
샘플 eBook 장(chapters) (무료): 여기
Teachable.com에서 eBook: $22.50 여기
Amazon.com에서 인쇄본: $65 여기
선형 회귀 모델은 시계열에 대한 점 추정을 당연히 할 수 있습니다. 선형 회귀 모델은 빠르고 해석하기 쉽며 쉽게 배포할 수 있는 장점이 있습니다. 많은 기관에서 여전히 좋은 선택입니다. 선형 회귀의 일반적인 유형은 자기회귀 모델로, 9장인 "자동 ARIMA"에서 나와 있습니다. 그러나 많은 실제 사용 사례에서는 다음 두 가지를 제공해야 합니다: (1) 확률적 예측(또는 예측 구간 또는 예측 불확실성이라고도 함)과 (2) 다기간 예측. 선형 회귀를 어떻게 확장하여 이 두 결과를 수행할 수 있을까요?
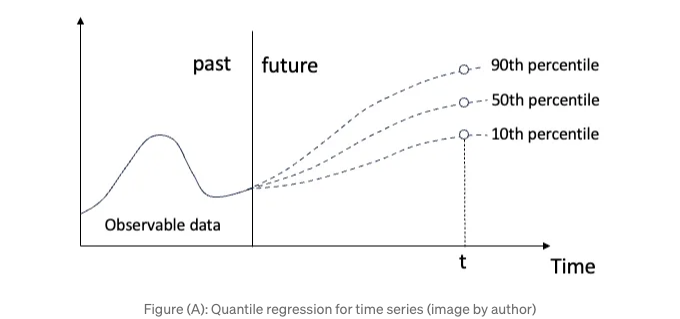
(1)에 대한 해결책은 분위 회귀를 사용하여 예측 불확실성을 제공하는 것입니다. (A) 그림은 분위 예측을 보여줍니다. 미래의 시간 t에 대해 10번째, 50번째 및 90번째 백분위수를 기반으로 예측 샘플을 반환합니다. 필요하다면 더 많은 분위 샘플을 생성할 수 있습니다. 이에 대해서는 "6장: 예측 불확실성을 위한 분위 회귀"를 참조해주세요.
(2)는 어떻게 해결할까요? 선형 회귀는 점 예측을 생성하지만, 다기간 예측을 어떻게 만들까요? 한 가지 방법은 동일한 모델을 재귀적으로 사용하는 것일 수 있습니다. 한 기간 예측을 모델로부터 얻어 다음 기간을 예측하는 데 입력으로 사용합니다. 그런 다음 두 번째 기간을 예측하기 위해 두 번째 기간의 예측을 입력으로 사용합니다. 이전 기간의 예측을 사용하여 모든 기간을 반복할 수 있습니다. 이것이 재귀 예측 또는 반복적 예측 전략이 하는 일입니다. (B) 그림은 모델이 먼저 yt+1을 생성하고, 그런 다음 같은 모델이 yt+1을 사용하여 yt+2를 생성하는 것을 보여줍니다.
아래는 마크다운 형식의 테이블입니다.
또 다른 전략은 n개의 별도 모델을 구축하는 것입니다. 각 모델은 n개의 기간에 대한 예측을 생성합니다. 10개 기간을 예측하려면 10개의 모델을 교육하고 각 모델을 특정 단계를 예측하도록 설정합니다. 이를 직접 예측 전략이라고 합니다. 이 전략은 그림 (C)에 나와 있습니다. 두 가지 전략을 학습하려면 13장인 "다중 기간 시계열 예측을 위한 두 가지 주요 전략"으로 이동하세요.
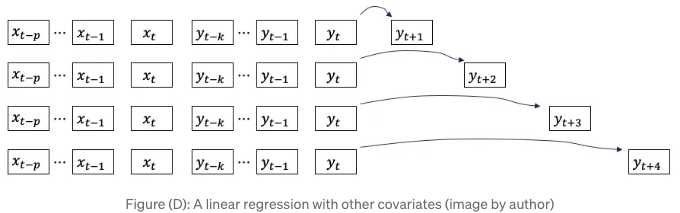
선형 회귀를 단변량 시계열로 제한할 이유는 명백히 없습니다. 다른 변수인 공변량이라고 불리는 변수도 추가할 수 있습니다. 그림 (D)에는 다른 공변량 xt와 과거 p개 항목이 포함되어 있습니다.
선형 모델은 Figure (A)에 표시된 분위수 예측 및 Figure (D)에 표시된 직접 예측을 수행해야 할 때 복잡해 보입니다. 다행히 Python 시계열 라이브러리인 Darts에서 이러한 프로세스가 구현되었습니다. Darts 라이브러리는 "scikit-learn" 함수를 많이 포함하고 있어 "scikit-learn"의 기능을 활용할 수 있습니다. 이 중에는 sklearn의 분위수 회귀기능도 포함되어 있습니다. 따라서 우리는 Darts 라이브러리에 초점을 맞출 수 있습니다.
우리는 다음 단계로 진행할 것입니다:
- 단변량 데이터로 시작하기
- 다른 공변럇값 포함하기, 그리고
- 분위수 예측 포함하기.
Darts 라이브러리는 시계열 데이터를 위한 특별한 데이터 형식을 가지고 있어요. 10장: 시계열 데이터 형식을 쉽게 다루는 내용은 Darts의 데이터 구조에 대해 소개하고 있어요. 이 장의 파이썬 노트북은 이 Github 링크를 통해 확인할 수 있어요.
우선 데이터를 불러와 볼까요?
데이터 불러오기
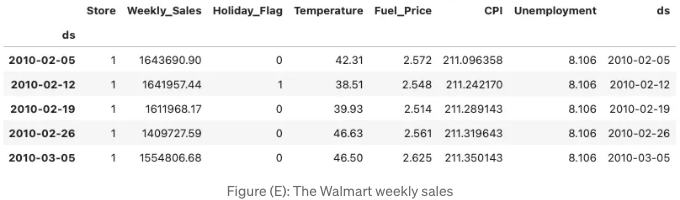
이번에는 Kaggle.com의 Walmart 데이터셋을 사용해 보겠어요. 이 데이터셋은 2010년 2월 5일부터 2012년 11월 1일까지의 매장 주간 매출 데이터를 포함하고 있어요:
- 날짜 — 판매 주의 주
- 상점 — 상점 번호
- 주간 판매 — 상점의 매출
- 공휴일 플래그 — 특별 공휴일 주 인지 여부 1 — 공휴일 주 0 — 비공휴일 주
- 온도 — 판매일의 온도
- 연료 가격 — 지역의 연료 비용
또한 소매 매출에 영향을 미칠 수 있는 두 가지 거시 경제 지표가 있습니다: 소비자물가지수 및 실업률. 데이터 집합은 먼저 Pandas 데이터 프레임으로로드됩니다.
%matplotlib inline
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from google.colab import drive
drive.mount('/content/gdrive')
path = '/content/gdrive/My Drive/data/time_series'
data = pd.read_csv(path + '/walmart.csv', delimiter=",")
data['ds'] = pd.to_datetime(data['Date'], format='%d-%m-%Y')
data.index = data['ds']
data = data.drop('Date', axis=1)
data.head()
데이터 준비를 위한 Darts의 주요 Python 클래스는 TimeSeries 클래스입니다. Darts는 값들을 다차원 배열로 저장하는데, 이 배열들은 다음과 같은 형태를 가지고 있어요 (시간, 차원, 샘플):
- 시간: 예를 들어 위 예시에서처럼 143주와 같은 시간 색인을 말해요.
- 차원: 다변량 시리즈의 "열"들을 나타냅니다.
- 샘플: 기간에 대한 값들을 의미합니다. 만약 10번째, 50번째, 90번째 백분위수에 대한 세 개의 샘플과 같이 확률론적 예측이라면, 세 개의 샘플이 존재하게 됩니다.
Walmart 상점 매출을 불러오기 위해 .from_group_dataframe() 함수를 사용할 거에요. 그룹 ID는 "Store"이며, 따라서 group_cols 매개변수는 "Store"여야 해요. 시간 색인은 "ds" 열이에요.
from darts import TimeSeries
darts_group_df = TimeSeries.from_group_dataframe(data, group_cols='Store', time_col='ds')
print("상점/그룹 수는:", len(darts_group_df))
print("시간 기간의 수는: ", len(darts_group_df[0]))
그룹/스토어의 수는 45개입니다. 기간의 수는 143개입니다.
.columns 함수를 사용하여 열을 나열할 수 있습니다:
darts_group_df[0].components;
열 이름은:
인덱스(['주간_매출', '휴일_플래그', '온도', '유종_가격', '소비자_물가_지수', '실업률'], dtype='object', name='구성요소')
로컬 모델 구축하기
시계열 예측에서는 두 가지 주요 유형의 모델이 있습니다: 로컬 모델과 글로벌 모델이 있습니다. 로컬 모델은 단일 시계열 또는 단변량 시계열에 사용되며 해당 시리즈에서 고유한 패턴과 트렌드를 포착하도록 설계되었습니다. 반면 글로벌 모델은 여러 시계열을 사용하여 개발되며 매개변수가 모든 시계열 전체에서 공유됩니다. 이를 통해 모델은 시계열 간에 일반적인 패턴과 관계를 포착하여 보다 정확한 예측을 할 수 있습니다.
각 가게에 대해 로컬 모델을 구축할 것입니다. 가게 1 판매를 위한 모델을 구축하기 위해 가게 1의 데이터인 "darts_group_df[0]"를 사용할 것입니다. 이를 훈련 및 테스트 데이터로 분할할 것입니다.
store1 = darts_group_df[0]
train = store1[:130]
test = store1[130:]
len(train), len(test) # (130, 13)
타겟 변수와 공변량을 정의해 봅시다.
타겟 및 과거, 미래 공변량
저희의 타겟 시리즈는 "Weekly_Sales"입니다. 다른 공변량도 포함할 수 있습니다. 시계열에서는 과거 공변량과 미래 공변량 두 가지 유형의 공변량이 있습니다. 과거 공변량은 현재 연구 시점까지의 변수입니다. 그리고 미래 공변량은 미래에서 관찰 가능한 변수입니다. 미래 값을 어떻게 알 수 있는지 궁금할 수도 있습니다. 우리는 미래 값을 알 수 있는 이유가 두 가지 있습니다. 첫 번째 이유는 그들이 달력 일수, 공휴일 또는 정기 프로모션과 같은 결정론적 값이기 때문입니다. 두 번째 이유는 날씨 예보와 같은 외부 소스의 예측 값입니다.
우리 경우에는 "Fuel_price"와 "CPI"를 과거 공선변수로 포함하고 "Holiday_flag"를 미래 공선변수로 포함할 것입니다. 훈련 데이터에서 목표 및 과거 공선변수는 130개의 데이터 포인트를 가지고 있습니다. 그러나 미래 공선변수는 미래로 확장되어야 하며, 테스트 데이터의 기간을 커버하기 위해 추가 13개의 데이터 포인트를 가지고 있어야 합니다.
target = train['Weekly_Sales'] #130 주
past_cov = train[['Fuel_Price', 'CPI']] # 130 주
future_cov = store1['Holiday_Flag'][:143] #143 주
기본 구문을 보여주기 위해 공선변수 없이 시작해봅시다.
(1) 유변량 데이터만, 공선변수 없음
아래 코드는 Darts의 LinearRegressionMode 클래스의 공식입니다.
from darts.models import LinearRegressionModel
n = 11
model = LinearRegressionModel(
lags=12,
multi_models = True # 기본값
)
주요 입력 매개변수는 다음과 같습니다:
- lags: 지연된 항목의 수
- multi_models: 이 하이퍼 매개변수는 다기간 예측 전략을 식별합니다. "True"이면 직접 예측 전략을 적용하고, 그렇지 않으면 재귀적 예측 전략을 적용합니다. 기본값은 "True"입니다.
"우리는 단변량 시리즈 'target'을 사용하여 모델을 훈련하고 다음 n 기간을 예측할 것입니다.
model.fit(target)
pred = model.predict(n)
pred.values()"
결과는 다음 n 기간을 예측한 것입니다. 위의 코드가 이미 직접 예측 전략을 실행했음을 주목하세요.
 "
"
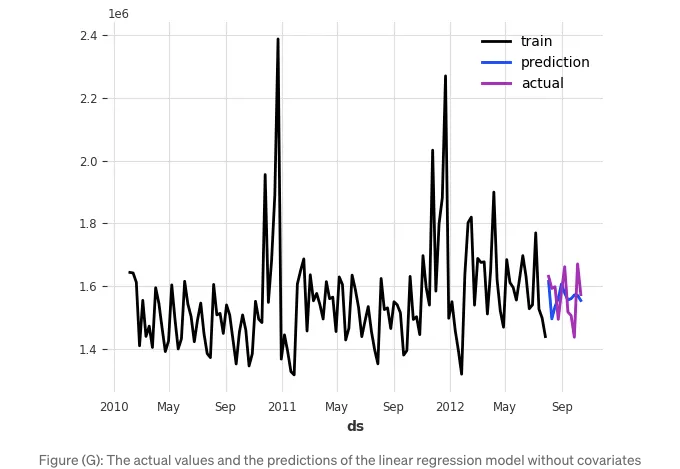
훈련 데이터, 예측 값 및 실제 값들을 함께 시각화해 보겠습니다:
import matplotlib.pyplot as plt
target.plot(label='훈련 데이터')
pred.plot(label='예측값')
test['Weekly_Sales'][:n].plot(label='실제값')
그림 (G)은 위의 플롯을 보여줍니다.
모델의 성능은 어떤가요? 평균 절대 오차 또는 평균 절대 백분율 오차를 사용해보는 것이 좋을 것 같아요.
from darts.metrics.metrics import mae, mape
print("평균 절대 오차:", mae(test['Weekly_Sales'][:n], pred))
print("평균 절대 백분율 오차:", mape(test['Weekly_Sales'][:n], pred))
MAPE는 4.07% 입니다:
- 평균 절대 오차: 63404.82928050449
- 평균 절대 백분율 오차: 4.070126403190025
이제 다른 공석요인을 추가해 봅시다.
과거 및 미래 공석요인 추가하기
공석요인은 추가 입력 변수입니다. Darts는 모델링을 위해 두 가지 유형의 공석요인을 취합니다. 하나는 과거 공석요인(lags_past_covariates)으로 된 지연된(lagged) 과거 공석요인이며, 다른 하나는 다소 혼란스러운 이름을 가진 미래 공석요인(lags_future_covariates)입니다. "미래 공석요인"은 이러한 공석요인의 미래 시간 단계에서의 값을 가리킵니다. 그리고 "지연된" 값은 이전 시간 단계의 미래 공석요인을 나타냅니다. 따라서 미래에서 t + n 단계에 해당하는 시간에 모델은 t부터 t + (n-1) 기능의 공석요인 값을 고려합니다.
from darts.models import LinearRegressionModel
n = 12
model = LinearRegressionModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5,6,7,8,9,10,11,12],
output_chunk_length=12,
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n)
pred.values()
상기된 매개변수 output_chunk_length에 대해 자세한 설명이 필요합니다. 이는 단변량 시리즈에서 샘플을 생성하는 데 관한 것입니다. Figure (H)에서는 y0부터 y15까지의 시리즈에서 생성된 샘플을 보여줍니다. 각 샘플은 입력 청크와 출력 청크를 포함합니다. 입력 청크의 길이가 5이고 출력 청크의 길이가 2인 것으로 가정해 봅시다. 첫 번째 샘플은 입력 청크로 y0부터 y4를, 출력 청크로 y5, y6을 가집니다. 창이 시리즈를 따라 이동하여 시리즈의 끝까지 샘플을 만듭니다.
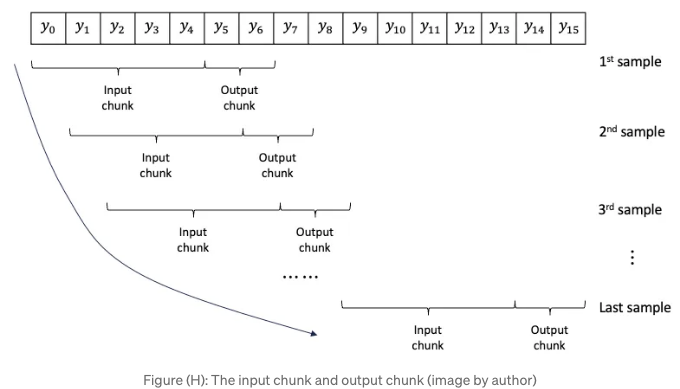
출력 청크의 길이는 예측 가능한 최대 길이를 정의합니다. 이를 12로 지정했습니다. 12보다 더 많이 예측하고자 한다면 에러 메시지를 받게 될 것입니다.
다음으로 하이퍼파라미터 multi_models=True는 다중 기간에 대한 확률적 예측을 위한 직접적인 전략을 정의합니다. 이는 각 미래 n 기간을 위해 별도의 n개 모델을 구축하는 전략을 의미합니다. 이는 기본 값이기 때문에 별도로 명시할 필요가 없습니다.

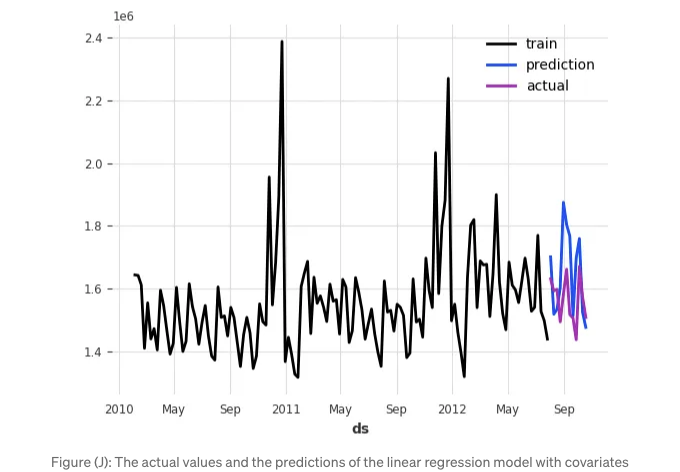
모델링과 예측을 한 뒤에는 실제 값과 예측값을 플롯에 함께 표시해보겠습니다.
import matplotlib.pyplot as plt
target.plot(label='훈련 데이터')
pred.plot(label='예측값')
test['Weekly_Sales'][:n].plot(label='실제값')
(J) 그림은 결과를 플롯한 것입니다:
성능을 측정해 봅시다.
print("평균 절대 오차:", mae(test['Weekly_Sales'][:n], pred))
print("평균 절대 백분율 오차:", mape(test['Weekly_Sales'][:n], pred))
- 평균 절대 오차: 119866.3976798996
- 평균 절대 백분율 오차: 7.738643655822244
MAPE는 7.73%로 이전 모델보다 낮습니다. 이전 모델을 선택할 수도 있었을 텐데요. 그 다음으로는 분위 예측을 생성하는 방법을 배워보겠습니다.
(3) 분위 예측
앞서 언급한대로 quantiles=[0.01,0.05,0.50,0.95,0.99]을 추가합니다. 샘플이 5개 있기 때문에 .predict()에서 num_samples=5를 지정할 것입니다.
from darts.models import LinearRegressionModel
n = 12
chunk_length = n
model = LinearRegressionModel(
lags=12,
lags_past_covariates=12,
lags_future_covariates=[0,1,2,3,4,5,6,7,8,9,10,11,12],
output_chunk_length=chunk_length,
likelihood = 'quantile', # 'quantile' 또는 'poisson'으로 설정할 수 있습니다.
# 'quantile'로 설정할 경우, sklearn.linear_model.QuantileRegressor가 사용됩니다.
# 'poisson'으로 설정할 경우, sklearn.linear_model.PoissonRegressor가 사용됩니다.
quantiles=[0.01, 0.05, 0.50, 0.95,0.99]
)
model.fit(target, past_covariates=past_cov, future_covariates=future_cov)
pred = model.predict(n, num_samples=5)
pred
각 기간에 대한 예측은 한 샘플 대신 5개의 샘플이 될 것입니다. (그래서 Darts의 데이터 형식을 "샘플"이라고 부릅니다.)

실제 값과 확률 예측을 그래플에 플로팅할 것입니다.
import matplotlib.pyplot as plt
target.plot(label='train')
pred.plot(label='prediction')
test['Weekly_Sales'][:n].plot(label='actual')
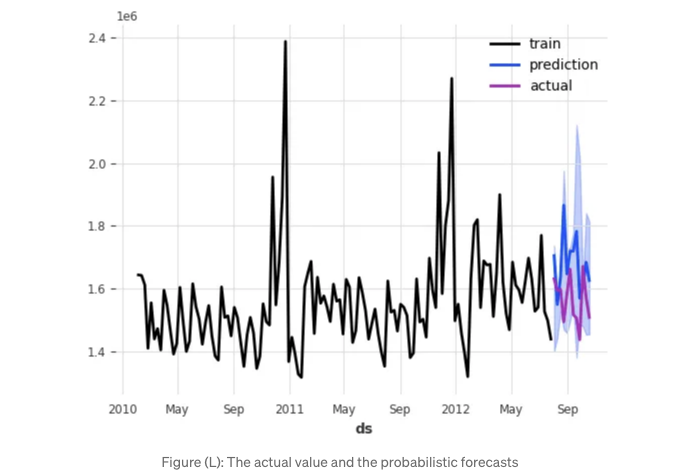
결론
이 장에서는 Darts 라이브러리를 사용하여 선형 회귀 모델 클래스를 배웠습니다. 이를 통해 여러 기간의 확률적 예측을 위한 선형 모델을 구축할 수 있습니다. 과거 및 미래 공변량을 포함한 구문 및 다기간 앞쪽 예측을 위한 직접 또는 재귀적 예측 전략의 옵션을 배웠습니다. 또한 모델을 분위수 확률적 예측을 위해 설정하는 방법도 배웠습니다.
이 장에서는 최신 회귀 기반 시계열 기법을 마무리합니다:
- 자동 ARIMA!
- 쉬운 시계열 데이터 형식
- 다기간 확률 예측을 위한 선형 회귀
다음 단원에서는 트리 기반 모델링 기법을 공부할 예정입니다:
- 트리 기반 시계열 예측에 대한 튜토리얼
- 다기간 시계열 예측에 대한 튜토리얼
- 다기간 시계열 확률 예측을 위한 트리 기반 XGB, LightGBM 및 CatBoost 모델
샘플 eBook 챕터(무료): 여기
- The Innovation Press, LLC의 스태프 여러분께 감사드립니다. 아름다운 형식으로 책을 재현하여 즐거운 독서 경험을 선사해 주셨습니다. 저희는 Teachable 플랫폼을 선택하여 eBook을 전 세계 독자에게 분배하며 무거운 오버헤드 없이 알찬 서비스를 제공합니다. 결제 거래는 Teachable.com에서 신뢰성 있고 안전하게 처리됩니다.
Teachable.com에서의 eBook: $22.50 여기에서 확인하세요
Amazon.com에서의 인쇄판: $65 여기서 확인하세요
- 인쇄판은 광택이 도는 표지, 컬러 프린트, 아름다운 Springer 폰트와 레이아웃이 매력적인 읽기를 위해 채택되었습니다. 7.5 x 9.25인치의 포털 크기로 대부분의 책장에 적합합니다.
- "이 책은 Kuo의 시계열 분석에 대한 심층적인 이해와 예측 분석 및 이상 탐지에 대한 응용을 입증하는 것입니다. 이 책은 독자들이 현실 세계의 도전 과제에 대처하는 데 필요한 기술을 제공합니다. 데이터 과학으로의 직업 전환을 추구하는 사람들에게 특히 가치 있는 자료입니다. Kuo는 전통적인 기법과 최신 기법을 자세히 탐구했습니다. Kuo는 신경망 및 다른 고급 알고리즘에 대한 논의를 통합함으로써, 분야의 최신 동향과 발전을 반영했습니다. 이것은 독자가 확립된 방법뿐만 아니라 데이터 과학 분야의 가장 최신이며 혁신적인 기법과 상호 작용할 준비가 되어 있는 것을 보장합니다. Kuo의 유쾌한 글쓰기 스타일로 책의 알기 쉽고 접근성이 향상되었습니다. 그는 복잡한 수학적 및 통계적 개념을 낯설지 않게 만들어 손실되지 않도록 했습니다."
모던 시계열 예측: 예측 분석과 이상 탐지를 위한
Chapter 0: 서문
Chapter 1: 소개
장 2: 비즈니스 예측용 선지자
장 3: 튜토리얼 I: 추세 + 계절성 + 휴일 및 이벤트
장 4: 튜토리얼 II: 추세 + 계절성 + 휴일 및 이벤트 + 자기회귀(AR) + 지연 회귀자 + 미래 회귀자
장 5: 시계열에서의 변화점 탐지
6장: 시계열 확률 예측을 위한 몬테카를로 시뮬레이션
7장: 시계열 확률 예측을 위한 분위수 회귀
8장: 시계열 확률 예측을 위한 일치 예측
9장: 시계열 확률 예측을 위한 일치화된 분위수 회귀
제 10 장: 자동 ARIMA!
제 11 장: 시계열 데이터 형식 쉽게 만들기
제 12 장: 다기간 확률 예측을 위한 선형 회귀
제 13 장: 트리 기반 시계열 모델용 피처 엔지니어링
Chapter 14: 다기간 시계열 예측을 위한 두 가지 주요 전략
Chapter 15: Tree 기반 XGB, LightGBM 및 CatBoost 모델에 대한 다기간 시계열 확률적 예측
Chapter 16: 시계열 모델링 기술의 진화
Chapter 17: 시계열 확률적 예측을 위한 Deep Learning 기반 DeepAR