파이썬 프로그래밍

Pandas는 데이터프레임에서 작업할 때 환상적인 프레임워크를 제공합니다. 데이터 과학에서는 작은 데이터프레임부터 크고 때로는 아주 큰 데이터프레임까지 다룹니다. 작은 데이터프레임을 분석하는 것은 매우 빠를 수 있지만, 큰 데이터프레임에서 심지어 단일 작업도 상당한 시간이 걸릴 수 있습니다.
이 글에서는 종종 데이터프레임에서 작업 순서를 바꿈으로써 이 시간을 단축시킬 수 있다는 것을 보여 드리겠습니다. 이 작업은 사실상 아무 비용도 들지 않는 방법입니다.
다음 데이터프레임을 상상해봅시다:
import pandas as pd
n = 1_000_000
df = pd.DataFrame({
letter: list(range(n))
for letter in "abcdefghijklmnopqrstuwxyz"
})
100만 행과 25개의 열을 갖고 있어요. 이렇게 큰 데이터프레임에서 다양한 작업을 수행하면 현재 개인 컴퓨터에서 눈에 띌 것입니다.
가령, 다음 조건을 따르는 행만 필터링하여 가져와야 한다고 상상해보죠: a 50,000이상 그리고 b 3,000이상, 그리고 a, b, g, n, x 열 다섯 개만 선택해야 한다면, 다음과 같이 할 수 있어요:
subdf = df[take_cols];
subdf = subdf[subdf["a"] < 50_000];
subdf = subdf[subdf["b"] > 3000];
위 코드에서는 먼저 필요한 열을 가져와서 행을 필터링합니다. 동일한 결과를 얻을 수 있으며, 연산의 순서를 바꿔서 먼저 필터링을 수행한 다음 열을 선택할 수도 있습니다:
subdf = df[df["a"] < 50_000];
subdf = subdf[subdf["b"] > 3000];
subdf = subdf[take_cols];
더불어 Pandas 연산을 연결하여 동일한 결과를 얻을 수도 있습니다. 해당 명령의 연결은 다음과 같습니다:
# 칼럼을 먼저 선택한 다음 행을 필터링합니다.
df.filter(take_cols).query(query)
# 행을 먼저 필터링한 다음 칼럼을 선택합니다.
df.query(query).filter(take_cols)
df가 크기 때문에 네 가지 버전 간 성능이 다를 것으로 예상됩니다. 어느 것이 가장 빠를까요? 가장 느릴까요?
벤치마크
이 작업을 벤치마크해보겠습니다. timeit 모듈을 사용할 것입니다:
아니면 IPython 쉘에서 이용 가능한 버전입니다.
저희의 벤치마크는 다음과 같습니다:
다음 섹션에서는 벤치마크 결과를 분석한 후 결과를 해석하겠습니다.
결과
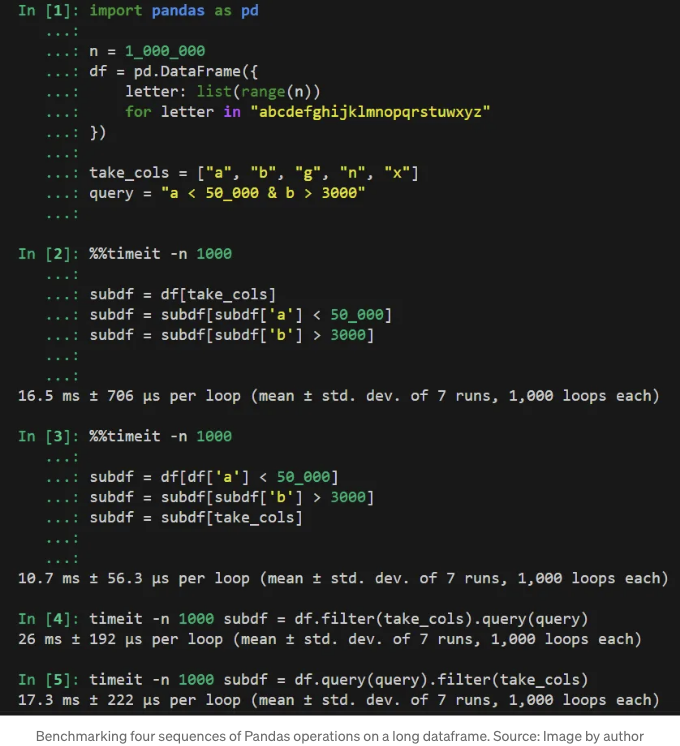
Bracketing: 열 선택한 다음 행 필터링하기 (16.5 ms)
subdf = df[take_cols];
subdf = subdf[subdf["a"] < 50_000];
subdf = subdf[subdf["b"] > 3000];
이 코드에서는 Tipycal Pandas 코드로 괄호, 불리언 인덱싱 및 대입을 사용했습니다. 예상 결과를 얻기 위해 다음 순서대로 세 줄을 사용했습니다: 먼저 열 하위 집합을 선택하고 그런 다음 두 개의 필터링 조건을 순차적으로 적용했습니다.
네 가지 접근법 중에서 이 방법은 비교적 빨랐어요 — 하지만 가장 빠른 방법은 아니었어요. 먼저 열을 선택하면 df 데이터프레임의 너비가 줄어들지만, 데이터프레임이 큰 이유는 주로 너비가 아니라 행의 수 때문이에요. 이렇게요¹:
In [7]: n_of_elements = lambda d: d.shape[0]*d.shape[1]
In [8]: n_of_elements(df)
Out[8]: 25000000
In [9]: n_of_elements(df.filter(take_cols))
Out[9]: 5000000
In [10]: n_of_elements(df.query(query))
Out [10]: 1174975
보시다시피 열을 먼저 제거할 때 (df.filter(take_cols)), 500만 개 요소를 갖는 데이터프레임을 얻을 수 있고, 행을 먼저 필터링할 때 (df.query(query))는 100만 개가 넘는 요소를 가진 데이터프레임을 얻게 돼요. 이는 네 배 이상 작은 크기에요.
불필요한 열을 먼저 제거하면 불필요한 행을 먼저 제거하는 것보다 작업이 느려질 것이 당연해요 — 다음 섹션에서 보여줄게요.
괄호 사용: 행 필터링 후 열 선택 (10.7 ms)
subdf = df[df["a"] < 50_000];
subdf = subdf[subdf["b"] > 3000];
subdf = subdf[take_cols];
이 코드는 브래킷, 부울 인덱싱, 및 할당을 기반으로 한 전형적인 판다스 코드를 사용하지만, 이번에는 데이터프레임의 크기를 줄이기 위해 먼저 행이 필터링됩니다. 그런 다음 선택된 열이 가져와집니다.
이는 시험한 네 가지 방법 중에서 명백히 가장 빠른 방법입니다. 효율성 향상은 데이터프레임 크기의 초기 감소로 인해 얻어지며, 결과적으로 후속 단계에서 처리해야 하는 더 작은 데이터셋을 제공합니다.
이전 방법과 이 접근 방식에서 우리는 진정한 벡터화된 Pandas 코드를 사용했습니다. 이는 직접 부울 인덱싱을 사용했다는 것을 의미합니다. 이론적으로 가장 성능이 우수한 Pandas 코드를 제공하는 것은 벡터화된 연산이며, 그것을 볼 수 있습니다. 두 가지 버전 간의 차이는 우리가 방금 분석한 내용에서 나타납니다: 데이터프레임 크기를 가장 줄일 것으로 생각되는 이 작업을 먼저 사용해야 합니다.
Pipes: 열 선택 후 행 필터링 (26.0 ms)
df.filter(take_cols).query(query)
이 코드는 연결된 Pandas 연산을 사용합니다. 먼저 행을 필터링한 다음 필요한 열을 가져옵니다.
판다스 데이터프레임의 .query() 메서드는 전통적인 판다스/넘파이 의미의 벡터화된 연산을 사용하지 않습니다. 대신, numexpr Python 패키지를 사용합니다. 이론적으로는 문서에 설명된 대로,
우리가 실험한 결과로는 불리언 인덱싱을 기반으로 한 벡터화된 연산보다 속도가 느린 것을 확인했습니다.
우리의 벤치마크로 돌아와서, 이 코드는 관찰된 코드 중에서 분명히 가장 느립니다. 이에는 두 가지 이유가 있습니다: 판다스 연산을 연쇄적으로 하는 것이 벡터화하는 것보다 느리며, 우리가 방금 논의한 대로, 먼저 열의 수를 줄이는 것이 먼저 행을 필터링하는 것보다 이 데이터셋에 효율적이지 않습니다. .filter() 메서드는 데이터프레임의 크기를 줄이지만, 이 감소는 .query()를 사용하여 행 수를 줄인 후에 얻은 감소보다 4배 이상 작습니다.
Pipes: 행을 필터링한 다음 열을 선택합니다 (17.3 ms)
df.query(query).filter(take_cols);
이 코드는 이전 것의 개선된 버전으로 간주할 수 있습니다. 이미 필요 없는 행을 먼저 없애야 하고, 그 후에 필요한 열을 선택해야 한다는 것을 알고 있습니다. 이 코드는 Pandas 연산을 연쇄적으로 수행하여 이 작업을 수행합니다.
이 방법은 이전 방법(열을 선택한 후 .query()가 적용되는 파이프)보다 효율적이지만, 여전히 해당 벡터화된 코드와 성능이 맞지는 않습니다. 덜 효과적인 순서에서 벡터화된 코드와 거의 유사한 성능을 보입니다.
해석
[본문 내용]
벤치마크 결과에서는 다음과 같은 관찰이 일어났습니다. 이는 벡터화된 연산과 연산 순서의 중요성을 강조합니다:
- 먼저 벡터화된 행 필터링: 결과는 데이터프레임 크기를 최대한 처음에 줄이는 것의 중요성을 강조합니다. 먼저 행의 수를 줄이면 이후의 작업(우리의 경우, 열 선택)이 더 작은 데이터셋에서 작동하므로 속도가 향상됩니다.
- 열 선택의 효율성: 열 선택으로 워크플로우를 시작하면 데이터프레임을 좁힘으로써 메모리 사용량을 줄일 수 있습니다. 이는 실행 시간을 줄이는데 이어집니다. 그러나 이 줄임이 행 필터링으로 시작했을 때보다 작습니다. 따라서 이 버전은 처리 속도에 최적화되어 있지 않습니다.
- 연쇄적인 작업: 이는 이 기사의 주제가 아니지만, Pandas 작업을 연쇄하는 것은 벡터화하는 것보다 효율적이지 않음을 관찰했습니다. 파이프의 실행 시간 (17.3 ms 및 26 ms)은 이 현상을 보여줍니다. 해당 시간은 해당 벡터화된 작업(각각 10.7 ms 및 16.5 ms)보다 더 느립니다.
그러나 이해해야 할 점은 이해가 일반적이 아니라는 것입니다. 이는 우리의 벤치마크 및 분석한 특정 시나리오를 참조합니다.
여러분에게 연습 문제를 남기겠습니다: 50_000 또는 b 3000 중 어떤 행 필터링을 먼저 적용하느냐에 따라 어떤 영향이 있을까요?
행보다 열이 많음
위에서는 행보다 열이 더 많은 데이터프레임을 다루었지만, 상황이 정반대인 경우는 어떨까요? 즉, 훨씬 많은 열이 있고 훨씬 적은 행이 있는 데이터프레임을 다루는 경우를 생각해보겠습니다.
위에서 배운 내용을 바탕으로, 우리가 작업 순서를 선택하는 주요 기준은 결과 데이터프레임의 크기입니다. 그래서 다음 시나리오를 분석해봅시다:
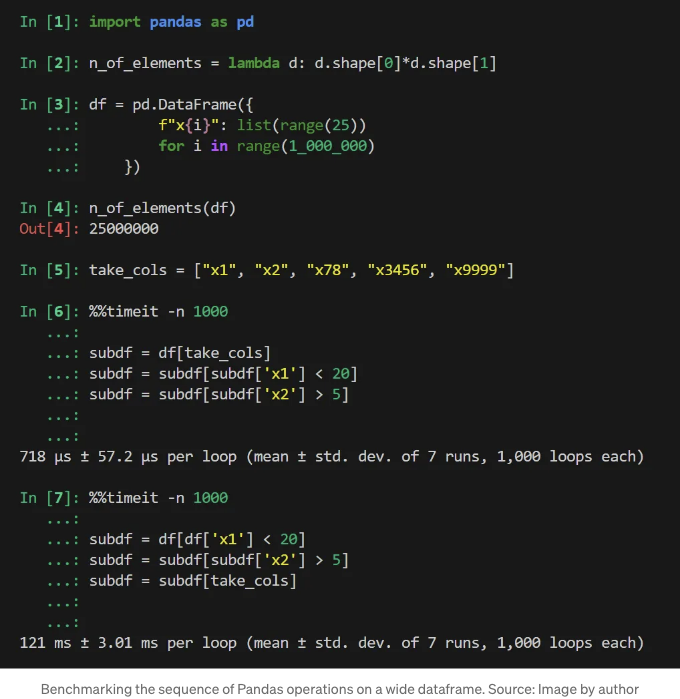
이거 봤어요? 718 µs 대 121 ms로 첫 번째 접근 방식(먼저 열을 선택)이 훨씬 빠릅니다. 거의 170 배나 빠르죠! 그 이유는 이전과 같아요 — 첫 번째 작업 후 데이터프레임의 크기 때문이에요. 이번에는 차이가 엄청나죠:

두 번째 작업도 매우 다른 크기의 데이터프레임에서 작동합니다:

Pandas 연쇄 작업은 이러한 데이터프레임에 대해 매우 비효율적으로 작동하는 흥미로운 점입니다:

열을 먼저 처리했음에도 불구하고 이 파이프는 위의 느린 작업보다 시간을 세 배나 적게 소요했음을 유념하세요. 순서를 바꾼 상태의 대응하는 파이프를 벤치마킹 해보려고 했지만, 3시간 후에 벤치마킹을 종료했습니다:

테이블 태그를 마크다운 형식으로 변경해 보겠습니다.
결론
저희 실험은 판다스에서 데이터 조작의 중요한 원칙을 보여줍니다: 가능한 한 빨리 데이터셋 크기를 줄이는 것이 성능을 크게 향상시킬 수 있습니다, 특히 벡터화된 행 필터링 작업을 통해.
이 권장 사항은 놀랍지 않을 수 있지만 상당히 분명해 보입니다. 과거에 가끔 이를 따르지 못한 적이 있었는데, 앞으로는 판다스 작업의 순서에 대해 생각해야겠다고 확실히 기억하겠습니다.
작은 데이터프레임을 대화식 세션에서 분석할 때는 성능 차이를 무시하고 선호하는 코드를 사용해도 됩니다. 그러나 실제 운영 코드에서는 작은 데이터프레임이나 대규모 데이터프레임을 분석할 때 작업 순서가 상당한 차이를 만들 수 있습니다.
첫 번째 예시에서 행 필터링을 열 선택보다 먼저 적용하는 것이 더 효율적인 전략으로 나타났습니다. 그러나 이는 일반적으로 나타나는 현상은 아니며 데이터프레임에 따라 다릅니다.
우리는 데이터프레임의 요소 수를 주요 기준으로 사용했지만, 데이터프레임이 길거나 넓은지도 중요한 점입니다. 요소 수가 동일한 두 데이터프레임을 분석했을 때 성능에 큰 차이를 확인했습니다.
따라서 성능이 중요하다면 각각의 데이터프레임을 개별적으로 분석하고 모양과 크기를 고려하여 작업 순서를 신중히 선택해야 합니다. 이 통찰력은 특히 대용량 데이터셋을 다룰 때 판다스 워크플로를 최적화하는 데 매우 소중합니다.
요약해 봅시다. 저희의 벤치마크는 Pandas 작업을 구현하는 데 다음과 같은 주요 통찰을 제공합니다:
- Pandas 작업에 벡터화를 적용하면 Pandas 작업을 연쇄하는 것보다 성능이 더 우수한 코드를 얻을 수 있습니다.
- 일반적으로 여러 Pandas 작업을 포함하는 성능이 우수한 코드를 구현하려면 데이터프레임의 모양과 크기에 따라 후속 단계에서 데이터프레임의 크기를 가장 크게 줄일 작업부터 시작하고, 이를 가장 적게 줄이는 작업으로 끝냅니다.
- 성능이 중요한 경우, 데이터프레임의 모양과 크기를 고려하여 각 코드 조각을 개별적으로 최적화합니다.
각주
¹ 이 코드에서는 다음 람다 정의를 사용하여 명명된 함수를 정의했습니다:
In [7]: n_of_elements = lambda d: d.shape[0]*d.shape[1]
네, 이름 붙은 람다 정의를 사용했어요. 여기에서 설명한 대로:
이론적으로는 이름 붙은 람다를 사용하지 말아야 하지만,
여기에서는 이 규칙의 예외를 보여드려요: 저장이나 배포되지 않는 데이터 분석 코드를 사용할 때요.
재밌게도, 이 정확한 코드를 배포했어요. 하지만 반항적으로 하는 게 아니라 어떤 점을 강조하기 위해서였죠.