기계 학습의 분류 문제를 다룰 때 고려해야 할 중요한 요소 중 하나는 레이블을 정의하는 클래스의 균형입니다.
세 개의 클래스로 이루어진 상황을 상상해보세요. 초기 분석을 수행하여 정확도를 계산하면 93%를 얻을 수 있습니다. 그런 다음 더 깊게 들여다보는데, 데이터의 80%가 한 클래스에 속한다는 것을 알 수 있습니다. 이것이 좋은 징후인가요?
음, 그렇지 않습니다. 이 문서에서는 그 이유를 설명하고 있습니다.
초보자를 위한 Jupyter 노트북 설정하기
기계 학습 초보자라면, ML 문제를 해결하기 위해 두 가지 소프트웨어를 사용할 수 있다는 것을 모를 수 있습니다:
- Anaconda
- Google Colaboratory
Anaconda는 데이터 분석 및 기계 학습으로 예측을 하는 데 필요한 모든 라이브러리를 제공하는 데이터 과학 플랫폼입니다. 또한 데이터 과학자들이 데이터를 분석하는 데 사용하는 Jupyter Notebooks를 제공합니다. 따라서 Anaconda를 설치하면 필요한 모든 것을 갖추게 됩니다.
반면에 Google Colaboratory는 설정이 필요 없는 호스팅된 Jupyter Notebook 서비스로, 무료로 컴퓨팅 리소스 및 필요한 모든 라이브러리에 대한 액세스를 제공합니다. 따라서 PC에 아무것도 설치하지 않고 데이터를 분석하려면 이 솔루션을 선택할 수 있습니다.
마침내, 이 글에서 찾을 수 있는 모든 코드를 포함하는 공개 저장소를 만들었습니다. 이 저장소는 하나의 Jupyter Notebook에 있어 데이터 과학자들이 데이터를 분석하는 방식을 확인하고자 할 때 참고할 수 있습니다.
머신 러닝에서 불균형 데이터 소개
이 섹션은 머신 러닝에서 클래스 불균형 문제를 소개하고, 불균형 클래스가 흔한 시나리오를 다룹니다. 그러나 계속하기 전에, "불균형" 또는 "균형이 맞지 않는" 용어를 무시하고 사용할 수 있다는 점을 얘기합시다.
불균형 데이터 정의 및 모델 성능에 미치는 영향
상상해봐요. 당신이 100명의 학생들을 가르치는 수학 선생님인 상황을 상상해보세요. 이 학생들 중 90명은 수학을 잘하는 학생(Group A), 그리고 10명은 어려워하는 학생들(Group B)이라고 부를 수 있겠네요. 이 수업 구성은 기계 학습 세상에서 "불균형 데이터"로 알려져 있어요.
기계 학습에서 데이터는 컴퓨터에 예측이나 결정을 내리도록 가르치는 데 사용되는 교과서와 같아요. 불균형 데이터가 있다는 것은 컴퓨터가 배워야 하는 것들에 대한 예제 수에 큰 차이가 있다는 것을 의미해요. 우리의 수업 비유에 따르면, 과반이 되는 A 그룹보다 소수인 B 그룹의 학생 수가 적어요.
이제 우리의 기계 학습 모델의 성능은 불균형 데이터에 영향을 받아요. 예를 들어, 여기에는 몇 가지 영향들이 있어요:
- 편향된 학습. 대부분의 학생들이 수학을 잘하는 이 불균형한 수업에서 컴퓨터를 가르치면, 약간 편향될 수 있어요. 마치 컴퓨터가 수학 천재들에게 둘러싸인 듯하니, 모두가 수학 천재인 것으로 생각할 수 있어요. 기계 학습 용어로는 모델이 과반수 클래스 쪽으로 편향될 수 있어요. 그것은 일반적인 것(Group A)을 예측하는 데 능숙해지지만 드문 것(Group B)을 이해하는 데 어려움을 겪을 수 있어요. 당신이 학생들의 투표를 사용하여 수학 가르치기에 얼마나 능숙한지를 평가한다면, 90%의 학생이 수학을 잘하는 것이기 때문에 편향된 결과를 받을 수 있어요. 그런데 이 90% 중 대부분이 사설 수업을 듣고 있다면 당신은 알 수 없어요.
- 잘못된 정확도. 컴퓨터의 성능을 평가하려면 컴퓨터가 수학을 잘하는 학생이나 어려워하는 학생을 올바르게 식별한 횟수를 확인하여야 해요. A 그룹이 많기 때문에 컴퓨터는 대부분의 학생을 올바르게 맞출 수 있을 거예요. 그래서 정확도가 높아 보인다면 컴퓨터가 훌륭한 일을 하는 것처럼 보일 수 있어요. 그러나 B 그룹이 적기 때문에 실제로는 B 그룹에는 엉망진창일 수 있어요. 기계 학습에서 이 높은 정확도는 컴퓨터가 소수 클래스에서 얼마나 잘 수행되고 있는지 알려주지 않아서 잘못된 정보일 수 있어요.
간단히 말해서, 불균형 데이터는 컴퓨터에 학습시키려는 서로 다른 사례들에 대해 불균형한 예제 수가 있다는 것을 의미하며, 특히 드물게 발생하는 경우를 처리할 때 머신러닝 모델의 성능에 심각한 영향을 미칠 수 있습니다.
어쨌든, 데이터가 불균형할 것으로 예상되는 경우도 있습니다.
이것들에 대해 설명하기 전에 먼저 어떤 경우에 불균형 데이터가 일반적인지 살펴보겠습니다.
불균형 데이터가 흔한 시나리오
현실적인 시나리오에서는 데이터가 불균형적인 경우가 많이 발생합니다. 만약 그렇지 않다면, 오류가 있는 것을 의미합니다.
예를 들어 의학 분야를 생각해보겠습니다. 대규모 인구 중에서 희귀 질병을 찾으려고 할 때, 데이터는 불균형해야 합니다. 그렇지 않으면 우리가 찾고 있는 질병이 희귀하지 않다는 것을 의미합니다.
사기 탐지의 경우도 마찬가지입니다. 금융 기관의 데이터 과학자로서 신용 카드에서 사기 거래를 분석하고 있을 때, 불균형한 데이터를 발견해야 합니다. 그렇지 않으면 사기 거래가 비-사기 거래만큼 자주 발생한다는 것을 의미합니다.
불균형 문제 이해하기
이제 Python 코드와 함께 실제 상황에 대해 알아볼까요? 이를 통해 다음을 보여줄 수 있습니다:
- 그래픽을 기반으로 한 주요 및 소수 클래스 간의 차이.
- 불균형한 데이터에 영향을 받는 평가 지표들.
- 불균형한 데이터에 영향을 받지 않는 평가 지표들.
주요 및 소수 클래스 간의 차이
수학 선생님인 당신이라고 가정해보겠습니다. 이번에는 1000명의 학생으로 이루어진 대규모 강의를 하고 있습니다. 머신러닝을 사용하여 어떠한 분류를 수행하기 전에, 데이터가 불균형인지 확인하기로 결정했습니다.
하나의 방법은 분포를 시각화하는 것입니다. 예를 들어, 다음과 같이:
import numpy as np
import matplotlib.pyplot as plt
# 재현 가능성을 위해 랜덤 시드 설정
np.random.seed(42)
# 다수 클래스 (Class 0)를 위한 데이터 생성
majority_class = np.random.normal(0, 1, 900)
# 소수 클래스 (Class 1)를 위한 데이터 생성
minority_class = np.random.normal(3, 1, 100)
# 다수 클래스와 소수 클래스 데이터 결합
data = np.concatenate((majority_class, minority_class))
# 클래스 레이블 생성
labels = np.concatenate((np.zeros(900), np.ones(100)))
# 클래스 분포 플로팅
plt.figure(figsize=(8, 6))
plt.hist(data[labels == 0], bins=20, color='blue', alpha=0.6, label='다수 클래스 (Class 0)')
plt.hist(data[labels == 1], bins=20, color='red', alpha=0.6, label='소수 클래스 (Class 1)')
plt.xlabel('특성 값')
plt.ylabel('빈도수')
plt.title('불균형 데이터셋의 클래스 분포')
plt.legend()
plt.show()
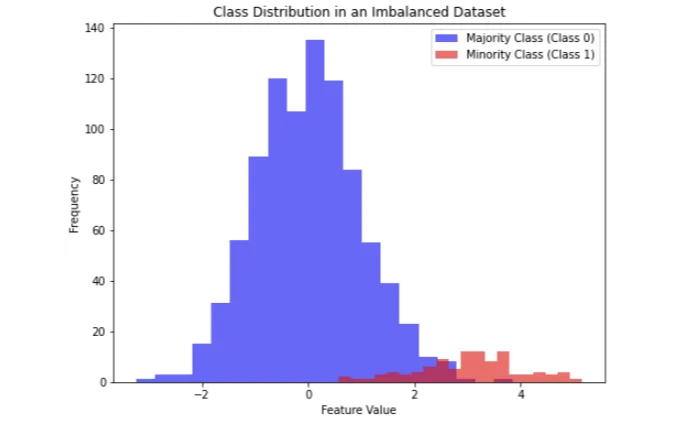
이 Python 예제에서는 두 개의 클래스를 만들었습니다:
- 주요 클래스 (클래스 0). 이 클래스는 데이터 포인트의 대다수를 나타냅니다. 평균이 0이고 표준 편차가 1인 정규 분포에서 900개의 데이터 포인트를 생성했습니다. 실제 시나리오에서는 매우 흔하거나 전형적인 것을 나타낼 수 있습니다.
- 소수 클래스 (클래스 1). 이 클래스는 데이터 포인트의 소수를 나타냅니다. 평균이 3이고 표준 편차가 1인 정규 분포에서 100개의 데이터 포인트를 생성했습니다. 이 클래스는 의도적으로 흔하지 않게 만들어져 불균형 데이터셋을 시뮬레이션합니다. 실제로는 드문 사건이나 이상을 나타낼 수 있습니다.
다음으로, 이 두 클래스를 해당 레이블 (주요 클래스에 대한 0 및 소수 클래스에 대한 1)과 함께 단일 데이터셋으로 결합합니다. 마지막으로, 히스토그램을 사용하여 클래스 분포를 시각화합니다. 히스토그램에서:
- 파란 막대는 주요 클래스 (클래스 0)를 나타내며, 좌측에 더 크고 더 빈번한 막대입니다.
- 빨간 막대는 소수 클래스 (클래스 1)를 나타내며, 우측에 더 작고 덜 빈번한 막대입니다.
이 시각화는 불균형 데이터셋에서 주요 및 소수 클래스 간의 차이를 명확하게 보여줍니다. 주요 클래스는 소수 클래스보다 훨씬 많은 데이터 포인트를 가지고 있으며, 이는 불균형 데이터의 일반적인 특성입니다.
클래스 불균형을 다루는 또 다른 방법은 분포를 통해 직접적으로 빈도를 살펴보는 것입니다. 예를 들어, 다음과 같이 할 수 있습니다:
import numpy as np
import matplotlib.pyplot as plt
# 재현성을 위해 임의의 시드 설정
np.random.seed(42)
# 주요 클래스 (클래스 0)에 대한 데이터 생성
majority_class = np.random.normal(0, 1, 900)
# 소수 클래스 (클래스 1)에 대한 데이터 생성
minority_class = np.random.normal(3, 1, 100)
# 주요 및 소수 클래스 데이터 결합
data = np.concatenate((majority_class, minority_class))
# 클래스에 대한 레이블 생성
labels = np.concatenate((np.zeros(900), np.ones(100))
# 각 클래스의 빈도 카운트
class_counts = [len(labels[labels == 0]), len(labels[labels == 1])]
# 막대 그래프를 사용하여 클래스 빈도 플로팅
plt.figure(figsize=(8, 6))
plt.bar(['주요 클래스 (클래스 0)', '소수 클래스 (클래스 1)'], class_counts, color=['blue', 'red'])
plt.xlabel('클래스')
plt.ylabel('빈도')
plt.title('불균형 데이터셋의 클래스 빈도')
plt.show()
아래와 같이 테이블 태그를 마크다운 형식으로 변경해주세요.
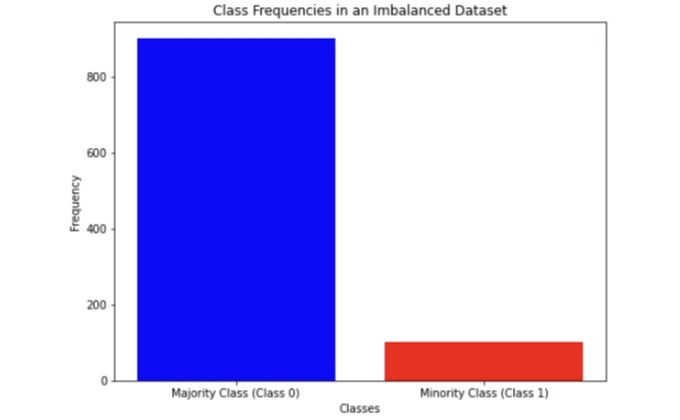
그러니까, 이 경우에는 클래스에 속하는 데이터의 모든 발생을 계산하는 내장 메소드 len()을 사용할 수 있습니다.
이상 데이터로 영향을 받는 일반 평가 지표
이상 데이터에 영향을 받는 모든 평가 지표를 설명하려면 먼저 다음을 정의해야 합니다:
- True positive (TP). 분류기가 조건이나 특성의 존재를 올바르게 예측한 값
- True negative (TN). 분류기가 조건이나 특성의 부재를 올바르게 예측한 값
- False positive (FP). 분류기가 특정 조건이나 속성이 존재하는 것으로 잘못 예측한 값
- False negative (FN). 분류기가 특정 조건이나 속성이 존재하지 않는 것으로 잘못 예측한 값
다음은 불균형 데이터가 영향을 미치는 일반적인 평가 지표입니다:
- 정확도. 데이터 세트에서 올바르게 예측된 인스턴스의 비율을 측정합니다.
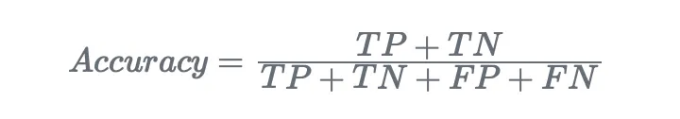
파이썬에서 정확도 지표를 계산하는 방법에 대한 예제를 만들어보겠습니다:
from sklearn.metrics import accuracy_score
# 실제 레이블
true_labels = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 모델이 예측한 레이블
predicted_labels = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
accuracy = accuracy_score(true_labels, predicted_labels)
print("정확도:", accuracy)
결과는:
정확도: 0.5;
정확도는 불균형한 데이터를 다룰 때 혼란을 줄 수 있습니다.
실제로 95%가 A 클래스에 속하고 5%만 B 클래스에 속하는 데이터 세트가 있다고 가정해 봅시다. 모델이 모든 인스턴스를 A 클래스로 예측한다면 95%의 정확도를 달성할 것입니다. 하지만 이는 반드시 모델이 좋다는 것을 의미하지는 않습니다. 이는 단지 클래스 불균형을 악용한 것뿐입니다. 다시 말해, 이 메트릭은 소수 클래스 (B 클래스)를 얼마나 잘 식별하는지를 고려하지 않습니다.
- 정밀도. 이것은 모든 예측된 긍정 인스턴스 중 올바르게 예측된 긍정 인스턴스의 비율을 측정합니다.
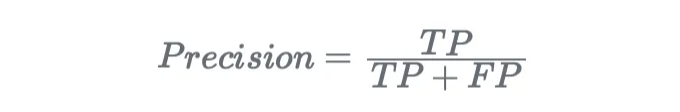
한 예제를 통해 Python에서 정밀도 지표를 계산하는 방법을 살펴보겠습니다:
from sklearn.metrics import precision_score
# True labels
true_labels = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# Predicted labels by a model
predicted_labels = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
precision = precision_score(true_labels, predicted_labels)
print("Precision:", precision)
결과는 다음과 같습니다:
정밀도: 0.5;
불균형 데이터 세트에서는 정밀도가 매우 오해를 일으킬 수 있습니다.
실제로, 모델이 하나의 인스턴스만을 긍정적(클래스 B)으로 분류하고 그게 맞는 경우, 정밀도는 100%가 될 것입니다. 그러나 이는 모델이 소수 클래스에서의 성능을 나타내는 것이 아닐 수 있습니다. 왜냐하면 많은 긍정적 인스턴스를 놓칠 수 있기 때문입니다.
- 재현율 (또는 민감도). 재현율은 또한 민감도 또는 진양성율로 알려져 있으며, 올바르게 예측된 긍정적 인스턴스의 비율을 측정합니다:
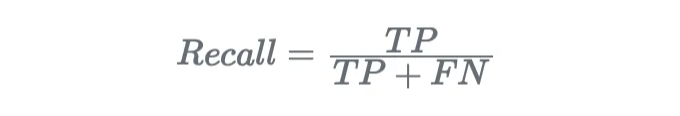
파이썬을 사용하여 재현율 지표를 계산하는 예제를 만들어 보겠습니다:
from sklearn.metrics import recall_score
# 실제 레이블
true_labels = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 모델이 예측한 레이블
predicted_labels = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
recall = recall_score(true_labels, predicted_labels)
print("재현율:", recall)
결과는:
재현율: 1.0;
재현율은 불균형한 데이터셋에서도 잘못된 정보를 줄 수 있습니다. 특히 모든 긍정적인 인스턴스를 포착하는 것이 중요할 때에는요.
만약 모델이 더 많은 양의 양성 인스턴스가 있는 상황에서 한 인스턴스만을 양성(Class B)으로 예측할 경우, 재현율이 매우 낮을 수 있습니다. 이는 모델이 소수 클래스의 중요한 부분을 놓치고 있음을 나타낼 수 있습니다. 이는 이 메트릭이 false positives를 고려하지 않기 때문에 발생합니다.
- F1 스코어. F1 스코어는 정밀도와 재현율의 조화평균입니다. 정밀도와 재현율 사이의 균형을 제공합니다:
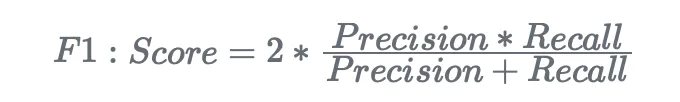
파이썬을 사용하여 F1 스코어 메트릭을 계산하는 예제를 만들어봅시다:
from sklearn.metrics import f1_score
# True labels
true_labels = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# Predicted labels by a model
predicted_labels = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# Calculate and print F1-score
f1 = f1_score(true_labels, predicted_labels)
print("F1-Score:", f1)
결과는:
F1-Score: 0.6666666666666666
이 메트릭은 정밀도와 재현율을 사용하여 생성되었기 때문에 데이터 불균형에 영향을 받을 수 있습니다.
하나의 클래스가 지배적이고 (다수 클래스인 경우), 그 모델이 해당 클래스를 편향으로 처리하는 경우, F1 점수는 소수 클래스의 낮은 재현율에도 높은 정밀도 때문에 상대적으로 높을 수 있습니다. 이는 모델의 전체 효과를 잘못 나타낼 수 있습니다.
데이터 불균형에 영향을 받지 않는 가장 많이 사용되는 평가 지표
이제 클래스 불균형에 영향을 받지 않는 평가 지표 중 가장 많이 사용되는 두 가지를 설명하겠습니다.
- 혼동 행렬. 혼동 행렬은 분류 알고리즘의 성능을 요약하는 표입니다. 이는 True Positives (TP), True Negatives (TN), False Positives (FP) 및 False Negatives (FN)의 자세한 분석을 제공합니다. 특히, 주 대각선(왼쪽 위에서 오른쪽 아래)은 TP와 TN을 보여주며, 보조 대각선(왼쪽 아래에서 오른쪽 위)은 FP와 FN을 나타냅니다. 따라서, 머신 러닝 모델이 데이터를 올바르게 분류할 경우, 혼동 행렬의 주 대각선은 가장 높은 값을, 보조 대각선은 가장 낮은 값을 보고해야 합니다.
파이썬에서 예제를 보여드리겠습니다:
from sklearn.metrics import confusion_matrix
# True and predicted labels
true_labels = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
predicted_labels = [0, 0, 0, 0, 0, 1, 1, 1, 0, 1]
# Create confusion matrix
cm = confusion_matrix(true_labels, predicted_labels)
# Print confusion matrix
print("Confusion Matrix:")
print(cm)
그리고 저희가 얻은 것은:
혼동 행렬:
[[5 0]
[1 4]]
이 혼동 행렬은 주 대각선에 결과가 가장 많기 때문에(10개 중 9개) 좋은 분류기를 나타냅니다. 이는 분류기가 5개의 TP와 4개의 TN을 예측했다는 것을 의미합니다.
그에 비해, 보조 대각선은 낮은 결과를 보여줍니다(10개 중 1개). 이는 분류기가 1개의 FP와 0개의 FN을 예측했음을 의미합니다.
그러므로 이것은 좋은 분류기로 이어집니다.
따라서 혼동 행렬은 모델 성능의 자세한 분석을 제공하여 각 클래스에 대해 올바르게 또는 잘못 분류된 인스턴스의 수를 몇 초 안에 알 수 있도록합니다.
- AUC/ROC 커브. ROC는 "Receiver Operating Characteristic"의 약자로, 참 긍정률 (TPR)을 다른 임계값에서 거짓 긍정률 (FPR)에 대비하여 그래픽 방식으로 그리는 분류기를 평가하는 방법입니다.
우리는 다음과 같이 정의합니다:
- TPR을 민감도로(우리가 말했듯이 recall로도 불릴 수 있음).
- FPR을 1-특이도로 정의합니다.
특이도는 분류기가 모든 부정적인 샘플을 찾는 능력을 의미합니다:
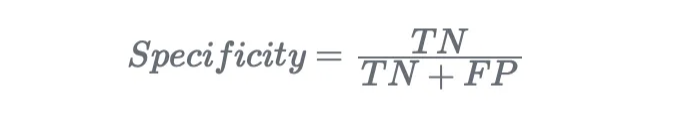
AUC는 ROC 곡선 아래 영역을 나타내며 "곡선 아래 영역"을 의미합니다. 이는 0에서 1사이의 전체적인 성능 지표로, 1은 분류기가 레이블의 100%를 실제 값으로 예측한다는 것을 의미하며, 서로 다른 분류기들을 비교할 때 더 적합합니다.
만약 이진 분류 문제를 공부한다고 가정해봅시다. 파이썬에서 AUC 곡선을 그리는 방법은 다음과 같습니다:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
# 무작위로 이진 분류 데이터세트 생성
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
# 데이터세트를 학습 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 학습 데이터에서 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 테스트 데이터에 대해 확률 예측
probs = model.predict_proba(X_test)
# ROC 곡선 및 AUC 점수 계산
fpr, tpr, thresholds = roc_curve(y_test, probs[:, 1])
auc_score = roc_auc_score(y_test, probs[:, 1])
# ROC 곡선 그리기
plt.plot(fpr, tpr, label='AUC = {:.2f}'.format(auc_score))
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
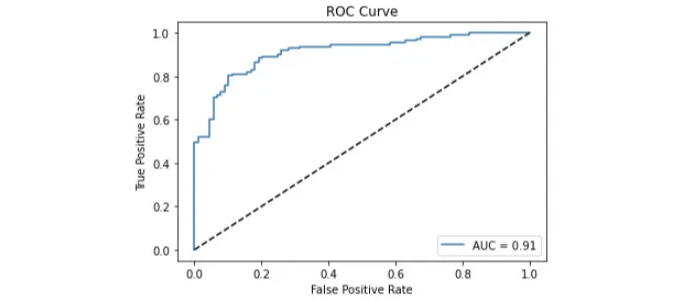
그 코드로는 다음을 할 수 있어요:
- make_classification 메서드로 분류 데이터셋을 생성했어요.
- 데이터셋을 훈련 세트와 테스트 세트로 나눴어요.
- Logistic Regression 분류기로 훈련 세트를 fit했어요.
- predict_proba() 메서드로 테스트 데이터에 대한 예측을 만들었어요.
- ROC 곡선과 AUC 점수를 계산했어요.
- AUC 곡선을 그렸어요.
불균형 데이터 다루는 기술
이 섹션에서는 불균형 데이터를 다루는 몇 가지 기술을 다루겠어요.
다시 말해, 우리는 불균형 데이터를 다루는 방법에 대해 이야기할 것입니다.
리샘플링
불균형 데이터셋을 처리하는 데 널리 사용되는 방법론은 리샘플링입니다. 이 방법론은 두 가지 다른 프로세스로 나눌 수 있습니다:
- 오버샘플링. 소수 클래스에 더 많은 예제를 추가하는 것을 의미합니다.
- 언더샘플링. 다수 클래스에서 샘플을 제거하는 것을 의미합니다.
두 가지 방법에 대해 설명해 보겠습니다.
Oversampling
Oversampling은 소수 클래스의 인스턴스 수를 늘려 클래스 분포를 균형있게 만드는 재표본화 기술입니다. 주로 기존 인스턴스를 복제하거나 소수 클래스와 유사한 합성 데이터 포인트를 생성함으로써 수행됩니다. 목표는 모델이 훈련 중에 두 클래스의 더 균형 잡힌 표현을 볼 수 있도록 하는 것입니다.
장점:
- 모델 성능 향상. Oversampling은 소수 클래스의 특성을 더 잘 학습할 수 있도록 도와주어 전체적인 분류 성능을 향상시킬 수 있습니다, 특히 소수 클래스에 대해서 더욱 효과적입니다.
- 정보 보존. 언더샘플링과는 달리, 오버샘플링은 과반 클래스의 모든 인스턴스를 보존하여 정보의 손실이 없도록 합니다.
단점:
- 과적합의 위험. 중복되거나 합성된 인스턴스는 적절하게 제어되지 않으면, 특히 합성 데이터가 기존 데이터와 너무 유사한 경우에는 과적합을 유발할 수 있습니다.
- 훈련 시간 증가. 오버샘플링으로 인한 더 큰 데이터셋은 머신러닝 알고리즘의 학습 시간이 더 오래 걸릴 수 있습니다.
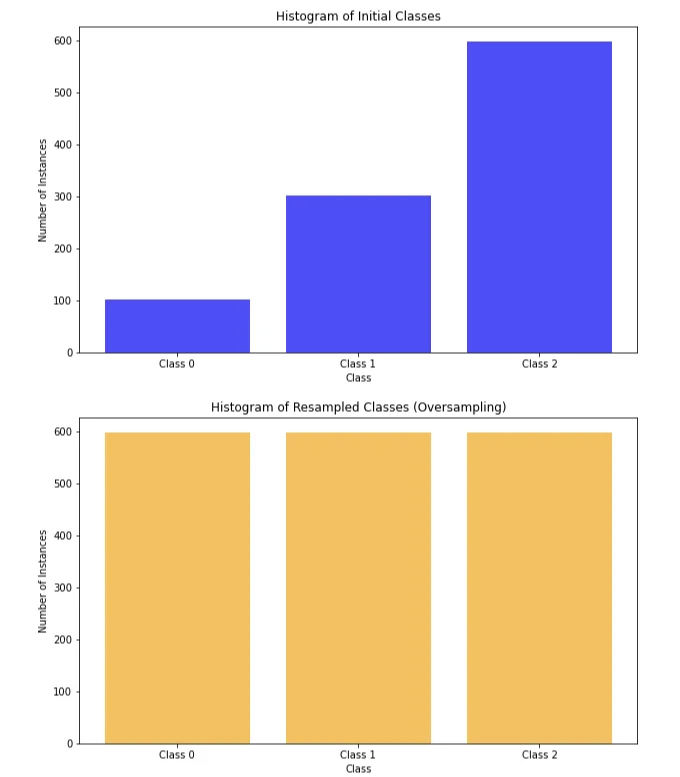
Python에서 불균형한 데이터셋에 대한 오버샘플링 기술을 어떻게 활용할 수 있는지 알아보겠습니다:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from imblearn.over_sampling import RandomOverSampler
from collections import Counter
# 3개 클래스를 가지는 불균형 데이터셋 생성
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.3, 0.6], # 클래스 불균형
random_state=42
)
# 초기 클래스들의 히스토그램 출력
plt.figure(figsize=(10, 6))
plt.hist(y, bins=range(4), align='left', rwidth=0.8, color='blue', alpha=0.7)
plt.title("초기 클래스들의 히스토그램")
plt.xlabel("클래스")
plt.ylabel("인스턴스 개수")
plt.xticks(range(3), ['클래스 0', '클래스 1', '클래스 2'])
plt.show()
# RandomOverSampler를 사용하여 오버샘플링 적용
oversampler = RandomOverSampler(sampling_strategy='auto', random_state=42)
X_resampled, y_resampled = oversampler.fit_resample(X, y)
# 재샘플링된 클래스들의 히스토그램 출력
plt.figure(figsize=(10, 6))
plt.hist(y_resampled, bins=range(4), align='left', rwidth=0.8, color='orange', alpha=0.7)
plt.title("재샘플링된 클래스들의 히스토그램 (오버샘플링)")
plt.xlabel("클래스")
plt.ylabel("인스턴스 개수")
plt.xticks(range(3), ['클래스 0', '클래스 1', '클래스 2'])
plt.show()
언더샘플링
언더샘플링은 머신 러닝에서 사용되는 샘플링 기술 중 하나로, 주요 클래스의 인스턴스 수를 줄여 클래스 분포를 균형있게 만드는 것에 초점을 맞춥니다. 주로 주요 클래스에서 인스턴스를 무작위로 제거해 두 클래스가 보다 균형 잡힌 표현이 되도록 하는 방식입니다. 여기에는 언더샘플링의 장단점이 있습니다.
장점:
- 과적합 위험이 감소합니다. 언더샘플링은 오버샘플링과 비교하여 과적합 위험을 줄입니다. 주요 클래스의 인스턴스 수를 줄이면 모델이 학습 데이터를 외워버리는 경향이 줄어들고 새로운, 보이지 않는 데이터에 대해 더 잘 일반화할 수 있습니다.
- 빠른 학습 시간입니다. 언더샘플링을 거친 후 데이터셋에는 더 이상 적은 인스턴스가 있기 때문에 머신 러닝 알고리즘의 학습 시간을 줄일 수 있습니다. 보통 데이터가 적을수록 학습 시간이 더 빨라집니다.
단점:
- 정보 손실. 언더샘플링은 주요 클래스에서 인스턴스를 버림으로써 귀중한 정보 손실을 야기할 수 있습니다. 만일 버려진 인스턴스에 주요 클래스의 전반적인 이해에 기여하는 중요한 특성이 있다면 문제가 될 수 있습니다.
- 편향된 모델의 위험. 주요 클래스에서 인스턴스를 제거하면 편향된 모델을 유발할 수 있으며, 이는 실제 주요 클래스의 분포를 정확하게 포착하지 못할 수 있습니다. 이러한 편향은 모델이 실제 세계 상황에 일반화하는 능력에 영향을 줄 수 있습니다.
- 주요 클래스에서의 성능 저하 가능성. 언더샘플링은 주요 클래스에서 성능이 나쁜 모델을 유발할 수 있습니다. 왜냐하면 학습할 정보가 적기 때문입니다. 이는 주요 클래스의 인스턴스를 잘못 분류할 수 있게 됩니다.
- 샘플링 비율에 민감함. 언더샘플링 정도는 모델의 성능에 중대한 영향을 미칠 수 있습니다. 샘플링 비율이 과도하면 주요 클래스의 중요한 정보가 손실될 수 있고, 너무 보수적이면 클래스 불균형 문제가 계속 남을 수 있습니다.
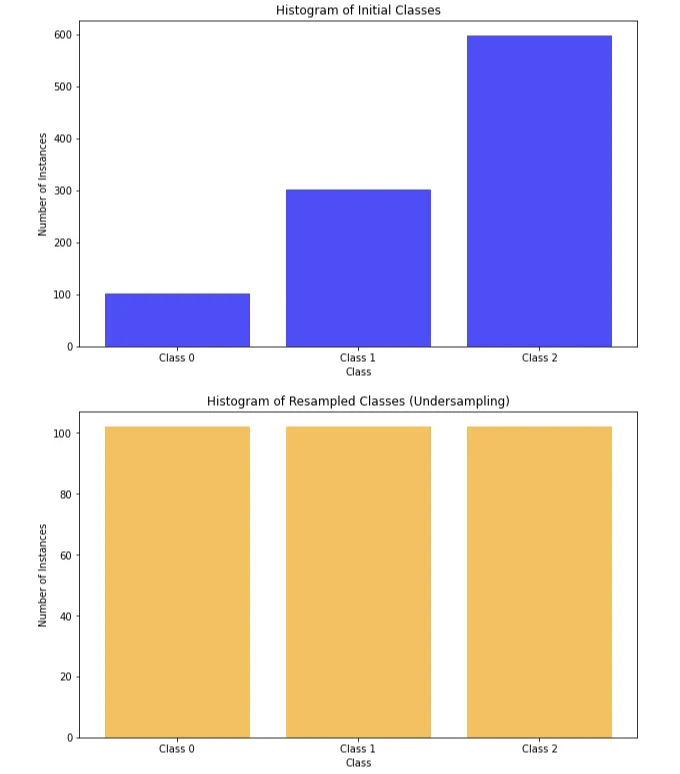
아래는 파이썬에서 불균형 데이터셋에 대해 언더샘플링 기술을 활용하는 방법입니다:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from imblearn.under_sampling import RandomUnderSampler
from collections import Counter
# 3개 클래스를 갖는 불균형 데이터셋 생성
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.3, 0.6], # 클래스 불균형
random_state=42
)
# 초기 클래스 히스토그램 출력
plt.figure(figsize=(10, 6))
plt.hist(y, bins=range(4), align='left', rwidth=0.8, color='blue', alpha=0.7)
plt.title("Initial Classes의 히스토그램")
plt.xlabel("클래스")
plt.ylabel("인스턴스 수")
plt.xticks(range(3), ['클래스 0', '클래스 1', '클래스 2'])
plt.show()
# RandomUnderSampler를 사용하여 언더샘플링 적용
undersampler = RandomUnderSampler(sampling_strategy='auto', random_state=42)
X_resampled, y_resampled = undersampler.fit_resample(X, y)
# 재샘플링 클래스의 히스토그램 출력
plt.figure(figsize=(10, 6))
plt.hist(y_resampled, bins=range(4), align='left', rwidth=0.8, color='orange', alpha=0.7)
plt.title("Resampled Classes (언더샘플링)의 히스토그램")
plt.xlabel("클래스")
plt.ylabel("인스턴스 수")
plt.xticks(range(3), ['클래스 0', '클래스 1', '클래스 2'])
plt.show()
아래는 Markdown 형식으로 표를 변경한 것입니다.
성능 비교
다음은 Python 예제를 만들어보겠습니다.
- 균형이 맞지 않은 데이터 세트를 만듭니다.
- 언더샘플링 및 오버샘플링을 진행합니다.
- 언더샘플링 및 오버샘플링된 데이터 세트에 대해 훈련 및 검증 세트를 만들고, KNN 분류기로 학습합니다.
- 언더샘플링 및 오버샘플링된 데이터 세트의 정확도를 비교합니다.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
from sklearn.metrics import accuracy_score
# 3개의 클래스를 가진 불균형 데이터셋 생성
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.3, 0.6], # 클래스 불균형
random_state=42
)
# 원본 데이터셋을 학습 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# RandomOverSampler를 사용하여 오버샘플링 적용
oversampler = RandomOverSampler(sampling_strategy='auto', random_state=42)
X_train_oversampled, y_train_oversampled = oversampler.fit_resample(X_train, y_train)
# RandomUnderSampler를 사용하여 언더샘플링 적용
undersampler = RandomUnderSampler(sampling_strategy='auto', random_state=42)
X_train_undersampled, y_train_undersampled = undersampler.fit_resample(X_train, y_train)
# 원본 학습 세트에 KNN 분류기 피팅
knn_original = KNeighborsClassifier(n_neighbors=5)
knn_original.fit(X_train, y_train)
# 오버샘플링된 학습 세트에 KNN 분류기 피팅
knn_oversampled = KNeighborsClassifier(n_neighbors=5)
knn_oversampled.fit(X_train_oversampled, y_train_oversampled)
# 언더샘플링된 학습 세트에 KNN 분류기 피팅
knn_undersampled = KNeighborsClassifier(n_neighbors=5)
knn_undersampled.fit(X_train_undersampled, y_train_undersampled)
# 학습 세트에 대한 예측 수행
y_train_pred_original = knn_original.predict(X_train)
y_train_pred_oversampled = knn_oversampled.predict(X_train_oversampled)
y_train_pred_undersampled = knn_undersampled.predict(X_train_undersampled)
# 테스트 세트에 대한 예측 수행
y_test_pred_original = knn_original.predict(X_test)
y_test_pred_oversampled = knn_oversampled.predict(X_test)
y_test_pred_undersampled = knn_undersampled.predict(X_test)
# 학습 세트의 정확도 계산 및 출력
print("원본 학습 세트 정확도:", accuracy_score(y_train, y_train_pred_original))
print("오버샘플링된 학습 세트 정확도:", accuracy_score(y_train_oversampled, y_train_pred_oversampled))
print("언더샘플링된 학습 세트 정확도:", accuracy_score(y_train_undersampled, y_train_pred_undersampled))
# 테스트 세트의 정확도 계산 및 출력
print("\n원본 테스트 세트 정확도:", accuracy_score(y_test, y_test_pred_original))
print("오버샘플링된 테스트 세트 정확도:", accuracy_score(y_test, y_test_pred_oversampled))
print("언더샘플링된 테스트 세트 정확도:", accuracy_score(y_test, y_test_pred_undersampled))
결과:
원본 학습 세트 정확도: 0.9125
오버샘플링된 학습 세트 정확도: 0.9514767932489452
언더샘플링된 학습 세트 정확도: 0.85
원본 테스트 세트 정확도: 0.885
오버샘플링된 테스트 세트 정확도: 0.79
언더샘플링된 테스트 세트 정확도: 0.805
정확도 지표 비교를 통해 이러한 방법론의 특징을 확인할 수 있습니다:
- 오버샘플링 기술은 KNN 모델이 오버피팅되고 있는 것을 시사하며, 이는 오버샘플링 그 자체 때문입니다.
- 언더샘플링 기술은 KNN 모델이 편향될 수 있음을 시사하며, 이는 언더샘플링 그 자체 때문입니다.
- 리샘플링 없이 모델을 학습시킨 것은 데이터의 불균형으로 정확도가 잘못 이끌 수 있음을 보여줍니다.
따라서 이 경우, 가능한 해결책은 오버샘플링을 사용하고 KNN의 하이퍼파라미터를 조정하여 오버피팅을 피할 수 있는지 확인해 보는 것입니다.
앙상블
불균형 데이터를 다루는 또 다른 방법은 앙상블 학습을 사용하는 것입니다. 특히, 랜덤 포레스트(Random Forest, RF)는 여러 의사 결정 트리 모델의 앙상블인데, 주 클래스에 편향되지 않는 내재적 능력으로 널리 사용되는 머신 러닝 모델입니다.
그 이유는 다음과 같습니다:
- Bootstrap 샘플링. RF 모델은 무작위 샘플링을 사용하여 작동합니다. 즉, 다양한 의사 결정 트리 모델을 훈련하는 동안, 선택된 데이터는 전체 데이터 세트의 무작위 하위 집합을 사용하고, 데이터는 대체됩니다. 이는 평균적으로 각 의사 결정 트리가 원래 데이터의 약 2/3에 대해 훈련됩니다. 결과적으로 소수 클래스의 일부 인스턴스가 의사 결정 트리를 작성하는 데 사용된 하위 집합에 포함될 가능성이 높습니다. 샘플 선택의 이 랜덤성은 주요 및 소수 클래스의 영향을 균형있게 조정하는 데 도움이 됩니다.
- 무작위 특성 선택. 데이터를 무작위화하는 것 외에도, 랜덤 포레스트는 각 트리의 각 노드에 대해 무작위로 특성을 선택합니다. 즉, 분할할 때 고려할 특성의 무작위 하위 집합을 선택합니다. 이 특성의 무작위성은 대부분 주 클래스를 대표하는 특성에 대한 잠재적인 편향을 줄입니다.
- 오류 수정 메커니즘. 랜덤 포레스트는 그 자체의 앙상블 성격을 통해 오류 수정 메커니즘을 사용합니다. 앙상블에서 한 의사 결정 트리가 소수 클래스 인스턴스에서 오류를 발생시키면, 앙상블의 다른 트리들은 해당 인스턴스에 대해 정확한 예측을 함으로써 보상할 수 있습니다. 앙상블 기반의 오류 수정은 주요 클래스의 우세함을 완화하는 데 도움이 됩니다.
이전에 만든 데이터세트를 고려해 봅시다. 랜덤 포레스트 분류기를 사용하여 적합한 결과를 살펴봅시다:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 3개의 클래스로 불균형 데이터세트 생성
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=3,
n_clusters_per_class=1,
weights=[0.1, 0.3, 0.6], # 클래스 불균형
random_state=42
)
# 데이터세트를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 훈련 세트에 랜덤 포레스트 분류기를 적합
rf_classifier = RandomForestClassifier(random_state=42)
rf_classifier.fit(X_train, y_train)
# 훈련 세트와 테스트 세트에 대한 예측 생성
y_train_pred = rf_classifier.predict(X_train)
y_test_pred = rf_classifier.predict(X_test)
# 훈련 세트의 정확도 계산 및 출력
train_accuracy = accuracy_score(y_train, y_train_pred)
print("훈련 세트 정확도:", train_accuracy)
# 테스트 세트의 정확도 계산 및 출력
test_accuracy = accuracy_score(y_test, y_test_pred)
print("테스트 세트 정확도:", test_accuracy)
그리고 우리는 다음과 같은 결과를 얻습니다:
학습 세트 정확도: 1.0
테스트 세트 정확도: 0.97
이 경우에는 랜덤 포레스트를 사용했기 때문에 데이터 세트를 다시 샘플링할 필요가 없었습니다. 그래도 결과는 모델이 과적합될 가능성을 시사합니다. 이는 랜덤 포레스트 특성 때문일 수 있으므로 하이퍼파라미터 튜닝을 위해 추가적인 조사가 필요할 것입니다.
어쨌든, 이 경우에는 하이퍼파라미터 튜닝 후 RF 모델을 사용하는 것이 KNN을 사용하고 데이터 세트를 언더샘플링하거나 오버샘플링하는 것보다 좋은 선택일 수 있습니다.
결론
이 기사에서는 기계 학습(Machine Learning)에서 불균형 데이터를 다루는 방법에 대해 논의했습니다.
특히, 희귀한 사건을 연구하기 때문에 데이터가 불균형할 것으로 예상되는 상황이 있습니다.
반면에 데이터가 불균형해서는 안 되는 경우, 리샘플링(resampling)과 앙상블링(ensembling)과 같은 ML 모델을 다루는 방법에 대한 몇 가지 방법론을 소개했습니다.
원문은 2024년 3월 7일 https://semaphoreci.com 에서 게시되었습니다.