
모든 데이터 과학자들이 그래픽이 그들의 데이터 이야기에 중요하다는 것을 알고 있습니다. Python 개발자들은 풍부한 플롯 컬렉션을 제공하는 언어로 일할 수 있어 행운입니다. 이 기사에서는 Sankey 다이어그램, 리지 플롯, 인셋, 스파이더 플롯 및 워드클라우드 플롯과 같이 잘 알려지지 않은 시각화를 사용하는 사용 사례에 대해 논의하여 이 풍부함을 시연할 것입니다. 또한 산점도 및 막대 플롯과 같은 더 익숙한 그래픽 표현에 대한 사용 사례도 논의할 것입니다. 대부분의 플롯은 Matplotlib, Seaborn 및 Plotly Python 라이브러리를 활용할 것입니다.
모든 사용 사례에서 모양, 크기, 색상, 방향, 면적 크기 및 마커 심볼 영역 같은 특성을 활용하여 10가지 다양한 사용 사례에 대한 플롯을 생성할 것입니다. 모든 사용 사례에서 우리의 목표는 효과적이고 효율적이며 미학적인 시각화를 만드는 것입니다. 우리가 플롯의 맥락에서 이러한 단어가 의미하는 바를 설명해보겠습니다: (a) 효과적: 전달해야 하는 모든 정보가 그래프 안에 포함되어 있습니다. (b) 효율적: 그래프에 중복 데이터가 없습니다. (c) 미적. 그래프는 데이터를 명확하게 제시하며 시각적으로 매력적이고 주목을 끕니다. 이 기사의 모든 그래프는 2D입니다. 효율성과 효과성 측면에서 3D보다 2D 그래프가 더 명확하고 이해하기 쉽고, 거리를 2D에 더 잘 표현할 수 있기 때문입니다. 각 사용 사례에 대한 코드도 제시되며 코드와 그래픽의 중요한 부분이 논의될 것입니다.
사용 사례 1. 대학 간 교환 학생 흐름 설명을 위한 Sankey 다이어그램.
이 다이어그램은 리소스 흐름을 보여주는 데 매우 유용합니다. 아래 코드는 우리의 사용 사례 구현을 보여줍니다. 문자 'A'는 첫 번째 대학을 나타내고, 문자 'B'는 두 번째 대학을 나타냅니다. 숫자 3,4,5는 각각 '통계, 수학, 물리' 부서를 나타냅니다. 다이어그램은 25번째 줄에서 'node'와 'link'가 딕셔너리로 생성됩니다. 'node'는 고유한 'Depts'로 구성된 'label' 객체를 사용하고, 'link'는 'sending' 부서의 인덱스와 'accepting' 부서의 인덱스로 구성된 두 개의 리스트를 사용합니다.
그림 1은 결과적인 Sankey 다이어그램을 보여줍니다. '3A' 노드 옆의 오렌지색 사각형에 주목하세요. 노드 중 하나에 커서를 가져가면 어떤 일이 발생하는지를 보여줍니다. 여기서 '3A' 노드에 커서를 가져가면, A 대학의 3 부서가 교환학생을 받고 보내는 빈도를 볼 수 있습니다. 그 부서는 한 번 학생을 받았고 3번 학생을 보냈습니다. '데이터' 딕셔너리에서도 이를 유추할 수 있습니다. 왜냐하면 'Sending_Dept' 리스트에서 '3A'가 3번 나오고 'Accepting_Dept' 리스트에서 한 번 나오기 때문입니다. '3A' 노드 왼쪽의 숫자 9는 B 대학에 보낸 총 교환학생 수입니다. 'Sending_Dept' 목록에서 3A의 값에 해당하는 'FlowValues'를 더하여 유추할 수도 있습니다.
또한 '3A' 노드를 클릭하면 해당 노드에서 시작되는 화살표가 짙어지며 '3A'가 학생을 교환하는 다른 노드를 보여줍니다. 화살표의 굵기는 'FlowValues'에 해당합니다. 즉, Sankey 다이어그램은 화살표의 방향과 폭을 사용하여 흐름 정보를 전달하고, 각 노드의 텍스트 기반 누적 흐름 형성을 제시합니다.
사용 사례 2. 부동산 대행사의 주택 판매 데이터를 플롯합니다.
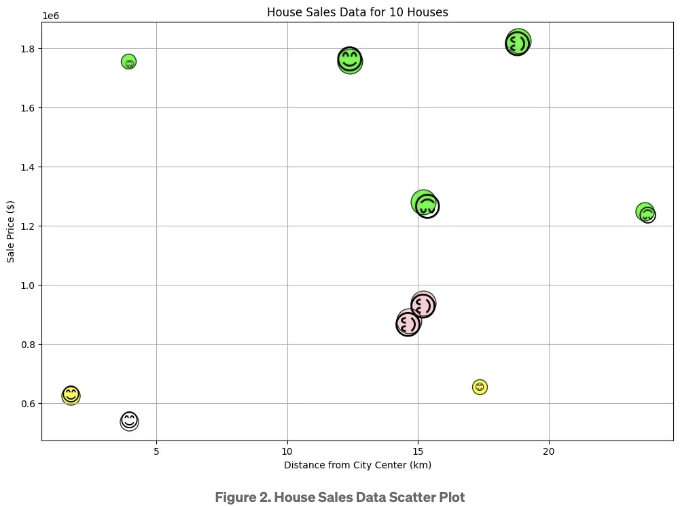
데이터 과학자가 부동산 대행사에서 일합니다. 대행사는 지난 달에 판매된 주택에 대한 정보를 제공할 2D 플롯을 요청했습니다. 각 판매된 주택에 대해 플롯은 다음 정보를 포함해야 합니다: (a) 주택 가격, (b) 도시 중심부터의 거리, (c) 도시 중심으로부터의 방향, (d) 에이전트의 수수료, (e) 판매 에이전트의 회사 직급 (협력사, 부사장, 파트너). 이 모든 정보를 하나의 2D 그래프에 담는 것은 많은 양입니다. 그러나 각 주택을 플롯에서 표현하기 위해 복잡한 개체를 사용함으로써 이 도전을 극복할 수 있습니다. 구체적으로, '웃는 얼굴 이모지'를 사용할 것입니다. 아래 코드 조각에 구현이 나와 있습니다.
위 코드와 아래에 나온 산점도 그래프에서, X와 Y 축은 각각 도시 중심부터의 거리와 판매 가격을 나타냅니다. 몇 가지 중요한 점은 다음과 같습니다:
- 얼굴 이모지의 크기는 판매 에이전트의 직급을 나타냅니다. 크기가 클수록 에이전트의 직급이 높습니다.
- 얼굴 이모지의 웃음 표정(위, 아래, 왼쪽, 오른쪽)은 도시 중심으로부터의 방향을 나타냅니다. 예를 들어, 웃음이 위에 있으면 주택이 도시 중심의 북쪽에 있습니다.
- 얼굴 이모지의 색깔은 에이전트의 수수료를 나타냅니다. 예를 들어, 라임은 6%이고, 분홍은 5%입니다 (부동산 대행사는 판매 가격이 높을수록 수수료가 높다는 정책을 가지고 있습니다).
이 사용 사례를 마무리하면, 우리는 주택의 다섯 가지 속성을 2D 플롯에 나타내기 위해 산점도와 이모지의 형태, 색상, 크기를 사용했습니다. 웃는 얼굴 같은 복잡한 객체를 데이터 포인트로 나타내는 것은 플롯에 많은 정보를 담을 수 있도록 도와주었습니다.
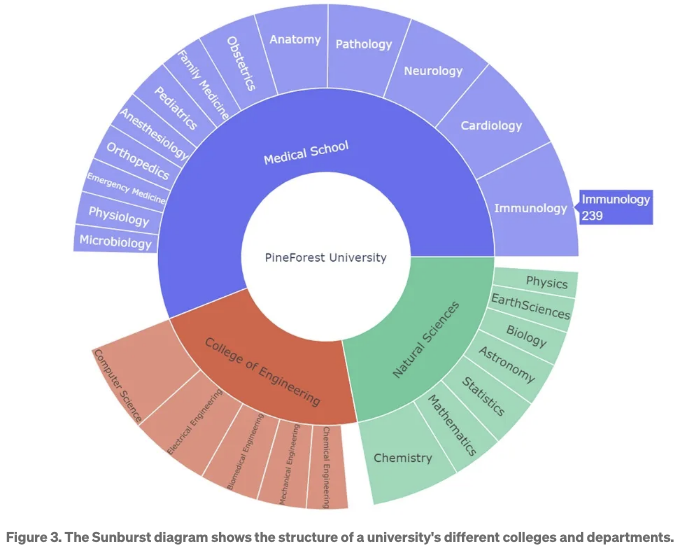
사용 사례 3. 대학의 다른 단과대학과 학과의 구성을 2D 그래프로 보여줍니다. 각 단과대학과 학과의 크기에 대한 정보도 전달되어야 합니다.
여기서 다른 구성 요소들이 계층 구조를 가지고 있는 경우입니다. 선버스트 그래프가 이 경우에 이상적입니다. 아래 코드 조각은 구현을 보여줍니다. 첫 번째 배열 '라벨'에는 선버스트 그래프의 이름이 포함되어 있습니다. 두 번째 배열 '부모'에는 계층 구조가 포함되어 있으며, '값' 배열에는 세그먼트의 크기가 포함되어 있습니다.
위 알고리즘의 출력물이 Figure 3에 나와 있어요. 각 세그먼트의 크기는 'values' 배열 내의 해당 숫자와 비례하다는 점을 유의해주세요. 아래 그래프를 보면 세그먼트를 클릭하면 크기가 나타납니다 (면역학 239).
요약하면 선크로스 그래프는 대학의 다양한 엔티티의 계층 구조를 설명하기 위해 크기, 색상 및 텍스트를 사용합니다.
사용 사례 4. 부동산 고객님은 지난 달에 판매된 주택에 관한 다음 정보를 보여주는 2D 그래프를 원합니다: (a) 판매 가격, (b) 크기, (c) 바다로부터의 거리, (d) 기차역으로부터의 거리. 같은 그래프 내에서 가장 많이 판매된 주택을 포함하는 그래프 세그먼트의 확대도 보여주어야 합니다.
이 use case는 use case 2와 비슷합니다. 그러나 데이터 과학자의 새로운 작업 하나가 있습니다: 그래프에서 가장 바쁜 부분의 확대된 버전을 만드는 것입니다. 이를 삽입이라고 합니다. 삽입은 플롯의 중요한 부분을 확대하여 효과를 크게 향상시킬 수 있습니다. 아래 코드 스니펫은 삽입의 구현을 보여줍니다. 플롯을 만드는 전체 코드는 내 Github 저장소에서 찾을 수 있습니다 (기사 끝에 표시됨).
아래 그림 4는 삽입이 있는 산점도를 보여줍니다. X와 Y 축은 집 크기와 판매 가격을 나타냅니다. 다이아몬드 모양의 점은 플롯상에 판매된 집을 나타냅니다. 다이아몬드의 색상은 바다로부터의 거리를 나타내고, 다이아몬드의 크기는 기차로부터의 거리에 해당합니다.
이 use case에서 우리는 플롯의 중요한 부분의 삽입을 포함하여 플롯의 효과를 향상시키는 방법을 살펴보았습니다.
사용 사례 5. 책 컨퍼런스를 위한 화려한 포스터 작성하기
이 경우, 워드 클라우드 그래프를 사용할 것입니다. 이 유형의 그래프는 단어를 다양한 크기로 포함하며, 단어의 크기는 원래 텍스트에서 나타나는 빈도에 따라 결정됩니다. 이는 가장 빈도가 높은 단어를 한 눈에 파악할 수 있는 매우 효과적인 방법입니다. 도표 5는 워드 클라우드 그래프를 보여주고, 아래의 코드 조각은 그래프를 생성한 Python 코드를 보여줍니다.

사용 사례 6. 새로운 스낵 제품의 장점을 명확하고 매력적으로 소개하기
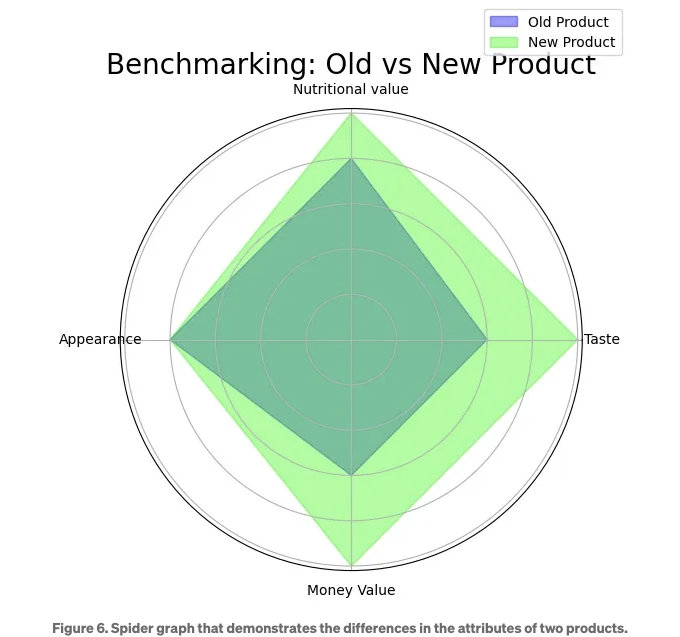
우리 데이터 과학자는 마케팅 부서가 실시한 설문 조사 결과를 발표하는 업무를 맡았습니다. 이 설문 조사에서 고객들은 고단백 바의 새로운 및 구식 형태에 대해 가치, 영양 가치, 외관 및 맛을 평가하도록 요청받았습니다.
데이터 과학자는 폴 결과를 보여주기 위해 스파이더 그래프를 사용합니다. 이 유형의 그래프는 각 속성(맛, 외관 등)을 서로 다른 축에 배치합니다. 그런 다음, 동일한 엔터티(우리 경우 고단백 바)에 속하는 속성 값은 연결되어 다각형 영역을 형성합니다. 서로 다른 영역에 대해 다른 색상을 사용하면 제품 간의 차이를 쉽게 이해할 수 있습니다.
그림 6은 결과 그래프를 보여주고, 아래의 코드 스니펫은 해당 그래프를 생성하기 위한 Python 코드를 보여줍니다. 아래 코드의 7~9행에 관한 흥미로운 점이 있습니다. ‘enpoint’가 False로 설정되어 있고, 첫 번째 값이 'old_values' 및 'new_values' 배열 끝에 추가되어 루프를 닫습니다.
아래 그림에서 볼 수 있듯이, 새로운 고단백 바는 영양 가치, 맛 및 가치 세 가지 핵심 영역에서 기존 제품보다 우수하다고 인식됩니다.
이 사용 사례에서는 두 제품 간의 색상과 모양을 거미 그래프에 사용하여 효과적으로, 효율적으로 및 시각적으로 매력적으로 구별하는 방법을 보았습니다.
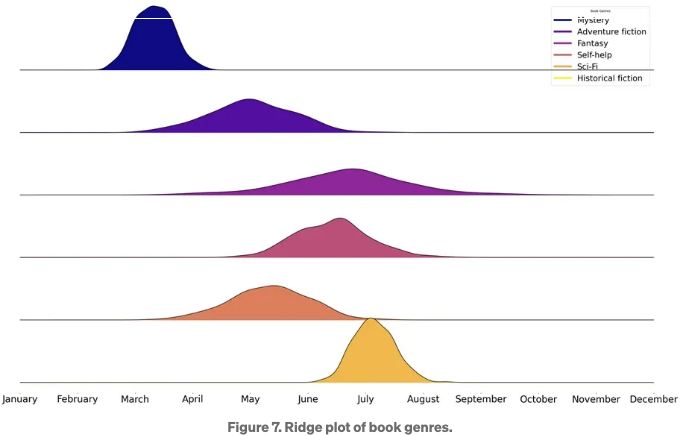
사용 사례 7. 동일한 플롯에서 해당 장르의 책 축제 주변에서 발생하는 다른 책 장르의 판매를 보여줍니다.
이 사용 사례에서는 동일한 플롯을 사용하여 다른 범주의 시간적 데이터를 플로팅해야 합니다. Python은 이 상황에 매우 적합한 리지 플롯을 제공합니다. 리지 플롯은 서로 다른 범주의 분포를 수직으로 쌓아서 표시하여 유사점과 차이점을 쉽게 비교할 수 있게 합니다. 도표 7은 해당 도서 축제를 중심으로 한 서로 다른 책 장르의 판매 차이를 보여줍니다. 동일한 플롯에 분포를 배치하고 다른 색상을 사용하여 시각적으로 매력적인 그래프를 만들어 비교를 효과적으로 가능하게 합니다. 해당 코드는 아래에 표시됩니다. 코드에서 중요한 몇 가지 포인트: (a) 조이플롯 Python 패키지를 사용하여 리지 플롯을 생성합니다. (b) 다양한 책 장르의 분포는 613번 줄에서 시뮬레이션되었습니다. 책 장르 뒤의 숫자는 해당 분포의 중심과 표준 편차입니다. (c) 20번 줄에서는 joyplot이 입력으로 DataFrame을 예상하기 때문에 데이터를 DataFrame에 넣습니다. (d) 30번 줄, 3336번 줄에서는 x축의 매개변수를 axis[-1]에 지정합니다. (이것은 하단 플롯입니다.)
사용 사례 8. 신용 카드 회사로부터 연령과 구매 금액에 대한 데이터가 주어졌을 때, 가장 높은 구매를 한 그룹을 플롯으로 강조합니다.
2D 히스토그램은 이러한 종류의 데이터에 적합해 보입니다. 일반적인 히스토그램은 데이터 포인트를 한 차원에 따라 빈에 넣지만, 2D 히스토그램은 두 차원에 대해 동시에 이 작업을 수행합니다. 아래 코드 조각은 코드를 보여주고, 그림 8은 결과 2D 히스토그램을 보여줍니다.
아래 2D 히스토그램에서 가장 높은 금액이 35-45세 그룹에서 소비되었음을 보여줍니다. 결론적으로, 2D 히스토그램은 가장 높은 구매 금액을 가진 그룹을 효과적으로 시각적으로 나타냅니다.
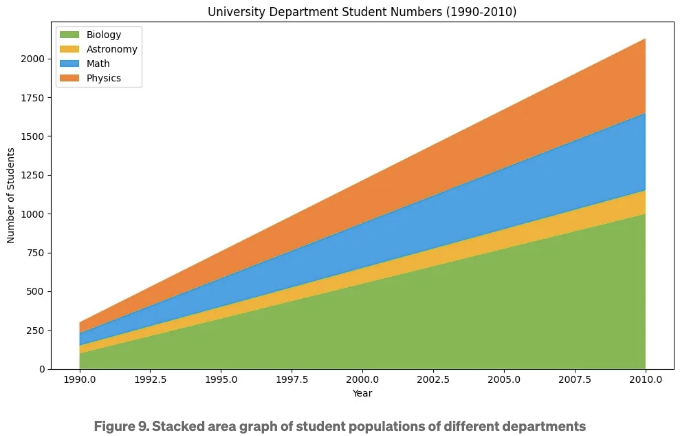
실제 사용 사례 9. 한 개의 그래프에서 1990년부터 2010년까지 생물학, 천문학, 물리학, 수학 학부의 학생 수를 보여줍니다.
이 경우, 적층 영역 그래프를 사용할 수 있습니다. 이 유형의 그래프는 다른 카테고리의 시간 데이터를 표시하는 데 사용되며 사용자에게 (a) 각 카테고리의 시간에 따른 변화, (b) 상대적 크기 및 (c) 시간에 따른 총 크기를 확인할 수 있도록 합니다. 각 카테고리에 대해 다른 색상이 사용됩니다. 아래에 코드가 나와 있으며, 그림 9는 각 학부의 학생 인구에 대한 적층 영역 그래프를 보여줍니다.
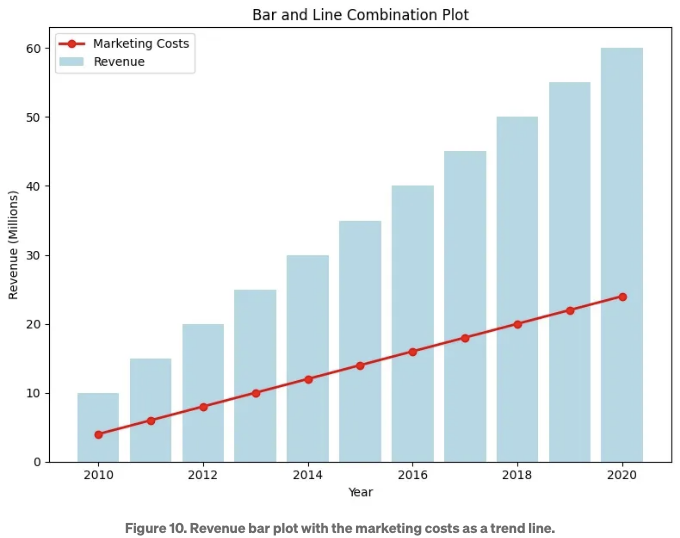
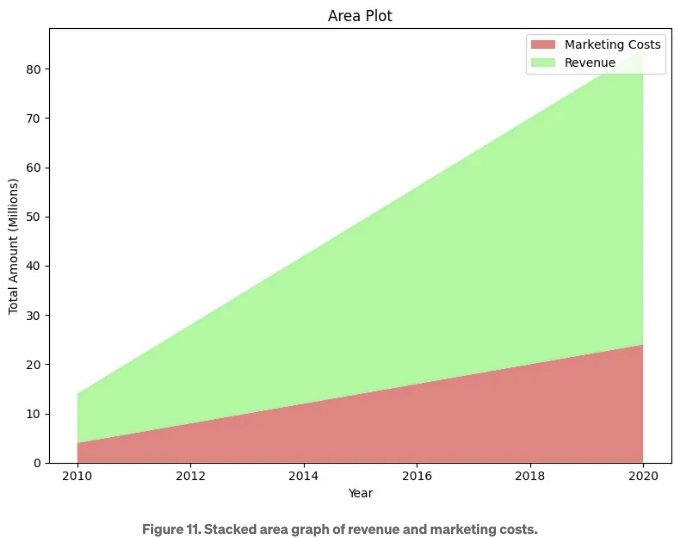
10번 유스 케이스입니다. 2010년부터 2020년까지 회사의 마케팅 비용과 수익을 비교합니다.
이전 유스 케이스와 마찬가지로, 이 유스 케이스에서도 스택된 영역 그래프를 사용할 수 있습니다. 그러나 스택된 영역 그래프는 카테고리별로 시간에 따른 차이를 그리는 유일한 솔루션이 아닙니다. 현재 유스 케이스에서는 수익 막대그래프와 마케팅 비용을 추세선으로 나타내는 것이 더 효과적인 비교 방법입니다. Figure 10은 막대그래프를 보여주고, Figure 11은 비교용 스택된 영역 그래프를 보여줍니다. 아래 스니펫에 코드가 표시되어 있습니다. 마케팅 비용이 수익 막대 앞에 추세선으로 그려질 때, 마케팅 비용이 증가하는 메시지가 더 효과적으로 전달됩니다.
결론
이 글에서는 Python 언어의 시각화 능력을 강조하기 위해 다양한 사용 사례와 해당 Python 플롯을 다뤘습니다. Sankey 다이어그램의 흐름부터 스파이더 플롯의 윤곽, 리지 플롯의 다중 피크까지, 이 글은 Python의 능력을 보여주며 가공하지 않은 데이터를 매력적이고 주목할 만한 데이터 이야기로 변환할 수 있다는 것을 보여줍니다. 우리가 논의한 플롯들은 Python의 포괄적인 도구 상자의 일부에 불과합니다. 시각화 개념에 대한 추가 학습을 위해 [1]-[6]에 나열된 훌륭한 책과 미디엄 기사를 추천합니다.
이 글의 모든 코드는 제 깃허브 디렉토리에서 찾을 수 있습니다: https://github.com/theomitsa/visualiz
읽어 주셔서 감사합니다!
참고 자료
- Tufte, E., The Visual Display of Quantitative Information, 2판, Graphics Press, 2001.
- Knaflic, C. N., Storytelling with Data: A Data Visualization Guide for Business Professionals, Wiley, 2005.
- Yau, N., Data Points: Visualization That Means Something, Wiley, 2013.
- Mansurova, M., Visualization 101: Choosing the Best Visualization Type, Medium: Towards Data Science, 2024년 1월.
- Mansurova, M., Visualization 101. Playbook for Attention-Grabbing Visuals, Medium: Towards Data Science, 2024년 2월.
- Sarkar, D., The Art of Effective Visualization of Multidimensional Data, Medium: Towards Data Science, 2018년 1월.