아마 수많은 기사들을 보면, 파이썬에서 for-loop 대신 리스트 컴프리헨션을 사용하는 것을 권장하는 내용이 많다는 것을 이미 알아차렸을 것 같아요. 저도 많이 봤어요. 그런데 놀랍게도 그 이유에 대해 설명한 기사는 거의 찾아보기 힘들었죠.
"파이썬 다운"이라거나 "가독성"과 같은 이유들만으로는 제가 같은 사람들을 쉽게 설득할 수 없을 거에요. 이런 "이유"들은 실제로는 파이썬 초보자들에게 잘못된 인상을 줄 수 있어요. 즉, 파이썬 리스트 컴프리헨션이 단순히 문법적 설탕에 불과하다는 거죠.
사실, 리스트 컴프리헨션은 파이썬에서 큰 최적화 중 하나에요. 이 기사에서는 이러한 메커니즘에 대해 심층적으로 살펴볼 거에요. 아래 질문들에 대한 답을 얻을 수 있습니다.
- 파이썬의 리스트 컴프리헨션은 무엇인가요?
- 왜 리스트 컴프리헨션의 성능이 일반적으로 for-loop보다 우수한가요?
- 언제 리스트 컴프리헨션을 사용해서는 안 되나요?
1. 간단한 성능 비교

우리는 간단한 프로그램을 작성할 것이다. 먼저 for 루프와 리스트 컴프리헨션을 사용한 방법으로 각각의 성능을 비교해보자.
factor = 2
results = []
for i in range(100):
results.append(i * factor)
위 코드는 100번 실행되는 for 루프를 정의합니다. range(100) 함수는 100개의 정수를 생성하고 각각은 요소와 곱해집니다. 이전에 정의된 요소는 2입니다.
이제 리스트 컴프리헨션 버전을 살펴봅시다.
factor = 2
results = [i * factor for i in range(100)]
이 예제에서는 훨씬 더 쉽고 가독성이 좋습니다. 이 두 개의 동일한 코드 스니펫을 실행해보고 성능을 비교해봅시다.

결과는 리스트 컴프리헨션이 일반 for-loop보다 거의 2배 빠르다는 것을 보여줬어.
놀라운 건 아무것도 없어, 많은 기사들이 이미 말해줬던 내용이야. 하지만, 이 기사에서는 리스트 컴프리헨션이 왜 더 빠른지에 대해 집중적으로 다루고 있고, 내부에서 어떤 주요 차이가 있는지에 대해 논의할 거야.
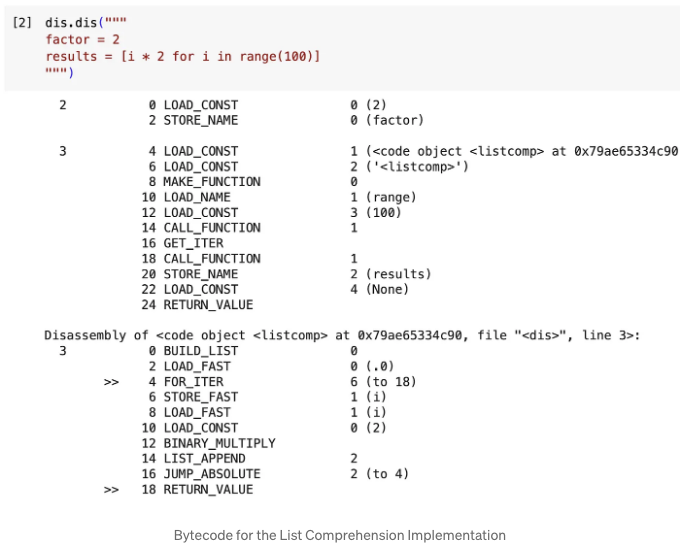
이 기사의 나머지 내용을 설명할 수 있는 모든 설명의 근거와 기준을 얻기 위해, 위의 두 구현, 즉 for-loop와 리스트 컴프리헨션의 bytecode를 얻기 위해 Python 내장 dis 모듈을 사용해보자.
import dis
dis.dis("""
factor = 2
results = []
for i in range(100):
results.append(i * factor)
""")
dis.dis("""
factor = 2
results = [i * 2 for i in range(100)]
""")
실행 결과는 다음과 같습니다. 바이트 코드를 이해할 필요는 없습니다. 단지 바이트 코드의 "작업"은 "운영 코드" 또는 간단히 "opcode"라고 불립니다. 나중에 해당 내용을 참조하겠습니다.

2. 전역 변수 대 로컬 변수

가장 큰 차이점은 변수의 범위입니다. 위의 바이트 코드에서 다음과 같이 나타납니다.
- for 루프의 LOAD_NAME 대 리스트 함축의 LOAD_FAST
- for 루프의 STORE_NAME 대 리스트 함축의 STORE_FAST
확실하게 말씀드리자면, for-loop 버전의 변수 i는 전역 범위에 있지만, 리스트 컴프리헨션의 변수 i는 지역 범위에 있어 실행 중에만 존재합니다.
변수의 범위(scopes)를 어떻게 확인할까요?
Python, Jupyter 또는 Google Colab과 같은 노트북 환경에서 이를 쉽게 확인할 수 있습니다. 새로운 세션을 시작한 후에 for-loop 버전을 실행한 다음 %whos 매직 명령어를 실행하면 현재 세션에 정의된 모든 사용자 변수가 나열됩니다.
factor = 2
results = []
for i in range(100):
results.append(i * factor)
%whos
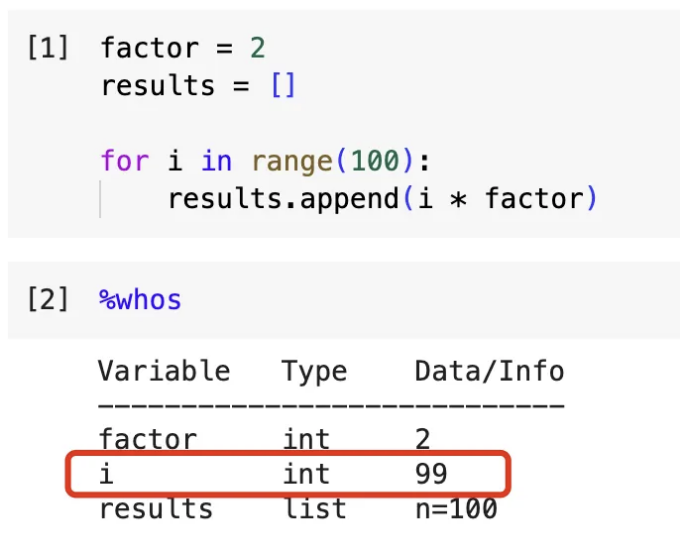
여기에는 for 루프가 끝난 후에도 변수 i가 여전히 남아 있는 것을 보여줍니다. 지금 global() 메소드를 실행하면 거기에도 변수 i를 찾을 수 있습니다.
그러나 세션을 재시작하고 리스트 내포를 실행하면 변수 i가 표시되지 않습니다.

이는 변수 i가 리스트 내포 구현에서 로컬 변수임을 증명했습니다.
왜 성능이 다를까요?
작업이 전역 네임스페이스에 있는 변수에 액세스해야 할 때, 전역 네임스페이스의 모든 객체 목록을 통과해야 합니다. 전역 네임스페이스에 무엇이 있는지 궁금하다면 세션에서 globals() 메서드를 실행해 보세요.
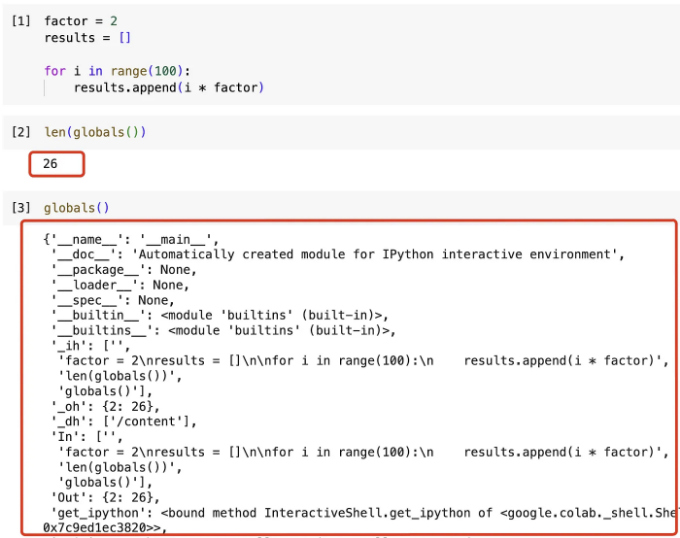
내 경우에는 Google Colab에서 새 세션을 시작했습니다. for 루프를 실행한 후 전역 네임스페이스 사전에 이미 26개의 객체가 있습니다. 더 복잡한 Python 애플리케이션을 실행한다고 상상해보면, 성능이 더 나빠질 수도 있습니다.
반면에 "로컬 변수"는 어떤가요?
안타깝게도, 리스트 내포에서 로컬 변수를 실행 중에 보여주는 것은 쉽지 않습니다. 따라서 간단한 함수를 사용하여 설명해보겠습니다. 함수 내부에 print() 메서드를 추가할 수 있기 때문이죠.
def my_function(x, y):
z = x + y
print("로컬 변수:", locals())
return z
my_function(1, 2)
아래 예시에서 x, y 및 z는 지역 변수입니다. 컴파일 시간에는 모든 지역 변수를 보유할 배열이 생성되며 각 변수에 고정된 인덱스가 지정됩니다. 개념적으로, 지역 변수 배열은 다음과 같이 나타낼 수 있습니다:
- x는 인덱스 0에 있음
- y는 인덱스 1에 있음
- z는 인덱스 2에 있음
따라서 함수(리스트 컴프리헨션)가 지역 변수에 액세스해야 할 때는 해당 인덱스를 사용합니다. 따라서 전역 네임스페이스에서 검색하는 것과 비교했을 때 훨씬 효율적입니다.
변수 대비 상수
변수 i를 제외하고 또 하나의 최적화는 로컬 변수 때문에 발생하고 있습니다.
변수 요소에 주의해주세요. 실제로, 요소 변수를 리스트 내포 밖에서 정의했지만, 그것은 로컬 상수로 리스트 내포에 로드될 것입니다.

위의 바이트 코드에서. 변수 factor를 모든 루프에서 전역 변수로 로드해야 합니다.

그러나 리스트 컴프리헨션에서는 컴파일러가 factor의 값을 변경할 수 없는 상수로 로드하고 지역 범위에 유지해도 충분히 안전합니다. 따라서 전역 네임스페이스에서 변수를 검색할 필요가 없습니다.
물론, 이것은 리스트 컴프리헨션의 성능에 기여하는 다른 요소입니다.
3. 일반 메소드 vs 최적화된 메소드

또 다른 주요한 차이점은 append() 메소드에서 나타납니다. 두 가지 구현 방법의 단계를 보여드리겠습니다.
for 루프 버전에서:
- LOAD_METHOD은 리스트 객체 결과에서 append() 메서드를 로드합니다.
- LOAD_NAME은 변수 i를 로드합니다.
- LOAD_NAME은 변수 factor를 로드합니다.
- BINARY_MULTIPLY는 수학 연산을 수행합니다.
- CALL_METHOD은 append() 메서드를 호출하여 실행하고, 즉 결과를 결과 목록에 추가합니다.
리스트 컴프리헨션 버전에서:
- LOAD_FAST는 로컬 변수에서 변수 i를 로드합니다.
- LOAD_CONST는 변수 factor의 값인 상수 2를 로드합니다.
- BINARY_MULTIPLY는 수학 연산을 수행합니다.
- LIST_APPEND는 결과를 로컬 변수에서도 있는 목록에 추가합니다.
리스트 컴프리헨션 버전의 성능이 더 우수한 이유는 단순히 한 단계가 덜 있기 때문만이 아니라 내부적인 메커니즘 때문입니다.
LOAD_METHOD과 LIST_APPEND가 왜 다른가요?
우리는 결과 목록에서 append() 메서드를 호출합니다. 즉, results.append(...)입니다. 이를 실행할 때 Python 런타임은 List 객체 공간에서 메서드를 찾아야 합니다. 이는 객체에 대해 dir() 메서드를 호출하는 것과 거의 동일합니다.
print(dir(results));
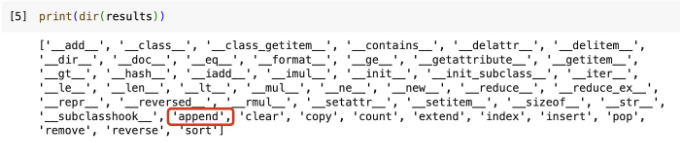
당연히 이 "검색" 작업은 모든 루프에서 발생할 것입니다.
그러나 리스트 내포 버전에서 결과 리스트도 로컬 변수입니다. 이 메커니즘은 리스트가 생성될 것이고, 리스트 내포 실행과 함께 만들어진다는 것입니다.
비유를 들어보겠습니다. 작은 항목을 큰 컨테이너에 정리하는 것으로 상상해 보겠습니다.
for 루프 버전은 append() 메서드를 사용하는 것이 매번 우리가 항목과 상자를 다른 사람에게 주고, 이 사람이 항목을 넣은 후에 우리에게 컨테이너를 다시 돌려주는 것처럼합니다.
리스트 내포 버전을 사용하면 다른 사람의 도움 없이 항목을 컨테이너에 넣을 수 있어요. 따라서 성능도 훨씬 좋아요.
4. 리스트 내포를 사용해서는 안 되는 경우

물론, 리스트 내포는 남용해서는 안 돼요. 다시 말해, 사용은 가능하지만 특정 상황에서는 사용해서는 안 되는 경우가 있어요.
한 가지 전형적인 시나리오는 필터 조건이 너무 복잡하다는 것입니다. 다음 예를 고려해보세요. 학생들의 이름과 시험 점수가 들어있는 튜플 목록이 있습니다.
students = [("Alice", 85), ("Bob", 95), ("Cindy", 100), ("David", 65), ("Eva", 70)];
그런 다음, 특정 조건에 따라 이름을 필터링하려고 합니다. 점수는 80보다 커야하고, 이름은 "A" 또는 "C"로 시작해야 합니다. 아래는 for 루프 구현입니다.
filtered_names = []
for name, score in students:
if score > 80 and name.startswith(("A", "C")):
filtered_names.append(name)
여기에 리스트 컴프리헨션 구현방법이 있습니다.
filtered_names = [name for name, score in students if score > 80 and name.startswith(("A", "C"))]
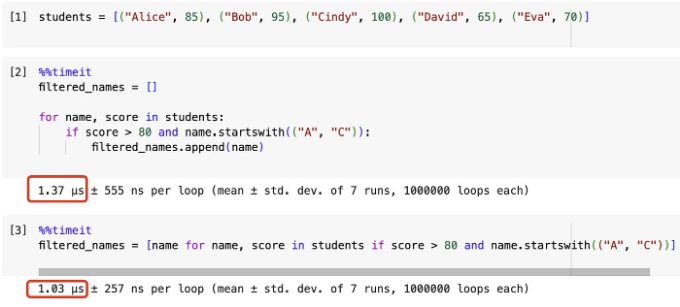
음, 리스트 컴프리헨션의 성능은 여전히 for 루프보다 조금 더 나은 편이에요. 그러나 복잡한 조건 때문에 리스트 컴프리헨션은 가독성이 많이 떨어지기 시작했다고 말씀드려야 할 것 같아요.
가독성과 디버깅 유연성을 희생해서 성능을 조금 향상시키는 것이 매우 주관적일 수 있습니다. 결정은 여러분에게 맡기겠습니다. :)
요약

이 글에서는 리스트 컴프리헨션의 성능이 일반 for-loop보다 우수한 이유에 대해 소개했습니다. 그것이 단순히 구문적인 설탕이 아니라 성능 최적화임을 증명했습니다.
두 구현의 바이트 코드를 표시하여 증거가 발굴되었습니다. 주요 차이점은 지역 vs. 전역 네임스페이스와 일반 메서드 vs. 최적화된 메서드입니다.
물론, 모든 시나리오에서 리스트 내포를 사용하는 것이 권장되지는 않습니다. 예를 들어, 조건이 매우 많은 계층과 보다 복잡한 조건을 갖는 경우입니다. 여전히 리스트 내포를 사용할 가치가 있는지 고려해야 합니다.