코딩 여정을 시작할 때 파이썬 세계에 뛰어 들어가면서 약간의 어려움을 겪었어요. 코딩의 기본은 이해했지만, 내 코드를 효율적으로 만드는 방법을 알아내는 것은 퍼즐을 푸는 것처럼 어려웠죠. 예전에는 종종 파이썬의 신이 이끌어 준다는 말을 기억해요 — 정말 좋은 조언이긴 하지만, 내 생각에는 너무 추상적이었어요. 더 구체적인 예시가 필요했고, 그래서 이 가이드를 만들게 되었답니다.
재미있게도, ChatGPT 시대 이후에 코딩을 배우기 시작한 사람들이 어떻게 코딩을 접근하는지에 변화를 주목했어요. ChatGPT 시대에 배운 사람들은 오류 수정과 디버깅에 뛰어나는 것 같아요. 그 반면, GPT 이전에 코딩한 사람들은 답을 분석하고 Stack Overflow나 문서와 같은 자료를 활용하는 데 능숙해요 — 아마도 조금의 복사-붙여넣기 기술도 있겠죠! ;)

사진: Kelly Sikkema 님의 Unsplash
저는 Python으로 코딩을 하는 7년 간에 중요한 차이를 만들어 준 몇 가지 개념을 경험해 왔습니다. 이 글에서는 제 경험을 바탕으로 27가지 직관적인 코딩 팁을 공유하고 싶습니다. 이러한 팁들은 제 코딩 속도를 높이는 데 도움이 되었을 뿐만 아니라, 제 코드를 더 깔끔하고 이해하기 쉽게 만들었습니다. 이러한 소중한 팁을 나누는 동안 함께해 주세요. 혹시 당신의 코딩 여정과 맞닿는 팁을 발견할 수도 있을 것입니다!
1. F-Strings: 동적 문자열 포맷팅
장점:
- 간결하고 읽기 쉬운 구문.
- 문자열 내부에 쉽게 표현식을 넣을 수 있습니다.
단점:
- Python 3.6 이상에서만 사용 가능합니다.
- 보안 취약점에 주의해야 합니다; SQL Injection
예시:
name = "John"
age = 25
message = f"My name is {name}, and I am {age} years old."
2. 데코레이터: 기능 동적으로 개선하기
장점:
- 함수의 동작을 확장하는 깔끔한 방법을 제공합니다.
- 코드 재사용성을 향상시킵니다.
Cons:
- 데코레이터를 과도하게 사용하면 코드를 이해하기 어렵게 만들 수 있습니다.
예시:
import time
def timer_decorator(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} executed in {end_time - start_time} seconds")
return result
return wrapper
@timer_decorator
def example_function():
# 함수 로직이 여기에 있습니다
3. Python 숙련도 향상을 위한 help() 함수 활용
장점:
- 즉각적인 문서화: 코드 내에서 Python 객체, 모듈 또는 함수에 대한 문서를 빠르게 참조할 수 있습니다.
- 대화식 학습: Python 인터프리터나 스크립트에서 직접 생소한 모듈이나 함수를 탐색하고 학습하기에 이상적입니다.
단점:
- 제한된 정보: help()를 통해 제공되는 정보는 때로 간결할 수 있으며, 복잡한 주제에 대해서는 보다 자세한 문서가 필요할 수 있습니다. help()의 효과는 코드 내 docstrings의 존재와 품질에 따라 달라집니다.
예시:
# 예시: help() 함수 사용하기
def calculate_square(number):
"""
주어진 숫자의 제곱을 계산합니다.매개변수:
- number (int): 입력 숫자.
반환:
- int: 입력 숫자의 제곱 값.
"""
return number ** 2
# calculate_square 함수에 대한 도움말 얻기
help(calculate_square)
4. List Comprehensions: 간결한 리스트 생성
장점:
- 목록 생성 로직을 간결하게 만들어 가독성을 향상시킵니다.
- 기존 루프와 비교하여 성능을 향상시키는 경우가 많습니다.
단점:
- 특히 복잡한 로직에서는 가독성을 높이기 위해 중첩된 리스트 컴프리헨션을 피해야 합니다.
예시:
# 범위 내에서 짝수의 제곱값 찾기
squares = [x**2 for x in range(10) if x % 2 == 0]
5. 루프에서의 else 절
장점:
- 루프가 break 문이 없이 자연스럽게 완료될 때 코드를 실행할 수 있습니다.
- 특정 동작이 성공적인 루프를 따라야 하는 시나리오에 이상적입니다.
단점:
- 종종 간과되거나 오해되어 잠재적인 논리 오류로 이어질 수 있습니다.
예시:
# else 절을 사용하여 소수 찾기
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
break
else:
print(n, "은(는) 소수입니다.")
6. 람다 함수: 빠르고 익명의 함수
장점:
- 간단한 함수를 간결하게 한 줄에 작성할 수 있습니다.
- 형식적인 함수 정의가 필요하지 않습니다.
단점:
- 단일 표현식에 한정되어 복잡한 논리에 적합하지 않음.
- 과다 사용 시 코드 가독성을 떨어뜨릴 수 있음.
예시:
# 람다 함수를 사용하여 두 숫자 더하기
add_numbers = lambda x, y: x + y
result = add_numbers(3, 5)
7. enumerate 및 zip을 활용한 파이썬적인 Iteration
팁: enumerate()와 zip() 함수를 활용하여 시퀀스를 더 파이썬스럽게 반복하세요.
장점:
- enumerate(): 인덱스와 값 모두를 사용하여 반복을 간단하게 만듭니다.
- zip(): 여러 리스트에 대해 병렬 반복을 용이하게 합니다.
Cons:
- 중요한 단점은 없음; 코드 가독성과 간결함을 향상시킴.
예시:
# enumerate와 zip을 사용한 Pythonic한 반복
names = ["Alice", "Bob", "Charlie"]
ages = [25, 30, 22]
# 인덱스와 값을 함께 사용하는 Enumerate
for index, name in enumerate(names):
print(f"사람 {index + 1}: {name}")
# 병렬 반복을 위한 Zip
for name, age in zip(names, ages):
print(f"{name}은(는) {age}살입니다.")
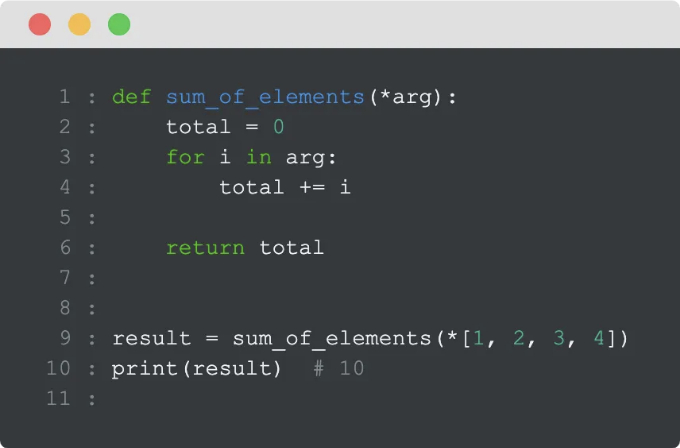
8. *args 와 **kwargs: 유연한 함수 인수
장점:
- 가변 개수의 인수를 처리하는 데 이상적입니다.
- 다양한 함수와 래퍼를 생성할 수 있습니다.
단점:
- 기능 시그니처가 모든 가능한 인수를 나타내지 않을 수 있으므로 주의 깊은 문서화가 필요합니다.
예시:
# 주어진 모든 인수를 곱하는 함수
def multiply(*args):
result = 1
for num in args:
result *= num
return result
9. try 및 except를 사용한 안정적인 오류 처리
장점:
- 오류 내구성: 예기치 못한 오류로 인해 프로그램이 충돌하는 것을 방지합니다.
- 향상된 디버깅: 무엇이 잘못되었는지에 대한 통찰을 제공하여 효과적인 디버깅을 돕습니다.
- 사용자 친화적: 사용자에게 구체적인 오류 메시지를 전달하여 더 나은 경험을 제공합니다.
단점:
- 오버헤드: try와 except를 사용할 경우 일부 경우에 약간의 성능 오버헤드가 발생할 수 있습니다.
- 잠재적인 실수: 오류를 잘못 잡거나 억제하는 경우 근본적인 문제를 숨길 수 있습니다.
예시:
# 예시: graceful try와 except를 활용한 오류 처리
def divide_numbers(a, b):
try:
result = a / b
print(f"{a}를 {b}로 나눈 결과는: {result}")
except ZeroDivisionError:
print("0으로 나눌 수 없습니다! 0이 아닌 값으로 나누어 주세요.")
except Exception as e:
print(f"예상치 못한 오류가 발생했습니다: {e}")
else:
print("나눗셈 성공!")
# 함수 테스트
divide_numbers(10, 2) # 일반적인 나눗셈
divide_numbers(5, 0) # 0으로 나누기
divide_numbers("a", 2) # 예상치 못한 오류 (TypeError)
10. 리스트 슬라이싱: 강력하면서 표현력이 있는 사용법
장점:
- 하위 목록 추출, 뒤집기, 요소 건너뛰기 등의 작업을 쉽게 수행할 수 있습니다.
- 코드 가독성을 향상시키고 명시적인 반복문이 필요 없도록 합니다.
단점:
- 복잡한 슬라이싱을 과도하게 사용하면 코드 가독성에 영향을 줄 수 있습니다.
예시:
# 인덱스 2부터 5까지의 서브리스트 추출
original_list = [1, 2, 3, 4, 5, 6, 7]
sublist = original_list[2:6]
11. 제너레이터: 메모리 효율적인 반복
장점:
- 대규모 데이터 세트를 효율적으로 처리합니다.
- 아이템을 실시간으로 생성하여 메모리를 절약합니다.
단점:
- 생성기는 일회용 반복자입니다. 한 번 소비되면 재사용할 수 없습니다.
예:
# 피보나치 수열 생성기
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
12. 단언문: 자신감을 가지고 디버깅하기
장점:
- 잠재적 문제를 미리 잡아내어 코드 신뢰성을 향상시킵니다.
- 코드에 대한 가정을 확인하는 방법을 제공합니다.
단점:
- 제품 코드에서 오버 사용하면 성능에 영향을 줄 수 있습니다.
예시:
# 변수가 양수인지 확인하는 어설션
num = -5
assert num > 0, "숫자는 양수여야 합니다."
13. 깊은 복사 vs 얕은 복사: 현명하게 복제하기
장점:
- 얕은 복사: 동일한 객체에 대한 참조를 가진 새로운 컬렉션을 생성합니다.
- 깊은 복사: 원본 객체 및 모든 내용의 독립적인 복제본을 생성합니다.
단점:
- deepcopy가 필요한데 얕은 복사를 사용하면 원본 데이터의 의도치 않은 수정이 발생할 수 있습니다.
예시:
# 중첩된 목록을 얕은 복사와 깊은 복사로 복제하는 방법
import copy
original = [[1, 2, 3], [4, 5, 6]]
shallow = copy.copy(original)
deep = copy.deepcopy(original)
14. 랜덤 모듈: 예측할 수 없는 것을 환영하세요
장점:
- 시뮬레이션, 게임 또는 예측할 수 없는 상황에 유용합니다.
- 다양한 무작위화 기능을 제공합니다.
단점:
- 결과는 실제로 무작위적이지 않고 의사난수입니다.
예시:
import random
# 1과 10 사이의 난수 생성
random_number = random.randint(1, 10)
15. Defaultdict: 사전 조작 간소화하기
장점:
- 존재하지 않는 키에 대한 기본값을 제공하여 코드를 간소화합니다.
- 명시적인 키 존재 여부 검사를 없애줍니다.
Cons:
- collections 모듈을 가져와야 함.
예시:
from collections import defaultdict
word = "pythonic"
letter_count = defaultdict(int)
for letter in word:
letter_count[letter] += 1
16. 해저 쇠사자 연산자(:=): 효율적인 인라인 할당
장점:
- 효율적으로 값을 할당하고 동일한 표현식 내에서 사용합니다.
- 특정 조건에서 중복을 줄여줍니다.
단점:
- 이를 과도하게 사용하면 연산자에 익숙하지 않은 사람들에게 코드를 읽는 데 어렵게 만들 수 있습니다.
예시:
# 파일에서 빈 줄을 찾을 때까지 줄을 읽는 방법
with open('file.txt', 'r') as f:
while (line := f.readline().strip()):
print(line)
17. 타입 힌팅: 코드 가독성 향상하기
장점:
- 코드 가독성과 유지 관리성을 향상시킵니다.
- 더 나은 IDE 지원 및 정적 유형 검사를 가능하게 합니다.
단점:
- Python은 여전히 동적으로 유형이 할당되는 언어이며, 유형 힌트는 옵션이며 강제되지 않습니다 — 인간 눈을 위한 것이죠 ;) .
예시:
# 타입 힌트가 있는 함수
def greet(name: str) -> str:
return f"Hello, {name}!"
18. Namedtuples: 스스로 설명하는 데이터 구조
장점:
- 가볍고 변경할 수 없는 데이터 구조를 제공합니다.
- 각 필드에 이름을 지정하여 코드 가독성을 향상시킵니다.
단점:
- 변경할 수 없으며, 생성 후 수정할 수 없습니다.
- 가변 구조를 위해서는 데이터 클래스를 사용하는 것을 고려해보세요 (Python 3.7+).
예시:
# 사람을 위한 namedtuple 만들기
from collections import namedtuple
Person = namedtuple('Person', ['name', 'age'])
alice = Person(name="Alice", age=30)
19. 리스트를 병합하고 해제하는 방법: 순차열 결합 및 해제
장점:
- 동시에 여러 리스트를 반복하는 것을 간단하게 만듭니다.
- 서로 다른 리스트에서 항목을 함께 처리해야 하는 작업에 편리합니다.
단점:
- zip()은 입력 리스트 중 가장 짧은 곳에서 멈춥니다. 크기가 다른 iterable을 사용할 경우 itertools.zip_longest()을 고려해보세요.
예시:
# 퀴즈에서 사용자 입력과 해당 답변을 매칭하는 예시
names = ["Alice", "Bob"]
scores = [85, 92]
for name, score in zip(names, scores):
print(f"{name}: {score}")
20. Dictionaries — get()과 setdefault(): 우아한 키 처리
장점:
- get(): 키의 값을 검색하여, 해당 키가 존재하지 않을 경우 기본값을 제공합니다.
- setdefault(): 키가 존재하지 않을 경우 기본값을 설정하여, 중복된 키 확인을 방지합니다.
단점:
- 이러한 방법을 간과하면 중복 코드를 확인하는 데 유용합니다.
예시:
data = { name: "Alice" };
age = data.get("age", 30);
data.setdefault("country", "USA");
21. main 가드: 스크립트 실행을 제어하기
장점:
- 특정 코드가 스크립트가 직접 실행될 때만 실행되고 가져올 때는 실행되지 않도록 보장합니다.
- 기능으로 가져와서 함수를 사용하거나 작업을 위해 직접 실행할 수 있는 유틸리티 스크립트에 유용합니다.
단점:
- 이 가드를 사용하는 것을 잊으면 모듈이 가져올 때 예기치 않은 동작을 초래할 수 있습니다.
예시:
if __name__ == "__main__":
print("이 스크립트는 직접 실행 중입니다!")
22. 가상 환경: 프로젝트별 개발을 위한 종속성 격리
장점:
- 각 프로젝트를 위한 깨끗하고 격리된 환경을 보장합니다.
- 의존성 관리를 용이하게 하고 충돌을 피할 수 있습니다.
Cons:
- 가상 환경을 활성화하는 것을 잊으면 전역 Python 환경에 의도하지 않은 패키지 설치로 이어질 수 있습니다.
Example:
# 가상 환경 생성 및 활성화
python -m venv my_project_env
source my_project_env/bin/activate
23. 별표 (*) 연산자: 다재다능하고 강력함
장점:
- 컬렉션을 각각의 요소로 효율적으로 언패킹한다.
- 함수 내에서 동적인 인수 처리를 용이하게 한다.
단점:
- 여러번의 언패킹을 연속적으로 사용하는 경우에는 코드 가독성이 감소할 수 있습니다.
예시:
# 함수에 별도의 인수를 기대하는 동적 목록 값 전달
def func(a, b, c):
return a + b + c
values = [1, 2, 3]
print(func(*values))
24. 컨텍스트 매니저(with 문): 리소스 관리의 간편함
장점:
- 리소스의 적절한 설정 및 해제를 보장합니다.
- 코드 가독성을 향상시키고 리소스 누수 가능성을 줄입니다.
단점:
- 유익할 때 with 문을 사용하지 않는 것은 리소스 관련 문제로 이어질 수 있습니다.
예시:
# 컨텍스트 매니저를 사용하여 파일 열고 읽기
with open('file.txt', 'r') as f:
content = f.read()
25. 파이썬의 언더스코어(_) 사용법: 명명과 루프에서의 다재다능함
장점:
- 명명 규칙에서 "보호된" 변수를 나타냄.
- REPL 환경에서 마지막 결과를 재사용함.
- 루프에서 루프 변수가 필요하지 않을 때 일회용 변수로 작용함.
단점:
- 다양한 용도로 사용되면 특히 새로운 코더들에게 혼란스러울 수 있어요.
예시:
# 루프 카운터가 필요 없는 특정 횟수만큼 반복하기
for _ in range(5):
print("Hello, World!")
26. 맵, 필터 및 리듀스: 파이썬에서의 함수형 프로그래밍
장점:
- map(): 컬렉션의 각 항목에 함수를 적용합니다.
- filter(): 조건에 따라 항목을 선택합니다.
- reduce(): 함수를 누적적으로 적용하여 시퀀스를 단일 값으로 축소합니다.
단점:
- Python 3.x에서 map()과 filter()는 반복자를 반환하므로 필요하다면 리스트로 변환하세요.
예시:
# map()을 사용하여 문자열을 대문자로 변환하기
names = ["alice", "bob", "charlie"]
upper_names = list(map(str.upper, names))
27. 딕셔너리 병합: 딕셔너리 작업을 간단하게 만들기
장점:
- 여러 사전의 내용을 결합하는 것을 간편하게 해줍니다.
- 병합 방법을 선택하는 데 유연성을 제공합니다.
단점:
- 이 접근을 과도하게 사용하면 중첩된 사전을 처리할 때 예상치 못한 결과로 이어질 수 있습니다.
예시:
딕셔너리를 update() 메서드를 사용하여 병합하기
dict1 = {'a': 1, 'b': 2} dict2 = {'b': 3, 'c': 4} dict1.update(dict2)
축하해요! 마침내 완료했어요!
이 파이썬 코딩 팁을 마무리하며, 여러분은 여러분의 코딩 도구 상자에 유용한 속임수들을 배운 것을 기대합니다. 코딩 전문가이든 초보자이든, 새로운 팁으로 색다르게 유지하는 것은 언제나 좋은 선택입니다. 이것들을 적용해보고, 여러분에게 도움이 되는 것을 확인하고, 여러분의 파이썬 코딩 실력을 조금씩 향상시키는 여정을 즐기세요. 즐거운 코딩 되세요!