이 모든 아티팩트들은 TFX에 의해 자동으로 생성되었습니다. 또한 자동으로 버전이 지정되며 세부 정보는 metadata.sqlite에 저장됩니다. 해당 sqlite 파일은 데이터 출처 또는 데이터 계보를 유지하는 데 도움이 됩니다.
아래와 같이 코드를 사용하여 이러한 자료를 프로그램적으로 탐색해 보세요.
# 생성된 자료 확인
artifact = example_gen.outputs['examples'].get()[0]
# 분할 이름과 URI 표시
print(f'split names: {artifact.split_names}')
print(f'artifact uri: {artifact.uri}')
출력은 파일 이름과 URI가 될 것입니다.

이제 train uri를 복사하여 파일 내부의 세부 정보를 살펴보겠습니다. 파일은 zip 파일로 저장되어 있으며 TFRecordDataset 형식으로 저장되어 있습니다.
# 훈련 예제를 나타내는 출력 아티팩트의 URI를 가져옵니다
train_uri = os.path.join(artifact.uri, 'Split-train')
# 이 디렉토리에 있는 파일 목록(모든 압축된 TFRecord 파일)을 가져옵니다
tfrecord_filenames = [os.path.join(train_uri, name)
for name in os.listdir(train_uri)]
# 이 파일들을 읽을 `TFRecordDataset`을 생성합니다
dataset = tf.data.TFRecordDataset(tfrecord_filenames, compression_type="GZIP")
아래 코드는 Tensorflow에서 가져온 것이며, TFRecordDataset에서 레코드를 가져와 결과를 반환하여 검사할 수 있는 표준 코드입니다.
도우미 함수로 개별 예제 가져오기
def get_records(dataset, num_records): '''주어진 데이터 세트에서 레코드를 추출합니다. 매개변수: dataset (TFRecordDataset): ExampleGen에 의해 저장된 데이터 세트 num_records (int): 미리보기할 레코드 수 '''
# 빈 리스트를 초기화합니다.
records = []
# 가져올 레코드 수를 지정하는 `take()` 메서드 사용
for tfrecord in dataset.take(num_records):
# 텐서의 넘파이 속성을 가져옵니다.
serialized_example = tfrecord.numpy()
# 직렬화된 데이터를 읽기 위해 `tf.train.Example()`을 초기화합니다.
example = tf.train.Example()
# 예제 데이터를 읽습니다 (결과는 프로토콜 버퍼 메시지입니다).
example.ParseFromString(serialized_example)
# 프로토콜 버퍼 메시지를 Python 사전으로 변환합니다.
example_dict = (MessageToDict(example))
# 레코드 목록에 추가합니다.
records.append(example_dict)
return records
데이터 세트에서 3개의 레코드 가져오기
sample_records = get_records(dataset, 3)
결과 출력
pp.pprint(sample_records)
3개의 레코드를 요청했고, 출력은 다음과 같습니다. 각 레코드와 해당 메타데이터가 사전 형식으로 저장됩니다.
다음으로, 다음 단계로 진행하여 StatisticsGen을 사용하여 데이터의 통계를 생성하는 과정으로 이동합니다. example_gen 객체에서 출력을 인수로 전달합니다.
statistics.run을 사용하여 구성 요소를 실행합니다. 이때 statistics_gen을 인수로 전달합니다.
# example_gen 객체를 사용하여 StatisticsGen으로 데이터 집합 통계 생성
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'])
# 구성 요소 실행
context.run(statistics_gen)
결과를 확인하려면 context.show를 사용할 수 있습니다.
# 출력 통계 보기
context.show(statistics_gen.outputs['statistics'])
TFDV (TensorFlow Data Validation) 기사에서 설명한 통계 생성과 매우 유사하다는 것을 알 수 있습니다. 그 이유는 TFX가 이러한 작업을 수행하기 위해 내부적으로 TFDV를 사용하기 때문입니다. TFDV에 익숙해지면 이러한 프로세스를 더 잘 이해하는 데 도움이 될 것입니다.
다음 단계는 스키마를 생성하는 것입니다. 이 작업은 statistics_gen 객체를 전달하여 SchemaGen을 사용하여 수행됩니다. 구성 요소를 실행하고 context.show를 사용하여 시각화하세요.
# 통계_gen 객체를 사용하여 SchemaGen을 사용하여 스키마 생성
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
)
# 컴포넌트 실행
context.run(schema_gen)
# 스키마 시각화
context.show(schema_gen.outputs['schema'])
출력 결과에는 데이터의 기본 스키마에 관한 세부 정보가 표시됩니다. TFDV와 마찬가지로입니다.
여기에 제시된 스키마를 수정해야 하는 경우 tfdv를 사용하여 수정하고 스키마 파일을 생성할 수 있습니다. ImportSchemaGen을 사용하여 새 파일을 tfx에 사용하도록 요청할 수 있습니다.
# 스키마 파일을 수동으로 추가
schema_gen = ImportSchemaGen(schema_file="path_to_schema_file/schema.pbtxt")
다음으로, ExampleValidator를 사용하여 예제를 유효성 검사합니다. statistics_gen 및 schema_gen을 인수로 전달합니다.
# ExampleValidator를 사용하여 예제 유효성을 검사
# statistics_gen 및 schema_gen 객체를 전달합니다
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'])
# 구성 요소를 실행합니다.
context.run(example_validator)
모든 것이 잘되었음을 나타내는 이상적인 출력입니다.
At this point, our directory structure looks like the image above. We can see that for every step in the process, the corresponding artifacts are created.

Let us move on to the actual transformation part. We will now create the constants.py file to add all the constants required for the process.
이 프로젝트에 사용할 모든 상수를 포함하는 파일 생성
_constants_module_file = 'constants.py'
모든 상수를 생성하고 constants.py 파일에 쓸 것입니다. “%%writefile '_constants_module_file'”을 참조하세요. 이 몤령어는 코드를 실행시키지 않고 대신 주어진 셀의 모든 코드를 지정된 파일로 작성합니다.
%%writefile {_constants_module_file}
문자열 데이터 유형을 인덱스로 변환할 기능
CATEGORICAL_FEATURE_KEYS = ['CryoSleep', 'Destination', 'HomePlanet', 'VIP']
지속적인 것으로 표시된 숫자 기능
NUMERIC_FEATURE_KEYS = ['Age', 'FoodCourt', 'RoomService', 'ShoppingMall', 'Spa', 'VRDeck']
버킷에 그룹화할 수 있는 기능
BUCKET_FEATURE_KEYS = ['Age']
각 버킷 기능을 인코딩하는 데 사용하는 버킷 수
FEATURE_BUCKET_COUNT = {'Age': 4}
모델이 예측할 기능
LABEL_KEY = 'Transported'
기능 이름을 바꾸기 위한 유틸리티 함수
def transformed_name(key): return key + '_xf'
실제 데이터를 변환하는 코드를 포함하는 transform.py 파일을 생성합시다.
# 프로젝트를 위한 전처리 코드가 포함된 파일을 생성합니다.
_transform_module_file = 'transform.py'
여기서는 tensorflow_transform 라이브러리를 사용할 것입니다. 변환 과정에 대한 코드는 preprocessing_fn 함수 안에 작성될 것입니다. 변환 과정에서 tfx가 내부적으로 이를 찾을 수 있도록 동일한 이름을 사용해야 합니다.
%%writefile {_transform_module_file}
import tensorflow as tf
import tensorflow_transform as tft
import constants
# 상수 모듈의 내용을 언패킹합니다.
_NUMERIC_FEATURE_KEYS = constants.NUMERIC_FEATURE_KEYS
_CATEGORICAL_FEATURE_KEYS = constants.CATEGORICAL_FEATURE_KEYS
_BUCKET_FEATURE_KEYS = constants.BUCKET_FEATURE_KEYS
_FEATURE_BUCKET_COUNT = constants.FEATURE_BUCKET_COUNT
_LABEL_KEY = constants.LABEL_KEY
_transformed_name = constants.transformed_name
# 변환을 정의합니다.
def preprocessing_fn(inputs):
outputs = {}
# 이러한 기능들을 [0,1] 범위로 스케일링합니다.
for key in _NUMERIC_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.scale_to_0_1(
inputs[key])
# 이러한 기능들을 버킷으로 나눕니다.
for key in _BUCKET_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.bucketize(
inputs[key], _FEATURE_BUCKET_COUNT[key])
# 문자열을 어휘 사전의 인덱스로 변환합니다.
for key in _CATEGORICAL_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.compute_and_apply_vocabulary(inputs[key])
# 라벨 문자열을 인덱스로 변환합니다.
outputs[_transformed_name(_LABEL_KEY)] = tft.compute_and_apply_vocabulary(inputs[_LABEL_KEY])
return outputs
이 데모에서는 몇 가지 표준 스케일링 및 인코딩 함수를 사용했습니다. transform 라이브러리에는 실제로 다양한 함수가 포함되어 있습니다. 여기에서 살펴보세요.
이제 변환 과정을 보겠습니다. Transform 객체를 생성하고 example_gen 및 schema_gen 객체와 함께 우리가 만든 transform.py 파일의 경로를 전달합니다.
# TF 경고 메시지 무시
tf.get_logger().setLevel('ERROR')
# example_gen 및 schema_gen 객체로 Transform 구성 요소 인스턴스화
# transform 파일의 경로를 전달
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=os.path.abspath(_transform_module_file))
# 구성 요소 실행
context.run(transform)
실행하고 변환 부분이 완료되었습니다!
아래 이미지에 나타난 변환된 데이터를 살펴보세요.

그냥 scikit-learn 라이브러리나 pandas를 사용하는 것은 왜 아닌가요?
지금 이게 여러분의 질문인가요?
이 프로세스는 데이터 전처리를 원하는 개인을 위한 것이 아닙니다. 모델 훈련을 시작하고 싶은 사람들을 위한 것이 아닙니다. 이것은 대규모 데이터 (분산 처리를 요구하는 데이터)와 끊어질 여지가 없는 자동화된 프로덕션 파이프라인에 적용되어야 합니다.
변환을 적용한 후에 폴더 구조가 다음과 같이 보입니다
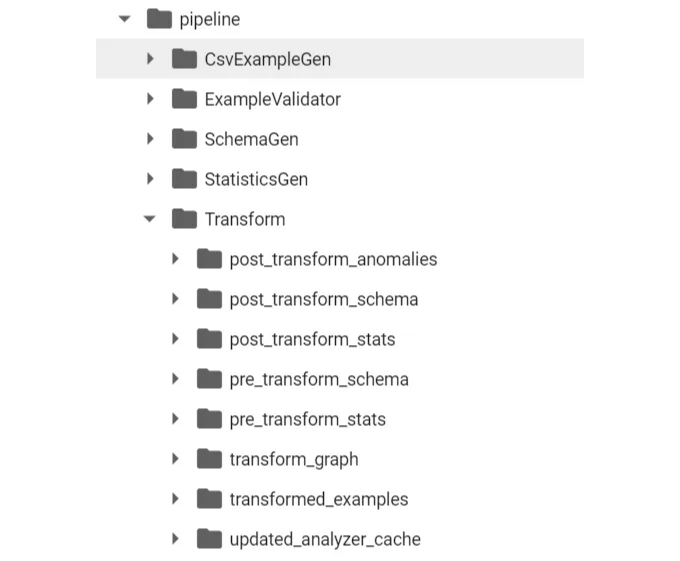
여기에는 변환 전후의 세부 내용이 포함되어 있습니다. 또한 변환 그래프도 만들어졌습니다.
우리는 tft.scale_to_0_1을 사용하여 숫자 특성을 스케일링했습니다. 이러한 함수는 전체 데이터를 분석해야 하는 세부 정보를 계산해야 합니다(예: 특성 내 평균, 최소값 및 최대값). 여러 기계에 분산된 데이터를 분석하여 이러한 세부 정보를 얻는 것은 성능이 많이 필요합니다(특히 여러 번 수행해야 하는 경우). 이러한 세부 사항은 한 번 계산되고 변환 그래프에 유지됩니다. 함수가 이러한 세부 정보를 필요로 할 때마다, 그것은 바로 변환 그래프에서 검색됩니다. 또한 학습 단계에서 생성된 변환을 직접 서빙 데이터에 적용하여 전처리 단계에서 일관성을 보장하는 데 도움이 됩니다.
Tensorflow Transform 라이브러리를 사용하는 또 다른 주요 장점은 모든 단계가 아티팩트로 기록되어 데이터 계보가 유지된다는 것입니다. 또한 데이터가 변경될 때 자동으로 데이터 버전 관리가 수행됩니다. 이로 인해 제품 환경에서의 실험, 배포 및 롤백이 쉬워집니다.
여기까지 입니다. 궁금한 점이 있으시면 댓글 섹션에 남겨주세요.
본문에 사용된 노트북 및 데이터 파일은 이 링크를 통해 내 GitHub 저장소에서 다운로드할 수 있습니다.
다음은 무엇일까요?
파이프라인 구성 요소를 더 잘 이해하기 위해 아래 글을 읽어보세요.
제 글을 읽어주셔서 감사합니다. 마음에 드셨다면 몇 개의 박수로 격려해 주시고, 만약 다른 쪽에 계신다면 의견란에 개선할 점을 알려주세요. 안녕히 가세요.
특별히 언급하지 않는 한, 모든 이미지는 저자가 찍은 것입니다.