내 꿈이었던 직업은 데이터 과학자가 되는 것이었습니다. 이 끝없는 여정은 2021년 9월 7일에 시작되었습니다. 고등학교 때부터 컴퓨터 과학에 관심을 가졌습니다. 삶은 나를 산업계의 생산 엔지니어로 이끌었습니다. 경력 동안 많은 데이터 주도 비즈니스 개발 프로젝트를 수행했습니다. 코로나 시기 이후, 내 열정을 찾고 미래로 나아가기로 결심했습니다. 파이썬 프로그래밍 언어를 배우기 시작했습니다. 학습 습관을 형성하는 데 74일이 걸렸습니다. 학습을 멈추지 않았습니다. 파이썬이 데이터 과학에서 가장 인기 있는 언어임을 알아보고 목표를 데이터 과학 분야로 변경했습니다. 제 생애 13년을 제조 엔지니어로 보낸 뒤에 데이터 과학이 경력 전환에 가장 적합한 분야임을 깨달았습니다.
항상 기초가 중요하다고 믿었습니다. 파이썬에 몰두했습니다. 6개월이 걸렸습니다. 동시에 Numpy, Pandas, Matplotlib, Seaborn, Scikit-learn 같은 파이썬의 인기 있는 라이브러리를 배우기 시작했습니다. 또한 데이터 과학 부트캠프에 등록했습니다. 성장 마인드셋을 채택했습니다. 가치 있는 데이터 과학 소셜 네트워크를 구축했습니다. 새로운 데이터 과학 기회를 얻을 수 있는 기술을 표현하는 자신감을 얻었습니다. 3개월 후에 데이터 관련 직무를 시작했습니다.
새로운 역할을 맡은 때에도 아직 달성해야 할 목표가 있었습니다. 기대치를 높였습니다. 프로그래밍의 객체 지향 접근법을 배웠습니다. 객체 지향 프로그래밍을 잘 이해하기 위해 자바 프로그래밍 언어를 공부했고, 이 접근법을 파이썬을 사용해 데이터 과학 프로젝트에 적용했습니다. 예측 분석을 위한 파이프라인을 구축했습니다. 이를 통해 확장 가능하고 유연한 모델과 유지 보수가 쉬운 보고 도구를 구축할 수 있었습니다. 상사들로부터 매우 감명깊은 피드백을 받았습니다. 이는 제 동기부여에 도움이 되었습니다.
이번 성공 이후, 경쟁 예측 분석 도구를 해킹하기 위해 역공학을 수행했습니다. 예측 분석을 위한 클러스터링 머신 러닝 알고리즘의 나만의 버전을 만들었고, 아직 개발 중에 있습니다.
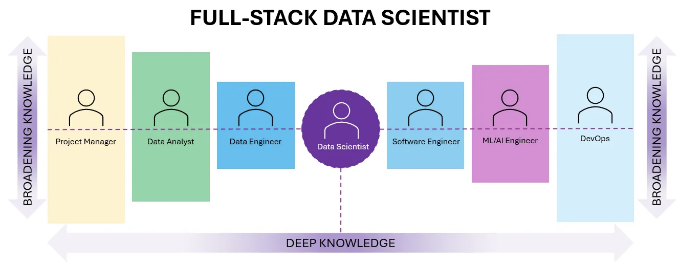
이 기간 동안 GPT 시스템에 대한 혹평에 실망했습니다. GPT 시스템을 해킹할 방법을 찾기 시작했고, V자형 직원이 데이터 과학에서 더 많은 잠재력을 가지고 있다는 것을 발견했습니다. 클라우드 컴퓨팅이 미래라고 생각했고, 풀 스택 데이터 과학자가 되는 목표를 세웠습니다. 이 모델에서 데이터 과학에 대한 심도 있는 지식을 개발하고, 데이터 엔지니어링, 데이터 분석, 프로젝트 관리, 소프트웨어 엔지니어링, ML/AI 엔지니어링 및 DevOps 지식을 확장하고 싶습니다.
AWS, Azure 및 GCP의 기본 클라우드 컴퓨팅 자격증 준비를 시작했습니다. Europe와 미국의 수요가 많은 기술을 찾기 위해 LinkedIn의 구인 게시판을 분석했으며, 아래 목록을 만들었습니다. 더 추가하고 싶은 항목이 있으면 댓글을 남겨주세요. 데이터 과학에 대한 열정이 계속됩니다.
- Agile
- Amazon Kinesis
- Apache Airflow
- Apache Cassandra
- Apache Hadoop
- Apache Hive
- Apache Kafka
- Apache Spark
- Apheris
- ARIMA
- Atlassian Bitbucket -AWS
- AWS Athena
- AWS Bedrock
- AWS Glue
- AWS Redshift
- AWS S3
- AWS SageMaker
- Azure
- Azure AI Services
- Azure CosmosDB
- Azure Data factory
- Azure Data Lake
- Azure Data storage
- Azure Databricks
- Azure HDInsight
- Azure Machine Learning Studio
- Azure SQL
- Azure Stream Analytics
- Azure Synapse Analytics
- Bash
- Bigquery
- C
- C#
- C++
- Catboost
- CI/CD
- Circle CI
- Databricks
- Datashield
- DAX
- DBT
- Deep Learning
- DevOps
- Digital Signal Processing
- Docker
- DOMO
- Elasticsearch
- ETL
- FA/FL
- Fast Fourier Analysis
- FastAPI
- Feature Engineering
- Fivetran
- FPGA
- GCP
- GCP Looker
- Git
- GitHub
- GitLab
- GraphQL
- IBM Cognos Analytics
- Java
- Javascript
- Jenkins
- Jupyter
- Kubeflow
- Kubernetes
- LangChain
- LightGBM
- Linux
- LLM
- LSTM
- Matplotlib
- Metabase
- Microsoft 365
- Microsoft Language Studio
- Microsoft SQL Server
- MLflow
- Monai
- MongoDB
- MySQL
- NLP
- NLTK
- NoSQL
- Numpy
- Nvidia Flare
- NWP
- OOP
- OpenAI API
- OpenCL
- Oracle
- Pandas
- PostgreSQL
- Power BI
- PySpark
- Pytest
- Python
- PyTorch
- QlikSense
- Qlikview
- R
- RAG
- Rest API
- SAS
- Scala
- Scikit-learn
- Scipy
- Scrum
- SDLC
- Snowflake
- Spacy
- Spinnaker
- SQL
- SQLAlchemy
- Streamlit
- Tableau
- Tensorflow
- Tensorflow Lite
- Time Series
- Travis CI
- Vector Database
- XGBoost