소개
이 문서는 데이터를 처리하여 분석을 위해 데이터베이스를 채우는 데 사용되는 실시간 마이크로서비스 프로젝트에 대한 안내서입니다.
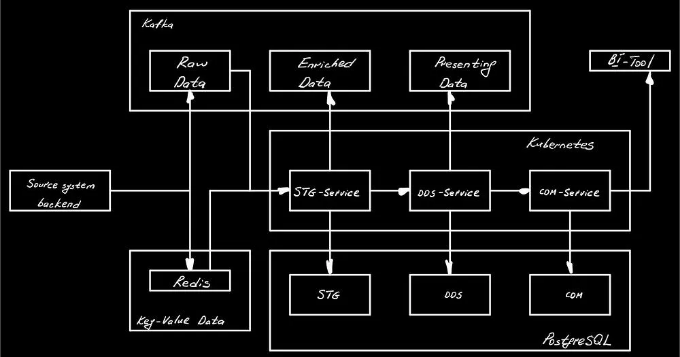
STG-Service
Redis 클라이언트
Redis와 상호 작용하기 위한 간단한 클라이언트입니다. 특정 키로 객체를 가져오거나 새 키-값 쌍을 설정할 수 있습니다:
import json
from typing import Dict
import redis
class RedisClient:
def __init__(self, host: str, port: int, password: str, cert_path: str) -> None:
self._client = redis.StrictRedis(
host=host,
port=port,
password=password,
ssl=True,
ssl_ca_certs=cert_path)
def set(self, k, v):
self._client.set(k, json.dumps(v))
def get(self, k) -> Dict:
obj: str = self._client.get(k)
return json.loads(obj)
Postgres 클라이언트
데이터베이스에 연결하는 것 외에도, 클라이언트는 하나의 컨텍스트 매니저의 일부로 여러 쿼리를 실행할 수 있는 기능을 제공하여 한 트랜잭션의 실행 명령을 커밋할 필요가 없어요 (나중에 사용 예제를 보게 될 거에요):
from contextlib import contextmanager
from typing import Generator
import psycopg2
class PgConnect:
def __init__(self, host: str, port: int, db_name: str, user: str, pw: str, sslmode: str = "require") -> None:
self.host = host
self.port = port
self.db_name = db_name
self.user = user
self.pw = pw
self.sslmode = sslmode
def url(self) -> str:
return """
host={host}
port={port}
dbname={db_name}
user={user}
password={pw}
target_session_attrs=read-write
sslmode={sslmode}
""".format(
host=self.host,
port=self.port,
db_name=self.db_name,
user=self.user,
pw=self.pw,
sslmode=self.sslmode)
@contextmanager
def connection(self) -> Generator:
keepalive_kwargs = {
"keepalives": 1,
"keepalives_idle": 30,
"keepalives_interval": 5,
"keepalives_count": 5,
}
conn = psycopg2.connect(self.url(), **keepalive_kwargs)
try:
yield conn
conn.commit()
except Exception as e:
conn.rollback()
raise e
finally:
conn.close()
카프카에서 메시지를 생성하고 사용하는 두 개의 별도 및 간단한 클라이언트:
import json
from typing import Dict, Optional
from confluent_kafka import Consumer, Producer
def error_callback(err):
print('Something went wrong: {}'.format(err))
class KafkaProducer:
def __init__(self, host: str, port: int, user: str, password: str, topic: str, cert_path: str) -> None:
params = {
'bootstrap.servers': f'{host}:{port}',
'security.protocol': 'SASL_SSL',
'ssl.ca.location': cert_path,
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': user,
'sasl.password': password,
'error_cb': error_callback,
}
self.topic = topic
self.p = Producer(params)
def produce(self, payload: Dict) -> None:
self.p.produce(self.topic, json.dumps(payload))
self.p.flush(10)
class KafkaConsumer:
def __init__(self,
host: str,
port: int,
user: str,
password: str,
topic: str,
group: str,
cert_path: str
) -> None:
params = {
'bootstrap.servers': f'{host}:{port}',
'security.protocol': 'SASL_SSL',
'ssl.ca.location': cert_path,
'sasl.mechanism': 'SCRAM-SHA-512',
'sasl.username': user,
'sasl.password': password,
'group.id': group, # '',
'auto.offset.reset': 'earliest',
'enable.auto.commit': False,
'error_cb': error_callback,
'debug': 'all',
'client.id': 'someclientkey'
}
self.topic = topic
self.c = Consumer(params)
self.c.subscribe([topic])
def consume(self, timeout: float = 3.0) -> Optional[Dict]:
msg = self.c.poll(timeout=timeout)
if not msg:
return None
if msg.error():
raise Exception(msg.error())
val = msg.value().decode()
return json.loads(val)
STG Schema
포스트그레스의 스테이징 레이어로, Kafka에서 나온 로우 메시지를 저장할 한 개의 테이블이 있을 것입니다. 이는 아래와 같이 정의되어 있습니다.
CREATE SCHEMA IF NOT EXISTS stg;
CREATE TABLE IF NOT EXISTS stg.order_events (
id SERIAL PRIMARY KEY,
object_id INTEGER NOT NULL UNIQUE,
object_type VARCHAR(20) NOT NULL,
sent_dttm TIMESTAMP NOT NULL,
payload JSON NOT NULL
);
그리고 이를 실행할 파이썬 함수는:
from lib.pg.pg_connect import PgConnect
def make_stg_migrations(db: PgConnect) -> None:
with db.connection() as conn:
with conn.cursor() as cur:
# STG 스키마의 SQL 정의 경로는 다를 수 있습니다.
cur.execute(open("stg_schema.sql", "r").read())
프로그램이 db.connection()으로 정의된 컨텍스트 매니저를 벗어나면 명시적으로 실행할 필요 없이 자동으로 커밋됩니다.
메시지 처리
먼저 소비된 카프카 메시지를 STG 포스트그레스 테이블(StgRepository)에 삽입한 다음, 레디스에서 레스토랑 데이터를 풍부하게하여 다른 카프카 클러스터(StgMessageProcessor)를 위한 출력 메시지를 구성해야 합니다.
from datetime import datetime
from lib.pg.pg_connect import PgConnect
class StgRepository:
def __init__(self, db: PgConnect) -> None:
self._db = db
def order_events_insert(self,
object_id: int,
object_type: str,
sent_dttm: datetime,
payload: str
) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute(
"""
INSERT INTO stg.order_events (object_id, object_type, sent_dttm, payload) VALUES (%(object_id)s, %(object_type)s, %(sent_dttm)s, %(payload)s)
ON CONFLICT (object_id)
DO UPDATE
SET object_type = EXCLUDED.object_type,
sent_dttm = EXCLUDED.sent_dttm,
payload = EXCLUDED.payload;
""",
{
'object_id': object_id,
'object_type': object_type,
'sent_dttm': sent_dttm,
'payload': payload
}
)
import json
from datetime import datetime
from logging import Logger
from lib.kafka_connect.kafka_connectors import KafkaConsumer, KafkaProducer
from lib.redis.redis_client import RedisClient
from stg_loader.repository.stg_repository import StgRepository
class StgMessageProcessor:
def __init__(self,
consumer: KafkaConsumer,
producer: KafkaProducer,
redis: RedisClient,
stg_repository: StgRepository,
logger: Logger) -> None:
self._logger = logger
self._consumer = consumer
self._producer = producer
self._redis = redis
self._stg_repository = stg_repository
self._batch_size = 100
def run(self) -> None:
self._logger.info(f"{datetime.utcnow()}: START")
for i in range(self._batch_size):
msg = self._consumer.consume()
if not msg:
continue
self._stg_repository.order_events_insert(object_id=msg["object_id"],
object_type=msg["object_type"],
sent_dttm=msg["sent_dttm"],
payload=json.dumps(msg["payload"]))
dst_msg = self._construct_output_message(msg)
self._producer.produce(dst_msg)
self._logger.info(f"{datetime.utcnow()}: FINISH")
def _construct_output_message(self, original_message: dict) -> dict:
restaurant_id = original_message["payload"]["restaurant"]["id"]
restaurant_data = self._redis.get(restaurant_id)
restaurant_name = restaurant_data["name"]
user_id = original_message["payload"]["user"]["id"]
user_data = self._redis.get(user_id)
user_name = user_data["name"]
user_login = user_data["login"]
order = original_message["payload"]
restaurant_menu = {p["_id"]: p for p in restaurant_data["menu"]}
products = {p["id"]: {**p, "category": restaurant_menu[p["id"]]["category"]} for p in order["order_items"]}
return {
"object_id": original_message["object_id"],
"object_type": original_message["object_type"],
"payload": {
"id": original_message["object_id"],
"date": order["date"],
"cost": order["cost"],
"payment": order["payment"],
"status": order["final_status"],
"restaurant": {
"restaurant_id": restaurant_id,
"restaurant_name": restaurant_name
},
"user": {
"user_id": user_id,
"user_name": user_name,
"user_login": user_login
},
"products": products
}
}
서비스 구성
소스/싱크 카프카, Redis 및 포스트그레스와 연결해야 합니다. 이것은 확실히 많은 구성이 필요하며 환경 변수를 사용해야 하므로 이를 별도의 클래스에서 수용할 것입니다:
import os
from lib.kafka_connect.kafka_connectors import KafkaConsumer, KafkaProducer
from lib.redis.redis_client import RedisClient
from lib.pg.pg_connect import PgConnect
from stg_loader.repository.stg_repository import StgRepository
class AppConfig:
CERTIFICATE_PATH = '/crt/YandexInternalRootCA.crt'
DEFAULT_JOB_INTERVAL = 25
def __init__(self) -> None:
self.kafka_host = str(os.getenv('KAFKA_HOST') or "")
self.kafka_port = int(str(os.getenv('KAFKA_PORT')) or 0)
self.kafka_consumer_username = str(os.getenv('KAFKA_CONSUMER_USERNAME') or "")
self.kafka_consumer_password = str(os.getenv('KAFKA_CONSUMER_PASSWORD') or "")
self.kafka_consumer_group = str(os.getenv('KAFKA_CONSUMER_GROUP') or "")
self.kafka_consumer_topic = str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
self.kafka_producer_username = str(os.getenv('KAFKA_PRODUCER_USERNAME') or "")
self.kafka_producer_password = str(os.getenv('KAFKA_PRODUCER_PASSWORD') or "")
self.kafka_producer_topic = str(os.getenv('KAFKA_DESTINATION_TOPIC') or "")
self.redis_host = str(os.getenv('REDIS_HOST') or "")
self.redis_port = int(str(os.getenv('REDIS_PORT')) or 0)
self.redis_password = str(os.getenv('REDIS_PASSWORD') or "")
self.pg_host = str(os.getenv('PG_HOST') or "")
self.pg_port = int(str(os.getenv('PG_PORT')) or 6432)
self.pg_db_name = str(os.getenv("PG_DB_NAME"))
self.pg_user = str(os.getenv('PG_USER') or "")
self.pg_password = str(os.getenv('PG_PASSWORD') or "")
def kafka_producer(self):
return KafkaProducer(
self.kafka_host,
self.kafka_port,
self.kafka_producer_username,
self.kafka_producer_password,
self.kafka_producer_topic,
self.CERTIFICATE_PATH
)
def kafka_consumer(self):
return KafkaConsumer(
self.kafka_host,
self.kafka_port,
self.kafka_consumer_username,
self.kafka_consumer_password,
self.kafka_consumer_topic,
self.kafka_consumer_group,
self.CERTIFICATE_PATH
)
def redis_client(self) -> RedisClient:
return RedisClient(
self.redis_host,
self.redis_port,
self.redis_password,
self.CERTIFICATE_PATH
)
def stg_loader(self) -> StgRepository:
db: PgConnect = PgConnect(
self.pg_host,
self.pg_port,
self.pg_db_name,
self.pg_user,
self.pg_password
)
return StgRepository(db)
def pg_client(self) -> PgConnect:
return PgConnect(
self.pg_host,
self.pg_port,
self.pg_db_name,
self.pg_user,
self.pg_password
)
STG Service 실행
StgMessageProcessor를 백그라운드 프로세스로 실행해야 합니다 (apscheduler 파이썬 모듈의 BackgroundScheduler를 사용할 것입니다) 그리고 건강 상태를 확인하는 간단한 API를 추가할 것입니다.
import os
import logging
from apscheduler.schedulers.background import BackgroundScheduler
from flask import Flask
from stg_loader.stg_message_processor_job import StgMessageProcessor
from app_config import AppConfig
from stg_migrations import make_stg_migrations
app = Flask(__name__)
# 서비스가 정상인지 확인할 수 있는 엔드포인트 생성
@app.get('/health')
def health():
return 'healthy'
if __name__ == '__main__':
app.logger.setLevel(logging.DEBUG)
config = AppConfig()
make_stg_migrations(config.pg_client())
proc = StgMessageProcessor(logger=app.logger,
consumer=config.kafka_consumer(),
producer=config.kafka_producer(),
redis=config.redis_client(),
stg_repository=config.stg_loader())
scheduler = BackgroundScheduler()
scheduler.add_job(func=proc.run, trigger="interval", seconds=config.DEFAULT_JOB_INTERVAL)
scheduler.start()
app.run(debug=True, host='0.0.0.0', use_reloader=False)
Dockerfile
스테이징 서비스는 코어크레이트 기반의 쿠버네티스 클러스터에서 실행될 예정이므로, 서비스를 도커 이미지로 만들어주어야 합니다.
FROM python:3.10
RUN apt-get update -y
# 컨테이너 내에서 confluent_kafka 파이썬 모듈이 작동되도록 필요합니다
RUN git clone https://github.com/edenhill/librdkafka && cd librdkafka && ./configure && make && make install && ldconfig
COPY . .
RUN pip install -r requirements.txt
# Kafka 클러스터에 안전한 연결을 위한 인증서 다운로드
RUN mkdir -p /crt
RUN wget "https://storage.yandexcloud.net/cloud-certs/CA.pem" --output-document /crt/YandexInternalRootCA.crt
RUN chmod 0600 /crt/YandexInternalRootCA.crt
WORKDIR /src
# 파이썬 임포트가 작동되도록 설정
ENV PYTHONPATH "${PYTHONPATH}:/src"
ENTRYPOINT ["python"]
CMD ["app.py"]
로컬 테스트를 위해 Docker Compose를 사용하여 스테이징 서비스를 실행할 수 있습니다.
version: "3.9"
services:
stg_service:
build:
context: .
network: host
image: stg_img:local
container_name: stg_container
environment:
FLASK_APP: ${STG_SERVICE_APP_NAME:-stg_service}
DEBUG: ${STG_SERVICE_DEBUG:-True}
KAFKA_HOST: ${KAFKA_HOST}
KAFKA_PORT: ${KAFKA_PORT}
KAFKA_CONSUMER_USERNAME: ${KAFKA_CONSUMER_USERNAME}
KAFKA_CONSUMER_PASSWORD: ${KAFKA_CONSUMER_PASSWORD}
KAFKA_CONSUMER_GROUP: ${KAFKA_CONSUMER_GROUP}
KAFKA_SOURCE_TOPIC: ${KAFKA_SOURCE_TOPIC}
KAFKA_DESTINATION_TOPIC: ${KAFKA_DESTINATION_TOPIC}
KAFKA_PRODUCER_USERNAME: ${KAFKA_PRODUCER_USERNAME}
KAFKA_PRODUCER_PASSWORD: ${KAFKA_PRODUCER_PASSWORD}
REDIS_HOST: ${REDIS_HOST}
REDIS_PORT: ${REDIS_PORT}
REDIS_PASSWORD: ${REDIS_PASSWORD}
PG_HOST: ${PG_HOST}
PG_PORT: ${PG_PORT}
PG_DB_NAME: ${PG_DB_NAME}
PG_USER: ${PG_USER}
PG_PASSWORD: ${PG_PASSWORD}
network_mode: "bridge"
ports:
- "5101:5000"
restart: unless-stopped
.env 파일:
KAFKA_HOST=******.mdb.yandexcloud.net
KAFKA_PORT=9091
KAFKA_CONSUMER_USERNAME=producer_consumer
KAFKA_CONSUMER_PASSWORD=******
KAFKA_CONSUMER_GROUP=test-consumer1
KAFKA_SOURCE_TOPIC=dds_input_topic
KAFKA_PRODUCER_USERNAME=producer_consumer
KAFKA_PRODUCER_PASSWORD=*******
KAFKA_DESTINATION_TOPIC=cdm_input_topic
REDIS_HOST=******.mdb.yandexcloud.net
REDIS_PORT=6380
REDIS_PASSWORD=******
PG_HOST=********.mdb.yandexcloud.net
PG_PORT=6432
PG_DB_NAME=sprint9dwh
PG_USER=yandex_pg
PG_PASSWORD=**********
HELM 차트
Chart.yaml 파일:
apiVersion: v2
name: first-service
description: 쿠버네티스용 헬름 차트
# 차트는 'application' 또는 'library' 차트 중 하나일 수 있습니다.
#
# Application 차트는 템플릿 모음이며 버전이 지정된 아카이브로 패키지화하여 배포될 수 있습니다.
#
# Library 차트는 차트 개발자를 위한 유용한 유틸리티 또는 함수를 제공합니다. Application 차트의 종속성으로 포함되어
# 렌더링 파이프라인에 이러한 유틸리티와 함수를 삽입합니다. Library 차트는 템플릿을 정의하지 않으며 따라서 배포될 수 없습니다.
type: application
# 이것은 차트 버전입니다. 이 번호는 차트 및 해당 템플릿에 변경이 있을 때마다 증가해야 합니다.
# 버전은 Semantic Versioning (https://semver.org/)을 따르는 것으로 예상됩니다.
version: 0.1.0
# 이것은 배포되는 애플리케이션의 버전 번호입니다. 이 버전 번호는 애플리케이션에 변경이 있는 경우마다 증가해야 합니다.
# 버전은 Semantic Versioning을 따르지 않습니다. 애플리케이션이 사용 중인 버전을 반영해야 합니다.
# 따옴표와 함께 사용하는 것이 권장됩니다.
appVersion: "1.16.0"
values.yaml 파일:
# 앱의 기본 값.
# 이것은 YAML 형식의 파일입니다.
# 템플릿에 전달할 변수를 선언합니다.
replicaCount: 3
image:
# 컨테이너 레지스트리에 대한 링크. 야н덱스 클라우드에서 실행할 것입니다.
repository: cr.yandex/crpr6naar69761ehm0bp/stg_service
pullPolicy: IfNotPresent
# 기본적으로 차트 appVersion인 이미지 태그를 덮어씁니다.
tag: "v2022-12-13-r1"
containerPort: 5000
config:
KAFKA_HOST: rc1a-hins1kp5qsfnsob3.mdb.yandexcloud.net
KAFKA_PORT: "9091"
KAFKA_CONSUMER_USERNAME: producer_consumer
KAFKA_CONSUMER_PASSWORD: "*****"
KAFKA_CONSUMER_GROUP: test-consumer1
KAFKA_SOURCE_TOPIC: order-service_orders
KAFKA_PRODUCER_USERNAME: producer_consumer
KAFKA_PRODUCER_PASSWORD: "*****"
KAFKA_DESTINATION_TOPIC: dds_topic_name
REDIS_HOST: c-c9qeltiiu2rkcr6v9net.rw.mdb.yandexcloud.net
REDIS_PORT: "6380"
REDIS_PASSWORD: "*****"
PG_HOST: rc1b-4olk4uzgdrdte114.mdb.yandexcloud.net
PG_PORT: "6432"
PG_DB_NAME: sprint9dwh
PG_USER: yandex_pg
PG_PASSWORD: "*****"
imagePullSecrets: []
nameOverride: ""
fullnameOverride: ""
podAnnotations: {}
resources:
# 일반적으로 기본 리소스를 지정하지 않고 사용자의 명시적인 선택으로 유지하는 것을 권장합니다.
# 이것은 Minikube와 같은 리소스가 적은 환경에서 차트 실행 기회를 높이기도 합니다.
# 리소스를 지정하려면 아래 줄 주석 처리를 해제하고 필요에 맞게 조정한 다음 'resources:' 뒤의 중괄호를 제거하세요.
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
templates/configmap.yaml은 우리 서비스의 구성을 저장하는 k8s 엔터티입니다. values.yaml 파일의 config 블록에서 모든 키-값 쌍을 가져올 것입니다:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ include "app.fullname" . }}-config
labels:
{{- include "app.labels" . | nindent 4 }}
{{- with .Values.config }}
data:
{{- toYaml . | nindent 2 }}
{{- end }}
templates/deployment.yaml 파일
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels" . | nindent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
{{- include "app.selectorLabels" . | nindent 6 }}
template:
metadata:
{{- with .Values.podAnnotations }}
annotations:
{{- toYaml . | nindent 8 }}
{{- end }}
labels:
{{- include "app.selectorLabels" . | nindent 8 }}
spec:
{{- with .Values.imagePullSecrets }}
imagePullSecrets:
{{- toYaml . | nindent 8 }}
{{- end }}
containers:
- name: {{ .Chart.Name }}
securityContext:
{{- toYaml .Values.securityContext | nindent 12 }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
envFrom:
- configMapRef:
name: {{ include "app.fullname" . }}-config
ports:
- name: http
containerPort: {{ .Values.containerPort }}
protocol: TCP
resources:
{{- toYaml .Values.resources | nindent 12 }}
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
STG-Service의 소스 코드는 여기에서 찾을 수 있어요.
# DDS-Service
STG-Service 이후의 모든 것은 실제로 매우 쉬워집니다. 다른 서비스들도 거의 동일한 구조를 사용하기 때문이죠. DDS-Service의 경우, 모든 클라이언트 정의가 동일합니다. Dockerfile, Docker Compose 및 HELM Chart는 거의 동일합니다. 여기에서 소스 코드를 확인할 수 있어요.
가장 큰 차이점은 데이터 모델링 방식에 있습니다 (Data Vault 2.0을 사용합니다):
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
CREATE SCHEMA IF NOT EXISTS dds;
-- 데이터 보트 --
-- 허브 --
CREATE TABLE IF NOT EXISTS dds.h_user (
h_user_pk UUID PRIMARY KEY,
user_id VARCHAR NOT NULL UNIQUE,
load_dt TIMESTAMP NOT NULL,
load_src VARCHAR NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.h_product (
h_product_pk UUID PRIMARY KEY,
product_id VARCHAR NOT NULL UNIQUE,
load_dt TIMESTAMP NOT NULL,
load_src VARCHAR NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.h_category (
h_category_pk UUID PRIMARY KEY,
category_name VARCHAR NOT NULL UNIQUE,
load_dt TIMESTAMP NOT NULL,
load_src VARCHAR NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.h_restaurant (
h_restaurant_pk UUID PRIMARY KEY,
restaurant_id VARCHAR NOT NULL UNIQUE,
load_dt TIMESTAMP NOT NULL,
load_src VARCHAR NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.h_order (
h_order_pk UUID PRIMARY KEY,
order_id INTEGER NOT NULL UNIQUE,
order_dt TIMESTAMP NOT NULL,
load_dt TIMESTAMP NOT NULL,
load_src VARCHAR NOT NULL
);
-- 훗들 --
CREATE TABLE IF NOT EXISTS dds.s_user_names (
hk_user_names_pk UUID PRIMARY KEY,
h_user_pk UUID NOT NULL UNIQUE REFERENCES dds.h_user (h_user_pk),
username VARCHAR NOT NULL,
userlogin VARCHAR NOT NULL,
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.s_product_names (
hk_product_names_pk UUID PRIMARY KEY,
h_product_pk UUID NOT NULL UNIQUE REFERENCES dds.h_product (h_product_pk),
name VARCHAR NOT NULL,
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.s_restaurant_names (
hk_restaurant_names_pk UUID PRIMARY KEY,
h_restaurant_pk UUID NOT NULL UNIQUE REFERENCES dds.h_restaurant (h_restaurant_pk),
name VARCHAR NOT NULL,
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.s_order_cost (
hk_order_cost_pk UUID PRIMARY KEY,
h_order_pk UUID NOT NULL UNIQUE REFERENCES dds.h_order (h_order_pk),
cost DECIMAL(19, 5) NOT NULL,
payment DECIMAL(19, 5) NOT NULL,
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.s_order_status (
hk_order_status_pk UUID PRIMARY KEY,
h_order_pk UUID NOT NULL UNIQUE REFERENCES dds.h_order (h_order_pk),
status VARCHAR NOT NULL,
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
-- 링크 --
CREATE TABLE IF NOT EXISTS dds.l_order_product (
hk_order_product_pk UUID PRIMARY KEY,
h_order_pk UUID NOT NULL REFERENCES dds.h_order (h_order_pk),
h_product_pk UUID NOT NULL REFERENCES dds.h_product (h_product_pk),
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.l_product_restaurant (
hk_product_restaurant_pk UUID PRIMARY KEY,
h_restaurant_pk UUID NOT NULL REFERENCES dds.h_restaurant (h_restaurant_pk),
h_product_pk UUID NOT NULL REFERENCES dds.h_product (h_product_pk),
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.l_product_category (
hk_product_category_pk UUID PRIMARY KEY,
h_category_pk UUID NOT NULL REFERENCES dds.h_category (h_category_pk),
h_product_pk UUID NOT NULL REFERENCES dds.h_product (h_product_pk),
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS dds.l_order_user (
hk_order_user_pk UUID PRIMARY KEY,
h_order_pk UUID NOT NULL REFERENCES dds.h_order (h_order_pk),
h_user_pk UUID NOT NULL REFERENCES dds.h_user (h_user_pk),
load_src VARCHAR NOT NULL,
load_dt TIMESTAMP NOT NULL
);
우리 DDS-Service의 소스 Kafka 메시지는 STG-Service의 출력 메시지입니다. 또 다른 차이점은 Postgres에 이러한 메시지를 저장하는 방식에 있습니다. 데이터 보트 모델을 사용하므로 약간 복잡해집니다:
import os
import uuid
from datetime import datetime
from lib.pg.pg_connect import PgConnect
from psycopg2.extras import execute_batch
class DdsRepository:
def __init__(self, db: PgConnect) -> None:
self._db = db
self._batch_size = 20
def h_user_insert(self, user_id: str) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute("""
INSERT INTO dds.h_user (h_user_pk, user_id, load_dt, load_src) VALUES (%(h_user_pk)s, %(user_id)s, %(load_dt)s, %(load_src)s)
ON CONFLICT (user_id)
DO NOTHING;
""",
{
"h_user_pk": str(uuid.uuid4()),
"user_id": user_id,
"load_dt": datetime.now(),
"load_src": str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
})
def s_user_names_insert(self, user_id: str, username: str, userlogin: str) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"SELECT h_user_pk FROM dds.h_user WHERE user_id = '{user_id}'")
h_user_pk = cur.fetchone()[0]
cur.execute("""
INSERT INTO dds.s_user_names (hk_user_names_pk, h_user_pk, username, userlogin, load_dt, load_src) VALUES (%(hk_user_names_pk)s, %(h_user_pk)s, %(username)s, %(userlogin)s, %(load_dt)s, %(load_src)s)
ON CONFLICT (h_user_pk)
DO NOTHING;
""",
{
"hk_user_names_pk": str(uuid.uuid4()),
"h_user_pk": h_user_pk,
"username": username,
"userlogin": userlogin,
"load_dt": datetime.now(),
"load_src": str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
})
def h_order_insert(self, order_id: str, order_dt: datetime) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute("""
INSERT INTO dds.h_order (h_order_pk, order_id, order_dt, load_dt, load_src) VALUES (%(h_order_pk)s, %(order_id)s, %(order_dt)s, %(load_dt)s, %(load_src)s)
ON CONFLICT (order_id)
DO NOTHING;
""",
{
"h_order_pk": str(uuid.uuid4()),
"order_id": order_id,
"order_dt": order_dt,
"load_dt": datetime.now(),
"load_src": str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
})
def s_order_cost_insert(self, order_id: str, cost: float, payment: float) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"SELECT h_order_pk FROM dds.h_order WHERE order_id = '{order_id}'")
h_order_pk = cur.fetchone()[0]
cur.execute("""
INSERT INTO dds.s_order_cost (hk_order_cost_pk, h_order_pk, cost, payment, load_dt, load_src) VALUES (%(hk_order_cost_pk)s, %(h_order_pk)s, %(cost)s, %(payment)s, %(load_dt)s, %(load_src)s)
ON CONFLICT (h_order_pk)
DO UPDATE SET cost = EXCLUDED.cost,
payment = EXCLUDED.payment;
""",
{
"hk_order_cost_pk": str(uuid.uuid4()),
"h_order_pk": h_order_pk,
"cost": cost,
"payment": payment,
"load_dt": datetime.now(),
"load_src": str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
})
def s_order_status_insert(self, order_id: str, status: str) -> None:
with self._db.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"SELECT h_order_pk FROM dds.h_order WHERE order_id = '{order_id}'")
h_order_pk = cur.fetchone()[0]
cur.execute("""
INSERT INTO dds.s_order_status (hk_order_status_pk, h_order_pk, status, load_dt, load_src) VALUES (%(hk_order_status_pk)s, %(h_order_pk)s, %(status)s, %(load_dt)s, %(load_src)s)
ON CONFLICT (h_order_pk)
DO UPDATE SET status=EXCLUDED.status;
""",
{
"hk_order_status_pk": str(uuid.uuid4()),
"h_order_pk": h_order_pk,
"status": status,
"load_dt": datetime.now(),
"load_src": str(os.getenv('KAFKA_SOURCE_TOPIC') or "")
})
def l_order_user_insert(self, user_id: str, order_id:
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
우리는 수신 메시지를 HUB, SATELLITE 및 LINK로 분할합니다 - 이는 우리 데이터 모델의 주요 개체입니다. 또한, 마지막 단계로, 메시지를 출력 Kafka 클러스터로 준비하여 다음 다운스트림 서비스에 전달합니다.
app.py 파일은 기본적으로 동일합니다: 서비스를 백그라운드 작업으로 실행하고 서비스의 상태를 확인하기 위한 간단한 API를 생성합니다.
# CDM-Service
다른 서비스들과 유사하게 작동하며 여기에서 확인할 수 있습니다.
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
# 스택아데믹 🎓
끝까지 읽어주셔서 감사합니다. 떠나시기 전에:
- 작가를 클랩하고 팔로우해주시면 감사하겠습니다! 👏
- 저희를 팔로우해주세요: X | LinkedIn | YouTube | Discord
- 저희 다른 플랫폼도 방문해주세요: In Plain English | CoFeed | Differ
- 스택아데믹닷컴에서 더 많은 콘텐츠를 만나보세요